基于Res-Bi-LSTM的人脸表情识别
2020-07-06梁华刚王亚茹张志伟
梁华刚,王亚茹,张志伟
长安大学 电子与控制工程学院,西安 710064
1 引言
面部表情是最有力和自然的表达感情状态的方式之一。由于表情识别在人机交互、临床医学、安全驾驶等方面有着广泛的应用,目前已有大量关于表情识别的研究。早在20 世纪,文献[1-2]定义了6 种基本表情类别:愤怒、厌恶、恐惧、快乐、悲伤和惊讶。
传统的表情识别方法主要采用手工提取特征,如LBP、HoG、SIFT等,然而这些特征无法解决影响表情识别的多种因素。随着深度学习的发展,卷积神经网络被应用到表情识别中,并取得了显著的成果。Mayya 等人[3]提出了基于深度卷积神经网络的表情识别的方法并达到了较高的准确率。Connie等人[4]采用混合CNN-SIFT网络实现表情识别,并在FER-2013、CK+、SFEW2.0 三个公开数据集上实现了较高精度。Bargal 等人[5]采用VGG13、VGG16、Resnet 三个不同的网络提取表情图像的特征,并将特征融合使用支持向量机SVM 实现分类。梁华刚等人[6]提出自适应Gabor卷积核编码网络的表情识别方法,对传统的Gabor 核进行改进,提高了识别率。
上述方法主要基于静态表情进行外貌特征提取,然而表情的表达是一个动态的过程,视频序列间拥有丰富的信息,在人脸表情识别中起着重要的作用。考虑到视频序列间的关系,也有一些学者在这方面做了一定的研究。Zhao 等人[7]提出了一种基于Peak-Piloted 的表情识别方法(PPDN),使用峰值表情样本(简易样本)来监督相同类型的非峰值表情(硬样本)样本的中间特征响应,实现表情强度不变性。Yu等人[8]提出了一种更深的级联peak-piloted的弱表情识别方法(DCPN),增强了特征的辨别力,同时采用级联微调的方法避免过拟合。Khorrami等人[9]使用CNN和RNN对视频数据进行维度情感识别,同时还分析了每个网络在整体模型中的重要程度。Jung 等人[10]提出了基于两种不同模型的联合微调网络(DTAGN),其中一个深度网络从图像序列中提取时间外观特征,另一个网络从时间面部关键点提取时间几何特征,最终提高了表情识别的精度。Vielzeuf 等人[11]研究了多模态输入下的表情识别,模型包括音频、VGG-LSTM 和C3D-LSTM 三种模态,然后将特征进行融合分类,最终在野生数据库上实现了高精度。虽然视频表情识别已经取得了一定的效果,然而传统的RNN、LSTM 网络不能有效地学习序列表情前后间的相关信息,导致最终识别率较低。
综上所述,为了更好地学习表情的空间特征和时间特征,增强LSTM 的时序特征的学习能力,同时为了避免LSTM单元过多时存在梯度消失的问题,本文提出了一种基于Res-Bi-LSTM 的表情分类方法。该方法采用Inception-w卷积神经网络进行人脸空间特征提取,该网络在Inceptin-V3的基础上进行改进,可以充分提取表情的空间特征,同时为了防止过拟合,增加了两个Reduction模块;然后每一帧相应的特征被送到残差双向长短期记忆网络Res-Bi-LSTM 学习帧间的时序特征,该网络不仅可以学习序列间的双向相互关系,而且采用残差块可以避免LSTM梯度消失的问题,提高了识别的准确率。最后,通过全连接层softmax 分类器实现视频表情的分类。
2 基于Res-Bi-LSTM模型的表情识别
本文设计的表情识别模型共包括两个部分,分别为Inception-w 和Res-Bi-LSTM。其中,Inception-w 网络学习表情视频帧的空间特征,Res-Bi-LSTM学习视频帧的时序特征并分类,网络结构图如图1所示。
2.1 特征提取
特征提取网络把连续视频帧作为输入,然后通过卷积池化层学习人脸表情的空间外貌特征。本文在特征提取时采用Inception-w 网络,其中CONVS 由五个卷积层和两个最大池化层组成,网络最后用全卷积层(FC)代替全连接层,可以减少网络模型的参数。该网络包括三个不同的Inception 模块,即Inception-A、Inception-B、Inception-C,这些模块与Inception-V3[12]网络中相同,采用并行的卷积核进行特征提取,最后再把不同卷积核提取到的特征进行融合。为了减少网络的参数,加快网络的训练速度,本文在原来的Inception-V3 中分别添加Reduction-A和Reduction-B,该模块最早在论文[13]中被使用,该网络的整体结构图如图2所示。除此之外,本文采取辅助神经网络可以防止梯度消失,加速网络收敛。
其中输入视频帧的大小为229×229×3,经过卷积层CONVS 进行特征提取得到35×35×288 的特征图,该模块采用3×3 的卷积核和最大池化。然后将CONVS 得到的特征图依次输入到Inception-A、Inception-B 和Inception-C中进行特征提取,最后通过两个全卷积层生成N×256 维的深度特征矩阵用来传输到Res-Bi-LSTM中学习时序特征,N表示视频帧的个数,由于本文在不同的数据集下进行实验,所以N的取值不同,其中在CK+数据集下训练时N=18,对于Oulu-CASIA 数据集N=22。
2.2 Res-Bi-LSTM
深度残差网络在2015 年的ILSVRC 比赛上获得了图像分类、检测和定位的三项冠军,该网络采用恒等映射的残差块,有效地解决了神经网络随着深度的增加引发的退化问题,提高了准确率的同时使网络更容易训练[14]。由于深度残差网络在特征提取中得到了广泛的应用,Zhao等人[15]提出了深度残差双向长短期记忆网络来处理序列问题,并在行为识别方面进行实验,实验表明该网络可以解决深层网络梯度消失的问题,提高了行为识别的准确率,因此本文将该网络应用到表情识别中。

