临床预测模型:新预测因子的预测增量值
2020-07-22文玲子王俊峰谷鸿秋
文玲子,王俊峰,谷鸿秋
预测因子是临床预测模型的基础组成部分,探索新的预测因子有助于改善诊断和预后模型的预测准确度,提高个体化治疗水平。随着技术的进步和基础研究的发展,大量新指标,包括基因组学、蛋白质组学和影像学技术指标被发现和提出[1]。然而,新的预测因子在提升预测模型准确性的同时,也增加了测量成本和对患者可能进行的侵入性操作。因此,当评价新的预测因子的预测能力时,尤其是对于测量成本较昂贵的指标,不应只针对该预测因子自身进行评估,而应根据已建立的基于易于获得的预测因子的临床预测模型,来评估新预测因子的预测增量值(incremental value)[2]。 因此,对于新预测因子的预测增量值的研究,也被认为是不同于模型开发和模型验证类研究的一种新的临床预测模型的研究类别[2,3]。作为临床预测模型系列文章的第四篇,本文将介绍在原有预测模型基础上评估新预测因子的预测增量值的方法,并讨论这些方法的优势和局限性,以供读者在方法选择和使用上作参考。
1 评价新预测因子表现的统计指标
随着对新的生物标记物研究的广泛开展,用于评估其预测增量表现的方法学也在迅速发展和不断完善。我们在表1中总结整理了一些传统的和近年来提出的可用于量化预测因子的增量值的指标[1,4],并在下文中对这些指标进行详细的介绍。
1.1 似然函数 大多数统计模型,包括logistic模型和Cox模型,都是基于似然函数来构建的。似然函数反映了在假定模型下获得观测数据的概率或“可能性”(likelihood),这里假定模型包括模型中包含的变量及回归系数。对模型中加入更多的变量会让模型对数据的拟合更好,得到实际观察到的数据的可能性越高[5]。在二分类结局的建模中常见的衡量模型拟合的Nagelkerke R2统计量,也是基于尺度调整后的对数似然函数而计算[1]。因此,似然值是否增加以及增加多少,可作为判断新的预测因子是否可以改善模型的标准。
当新模型和原有模型为嵌套关系时(例如新模型仅比原有模型多出一个新的预测因子),我们可以通过似然比检验来检验模型的改进。当新模型与原有模型为非嵌套关系时,我们可以使用其他基于似然函数的评价指标,例如赤池信息标准(AIC)或贝叶斯信息标准(BIC)。原始AIC对每个新增变量施加2个自由度的惩罚,而广义AIC则可以使用任意惩罚函数。BIC通常对样本数量的对数值[ln(N)]施加较大的惩罚,因此,与AIC相比,它更倾向于简化模型,所以很难得到新的预测因子具有附加价值的结论[4]。

表1 评价预测因子增量值的指标总结
如果新的预测因子不能提高似然值,则不太可能产生任何临床影响。当新模型与原有模型效果一致的零假设成立时,其他评价指标可能变得多余,甚至产生偏差。因此,基于似然函数的检验方法是首先考虑的检验,甚至有研究者提出,基于嵌套模型的似然比检验是评估是否应在现有模型中加入新的预测因子时唯一需做的检验[6]。
尽管基于似然函数的指标或检验可以证明哪个模型有更好的拟合,但这并不一定能转化为临床意义。因为模型改进程度可能很小,改进可能仅限于少数个体,或者可能无法对临床决策产生影响。因此,在新预测因子可以对模型拟合带来改进的基础上,还需进一步通过其他指标来综合判断。
1.2 风险因素效应值 风险因素的效应值,衡量的是风险因素与结局指标的关联程度。对于二分类结局变量,比较常见的效应值包括比值比(OR);对于生存结局,比较常见的效应量包括风险比(HR)。
如果想要评价的预测因子为二分类变量,效应量的解释比较直观,它代表了两组患者间发生结局事件的风险的相对倍数。然而,较高的效应值并不能直接表示预测因子具有较高的增量值,因为预测因子在某个分组中的比例可能非常少。一个OR值为2并且两组患者数的比例为50:50的预测因子,要比OR值为10但是两组患者数的比例为1:99的预测因子更重要[1]。
