基于神经随机森林的局部空气质量预测模型
2020-07-20钱雪忠
程 蓉,钱雪忠
(江南大学 物联网工程学院 物联网技术应用教育部工程研究中心,江苏 无锡 214122)
0 引 言
空气质量指数(air quality index,AQI)是用来定量描述空气质量的无量纲指数,其大小代表空气的污染程度。主要利用PM2.5、 PM10 、 SO2、 NO2、 CO 、 O3这6项污染物来评价空气质量。随着我国经济的快速发展,大气污染日益严重,雾霾天气频频出现,不仅严重威胁着人们的身体健康及地球的气候系统,还造成了我国经济利益的巨大损失。同时,对于像南京玄武湖、夫子庙这样的旅游景区,人来车往,较差的空气质量也给人们的外出旅行带来了极大困扰。人们越来越关注空气质量,希望像天气预报一样可以提前知晓,以便安排他们的出行活动计划并提前做好保护措施。因此,研究局部空气质量的预测方法,对人们的健康出行以及国家经济发展意义重大。本文是利用南京市玄武湖地区的历史天气数据和空气质量数据,对该地区下一日的空气质量进行预测。
目前为止,已经提出了许多预测空气质量的方法。Shamsoddini A等[1]将随机森林特征选择方法与多元线性回归和多层感知器人工神经网络相结合,实现空气中PM2.5、 SO2、 NO2、 CO含量的预测。不仅利用了前一天的空气污染物的含量,还分析了交通和植被密度对污染物的影响,有效预测了空气中染污物的浓度。Zhang C等[2]基于Spark集群,提出了随机森林的空气质量预测模型,将PM2.5、 PM10、 SO2、 NO2、 CO、 O3作为影响因子,该模型在处理大数据集的时候能够快速预测AQI,不仅缩短时间还具有可扩展性,但是忽略了AQI的其它影响因素。Junshan W等[3]考虑到天气模式和空气质量的时空依赖性,提出一种深度时空集合模型,它是由基于天气模式的分区策略的集合方法,通过分析各站点间Granger因果关系并将空间数据生成为相对站点和相对区域来发现温度的相关性,基于深度LSTM的时间预测器3个部分组成,并利用北京35个监测站的数据评估模型,验证了该模型优于传统的回归方法和机器学习。Lifeng W等[4]为了获取未来空气质量的趋势,利用分数阶累积的FGM(1,1)模型预测京津冀地区2017年-2020年PM2.5、PM10、SO2、NO2、8-h O3、24-h O3年平均浓度。实验结果表明,FGM(1,1)模型的预测性能明显优于传统的GM(1,1)模型。Gu K等[5]考虑到气象因子与空气污染物浓度及几小时后的空气质量指数之间的非线性关系,采用1小时中长期预测模型,递归地提出了一种启发式的RAQP模型,并验证了该模型的有效性以及通用性,它不仅具有较高的预测性能,还可以推导出中间时刻的空气质量指数。