图1 基于Res-Bi-LSTM模型的表情识别框架
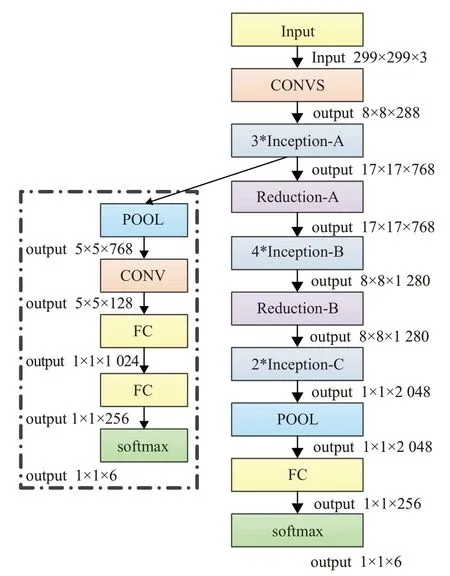
图2 Inception-w模型
传统的LSTM 只能根据前面的信息推出后面的信息而不能使用未来信息预测,因此提出了Bi-LSTM。Bi-LSTM既可以使用某个输入中的历史数据,同时也可以使用该输入的未来数据,其原理结构图如图3所示。
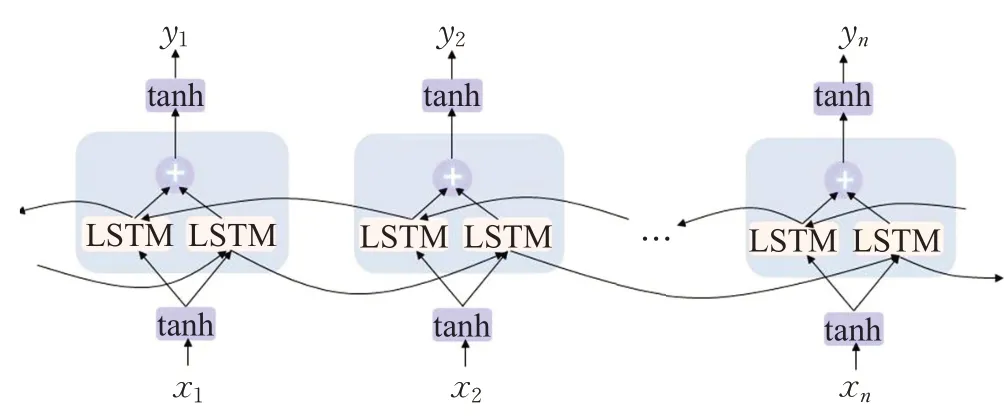
图3 Bi-LSTM的网络模型
假设图3中前向传播的序列为f,反向传播的序列为b,给定特征图的输入为(x1,x2,…,xn),则Bi-LSTM的计算公式如下式(1)~(3)所示:

Res-Bi-LSTM 的结构图如图4 所示。由图可知,信息在水平方向(时间维度)和垂直方向(空间维度)上流动。除了输入和输出层之外,有两个残差块作为隐藏层。每个残差块包含2 个Bi-LSTM,所以共包含8 个LSTM单元,本文采用ReLU 激活函数。Res-Bi-LSTM 能够融合累积相邻帧间的特征,获取整个表情帧上的叠加时间信息,最终通过softmax 分类层来判断最终表情的类别。由于空间特征提取网络最终得到256 维的特征向量,因此本文设置了256个Res-Bi-LSTM单元。
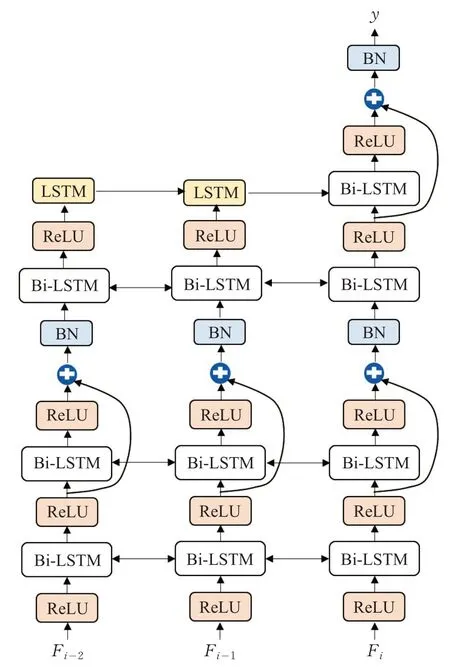
图4 Res-Bi-LSTM的网络模型
3 实验结果及分析
3.1 实验数据集
本文在CK+[16]和Oulu-CASIA[17]两个公开的人脸表情数据集上进行实验。其中,每个数据集的介绍如下所示,如图5展示了这两个数据集下的不同表情的部分样本,第一行来自CK+表情数据库,第二行来自Oulu-CASIA数据库。

图5 部分CK+、Oulu-CASIA数据库样本
CK+:Extended CohnKanade(CK+)数据库是表情识别中的最具代表性的数据库。该数据库包含来自123个受试者的593 个视频序列,其中来自118 个受试者的327个序列被标记为7个基本标签(愤怒、蔑视、厌恶、恐惧、快乐、悲伤和惊讶),本文实验中只对除轻蔑以外的6种基本表情进行研究。在这个数据库中每个视频序列开始于中性表情,结束于峰值表情。
Oulu-CASIA:Oulu-CASIA 数据库包含在 3 种不同的照明条件下(明亮、弱光、黑暗)和两个成像系统(近红外和可见光)的2 880 个图像序列,其中可见光照下有480 个序列。这些序列被注释为6 个基本情感标签:愤怒、厌恶、恐惧、快乐、悲伤和惊讶。与CK+相同,该数据库第一帧是中性表情,最后一帧为峰值表情。本文选用可见光下的480个序列进行人脸表情识别。
3.2 数据预处理
一般情况下表情识别的数据预处理部分包括人脸检测、人脸对齐、数据增强这三步,然后将预处理后的图片进行网络训练。由于图像序列的长度是变化的,而深度学习网络的输入是固定的,因此先将图像序列归一化为固定长度。本文将CK+和Oulu-CASIA这两个数据库上的表情分别归一化为18和22的序列长度。对于长度大于平均长度的,采用均匀采用的方式进行归一化,对于长度小于平均长度的,本文对最后一帧进行复制,将其转化为平均长度的大小。然后采用多任务级联卷积网络(MTCNN)[18]进行人脸检测和对齐,该操作可以避免脸上头发、眼镜以及头部姿势等因素的干扰,提高人脸表情识别的精度。首先提取出两只眼睛的坐标并保持两眼间距离不变,裁剪出相应的人脸,尽可能减少人脸周围无关因素(如头发、首饰、人脸轮廓)对表情识别的影响。本文裁剪出来的人脸呈现矩形,然后采用0填充将其填充成正方形,再将输入视频帧标准化为229×299 的大小。人脸检测和对齐的结果如图6 所示,其中第一行表示CK+数据集的六种表情下的数据,第二行是Oulu-CSIA下的6种基本表情的样本。
深度神经网络需要充足的训练样本才能确保良好的泛化性,然而表情数据库样本较少,在训练时容易产生过拟合的问题,为了防止过拟合,数据增强在表情识别中是必要的。首先在−15°、−10°、−5°、5°、10°和15°这6种不同角度下旋转图像序列,然后对原图和旋转后的图像进行水平翻转,这样可以增强模型在输入图像存在小幅度旋转的情况下的鲁棒性。 通过图像增强后本文获得了原来14 倍的数据,即原始图像序列(1),水平翻转图像序列(1),6个角度的旋转图像序列以及它们的翻转图像序列(12)。如图7 为在CK+数据集上数据增强的结果。