如果预测因子为连续变量,效应量表示预测因子每增加一个单位时事件发生的风险会增加到多少倍,因此当变量的单位很小或取值范围较广时,效应值可能会显得很小。以身高为例,若以“厘米”为计量单位时身高的OR是1.01,那么当以“米”为计量单位时,OR将变为2.70(1.01的100次方),所以不能仅根据效应值的大小来判断预测因子的表现。这时可以考虑使用标准化的效应值,即对应于预测因子一个标准差的变化的效应值。另一种常见的方法是,使用四分位间距的效应值,即预测因子上四分位值(75%分位点)相对于下四分位值(25%分位点)的效应值[1]。
1.3 ROC曲线和C统计量 ROC曲线可以用来描述一个连续预测因子在一系列阈值上的灵敏度和特异性。ROC曲线下面积(AUC),有时也称为c统计量,可以解释为当我们比较一位发生事件的患者与一位未发生事件的患者时,发生事件者具有较高的模型预测值的概率[1]。当AUC为0.5时代表预测模型没有判别能力,与抛硬币无异,AUC值为1则代表预测模型具有完美的判别能力。一直以来,AUC和C统计量都是评估诊断模型或预后模型的主要指标。通过比较增加新预测因子的模型和原有模型的AUC,可判断新预测因子的预测能力。ROC曲线直接评估模型区分度,不受模型校准度(即预测风险概率与观察风险概率的匹配程度)的影响,当研究问题是区分不同患者时,比如区分患病和未患病人群时,该指标较适用[7]。
然而,由于ROC曲线和AUC是对区分度的总体衡量指标,没有针对特定分类阈值给出正确分类和不正确分类的绝对人数或比例,所以该指标没有直接的临床解释。另外,根据实践经验,AUC的绝对变化量通常很小,尤其是当模型的AUC较大时,即便是更好的模型也很难继续提高AUC。因此,当评价新的预测因子的增量值时,不应过分强调AUC的改善程度,因为这一指标很大程度上是取决于原模型AUC的高低,而不是取决于新预测因子对结局的预测能力[4]。实际上,在心血管疾病领域,有许多非常有应用前景的生物标志物,虽然与心血管疾病有很强的联系,但由于未能显著改善AUC,导致研究得出对生物标志物的价值过于悲观的结论[7]。
1.4 重分类指标 为了解决AUC改善值评价新预测因子的预测增量值的局限性,研究者们又提出了一系列基于模型预测重分类的替代指标。风险分层主要关注的是预测模型是否能够准确的将个体根据临床意义分组,这对于确定治疗决策和优先治疗对象等方面都具有重要意义。风险重分类的思想最初由Cook等[8,9]提出,目的是显示有多少个体在模型增加新的预测因素后风险分层将发生变化。而风险重分类指标最早是由Pencina等学者提出的[10],主要包括净重分类改进指数(NRI)和综合判别改进指数(IDI)。
1.4.1 分类净重分类改进指数 最常用的净重分类改进指数是基于风险分层来计算的,也被称为分类净重分类指数[10]。
如果是根据有临床意义的阈值将预测概率进行的风险分层,那么分类NRI可以表示于原有模型相比,新模型是否使风险分层结果发生变化,从而影响有关临床治疗的决策。分类NRI的计算公式如下[11]:
本刊:2015年11月27日,中共中央、国务院印发《关于进一步推进农垦改革发展的意见》,充分体现了以习近平同志为核心的党中央对农垦事业发展的高度重视,是新形势下指导农垦改革发展的纲领性文件。请介绍一下广东农垦贯彻落实中央文件的情况。
N R I=N R I(+)+N R I(-)=[P(u p|D=1)-P(down|D=1)]+[P(down|D=0)-P(up|D= 0)]
=[向上转移数/事件数-向下转移数/事件数]+ [向下转移数/非事件数-向上转移数/非事件数]
