领域本体驱动的招投标网页解析方法
2020-06-20马冬雪谢振平
马冬雪,宋 设,谢振平*,刘 渊
(1.江南大学数字媒体学院,江苏无锡 214122;2.江苏省媒体设计与软件技术重点实验室(江南大学),江苏无锡 214122;3.浪潮卓数大数据产业发展有限公司,江苏无锡 214125)
(∗通信作者电子邮箱xiezp@jiangnan.edu.cn)
0 引言
互联网已成为招投标活动的主要媒介,通过解析招投标网站的公示信息,可以为企业和用户提供有价值的信息,对征信、经济发展有着重要的意义。但是招投标网站众多、结构复杂,信息发布缺乏明确规范、形式灵活,计算机很难直接获取其中的结构化语义信息,需要通过网页信息解析技术实现有效内容的提取。
网页信息解析技术是指从网页信息文本中分析提取出真正想要的信息,排除噪声干扰,并将其形成结构化数据的过程[1]。广泛采用的解析方法[2-4]是通过构建相应的正则表达式模板实现网页信息抽取,然而构建高质量并且复杂度较高的正则表达式通常需要耗费大量的人工成本[5]。目前主要的自动化抽取技术有基于网页结构特征的网页信息抽取技术、基于包装器归纳方式的网页信息抽取技术、基于本体的网页信息抽取技术等。
由于招投标领域信息复杂,相关的研究较少,直接使用现有技术,方法适用性低,抽取粒度粗糙,不能满足系统需求;使用正则表达式,虽然能够满足用户的精确需求,但人工成本较大,灵活性差。为此,本文从招投标领域本体知识特点出发,通过构建轻量级领域本体,从招投标网页数据中抽取到精确有用的细粒度信息。
1 相关技术
信息抽取是从自然语言文本中抽取出指定的信息,将其转换为结构化文本的过程[6]。网页信息抽取是从网页文本中抽取出指定的一类信息并将其形成结构化数据的过程[7],主要有:
1)基于网页结构特征的信息抽取技术[8-9]。该方法首先根据超文本标记语言(Hypertext Marked Language,HTML)文档的结构特征信息,将HTML 文档解析为利于理解的语法结构层次树,然后通过自动或半自动的方式产生抽取规则,最后实现网页信息抽取。李效东等[10]基于文档对象模型(Document Object Model,DOM)树结构中的路径表达式来定位HTML 文档中待抽取信息,通过学习算法归纳抽取规则,使得对结构变化的文档有一定的适应能力。
2)基于包装器归纳的网页信息抽取技术[11]。该方法首先对样本网页进行标注,通过机器学习归纳出网页结构特征的抽取规则,然后自动分析待抽取网页的结构特征,最后实现网页信息抽取。王辉等利用中文知识图谱对网页数据项进行自动标注,建立具有容错能力的包装器归纳框架,从包含错误的标注集中归纳学习出正确的包装器,可获得良好的抽取效果[12]。
