基于AdaBoost的某竞技游戏得分预测的应用
2020-07-15
(云南财经大学 云南 昆明 650221)
一、机器学习概述
主流的机器学习算法包括支持向量机、神经网络、集成学习和逻辑回归。本节对这些算法的基本原理进行简要介绍。
(一)支持向量机
支持向量机(SupportVectorMachines,SVM),其早期工作来自前苏联学者VladimirN.Vapnik和AlexanderY.Lerner在1963年发表的研究,是一类按监督学习方式对数据进行分类的广义线性分类器。其核心思想即,二维数据分布在样本空间上,由一个超平面对多维数据进行分割,这个平面叫做分类的决策边界,支持向量就是离决策边界最近的一些点,支持向量机的目的就是最大化支持向量到决策边界的距离,从而,如果数据犯错的话,分类器会尽可能的健壮。
当遇到多维或者复杂数据时,就需要引用核函数将数据转换成易于分类器理解的形式,其中最流行的一种成为径向基函数(radialbasisfunction),利用核函数讲数据映射到高维空间,可以将在低维空间中的非线性问题转换成高维空间下的线性问题来求解。支持向量机是一个二分类器,当用其解决多分类问题时,则需要额外的方法对其进行扩展。SVM效果取决于优化参数和和函数中的参数设置。
(二)神经网络
1958年,计算科学家Rosenblatt提出了由两层神经元组成的神经网络。他给它起了一个名字——“感知器”(Perceptron),也就是单层神经网络,它由一个输入层和输出层组成,每一个特征属于代表一个神经单元,输入层只负责传输数据,不做计算。在输出层则需要对前一层的数据进行计算,连接输入层和输出层的带有箭头的线表示一个权重,预测值则是输入和权值之间的线性加权和叠加了一个激活函数g的值,即Z=g(W*a),在单层神经网络中,g函数使用sgn函数,也就是取符号函数。这个函数当输入大于0时,输出1,否则输出0。
但是Minsky在1969年出版了一本叫《Perceptron》的书,里面用详细的数学证明了单层神经网络的弱点,尤其是对异或这样的简单分类任务都无法解决[2]。
两层神经网络,在单层神经网络基础上,增加一个中间层,此时,中间层和输出层都是计算层,激活函数也由sgn变为sigmoid。我们将yp作为预测值,y为真实值,将loss=(yp-y)2定义为损失函数,因此我们做的工作就是让loss值尽可能的小,一般采用梯度下降法,直到梯度接近零,在神经网络中,由于结构复杂,每次计算梯度的代价很大。因此1986年,Rumelhar和Hinton等人提出了反向传播(Backpropagation,BP)算法,解决了两层神经网络所需要的复杂计算量问题。也就是经典的BP神经网络,反向传播法利用神经网络的结构,首先计算输出层的梯度,然后是第二个参数梯度,接着计算中间层梯度,再然后计算第一个参数的梯度,最后计算输入层梯度。尽管使用了BP算法,一次神经网络的训练仍然耗时太久,而且困扰训练优化的一个问题就是局部最优解问题,这使得神经网络的优化较为困难。同时,隐藏层的节点数需要调参,这使得使用不太方便。
多层神经网络,随着计算机硬件性能提升(如GPU图形加速卡),在二层的基础上,中间层的层次继续扩张,参数也随之增加,通过研究和实践发现,更深的网络层次往往比浅层有更好的识别率,这点在ImageNet大赛上获得的证实。因为通过每一层,对前一层的抽象表示更加深入。ReLU函数(f(x)=max(0,x))在训练多层神经网络时,更容易收敛,并且预测性能更好。
(三)集成学习
俗话说,三个臭皮匠顶个诸葛亮,这就是元算法的思路,集成学习就是对其它算法进行组合的一种学习方式。集成方法主要包括Bagging和Boosting两种方法。Bagging方法即在原始样本中,根据Bootstraping方法,随机抽取一部分数据集作为训练数据,一共抽取K次,每一次的训练集训练出一个模型,一共训练出K个模型,最后再由K个模型投票得出结果,如果是对于回归问题,则计算K个模型的均值为最后的结果[3]。Boosting则是每一轮训练集相同,但是会赋予训练集一个权重,根据模型的错误率来调整权值,错误率越高,权值越高。其中具有代表性的AdaBoost分类器,具有泛化错误率低,可以应用在大部分分类器上,无需调参。但是对离群点敏感等特点。
二、数据说明
本文数据来自国内某款流行竞技游戏官网RiotAPI中,通过玩家ID获取到前十分钟的游戏状态数据,玩家水平控制在一定范围,即代表玩家水平大致相同。本数据集收集了共19项状态数据,一共38项(红蓝两方玩家)。
数据集状态属性包括19项,共38个,分别是blueWardsPlacedDestroyed,blueFirstBlood,blueKills,blueDeaths,blueAssists,blueEliteMonsters,blueDragons,blueHeralds,blueTowersDestroyed,blueTotalGold,blueAvgLevel,blueTotalExperience,blueTotalMinionsKilled,blueTotalJungleMinionsKilled,blueGoldDiff,blueExperienceDiff,blueCSPerMin,blueGoldPerMin。以上状态特征除blueFirstBlood为分类变量,1为是,0为否,其它均为连续变量。目标变量为blueWins,是否取胜。数据集一共包括9879个样本。