图7 图像增强结果
3.3 网络参数设置
本文特征提取网络使用Inception-w网络,由于该网络比较深,而人脸表情数据集的样本较少,容易出现过拟合的现象,所以本文先在大规模人脸数据集CASIA Webface[19]上对Inception-w 网络进行预训练,其中辅助分类器损失函数的权重设置为0.4。然后使用表情数据集对网络进行微调。CASIA Webface包含来自10 575个实验者的494 414张训练图片,训练时初始化的学习率设置为0.01。微调时本文固定CASIA Webface 上得到的预训练模型卷积层的参数值,通过表情识别数据对网络的最后两层全连接层进行微调,全连接层的初始化参数使用“xaiver”[20]进行随机初始化,且学习率设置为0.000 1。
本文模型采用随机梯度下降的方法来优化网络参数。其中训练时的权重衰减参数设置为0.000 04,动量设置为0.9,批次大小设置为32,dropout设置为0.5,最终在迭代20 000次后得到网络模型。
3.4 特征可视化
为了理解Inception-w网络学习到的特征,本文选取CK+数据集多帧图片进行特征可视化。如图8 对应的表情标签是惊讶,由左至右分别对应一段表情视频的第1、5、10、18帧,即表情由中性表情变化至峰值表情的过程。由上往下分别对应卷积层3、卷积层5、Inception-A和Inception-B提取到的特征。由图可以看出,位于较浅位置的神经元从输入中提取的是较为简单的一些特征信息,而随着层次的加深,神经元将提取愈加复杂的特征信息,从而使得神经网络能够做出更准确的判断。

图8 特征图
3.5 实验及结果分析
本文实验的硬件环境为64 位的Ubuntu16.04.1LTS操作系统,CPU为Intel i7-6700k 4.00 GHz,显卡型号为NVIDIA GeForce GTX1070,显存为8 GB。 深度学习框架采用谷歌开发的Tensorflow框架。为了能得到准确的实验结果,本次实验采用10倍交叉验证(10-fold crossvalidation)的方法。将CK+数据集平均分成10组,轮流选取其中九组数据作为训练集,另外的一组数据作为测试集,共进行10次实验,最后结果的准确率是10次实验结果的平均值。Oulu-CASIA数据集采用与CK+相同的方法进行训练。
人脸检测对人脸表情识别精度的提高有一定的作用,因此本文对人脸检测的影响进行分析。本文使用MTCNN人脸检测网络在CK+和Oulu-CASIA两个数据库上进行人脸检测的实际检测结果和理论检测结果的对比如表1 所示,其中检测精度是原论文中MTCNN 的准确率。由表1 可知,在CK+和Oulu-CASIA 两个数据集上,实际的检测结果约为99.6%。因此,在实验环境下人脸检测的准确率接近于1,人脸检测的漏检率和误检率基本可以忽略掉。尽管对比实验中采用的人脸检测方法略有不同,但是依然可以保证实验的公平公正性。