玄武湖地区的空气质量不仅受天气影响,同时也受该地区的交通状况以及人流量的影响。在车流量和人流量较大的情况下,车子排放的尾气以及人为的污染对空气质量预测的影响也很大。所以,空气质量具有很强的非线性特性。针对空气质量非线性动态变化的特点,本文提出一种神经随机森林局部空气质量预测方法。
1 神经随机森林局部空气质量评价模型
1.1 CART回归树
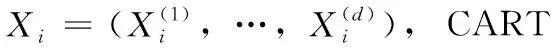

(1)
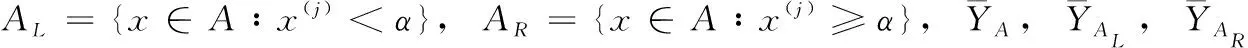
(2)
1.2 随机森林
随机森林是由M棵随机的CART回归树组合而成的预测器。对于模型中的第m棵树,查询点x处的预测值用t(x;Θm,Dn) 表示,其中Θ1,…,ΘM是随机变量,分布与一般随机变量Θ相同。假设Θ1,…,ΘM,Θ与Dn相互独立,模拟每棵树结构中引入的额外随机变量Θ,用于:①在单棵树生长之前对训练集进行重新取样;②通过随机的CART标准选择连续的分裂方向;③最后,将所有的树木组合起来,形成森林。式子如下
(3)

(4)
式(2)和式(4)的本质区别在于式(4)是在随机选择的坐标子集Mtry上进行估计的,而不是在整个范围内 {1,…,d}。 参数mtry是为了减少计算负担,并在树之间创建一些多样性,与n无关,通常将mtry设置为d/3。 此外,由于采用了无替换采样,每棵树都是在初始样本中选取的an个示例的子集上构建的,而不是在整个样本Dn上。在CART中,当每棵树到达Kn终端节点时,停止构建单棵树 (Kn∈{2,…,an},Kn是算法中的一个参数),这里每棵树上的叶节点树等于Kn。
1.3 回归树和神经网络
一般的框架是非参数回归估计,向其中输入一个随机向量X∈[0,1]d, 然后通过估计回归函数r(x)=Ε[Y|X∈x] 来预测平方可积随机响应Y∈R。 根据这一思路,假设有一个训练数据集Dn=((X1,Y1),…,(Xn,Yn))且n≥2, 独立随机变量的分布与独立原型对 (X,Y) 相同。Dn用于构造函数r的估计值r(·;Dn)∶[0,1]d→R。 下文将r(x;Dn) 简写成rn(x)。

树的结构依赖于数据,每棵树的结构都是不同的。对于一棵回归树tn, 它的结构最终取决于数据Dn, 同时,在每个K≥2个终端节点上取恒定值。Tanno R等[6]提出将树结构中根到叶的路径由NN表示,形成自适应神经决策树。在本文中,用同样的思想将回归树与神经网络结合,但是限制了网络的层次,将其构建为具有特定连接权重的神经回归树。因此,该估计可以被重新解释为具有两个隐含层和一个输出层的三层神经网络估计。H={H1,…,HK-1} 为构建tn所有超平面的集合,其中jk∈{1,…,d},αjk∈[0,1],hk(x)=x(jk)-αjk, 则HK的形式为HK={x∈[0,1]d∶hk(x)=0}。 为了到达查询点x的叶节点,x落在超平面HK的右边用+1表示,左边用-1表示。利用这种表示法,树估计tn与下面描述的神经网络相同。
