贸易口岸数据融合系统设计
2020-06-09张伟周贺寇进科
张伟 周贺 寇进科

摘 要: 贸易口岸统一收费系统是口岸重要业务系统,涉及众多机构和业务系统间的数据融合。为本文针对贸易口岸业务需求,阐述了数据融合系统的架构设计和融合功能功能设计,分析了融合的技术问题,并阐述了基于实时和批量相结合的技术实现方案。
关键词: 数据融合;数据融合架构;实时融合
中图分类号: TP391. 41 文献标识码: A DOI:10.3969/j.issn.1003-6970.2020.02.051
【Abstract】: In order to meet the business requirements of the trade port, this paper expounds the architecture design and function design of the data fusion system, analyzes the technical problems of the fusion, and expounds the technical implementation scheme based on the combination of real-time and batch.
【Key words】: Data fusion; Data fusion architecture; Real-time fusion
0 引言
贸易口岸数据融合系统以“一次缴费、全港通行”为建设目标,破除港口生态利益藩篱和信息孤岛壁垒。整合货代、报关、理货、运输、堆场、码头、船代、查验等多机构部门,通过费目公开,统一缴费、电子支付、环节匹配、价格监测、分级管控、全程可溯等主要措施,打通价格、收费、缴费、核查、放行等全链条、全流程服务,为码头、物流、仓储、贸易、运输和代理等企业、用户的收缴费提供一站式服务、一次性办理和一体化管理,实现业务流、资金流、信息流和信用流的完全统一[1-5]。