3)基于本体的网页信息抽取技术[13-14]。该方法首先建立本体,然后根据本体描述的概念、关系、层次结构以及概念关系间的约束等计算待解析信息的相关度,最后实现网页信息抽取。王放等[15]提出了一种人机交互式实现本体自学习构建和基于本体的Web 表格信息自动化抽取方法。目前基于本体的网页信息抽取研究已经开始与具体领域相结合,以解决领域内遇到的具体问题。李贯峰等[16]针对农业领域通过构建农业本体,实现农业领域的Web知识抽取系统。
4)基于领域本体的信息抽取在生物医学领域[17-18]、农业领域[19]已经有了广泛应用,段宇锋等[20]复用植物本体(Plant Ontology,PO)建立中文植物物种多样性领域本体,实现植物物种文本的信息抽取。由于招投标领域的相关研究应用较少,构建一个专业的领域本体需要领域专家参与,费时费力。为此,本文通过构建本体的轻量级领域知识模型,减少构建领域本体过程中对专家的依赖,轻量级本体可以看作是本体的简化版本[21],相对而言更加容易实现。
由于中文文本的复杂性,网页信息解析技术需要通过分词、标注对复杂的网页信息文本进行命名实体识别。本文基于招投标领域文本的结构特征,根据招投标文本中实体之间的映射关系,对文本进行规范化处理,引入一种新的招投标网页元素语义匹配与抽取算法,降低了网页信息解析过程的算法复杂度。
2 招投标网页信息解析模型
招投标网页信息解析模型是通过招投标网站发布的公示信息解析抽取出所需要的目标语义信息。招投标网页信息解析模型由知识模型构建模块和信息解析模块两个部分组成,如图1所示。
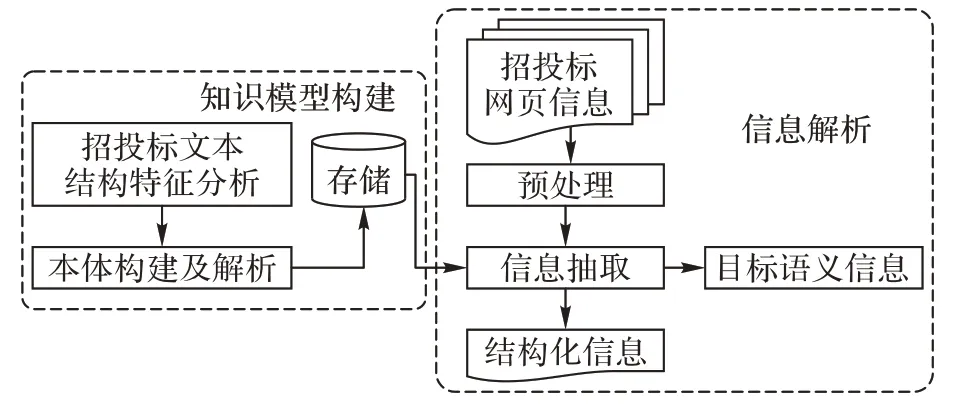
图1 知识模型驱动的招投标网页信息解析模型Fig.1 Parsing model of bidding webpage information driven by knowledge model
知识模型构建模块是通过对招投标领域文本结构特征的分析,采用构建轻量级本体的方式,构建信息解析所需的知识模型;信息解析模块是根据目标语义信息元素,基于招投标领域本体知识模型对预处理后的招投标网页信息进行信息抽取,实现招投标网页信息的自动结构化解析。
2.1 文本结构特征分析
通过浏览招投标网站可以发现,招投标网页数据大多数是以公告形式呈现的半结构化文本信息,有的还会包含表格文本信息,并且没有固定标准的格式规范。图2 是来自不同网站的招投标文本信息的示例。

图2 招投标网页示例Fig.2 Bidding webpage examples