第一个隐藏层。第一个隐层的神经元对应于K-1感知机(每个内部树节点对应一个),其激活的定义为
τ(hk(x))=τ(x(jk)-αjk)
(5)
其中,τ(u)=2Ιu≥0-1是阈值激活函数,权重向量仅是特征jk的单个单热矢量, -αjk偏差值。因此,对于树中的每个分裂,第一层有一个神经元,它的活动编码输入x相对于相关分裂的相对位置。总的来说,第一层输出±1的向量 (τ(h1(x)),…,τ(hK-1(x))), 它描述了内部的所有决策树节点(包括x的树路径之外的节点)。若x在超平面HK的一侧,则τ(hk(x)) 为+1,若在另一侧,则τ(hk(x)) 为-1。在这里强调,该层的每个神经元k有且只能连接一个输入x(jk), 并且该连接具有权重1和偏移-αjk。 如图1所示,给出了一个列子。由于第一层的这些特殊激活,第二层可以轻松地构建x的终端单元。

图1 回归树和相应神经元
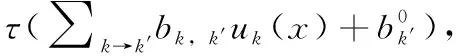
(6)

(7)


(8)

1.4 神经随机森林
由1.3小节可知,在神经网络的设置中,重新构造森林的每棵随机树估计t(x;Θm,Dn), 1≤m≤M。 得到的M个网络是不同的,因为它们对应不同的随机树。由上文可知第m个网络在第一个隐藏层中具有Kn-1个神经元,而在第二个隐藏层中具有Kn个神经元。同时。神经元的连接方式和相关系数取决于Θm和Dn。 将第m棵树估计t(x;Θm,Dn) 作为神经网络估计。在Θm和Dn条件下,该网络神经元的连接方式是固定的,三层的权重和偏移也是固定的。为了保持网络结构的完整,一旦神经元之间的连接被树到网络的映射设计好了,就可以通过最小化样本Dn上网络的经验均方误差来学习更好的网络参数。这种额外的训练可以潜在地改进原始随机森林的预测。
为了实现梯度反向传播的训练,激活函数必须是可微的。因此,用双曲正切激活函数来代替原始的中继型激活函数τ(u)=2Iu≥0-1, 即
(9)
取值范围为[-1,1]。在第一个隐藏层中,每个神经元使用σ1(u)=σ(γ1u)。 在第二层神经网络中,每个神经元使用σ2(u)=σ(γ2u)。 其中,γ1和γ2是决定双曲正切激活函数对比度的正超参数:γ1和γ2越大,从-1到1的转换越快;当γ1和γ2接近无穷大时,连续函数σ1和σ2收敛到阈值函数。双曲正切激活函数除了提供更好的泛化效果外,还有助于决策边界的平滑和树节点隶属度的松弛。最后,它们允许在不连续阶跃激活函数的平滑近似下进行操作。这使得网络损耗函数在各个参数上都是可微的,并且可以用反向传播来训练网络。
