涉黑涉恶类警情的特征分析方法研究
2020-07-14邱明月崔年冬
邱明月 崔年冬
关键词 自然语言处理 涉黑涉恶 警情 Python I2
基金项目:中央高校基本科研业务费专项资金项目:基于NLP的涉黑涉恶警情的特征分析与可视化研究(编号:LGYB2 02012)。
作者简介:邱明月,南京森林警察学院,讲师,博士,研究方向:数据挖掘、公安情报学;崔年冬,南京森林警察学院公安情报学学生。
中图分类号:D631 文献标识码:A DOI:10.19387/j.cnki.1009-0592.2020.06.340
一、背景
伴随着大数据时代的到来,大数据在社会的各个领域都得到了广泛的应用。现如今,大数据是朝着“未来社会发展的趋势”发展,习总书记也不断强调了科技以及大数据在公安工作中的应用前景,将大数据战略提升到了国家的层次。在目前公安行业对大数据与人工智能等热门关键技术应用的过程中,充分利用了业务系统产生的结构化数据,如人员数据、轨迹数据、交通数据等。但是近些年来黑恶势力犯罪形式的不断变化又给公安机关开展工作带来了不少的挑战。
当今社会随着现代信息技术的发展和普及,使得黑恶势力犯罪分子具有过去多得多的犯罪手段、方式和犯罪环境。犯罪分子的高学历化、高智商化,犯罪工具的现代化、智能化趋势让现在的扫黑除恶工作越来越难开展。他们利用现代网络设施和交通工具,使得作案的空间和时间都得到空前的扩展和延伸。犯罪分子进行有组织的团伙作案,利用现代化的手段逃避公安机关的追查的趋势也越来越明显。因此,公安机关实战部门如何利用好大数据技术来打击黑恶势力犯罪成为当今政府部门以及全社会关注的热点问题。
2018年1月中旬, 党中央和国务院部署了《关于开展扫黑除恶专项斗争的通知》,从而决定在全国范围内开展一项为期三年的扫黑除恶专项斗争。这个经历是这一阶段进行十多年打黑除恶斗争后,对黑恶暗黑势力展开的一场更全面更深入更有效的打击斗争。涉黑犯罪是我国社会治理中面临的重大挑战,在全球化网络时代,如何利用大数據打击黑社会犯罪已经成为各国政府所应解决的重大问题。
二、相关概念
(一)自然语言处理
自然语言处理是人工智能和语言学相结合的交叉学科,主要研究如何让计算机处理并应用人类语言。可以说,计算机视觉和语音识别是人工智能领域的感知智能,而 NLP 属于人工智能领域的认知智能,因而相对更难。在深度学习的发展过程中也与之类似,语音和图像提前获得突破,而 NLP 这两年才渐渐在机器翻译等领域大展身手。
(二)Python
Python是一种跨平台的计算机程序设计语言,是一种面向对象的动态类型语言。基于Python的网络爬虫十分完备,可以分布式、多线程地对网页进行抓取。Python提供了多个能实现http请求的功能模块例如urlib库、resquests库;以及可以解析网页页面的功能模块例如BeautifuleSoup库、lxml库等,可以很有效得实现对各种网页页面的抓取、数据采集的任务。
(三)网络爬虫
网络爬虫,是按照既定的规则自动抓取万维网信息的程序或者脚本,他们广泛地运用于互联网的搜索引擎或者其他类似的网站中。基本上可以分为4类:第一类是通用网络爬虫,指搜索引擎爬虫,类似于百度、谷歌等这种大型的搜索引擎,其特点是根据一定的策略,用特定的计算机程序,将互联网上的信息加以收集并对信息进行筛选和排序后展示给用户,搜索引擎由搜索者、用户界面、索引器和搜索器4部分组成。第二类是聚焦爬虫,是指可以有选择地爬取那些事先处理好的主题相关的网络爬虫,与一般形式的网络爬虫相比,聚焦网络爬虫需要爬取与主旨相关的内容,极大地节约了硬件和网络资源。第三类是增量网络爬虫,是指有间隔地进行信息收集,一段时间内重新爬取数据进行数据更新。第四类是深层网络爬虫,深层网络需要通过登录提交数据后,才能进行页面提取信息。
三、警情数据的预处理与筛选