招投标文本信息之间虽存在一定差异,但内容的组织形式有着类似的结构特征。通过学习分析,归纳出以下几点招投标领域文本的结构特征:
1)招投标文本存在表格信息,表格的结构形式不固定;
2)招投标文本可以用信息块来表示,信息块之间内容相互独立,界限分明;
3)招投标文本信息块可以看作是“概念与概念释义”的组合模式;
4)信息块之间的界限一般以特殊符号分隔。例如:换行、数字编码等;
5)不同来源的招投标文本之间的信息块位置分布相对一致。
2.2 本体构建及解析
采用构建轻量级本体的方式,构建所需的知识模型。一方面定义了招投标领域中的相关概念、属性、层次关系;另一方面还规范了网页信息中表格信息的抽取。实现了被不同用户理解的同时也可以成为机器能够理解和解析的知识,可以较细粒度地实现招投标网页信息解析并且不丢失重要语义信息内容。通过对招投标领域文本结构特征的分析,参考《招标公告和公示信息发布管理办法》[22]文件及招投标专员建议,使用斯坦福大学的编辑器Protégé 构建招投标本体的轻量级领域知识模型,层次结构如图3所示。
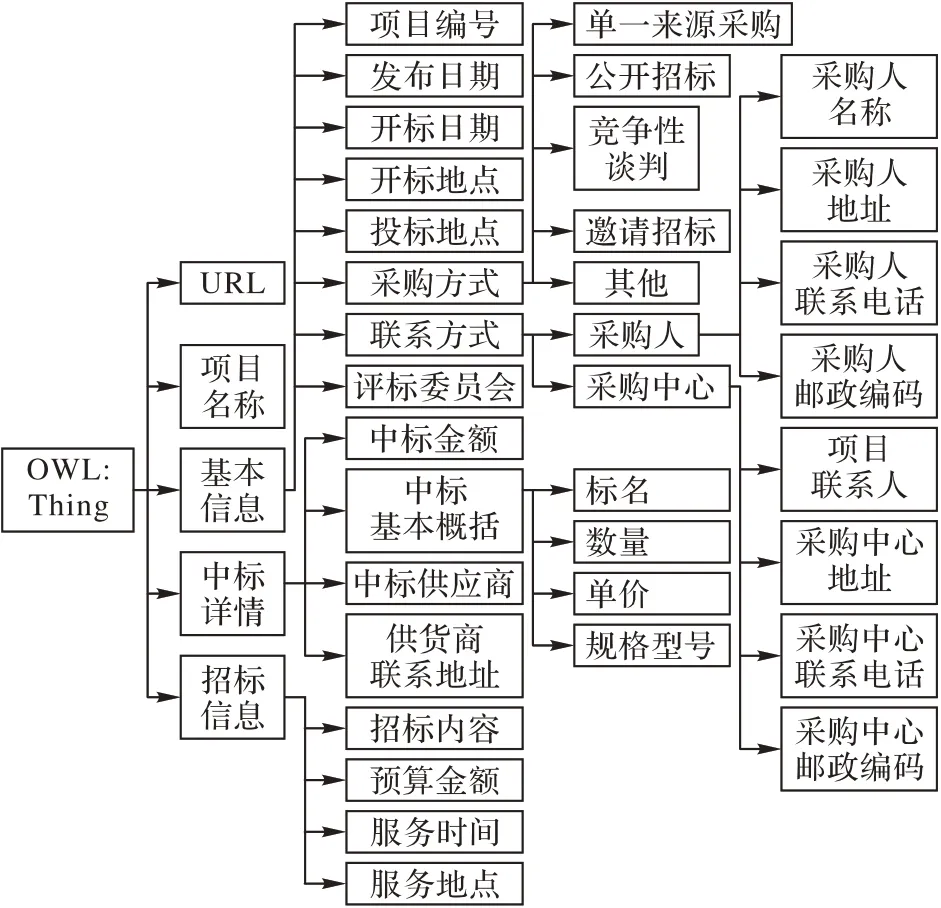
图3 招投标本体的轻量级知识层次结构Fig.3 Lightweight knowledge hierarchical of bidding ontology
构建的领域本体需要通过本体解析,从而利用本体中的知识,为知识抽取过程服务。将构建的领域本体中的概念以及概念之间的层次关系进行解析,得到本体的概念、属性、层次关系的词典和概念与概念、属性与属性、概念与属性之间的关系三元组,生成信息抽取过程的规则集,并且将本体持久化到关系型数据库中。对网络本体语言(Ontology Web Language,OWL)本体文件的解析结果如图4所示。

图4 部分OWL本体文件解析结果Fig.4 Part OWL ontology file parsing results
2.3 目标语义信息
通过对招投标领域文本结构特征的分析,归纳结构化抽取的目标信息项,相应的目标语义信息元素定义如表1所示。
2.4 预处理
通过爬虫得到的招投标网页信息存在噪声数据,需要通过预处理清洗数据,删除噪声信息,包括HTML 的标签、图片、样式等,保留标题、文本信息和统一资源定位符(Universal Resource Locator,URL)信息。通过预处理,将网页信息转换成更容易被处理的文本格式。

表1 目标语义信息元素Tab.1 Target semantic information elements
2.5 信息抽取