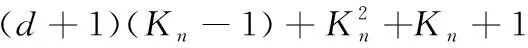
当允许层之间完全连接时,树结构的松弛可以更进一步。在这种情况下,树结构仅用作相同大小的完全连接网络的初始化。在此设置中,属于树结构的所有权重都具有非零初始化值,而其它权重是以零开始。在训练过程中,所有的权重都可以被修改,以便在各个层之间建立任意的连接。与随机初始化相比,初始树型参数化提供了很强的诱导偏差,为网络提供了有效的热启动。随机初始化包含有价值的信息,并在反向传播训练之前就已经模拟了CART决策树的回归函数。
综上所述,可以将M个CART类型的树转换为M个树类型的神经网络。接下来,将描述如何组建M个网络,将该方法称为神经随机森林(下文简称为NRF)。
每棵树型网络的参数是由网络相互独立地进行网络拟合的,通过将树型网络进行独立的训练,然后得到一个由M个小神经网络组成的估计集合r(·;Θm,Dn), 其中1≤m≤M, 最后求平均形成估计
(10)
如图2所示。下文,将r(x;Θ1,…,ΘM,Dn) 简写为rM,n(x),rM,n(x) 取决于Θ1,…,ΘM和样本Dn。
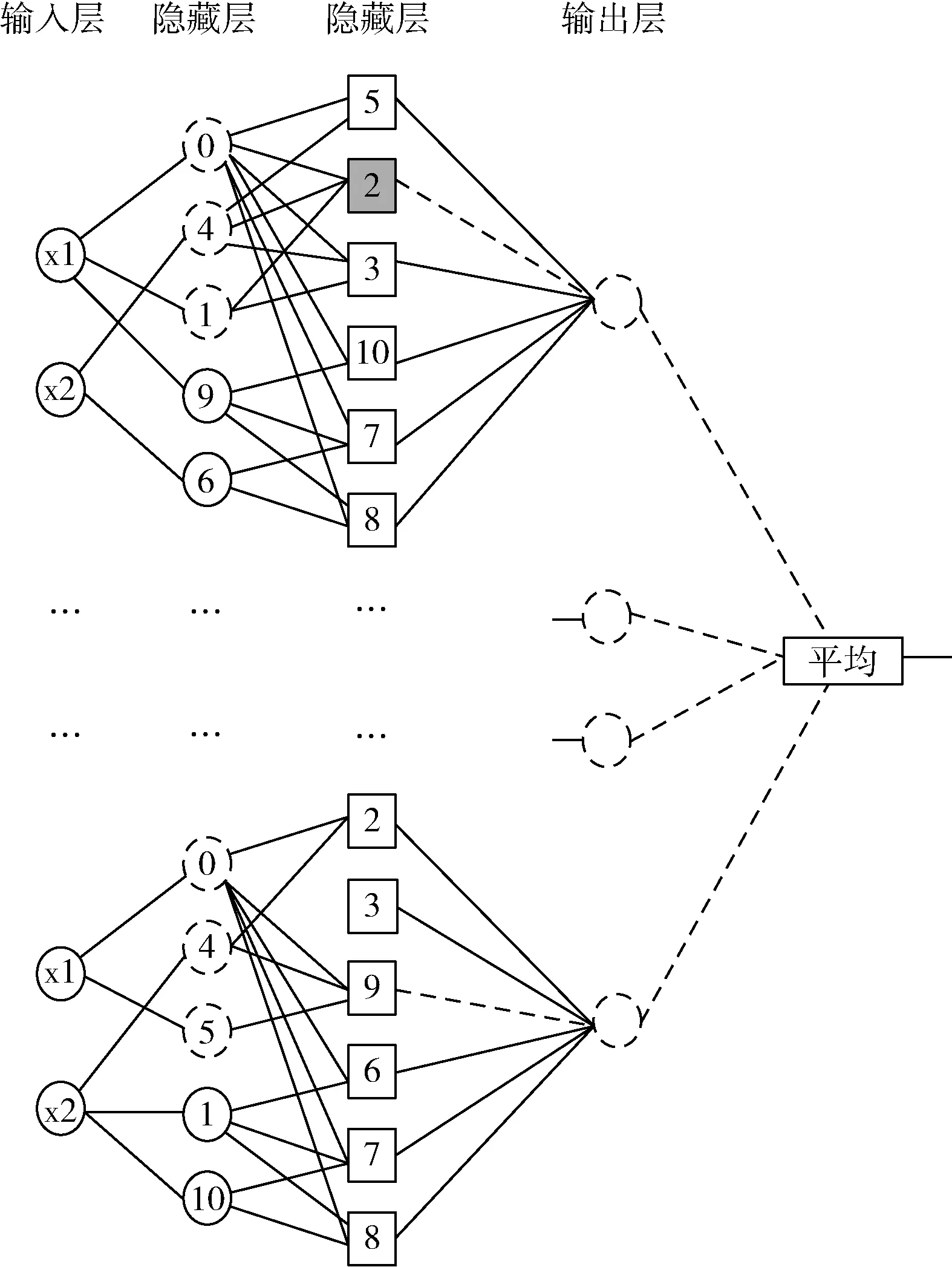
图2 独立训练
下面将介绍在每个小网络上实施的最小化程序,以及rM,n(x) 的统计特性。考虑到集合中的第m棵随机树,用g1=g1(Θm,Dn) 表示输入向量x=(x(1),…,x(d)) 和第一个隐藏层的Kn-1神经元之间连接的二分图。同样的,用g2=g2(Θm,Dn) 表示第一个隐藏层与第二个隐藏层的Kn神经元之间连接的二分图。
令M(g1) 为d×(Kn-1) 矩阵的集合W1=(aij), 如果(i,j)∉g1则aij=0。 同样的,令M(g2) 为 (Kn-1)×Kn矩阵的集合W2=(bij), 如果 (i,j)∉g2则bij=0。 第一个隐藏层的参数由g1的权重M(g1) 的矩阵W1和大小为Kn-1 的偏移的列向量b1表示。类似的,第二个隐藏层的参数由g2的权重M(g2) 的矩阵W2和大小为Kn的偏移的列向量b2表示。最后,让输出权重和偏移量分别为Wout=(w1,…,wKn)Τ∈RKn(Τ表示转置)和bout∈R。 因此,指定第m个网络的参数由“向量”表示
λ=(W1,b1,W2,b2,Wout,bout)∈
M(g1)×RKn-1×M(g2)×RKn×RKn×R
(11)