其中D代表事件发生状态(D=1为发生事件,D=0为未发生事件),up表示转移到更高风险类别,down表示转移到更低风险类别。从公式中我们可以看到,NRI可以分为两个部分:事件组NRI[NRI(+)]和非事件组NRI[NRI(-)]。其中NRI(+)是两个比例的差值,即事件组中转移到更高风险类别的患者比例P(up|D=1)减去事件组中转移到更低风险类别的患者比例P(down|D=1)。如果NRI(+)的计算结果为正,则表明更多的事件组患者被新模型转移到更高风险类别而不是更低风险类别,也就是被重新分类为更合适的风险类别。相应的,NRI(-)也是两个比例的差值,即非事件组中转移到更低风险类别的患者比例P(down|D=0)减去非事件组中转移到更高风险类别的患者比例P(up|D=0),如果NRI(-)的计算结果为正,则表明未发生事件的患者被新模型转移到更低风险类别的人数要多于转移到更高风险类别,即被重新分类为更合适的风险类别[11]。
以表2中在ADVANCE心血管疾病预测模型中加入eGFR的风险重分类数据为例[2],根据以上公式计算分类NRI。
在ADVANCE研究数据中,共有429例患者在随访期间发生重大心血管疾病事件,加入eGFR的扩展模型仅将2例患者正确地向上分类(改善),但同时也将另2例患者错误地向下分类(损失),NRI(+)为0%(2/429-2/429)。在6739例随访期间未发生事件的患者中,加入eGFR的扩展模型对其中32例正确地向下分类(改善),同时也导致29例患者被错误地向上分类(损失),NRI(-)为0.04%(32/6739-29/6739)。因此,此案例中总的NRI为0.04%,这表明原模型与新模型相似,没有迹象表明eGFR在原模型之上增加了额外的预后价值。

表2 在ADVANCE心血管疾病预测模型中加入eGFR后的风险重分类
在实际应用中,NRI的值会受到风险分层的数量和每个分层大小的影响,因此应预先确定分层的阈值。如果没有给定的阈值,可以考虑根据事件发生率P,设定阈值为P/2,P,和2P,将所有患者分为四个风险组[12]。另外一种特殊的情况,是以P作为阈值将预测结果分为两组,这时计算的NRI值通常用NRI(p)来表示。NRI(p)虽然具有一些不错的统计属性,也与其他评价模型表现的统计量有一定关联,但是缺乏临床意义,无法对临床决策产生重要影响。
在使用NRI时需要注意,对于事件组和非事件组,应始终分别报告NRI的两个组成部分,即NRI(+)和NRI(-),以便可以根据需要来分别解读模型在事件组和非事件组中的改进或根据重要程度对两部分进行重新加权。
1.4.3 综合判别改进指数 综合判别改进指数(IDI)是另一种不依赖风险分类,而是综合所有风险预测值的变化的指标[10]。与连续NRI不同的是,IDI不仅依据是否增加或降低,还计算增加或降低的程度。我们结合表3中的示例数据来看一下分类NRI,连续NRI和IDI在计算时的差别。
表3中前4位患者的数据,假设他们都发生了目标事件,所以都属于事件组。假定我们提前选定的阈值是0.08,预测风险概率大于0.08的作为高风险组,小于0.08的作为低风险组。患者1在原模型中的预测概率为0.07,属于低风险组,而在新模型中预测概率为0.09,被重新分类为高风险组,所以对于分类NRI的计算贡献为+1,连续NRI只考虑预测概率是否增加,所以也是+1,IDI计算概率增加的具体数值,所以患者1对于IDI计算的贡献是0.09-0.07=0.02;患者2刚好与患者1相反,预测概率从0.09变为0.07,所以对各指标的贡献也与患者1相反;患者3在原模型和新模型中,都被分为高风险组,风险分组没有改变,所以对于分类NRI的贡献为0,由于新模型的预测概率高于原模型,所以连续NRI的贡献为+1,IDI的贡献则为预测概率的增加程度0.1-0.09=0.01;患者4与患者3类似,风险分组没有改变,但是风险预测值有所降低,所以对分类NRI的贡献为0,对连续NRI的贡献为-1,对IDI的贡献为0.09-0.11=-0.02。若需在非事件组中计算上述指标,也可以此类推,只需对变化的方向进行相应调整。表3后4位患者的数据,假定其均未发生事件,计算过程与前述4位类同,只是计算结果的符号发生改变。