本文提出的招投标网页解析方法,经过预处理后,在招投标本体驱动下,与招投标网页元素进行语义匹配和抽取,实现对招投标网页语义信息的结构化解析。具体算法设计流程如图5所示。
经过预处理的信息,首先要判断文本是否存在表格,存在表格信息的要提取表格内容;接着以“;”“。”和“ ”作为切分界限标识符,将文本切分成独立的信息块,用句子集合S={S1,S2,…,Sn}表示;再根据招投标领域文本的结构特征,遍历句子集合S,将子句Si(i=1,2,…,n)切分成概念与概念释义的字典形式[Si,k:Si,v];然后匹配目标语义信息元素,在招投标本体驱动下,导入包含目标信息项的领域本体知识模型C={C1,C2,…,Cm},计算Si的Key 值Si,k与Cj(j=1,2,…,m)之间的相似度,如式(1)所示。
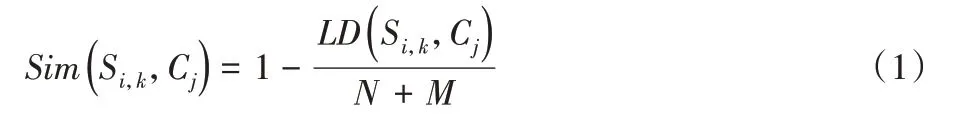
其中LD(Si,k,Cj)表示编辑距离,计算编辑距离[23]如式(2)所示。
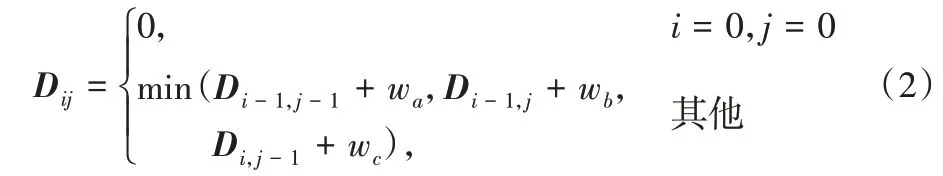
式中,矩阵Dij=D(s0s1…si,c0c1…cj)(0 ≤i≤n,0 ≤j≤m),s0s1…si表示字符串Si,k,c0c1…cj表示字符串Cj,通过(n+1)×(m+1)阶矩阵Dij计算得到LD(Si,k,Cj);Di-1,j-1为删除操作、Di-1,j为插入操作、Di,j-1为替换操作,设置删除的权重wa和插入的权重wb为1,替换的权重wc为2,即wa=1,wb=1,wc=2。从字符串Si,k的第一个位置s0和字符串Cj的第一个位置c0进行比较,对已经比较过的编辑距离,继续计算下一个字符位置的编辑距离。矩阵Dij从D00逐行逐列计算,最终得到Dnm,即编辑距离LD(Si,k,Cj)。

图5 网页信息抽取算法流程Fig.5 Flowchart of webpage information extraction
N和M代表Si,k和Cj的长度,经过计算得到Si,k和Cj之间的相似度Sim,Sim值越大表示相似度越高。设置相似度Sim的阈值:小于阈值继续进行迭代;大于等于阈值则保留Sim值最大的Key 值Si,k,并且返回其Value 值Si,v,保存经过匹配得到的Si,k和Si,v信息。随后判断句子集合S={S1,S2,…,Sn}是否遍历结束,遍历结束得到一个初步的解析结果。然后调用招投标本体解析生成的层次结构关系规则集合U={R1,R2,…,Rw},规则Rt(t=1,2,…,w)以三元组(ta,tr,tb)形式表示,ta和tb分别表示招投标本体结构中的不同概念属性,tr表示两者之间的关系。遍历规则集合U,进一步对初步结果进行抽取,最终输出结构化信息。
3 实验与结果分析