这里,为了保持一致性,限制这些参数的变化范围。对于给定的矩阵M, 符号 |M| 表示M的元素的绝对值矩阵。假设存在一个正常数C1, 这样
(12)
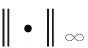
Λ(Θm,Dn)={λ=(W1,b1,W2,b2,Wout,bout)}
(13)
第m个神经网络实现了这种形式的函数
(14)
其中,λ∈Λ(Θm,Dn), 并且σ1和σ2是按元素来应用的。我们的目的是利用数据Dn来调整参数λ, 从而使所得到的网络实现的函数可以很好地估计r。 使
F(Θm,Dn)={fλ∶λ∈Λ(Θm,Dn)}
(15)
其中,m∈{1,…,M}。 算法通过最小化经验误差来构造回归函数估计r(·;Θm,Dn)
(16)
在F(Θm,Dn) 中的函数f, 即f∈F(Θm,Dn) 有
Jn(r(·;Θm,Dn))≤Jn(f)
(17)
在这里,假设存在一个最小值,尽管它不一定是唯一的。在不存在最小值的情况下,可以使用误差任意接近下限的函数来执行相同的分析,但是为了简单起见,本文坚持存在的假设。通过重复这个最小化过程,对于每个m∈{1,…,M}, 可以得到随机估计的集合r(·;Θ1,Dn),…,r(·;ΘM,Dn), 它们被合并求平均值形成了估计
(18)
估计rM,n只是随机森林估计tM,n对神经网络框架的推广,由于双曲正切激活函数的存在,额外松弛到模糊树节点隶属度:样本不仅每个分裂和一个最终叶子落入一个方向,而且同时分成几个树枝和叶子。
2 实验设计与结果分析
2.1 数据来源及选择
NRF模型是对原始随机森林算法的优化,为了验证NRF模型的性能,本文在UCI机器学习仓库中选取4个标准回归数据集,分别是汽车MPG数据集(auto_mpg)、社区犯罪数据集(communities crime)、森林火灾数据集(forest fires)以及波士顿房价数据集(Boston House Price)作为样本数据集,并将样本数据按照50∶25∶25的比例分为训练集、验证集和测试集,分别在NRF模型、RF模型和NN模型中运行。这里,随机森林采用树木数量为25,最大深度为6的最优参数组合。表1展示了不同数据集在NRF、RF和NN模型上运行的均方根误差(RMSE)。

表1 NRF、RF、NN在不同数据集上的RMSE
从表1可看出,NN模型在大部分数据集中都没有达到与NRF模型和RF模型一样的预测效果。同时,NRF模型在不同数据集中的RMSE都明显小于RF模型的RMSE。由此可见,NRF模型的预测效果要优于RF模型和NN模型,取得了不错的效果。接下来,本文将NRF方法应用于实际问题,利用南京市玄武湖地区的历史天气和空气质量数据,来预测该地区下一日的AQI指数。