表1 人脸检测对比结果
3.5.1 CK+实验结果
在CK+数据集上,通过对10%的样本进行测试,本文提出的网络模型精度达到99.6%。明显超过了其他方法,说明本文方法在对序列表情识别的有效性。不同方法的精度对比如表2所示。

表2 CK+数据库分类准确率对比
为了评价Res-Bi-LSTM 的有效性,本文进行了两组实验。由表2 可知在卷积神经网络的基础上增加Bi-LSTM 可以明显地提高表情识别的准确率。此外本文也对Inception-w+Bi-LSTM和Inception-w+Res-Bi-LSTM进行了对比实验,最终实验表明本文方法比Inception-w+Bi-LSTM网络识别提高了一个百分点,因此本文方法可以提高动态表情识别的准确率。
为了便于观察各个表情之间的识别率,本文制作了CK+数据集测试结果的混淆矩阵,其中对角线表示不同表情识别的正确率,如表3所示。

表3 CK+数据库混淆矩阵 %
表3中第一列表示表情的真实标签,第一行表示表情的实际预测结果。由混淆矩阵可知本文模型对生气和惊讶的识别精度最高,其他的识别结果次之。其中生气、悲伤、厌恶这3种表情的识别结果往往相互交叉,这主要是因为现实生活中这3种表情基本相似,都具有相同的眉毛、嘴角特征等。而恐惧易被错误的预测为高兴或惊讶,这主要是因为恐惧、高兴和惊讶都是嘴巴微张。由此可见表情识别是一个复杂的研究。现实生活中人脸表情往往不是单一的,有时候是多种表情混合出现的,例如生气的同时产生厌恶之情,高兴的同时产生惊讶等,使得表情识别的难度大大增加。
3.5.2 Oulu-CASIA实验结果
本文模型除了在CK+数据库上进行实验外,还在Oulu-CASIA 数据库上做了实验,与CK+相同均采用十倍交叉验证进行实验,精确率达到89.39%。不同方法分类准确率的比较如表4所示。由表4可知本文模型超过了现有模型的精度,说明了本文提出方法在表情识别上的有效性。

表4 Oulu-CASIA数据库分类准确率对比
同CK+一样,为了验证Res-Bi-LSTM 的有效性,本文在Oulu-CASIA数据库也进行了两组实验。对比表4中Inception-w和Inception-w+Bi-LSTM可以明显的知道Bi-LSTM对时序特征提取的有效性。此外Inception-w+Res-Bi-LSTM在Oulu-CASIA数据库上的识别准确率为89.39%,相比Inception-w+Bi-LSTM 而言,提高了2%以上,因此本文方法可以提高动态表情识别的准确率。Oulu-CASIA数据库的混淆矩阵如表5所示。

表5 Oulu-CASIA数据库的混淆矩阵%
表5为本文算法在Oulu-CASIA数据库上的混淆矩阵,由于该数据集的干扰因素较多,所以整体的识别率较低。其中生气的识别率最低,这主要是因为生气和厌恶、悲伤等表情间有很大的相似性。厌恶、恐惧、悲伤的识别率次之,分别为87.82%、89.06%和89.94%,惊讶的识别率最高。结合该混淆矩阵也充分说明了表情识别的复杂性和难度。
4 总结
本文提出了一种基于Res-Bi-LSTM 模型的人脸表情识别算法。首先通过Inception-w 网络来提取视频帧的人脸外貌特征信息,然后采用Res-Bi-LSTM神经网络学习帧间的时序特征信息,最后采用softmax 分类器对表情进行分类。实验结果表明本文提出的模型可以在CK+和Oulu-CASIA两个公开数据集上达到了较高的识别率,超过了现有方法。但是本文算法也存在一定的缺陷,例如本文模型只在理想的实验数据集上进行了实验,而现实生活中表情识别的干扰因素众多,因此在AFEW等野外数据库上的研究将是未来的研究重点。
