国产全文数据库测试指标及测试方法研究
2020-06-24杨美钰付玉涛
杨美钰 付玉涛


摘要:随着大数据的发展,对数据存储、数据查询响应时间的要求越来越高,MPP数据库(大规模并行处理数据库)、全文数据库、图数据库等成为大数据应用所需产品。本文针对国产全文数据库提出一套从全文数据库功能、接口、可管理性、可靠性、可扩展性和性能进行客观评价的测评指标及其测试方法,为选用国产化全文数据库提供一套依据,为指导产品的研发和性能的不断改进提供指导意义。
关键词:大数据;国产化;全文数据库;测评指标
引言
随着当前对数据挖掘、数据分析的需求越来越大,对数据规模、数据查询响应速度等的要求越来越高。从数据结构来看,数据主要分为结构化数据和非结构化数据,本文主要针对非结构化数据的存储与检索进行研究。对于非结构数据的检索,基于Hbase[1]的设计,比较占空间,硬件配置要求比较高,且在ID超过200之后,查询性能直线下降,很难符合线上的要求。ElasticSearch[2](以下简称ES)基于Lunce,优点是搜索速度快,方便建立索引。本文针对基于ES设计的全文数据库进行研究。
当涉及到选购全文数据库时,对其功能、接口、可管理性、可靠性、可扩展性、性能的客观评价还缺少相应的依据。因此,建立一种合理、适用性强的全文数据库测评指标及其测试方法意义重大,帮助用户评估和选型全文数据库的同时,对产品性能的不断改进有着重要的意义。本文依据全文数据库的特点,提出了一套关于国产全文数据库功能、接口、可管理性、可靠性、可扩展性、性能的测评指标,为广大用户选用和评价国产全文数据库提供方法。
一、全文数据库简介
(一)数据、检索的分类
我们生活中的数据总体分为两种:结构化数据 和非结构化数据。
结构化数据: 指具有固定格式或有限长度的数据,如数据库,元数据等;非结构化数据: 指不定长或无固定格式的数据,如邮件,word文档等。
按照数据的分类,搜索也分为两种:对结构化数据的搜索 :如对数据库的搜索,用SQL语句。再如对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。对非结构化数据的搜索:如利用windows的搜索也可以搜索文件内容,如用Google和百度可以搜索大量内容数据。
(二) ES简介
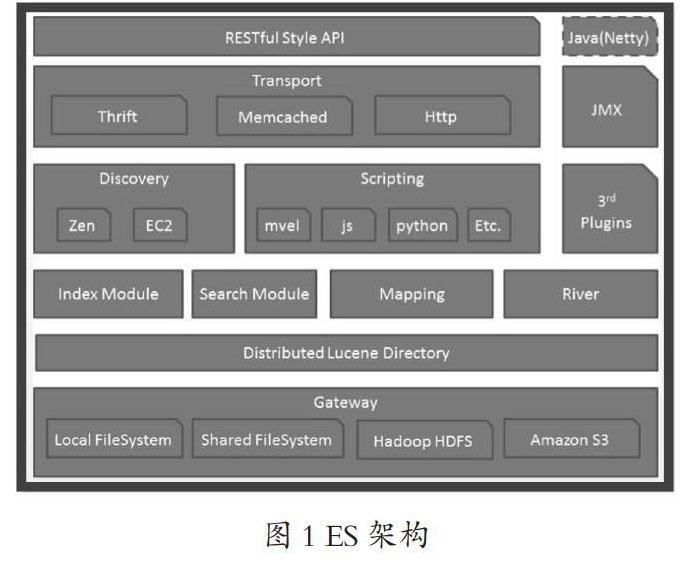
1 ES架构及与传统数据库的区别
ES是一款分布式全文检索框架,底层基于Lucene实现,其架构如图1所示。
ES与传统数据的区别主要有:
1)结构名称不同:一个ES集群可以包含多个索引,每个索引又包含了很多类型,类型中包含了很多文档,每个文档使用JSON 式存储数据,包含了很多字段。
2)ES采用分布式搜索,传统数据库进行遍历式搜索。
3)ES采用倒排索引,传统数据库采用B+树索引。
2 ES基本概念
集群:指的是一个或者多个节点(服务器)的集合,这些节点会一起保存数据,并且会在所有的节点上提供联合索引和搜索的功能。一个集群通常会被一个名字所标示,必须说明的是,确保不要在不同的环境中使用相同的集群名称。否则节点可能会加入错误的集群。
节点:指的是一个集群中的单个机器,它存储数据、并且参与集群的索引和搜索功能,实际上就像一个集群。一个节点也是被一个名字所标示,其默认的名称是在节点启动时候的分配给他的唯一标示符(UUID)。一个节点可以通过一个集群名加入某一个集群。默认情况下,每一个节点都会加入名为ES的集群中。
索引:指的是一系列文档的集合,这些文档有着共同的特性和特征。
类型:在索引中,可以定义一种或者多种类型。一般而言,一种类型定义是为了给一个拥有共同的元素的集合。
文档:可以被索引的基本单元。例如,你可以拥有一个针对单个消费者的文档,另一个用于单个订单信息的文档。该文档以JSON(JavaScript Object Notation)表示,JOSN是一种无处不在的互联网数据的交换格式。
分片&副本:一个索引中可能存放非常多的数据,这些数据甚至有可能超越一个单节点机器的资源限制。例如一个索引中如果有十亿个文档的话将会占用多达1Tb的空间,而这些是无法从单个节点提供搜索请求的,因为这将十分缓慢。想要解決这个问题,ES提供了可以将你的索引分片的能力,这些分片成为切片。每当你创建一个索引的时候,你可以十分轻松的制定这个索引的分片个数。每个分片就是一个功能完整且独立的索引,当然,他们可以分布在集群的任意一个节点上。