本实验采用的数据是来自南京市玄武湖监测站提供的空气质量历史监测数据。实验选取了2013年10月1日-2019年3月31日玄武湖地区的空气质量数据作为实验样本数据,共2008条,将样本数据按50∶25∶25的比例分为训练集、验证集和测试集。
图3和图4分别展示了南京市玄武湖地区AQI指数日均值和月均值时序变化规律。从图中可以看出,AQI指数日均值和月均值基本上服从正态分布规律,更好契合了该算法。从图3可看出,AQI指数日均值随着时间的推移出现峰谷型变化。从图4可看出,AQI指数呈春冬高、夏秋低的特点,12月和1月是AQI指数高发月,这也是把季节作为一项特征的原因。
如表2所示,选取气象条件、大气污染、人类污染和季节4个方面共33个相关特征因素。其中,温度、气压、紫外线、湿度、降水量、大气污染物浓度以及人流量车流量属于数值型特征用“real”表示,其余均属于非数值型。在处理非数值型特征时,本文对其进行量化:将非数值型特征转化为离散的数值型特征,并放入“[]”,以此表示取值范围。如“(Before_)weather”的取值为“[0,1,2,3,4,5]”,代表6种天气状况:晴、多云、阴、雨、雪、雾;“(Before_)Direction”的取值为“[0,1,2,3,4,5,6,7]”,代表8种风向:东风、东北风、东南风、南风、西南风、西风、西北风、北风;“(Before_)speed”的取值为“[0,1,2,3,4,5]”,代表6种风力类型:1~2级、3~4级、4~5级、5~6级、6~7级、7~8级;“Season”的取值为“[1,2,3,4]”,代表初、夏、秋、冬4个季节。
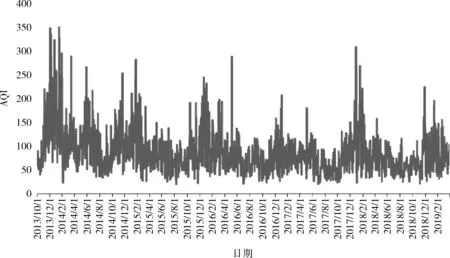
图3 玄武湖地区AQI指数日均值时序规律
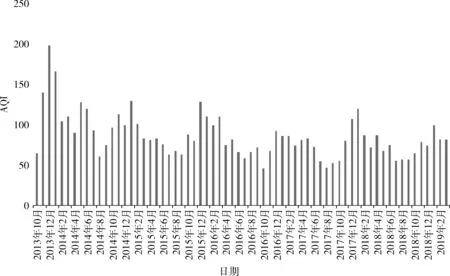
图4 玄武湖地区AQI指数月均值时序规律
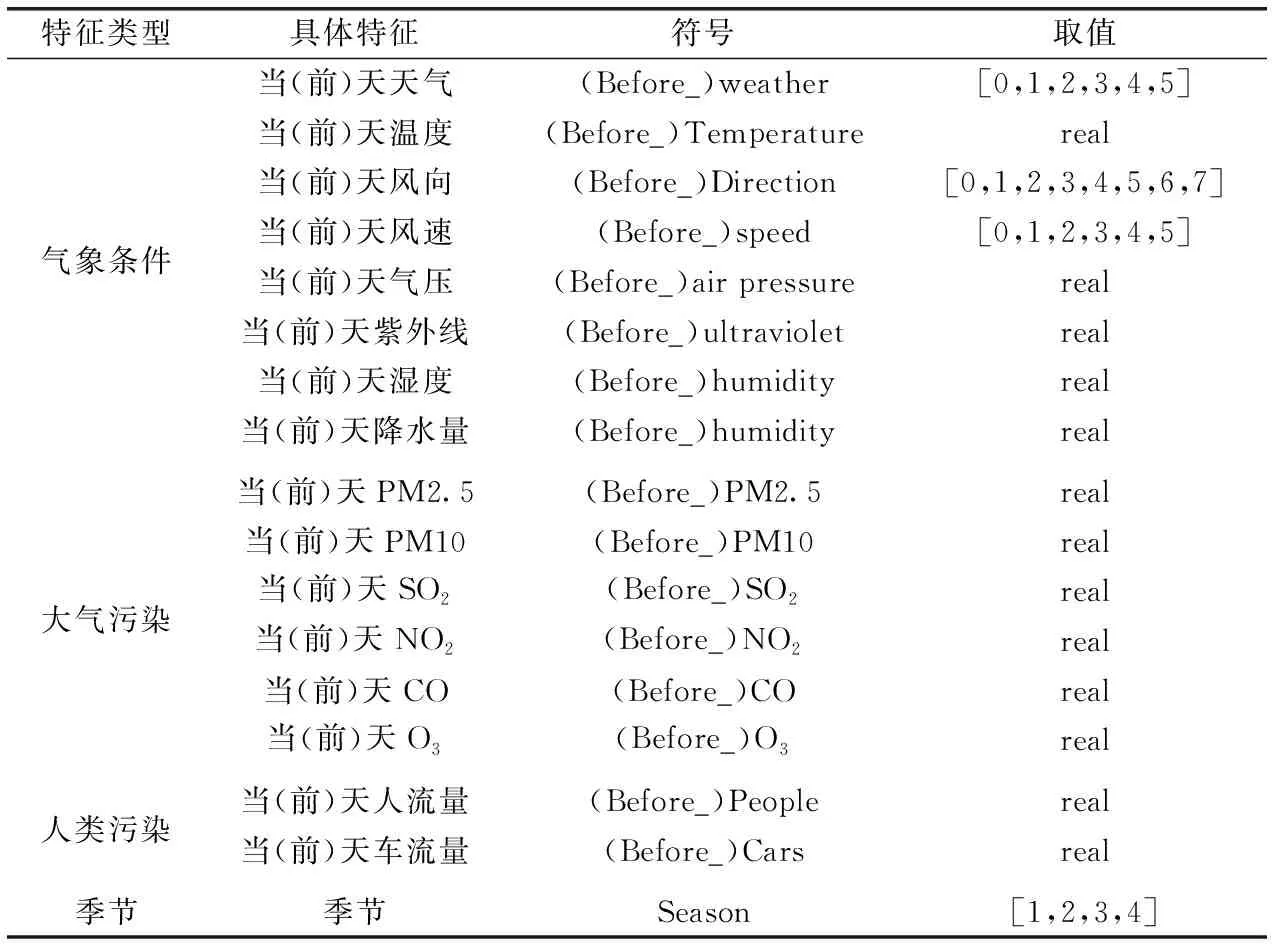
表2 特征因素的选取
2.2 模型评价指标
为衡量预测模型的稳定性和适应性,本文选取了拟合度(R2)、均方根误差(RMSE)这两个指标对模型进行评价。公式如下
(19)
(20)
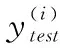
2.3 实验结果与分析
在构造NRF模型时,采用树木数量为25,最大深度为6的最优参数组合,NRF层之间采用的是完全连接,即初始化网络权重,这样就有较少的权重需要优化,并且每层具有相同数量的神经元。首先使用scikit-learn运行随机森林,在此基础上,将所有分割方向和分割位置的集合用于构建神经网络初始化参数,然后再使用TensorFlow框架训练NRF模型。