3.1 数据集
由于招投标领域网站,例如招投标网、中国招标与采购网、千里马等,都需要注册登录会员才可以获取信息,所以选用公开的采购网站作为实验对象,为保证数据集的多样性,选择多个网站源并且随机选取不同时间段共640 个网页数据作为本次实验测试的数据集,并采用人工抽取评估的方式作为标准参照结果。
3.2 评价指标
选取准确率、召回率和F值为评价指标[24],定义如下:
1)准确率是指正确抽取目标信息项个数占所有抽取结果的比率,如式(3)所示。

2)召回率是指正确抽取目标信息项个数占所有正确结果的比率,如式(4)所示。

3)F值是对准确率和召回率的综合评价,如式(5)所示。

3.3 结果分析
实验基于Windows 10 系统,CPU 2.80 GHz,内存8 GB,开发工具Python。网页解析的结果示例如图6所示。
进一步,对本文方法所获得的解析性能进行统计分析,如表2 所示,综合多个不同网站中招投标网页信息的解析实验结果,本文方法的准确率约是95.33%,召回率约为88.29%,F值约为91.68%。实验中发现,由于有些网页信息以非结构文本或复杂的表格信息展示,未能将信息识别抽取,是导致本算法召回率稍低的原因;有些存在于表格内的信息,由于表格结构过于复杂,未能在构建的领域本体中有所体现,降低了算法的准确率。
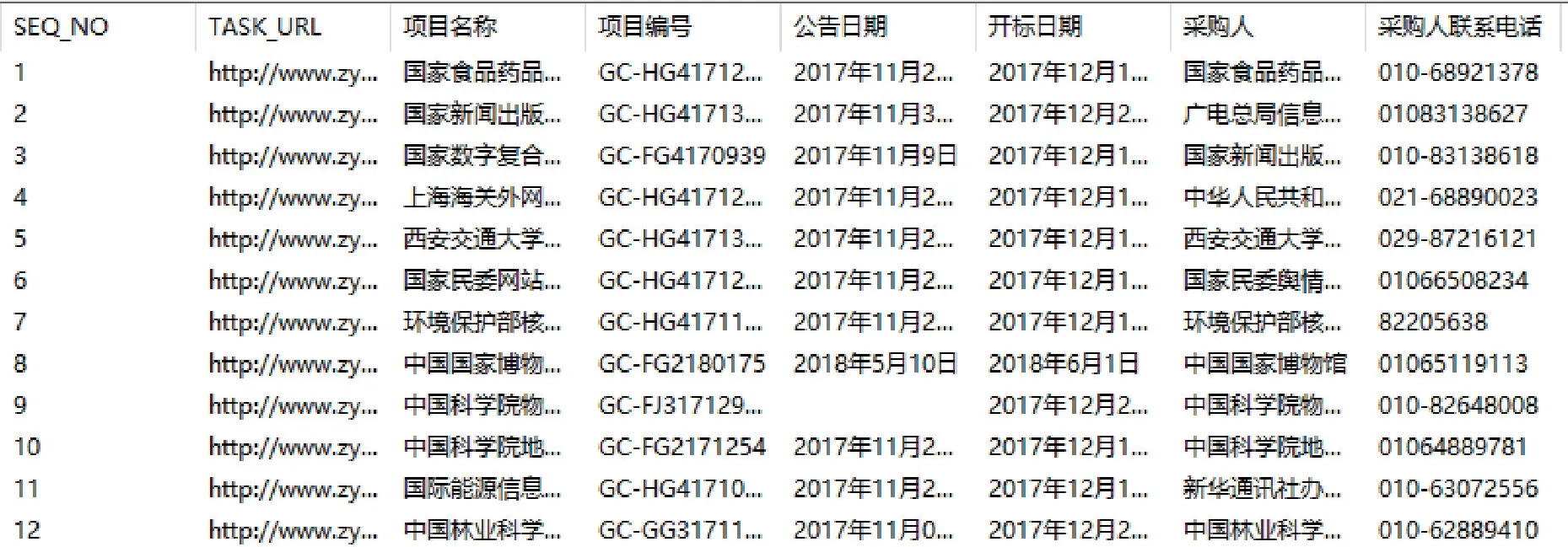
图6 招投标网页解析实验结果示例Fig.6 Example results of bidding webpage parsing experiment
为进一步分析文本算法性能,选择经典的基于正则表达式的网页解析方法作为对比。在实现对网页数据细粒度的信息抽取时,首先需要构建招投标目标信息项描述语句对应的正则表达式的数据模式,通过对选取网站的招投标信息格式的具体分析,部分模式规则如表3所示。
利用相同的数据集进行对比实验。两种算法对目标语义信息元素的提取结果对比如表4 所示。两种算法的综合解析性能对比结果如表5所示。
由表4可以看出,具有相对固定模式的信息项,例如编号、时间,正则表达式方法表现得更好,以项目编号为例,信息相对规范,以大写英文字母和数字组合而成,只需要列出固定组合模式即可,不会因为存在非结构文本而受到影响。例如“天津市公安局行动技术总队机房改造通用硬件采购项目(HGGP-2019-C-0117)”项目编号对应的正则表达式为“[A-Z]{1,4}.d{1,5}.[A-Z]{1,3}.d{1,6}”符合规则即可匹配抽取信息。