二、 测评指标及方法
(一) 测试指标
2017年9月至2018年1月,项目组对阿里云、浪潮、拓尔思、星环科技等国内7个厂商的全文数据库进行了测试,并对数据库的业务应用进行了进一步的分析,为更加规范地开展未来全文数据库测试及符合性评价,依据GB/T16260《软件工程产品质量》和GB/T20273《信息安全技术数据库管理系统安全技术要求》,结合全文数据库自身的特点,制定了全文数据库产品的功能、接口、可管理性、可靠性、可扩展性、性能的测评指标体系,如图3所示。在实际测评工作中,用户可根据实际使用情况合理裁剪,以满足产品测试的个性化要求。
(1)功能指标:主要评价全文数据库应具有的基本功能。指标包括支持对二维表的管理,类SQL的查询语法,支持相关度排序,词库可配置,地理位置检索功能,支持时间、IP、数值、全文、地理经纬度、二进制等数据类型,支持算术、关系、逻辑等操作符类型,支持等值和区间两种分区计算,支持SQL方式进行表的管理、数据查询、二进制检索。
(2)接口指标:评价全文数据库的接口支持情况。指标包括支持SQL检索语法、支持Java和C加载接口、提供Shell交互接口。
(3)可管理性指标:评价全文数据库的基本管理能力。指标包括索引/表管理、用户权限管理、集群状态监控。
(4)可靠性指标:评价全文数据库是否支持副本策略,且不存在单点故障。
(5)可扩展性指标:评价全文数据库线性扩展的能力。
(6)性能指标:主要评价全文数据库的业务性能。指标包括数据加载、热数据查询、并发查询。
(二)功能、接口、可管理性、可靠性、可扩展性测试方法
对于功能、接口、可管理性、可靠性、可扩展性的测试指标的测试,测试方法及流程可概括为三方面:
(1)生成数据阶段:用于全文数据库功能、接口、可管理性、可靠性、可扩展性测试的数据准备;
(2)生成测试语句阶段:用于功能、接口、可管理性、可靠性、可扩展性测试;
(3)输出结果及分析:查看输出结果与预期结果的符合性。
(三) 性能测试方法
1 测试数据设计
测试数据采用通讯邮件数据,以.json文件进行存储,包括了14个常用业务字段类型,具体见表1所示。
2 数据加载测试方法
数据加载测试方法同样可归纳为三个方面:
(1)生成数据:根据设计的场景,搭建数据生成环境并生成200亿条数据;
(2)数据记载:执行数据加载语句,直至索引建立完毕;
(3)记录数据加载速率并核实入库数据量。
3 热数据查询、并发查询测试方法
(一)热数据查询
a.精确查询:基于入库的邮件数据,分别对字符串、IP类型、数值三种类型的数据进行精确查询;
b.全文查询:基于入库的邮件数据,分别对关键字、通配符、短语进行查询;
c.相关度查询:基于入库的邮件数据,进行相关度查询;
d.多个关键词查询;
e.聚合函数查询;
f.表达式查询;
(二)并发查询
准备查询语句执行并发查询,查看结果返回时间,例如:
Select * from d6 where subject=full_text("经理") limit 1000
三、结束语
本文从全文数据库的应用出发角度,提出了一套对其功能、接口、可管理性、可靠性、可扩展性、性能的客观评价的依据和测试方法,并针对数据加载、热数据查询、并发查询进行了测试,验证了测试方法的可行性。实际测评工作中,用户可根据实际使用情况合理裁剪,以满足产品测试的个性化要求。随着全文数据库应用的越来越广泛,还需在今后的大量实验和总结的基础上对性能测试做进一步的研究。
参考文献:
[1] 陈栋波,高跃明.基于HBase的海量文件的检索方案研究,设计研究与应用,2016
[2] 杨丽萍,张希翔,孟椿智,谢瑞浩.基于Elasticsearch的大数据搜索引擎在电力企业的应用研究,数字技术与应用,2017
作者简介:
杨美钰(1985-),女,山西运城人,桂林電子科技大学硕士,工程师。从事军用软件试验鉴定与研究工作。
付玉涛(1982-),女,山东聊城人,北京邮电大学硕士,工程师。从事军用软件试验鉴定与研究工作。