在学习NRF和NN网络模型时,优化目标是最小化某些训练集上的均方误差。在神经网络训练中,是通过使用基于迭代梯度的优化算法来实现的。该算法遍历训练集,生成预测,然后将产生的误差信号相对于所有单独的网络参数的梯度传播回网络。更新网络参数,可以减小该误差,慢慢地模型学会了生成正确的预测。本实验中,batchsize大小默认为32,随机初始化权重分别默认为β1=0.9,β2=0.999,ε=1e-08, 以及初始学习率默认为0.001。在每次训练开始时,都会对训练集进行重新排序和分配,以避免过度拟合。
每棵神经树的神经网络都训练迭代100次。在训练过程中,每完成一次训练后都会监测训练损失和验证损失,最后选择的参数是在100次训练过程中给出最小验证误差的参数。同时,γ2使用较小的值比γ1使用较小的值 (γ2,γ1分别是第二和第一隐藏层中的激活函数的初始对比度参数)更有用。这是因为有一个相对较小的对比度γ2, 激活函数从-1到+1的转变更平滑,并且更强的梯度信号到达反向传播训练中的第一隐藏层。因此,本实验使用γ1=100和γ2=1。
为了说明训练行为,将NRF模型与RF模型和NN模型的训练误差和验证误差进行了对比,如图5所示。

图5 训练和验证误差对比
从图5中可以看出,NRF模型在训练期间的RMSE明显低于验证期间的RMSE。同时,NRF模型不管是训练RMSE还是验证RMSE都低于RF模型对应的RMSE,说明了NRF具备较好的学习能力和泛化能力。将NRF与参数和层数完全相同的NN对比,很显然,NRF模型在训练集和验证集上的RMSE均低于NN模型。由此可见,NRF模型优于RF模型和NN模型。
利用测试集对训练好的模型进行AQI指数的预测。图6 给出了NRF模型的测试效果,预测值与实际测试值拟合较好。

图6 测试效果
图7展示了模型预测值和实际值的线性拟合结构,其中相关系数为0.952,拟合度R2达到了0.973。图8是随机森林(RF)、神经网络(NN)、支持向量机回归(SVR)、线性回归(LR)、LSTM神经网络(LSTM)模型与NRF模型的预测误差对比图,RF和LR的误差在(-90,60)范围内,NN和SVR的误差在(-280,70)之间,LSTM的误差在(-60,270)之间,NRF的误差则在(-70,30)之间。相比较其它模型,NRF的预测误差范围最小,分布也比较均匀集中。具体性能指标对比见表3。
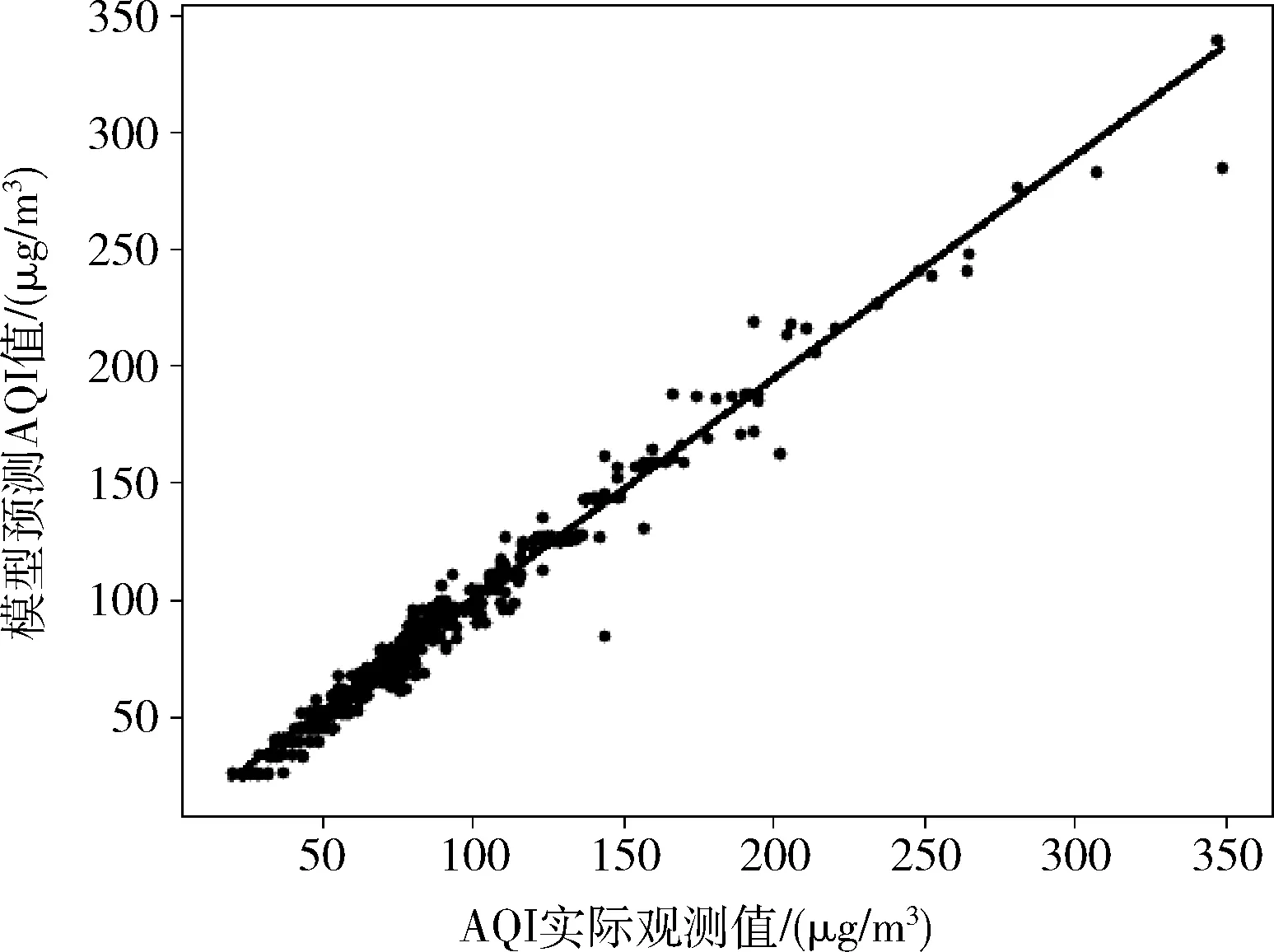
图7 AQI预测值与实际值相关性分析
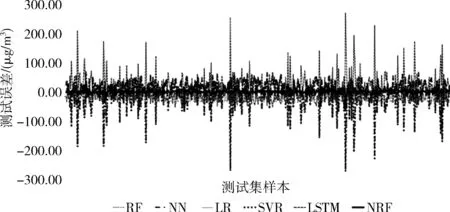