三、得分预测
(一)数据处理步骤
1.读取数据
使用python中的csv包,读取样本数据文件‘high_diamond_ranked_10min.csv’,同时引用numpy包,创建训练数据矩阵和标签矩阵,遍历样本数据,将特征一一读取到训练举证,同时读取每一个样本数据中的标签,将其添加到标签矩阵。自此,已经建立了训练数据。接着我们分析该矩阵的数据特点。
2.归一化
由于blueTotalGold,blueAvgLevel,blueTotalExperience,blueTotalMinionsKilled,blueTotalJungleMinionsKilled,blueGoldDiff等几个特征数值偏大,有的甚至是周围值的几千倍,不同指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理。在本文中,采取将数据做线性变换,使结果值映射到[0-1]之间。
经过归一化处理后,各指标处于同一数量级,便于综合对比。同时,求最优解的过程会变得平缓,更容易正确收敛。即能提高梯度下降求最优解时的速度,提高计算精度。此过程使用SK-Learn包中的preprocession函数完成。自此数据处理大致完成,如果还需要调整的话,可以根据实验最后的精度来做下一步分析。
预测模型
本文采用泛化程度较高的AdaBoost分类器来完成预测工作。其伪代码如下:
对每次迭代:
利用buildStump()函数找到最佳的单层决策树
将最佳单层决策树加入到单层决策树组
计算alpha
计算新的权重向量D
更新累计类别估计值
如果错误率等于0,则退出循环
使用SK-Learn中的AdaBoost模型,分类器选取DecisionTreeClassifier,最后,训练结果如图所示:

结果解释:可以看到使用AdaBoost模型,参数取以上值时,通过交叉验证,最佳参数为,决策树参数最高3层,其它参数由于样本特征,均为默认值,基分类器提升(循环)次数n_estimators为1000次,模型提升准则选择SAMME。AdaBoost其它参数均为默认值。分类器在训练集上的错误率为26.26%,在测试集上错误率为27.46%,可以看出并没有过拟合,模型拟合效果比较合适。整体预测准确率为72.5%。
四、预测模型的评价
在机器学习算法中,模型本身所需要的假设比较少,相应地,对模型进行评价的工具也不多,通常只能通过对模型的预测结果与真实结果进行比较来判断模型的预测精度。
在本文中,得分预测是属于分类问题。对于分类问题,预测精度的评价指标主要有查全率和查准率,AUC值和F值。

混淆矩阵
模型的精度,即模型预测正确的个数/样本的总个数
召回率,真正类率,表示的是,模型预测为正类的样本的数量,占总的正类样本数量的比值:
一般情况下,Recall越高,说明有更多的正类样本被模型预测正确,模型的效果越好。除了上述的评价指标,另一个用于度量分类中的非均衡的工具是ROC曲线(ROC curve)。
本分类器ROC曲线如下图:
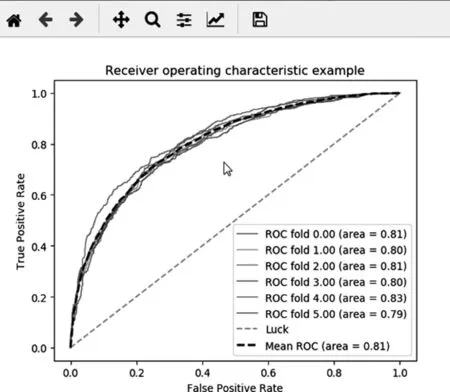
ROC曲线是从[0,0]到[1,1]的上凸曲线。ROC曲线越趋近于左上角的[0,1]点,说明分类器的效果越好。ROC 曲线下方的面积称为AUC值,AUC介于0到1之间,当AUC小于0.5时,说明分类器的效果不如随机预测的效果; AUC 越接近于1,说明分类器的效果越好。本实验中,随机将样本集划分6次,平均AUC值如图所示,为0.81,证明模型能够有效预测比赛胜负。
五、小结
通过实验,可以证明基于AdaBoost模型的某竞技游戏胜负分类器是有效的,平均AUC为0.81左右,不同的训练模型对数据的拟合效果有时差距是非常大的,所以本文后续工作还可以应用更加合适的模型来提高其精度,比如可以利用回归分析,对特征相关度进行分析,根据分析适当增加或降低模型复杂度,可以提高分类准确率,本文由于篇幅有限,不再做赘述。
电子竞技是随着行业越来越规范和飞速发展,无论是个人电脑端还是手机端,每天都有大量的数据产生,本文仅对其中游戏类中的一个小方向做了简单分析。机器学习,深度学习,强化学习模型作为一种工具已经在许多领域取得了良好的应用效果,如语音,图片识别,自然语言处理等领域中大放光彩。去年,腾讯AILab实验室研发的虚拟角色在2100场游戏对抗中,取得了99,8%的获胜率,让我们的认知不仅仅停留在alphaGo大战围棋高手,而电子竞技作为一项体育运动,不论在专业领域和普通玩家中,都深受喜爱,从前文的报告中,在2020年,电竞整体规模有望达到1300亿元,但是相关研究并没有成型,希望本文是抛砖引玉,今后的学习中能够有更多的研究应用到电竞行业。最后,机器学习以及其后面一系列学习模型算法作为一种新兴的预测模型,在电子竞技行业具有广阔的应用前景,对于提升用户游戏体验度,增强用户黏性,完善游戏内部机制,改善游戏生态有着重要的应用价值。