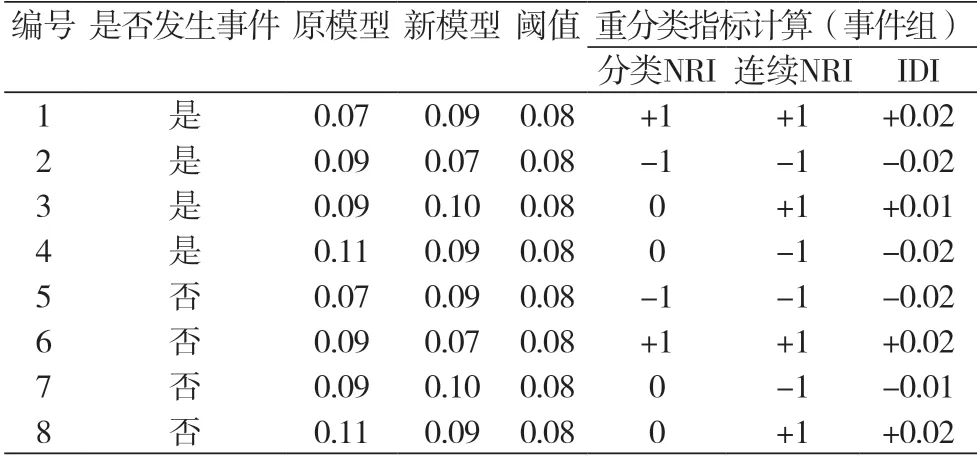
表3 在事件组和非事件组中计算分类NRI,连续NRI和IDI的示例
以上示例中的计算,只是演示每个患者对不同指标的贡献如何确定,在计算最终指标时,应首先将每个患者的贡献除以数据中的事件数(对于非事件组则除以非事件数)。IDI与其他的一些评价模型预测表现的指标有着密切的关系,它等于新模型与原模型的区分度斜率(又被称为Yates斜率)的差值,并且等于新模型与原模型的尺度调整后的Brier得分的差值[7]。与NRI相比,IDI的值通常很低,并且难以解释,在实际应用时可以考虑将IDI除以原模型的区分度斜率作为区分度斜率的相对变化值[15]。
2 研究新预测因子增量值的注意事项
在进行新预测因子的增量值的研究时,有以下几方面的问题需要特别注意[1]。其中部分内容已经在上文中有所涉及,此处再重新汇总强调如下:
首先,需要明确此类研究和关键问题是评价预测因子的增量值,所以应当考虑将诸如人口学特征,标准预测因子或其他易于获得的预测因子,或使用之前已经发表的预测模型作为分析中的参考模型。例如,在研究心血管疾病标记物的价值时,可以在统计模型中加入Framingham研究中使用的预测因子。然而,有研究发现,在声称针对“Framingham预测因子”进行调整的研究中,每个研究对参考模型的确切定义有很大不同,这就导致当新的预测因子被添加到效果较差的参考模型中时,会高估新预测因子的增量值。
第二,在建模过程中,避免对连续的预测因子进行二分类处理,因为这会导致信息丢失。二分类法更适用于在建模过程结束后,对模型预测结果进行分类,以便预测为临床决策提供依据。
第三,不应直接将较大的效应量(OR或HR)解释为预测增量值的证据,因为效应量取决于变量的测量单位,并且忽略了变量的分布特征。另外,如果变量中的某个类别非常罕见,也会导致较高的效应量,但是实际应用中对疾病诊断或预后的价值有限。
第四,不应直接将较低(或低于预先设定的显著性水平)的P值解释为预测增量值的证据,因为P值不仅取决于效应量,还取决于样本量,在大型研究中很容易得到极低的P值。
第五,不应直接将较大的AUC值解释为证明预测因子具有良好的临床实用性,因为在没有上下文的情况下无法解释AUC值:AUC为0.7或0.8可能在某些情况下表示在临床上有用,而在其他情况下则不一定,这具体取决于决策阈值在预测风险的分布中所在的位置,这一点对于评价新的预测因子带来的AUC的增长也是一样的。
第六,在使用重分类指标时,也应考虑这类指标的局限性。大多数时候,预测风险概率的变化不会转化为治疗决策和临床管理的改变:例如,一例10年冠心病预测风险从1%增长至2%的患者,可能并不会因此得到不同的治疗。因此连续NRI相比于分类NRI,临床解释性较差。而对于分类NRI,计算时直接采用事件发生率P为权重来综合假阴性结果(事件分类为向下)和假阳性结果(非事件分类为向上)的成本。从临床角度来讲,对假阳性和假阴性结果采取不同的权重更为合适。所以,非加权的分类NRI更适用于评估新预测因子的早期研究,下一步还需要运用决策分析(decision analysis)方法,来评估新预测因子的潜在临床效用[16]。关于临床预测模型的决策分析和成本效应分析方法,将在本系列之后的文章中详细介绍。
在本文中,我们介绍了一系列传统的和相对新颖的评价新预测因子增量值的指标。同时,我们以心血管疾病患者的标志物为例,说明了不同性能指标的计算方法,最后着重强调评估诊断标志物增值时的一些方法学挑战。净重分类改进指数是汇总风险重分类表中包含的信息的一种简单而有效的方法。在没有具有临床意义的风险类别的情况下,建议使用连续净重分类改进指数和综合判别改进指数作为衡量新生物标记物增量价值的指标。