图8 不同模型的测试误差
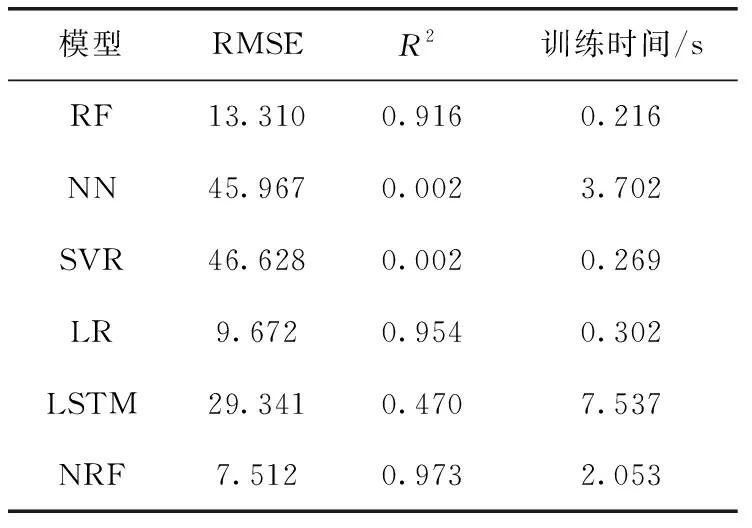
表3 不同模型的预测结果对比
通过表3比较发现,NRF在模型精度方面明显优于其它方法。NRF模型的均方根误差RMSE为7.512,相比较RF模型的13.310和NN模型的45.967,分别降低了5.798和38.455,同时NRF模型的拟合度R2也高于RF和NN,说明NRF不易过拟合,并且具备较好的学习能力和泛化能力。而NN模型存在计算量大、学习效率低,容易过拟合等问题。同时,NRF模型的RMSE明显高于SVR模型、LR模型和LSTM模型。在模型的运行效率方面,NRF模型的训练时间高于RF模型,低于NN模型,那是因为NRF模型需要对每棵神经树进行单独安装,并单独进行训练,每次训练迭代100次,所以导致NRF模型训练时间高于RF模型。但是,NRF连接网络使用的是森林结构,并且提供了智能初始化作为热启动,可以有效降低过度拟合,同时完全连接网络优化速度快,在GPU上进行训练时,使用密集矩阵乘法,将不存在的连接的条目强制为0,因此也大大减少了训练时间,故训练时间低于NN模型。同时,NRF模型的拟合度明显高于RF模型的拟合度,说明NRF模型对数据的拟合效果更好,可以更准确预测该地区下一日空气质量。从整体来看,NRF模型的预测效果优于RF模型。综合比较预测结果,NRF模型在空气质量指数预测问题上的效果优于RF、NN、SVR、LR、LSTM,具有较高的准确率,能够很好地解决复杂的非线性问题。
NRF模型结合了RF模型和NN模型的优点,结构简单易于理解、参数易于调节、模型实现简单,且不需要对数据进行归一化处理和交叉验证,模型的精度高,拟合效果也更好。所以,NRF在综合性能上具有一定的优势。综上所述,本文使用的方法具有可行性与有效性,能够很好地满足玄武湖地区下一日空气质量的预测任务。
3 结束语
基于优化的随机森林的局部空气质量预测模型,通过将随机回归树重构为具有两个隐藏层和一个输出层的神经网络回归树,然后再将这些神经网络回归树进行独立训练,最后合并求平均形成一个由M个小网络构成的神经随机森林。该神经随机森林结合了随机森林与神经网络的优点,具有较高的拟合度,并且性能稳定,具有很好的泛化能力,可以很好地应用在局部空气质量的预测上。NRF模型是对原始随机森林RF的优化,有效提高了预测精度。同时,由于NRF模型的特定归纳偏差,不管在哪一个数据集上,都可以取得令人满意的预测结果。因此,在实际应用中,本文为城市环境空气质量评价提供了一种高效准确的处理办法。下一步的工作是改变每棵神经网络回归树的训练方式,将它们放在一起训练并研究该训练方法对整个模型的影响,从而提高模型的运行效率。