从基层公安部门获得的原始数据来源各异,表示方式也不尽相同,还会有很多字段值的缺失等情况出现。所以在收集到人员的各类数据之后,需要进行指标的预处理与筛选。指标的预处理是一项重要的工作,直接影响到模型的准确性与可用性。如果直接未经筛选将全部的数据导入预测模型,会造成模型的多余、运行的速度减缓以及预测的准确度下降等不同问题。因此,我们在模型运算之前,将指标数据的筛选和预处理是一项重要的难点工作。由于数据样本中影响因素繁多且数量较大,还有缺失值的出现,容易导致分析的结果很难达到一个较为准确的水平,所以需要首先进行数据指标的预处理工作。数据的预处理可包括属性指标量化、数值化赋值、缺失值处理以及数据归一化处理等。比如:按出生日期将犯罪嫌疑人的年龄分为老年、中年、青年三种类型,制定出指标的分类变量。根据犯罪嫌疑人的性别,1表示“男”,2表示“女”。将指标进行数值化赋值。然后,将经过归一化处理过的数据输入到后续的模型中。
在涉黑涉恶类警情分析中,有些指标因素相对于人员涉黑涉恶行为的发生影响是具有相关性的。可以通过模糊数、相关分析等处理与筛选出具有代表性的影响指标。这样,通过小部分的指标就可以进行某些预测,目的用来提高模型的准确度。同时,可以针对这些变量进行特征分析,对影响犯罪的重要因素进行排序,得出影响涉黑涉恶案件的犯罪因素的重要性顺序表。
四、基于NLP的涉黑涉恶类警情的特征分析与可视化
(一)涉黑涉恶类数据的预处理
属性指标量化:将采集到的属性指标进行量化,可通过模糊数来进行区间划分。
数值化赋值:采集到的人员指标中如果有连续性的数据,可以通过运用连续函数进行数值转换。例如:对于活动轨迹和前科记录这样具有时间特征的连续性数据,可以运用连续函数对其进行赋值。
缺失值处理:数据采集中,缺失数据的情况时有发生。由于缺失值对于之后的对模型的准确性与可用性影响较大,所以应采用科学有效的方法进行填充。填充方法包括:人工填充、特殊值填充、关联规则填充以及其他众多的统计以及数据挖掘算法进行填充。
数据归一化处理:由于采集到的数据范围不同,所以对数据做归一化处理,以加快模型的收敛以及预测的准确率。
(二)涉黑涉恶类案件词库的建立
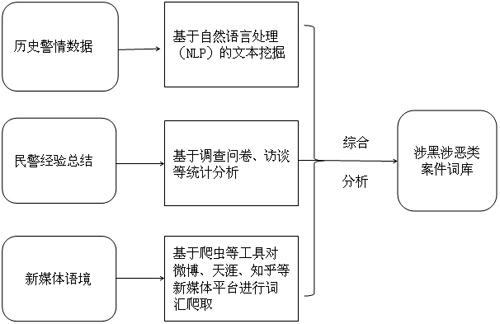
通过如图1三种方式建立涉黑涉恶类案件词库:
1.基于历史警情数据的文本挖掘。通过收集到的历史相关警情案件数据,运用自然语言处理等方式对关键词进行提取与分析。
2.基于基层民警经验总结分析。通过调查问卷、座谈访问等方式,对基层民警关于涉恶涉恶案件的词汇进行经验总结。
3.基于新媒体语境的网络爬虫。通过网络爬虫等工具,对微博、天涯、知乎等新媒体主流平台进行涉黑涉恶类词汇的网络爬取。
图1:涉黑涉恶类案件词库的建立
(三)重要性特征排序与可视化呈现
通过人工神经网络模型、决策树模型等对涉黑涉恶类警情进行重要性分析与排序。训练样本:通过数据预处理后的70%数据用作训练模型的样本数据。根据人工神经网络等模型的自适应等特点,对样本数据的内在的潜在规律进行机器学习。模型运用:将训练好的模型对案件的重要性特征进行分析。用剩余的30%数据作为测试样本输入模型中进行测试,以检验模型的预测效果。随后,运用Python、I2等技术对上述数据库进行实时动态连接,以保证动态化警情数据特征能够得到实时反馈。
五、结语
涉黑涉恶警情的特征分析不仅可以对基层公安工作提供有力的数据参考,也使得公安大数据在实际的公安工作中得到有效的运用。通过运用自然语言处理、人工神经网络模型等模型算法,将采集到的与涉黑涉恶案件相关的大量指标数据进行分析,并推断出影响涉黑涉恶案件的重要指标与影响因素。运用案件的相关特征做出可视化云图,以指导公安机关的警力部署,提高出警效率和质量。
参考文献:
[1]廣东省扫黑除恶专项斗争领导小组,省委政法委.应对三个难题 统筹强力攻坚 深入推进扫黑除恶专项斗争打击工作[N].人民公安报,2018-10-19(003).
[2]杜晓旭,贾小云.基于Python的新浪微博爬虫分析[J].软件,2019,40(4):182-185.
[3]张昌繁,陈利高,刘晓波,龚建.基于NPL-NMC系统的 测量子系统的建模与优化[J].原子能科学技术,2016,50(4):698-704.
[4]张继光.许渊冲研究现状的可视化分析及其启示[J].西安外国语大学学报,2020,28(1):87-92.