但相对灵活的信息项,即需要结合上下文语义环境进行分析的信息项,例如网页信息“采购人:山东省水利信息中心;地址:济南市历下区历山路127 号;联系方式:0531-86 974502;采购代理机构:海逸恒安项目管理有限公司;地址:山东省济南市高新区县(区)舜华南路297 号汉峪金谷A2-3-18;联系方式:0531-82661880”基于正则表达式的方法在抽取联系方式信息项时,虽能抽取出结果,但是没有上下文语义,并不能正确对应抽取出联系方式是采购人还是采购代理机构。而本文方法在招投标领域本体知识驱动下,通过领域本体的概念、属性、层次关系的解析规则,能够把握抽取时的语义关系,保证抽取结果的正确性。

表2 本文方法在实验数据集上的性能统计结果Tab.2 Performance statistics results of the proposed method on experimental dataset

表3 目标信息项的模式规则示例Tab.3 Examples of pattern rules for target information items
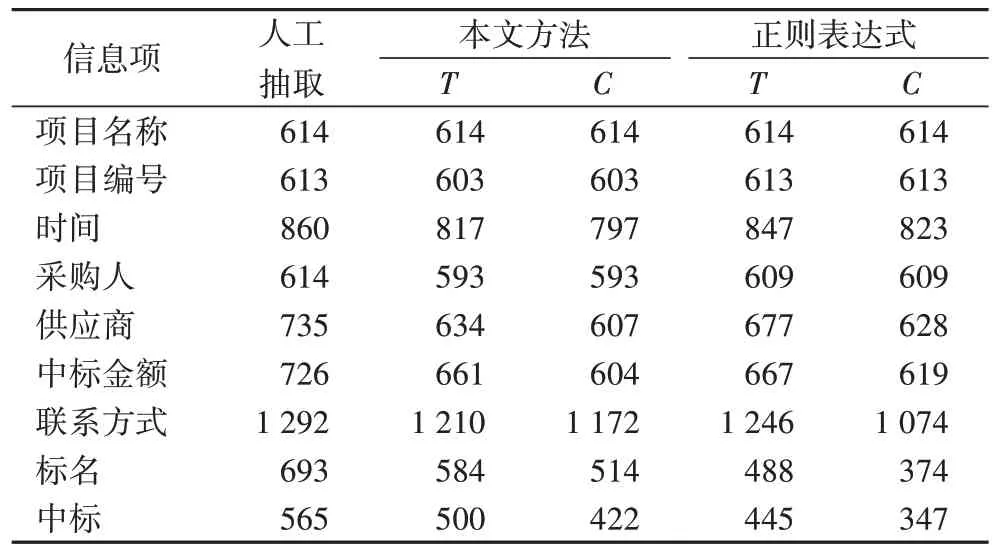
表4 两种对比方法对不同语义信息元素解析性能对比Tab.4 Parsing performance comparison of two methods for different semantic information elements

表5 两种对比方法的综合解析性能Tab.5 Comprehensive comparison of two methods
综合地,一方面正则表达式匹配严格,适用于模式相对固定的信息项;而面对灵活的信息项,由于表述方式多样,编写困难,更适合用本文方法。另一方面正则表达式依赖于目标信息项的结构特征,不同网站之间的模式规则存在差异,对比实验中已经根据具体测试的网站的网页信息,构建出目标信息项的正则表达式的规则集,但是若仅对目标信息项使用单一的正则表达式规则,效果会有较大差距,并且随着网页信息结构的改变需要重新编写,灵活性差,耗费大量人工成本;相对而言,本文方法不依赖网页结构,更加灵活,无需人工设计复杂的模式规则,更具有领域通用性和实用性。
从实验结果可以看出,本文方法总体达到了预期。但是由于互联网的复杂性和信息数据结构的多样性,目前还无法完全胜任一些复杂陈述结构的解析。
4 结语
针对招投标网页信息,提出一种招投标本体驱动下的网页解析方法,有效地实现对招投标网页中语义信息的自动结构化解析,具备较好的网页自适应能力,能满足实用性能要求。由于不同页面中招投标内容表述的多样性,实际使用中可以对知识模型进行进一步工程优化,以获得更高的解析性能。