在保障港口经营主体一站式缴费、一次性办结的效率需求同时,也满足了行业主管部门集约化管理、多线联控的监管需求,使缴费企业“缴的明白,缴的方便”,使收费企业“收的准确,收的透明”,为持续优化营商环境提供了机制保障和平台支撑。本文阐述了贸易口岸数据融合系统的设计和实现技术,为业务流、信息流、资金流和信用流的统一提供支撑环境。
1 架构设计
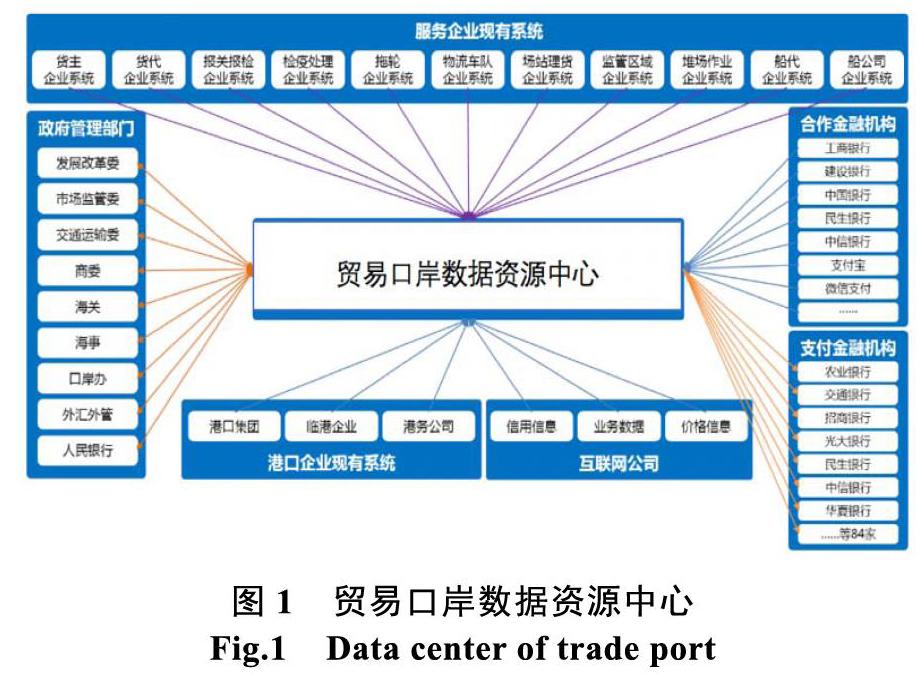
贸易口岸统一收费管理承接全流程、覆盖全环节的港口收缴费管理,面向货代、报关、理货、运输、堆场、码头、船代、查验等多机构部门,以及相关的政府管理部门和金融机构,是某贸易口岸通过数据资源中心进行数据整合的相关业务系统如 图1。
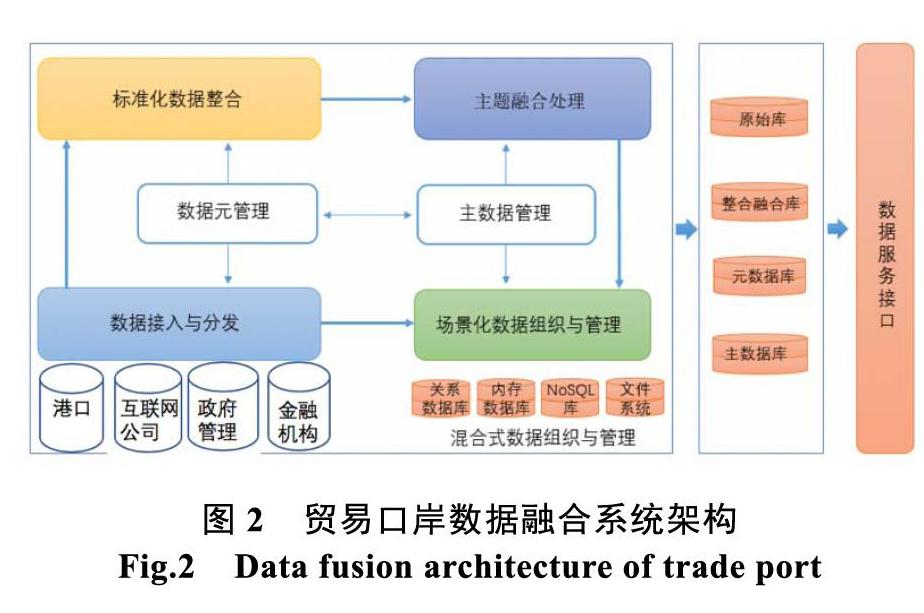
多源、多模态的各类港口数据、相关互联网公司数据、政府管理部门数据和金融机构数据,通过数据接入与分发系统接入平台,基于数据元进行标准化整合处理,并形成口岸业务主数据,为口岸业务一致性提供支撑。在此基础上,基于不同业务主题进行数据融合,按照不同业务场景要求进行数据的组织和管理,形成可对外服务的数据资源库—原始库、整合融合库、元数据库、主数据库,并提供多种接口多样化的访问方式[6-8]。
2 融合功能设计
2.1 数据采集和分发
数据接入和分发系统支持不同来源、不同模态政法数据的即时采集接入,由数据源管理、接入配置和数据分发等组成。
数据源管理对数据源名称、来源、地址、访问接口等进行管理;接入配置对接入请求监听、接入触发、接入转换参数进行配置,支持即时接入,同步、异步接入,全量接入和部分接入。数据分发支持多目标分发、实时分发和批量分发,支持数据分发的可靠性和安全性。
数据采集分发根据外部系统的多种数据源的数据,不同的分类标准采取不同的方式进行数据采集,采用如图3流程。
业务数据在应用系统中的数据量比较小时抽取过程需要用全部抽取;如果业务数据在应用系统运行过程中,能准确的区分出某一时刻以后发生變化的数据,则增量抽取;抽取需要支持增量抽取和全量抽取。抽取管理模块支持两类数据源抽取:分别是关系型数据库抽取和文件数据抽取。抽取的文件支持TXT、CSV、TSV等主流文本格式并且支持指定的分割符。
数据源为关系型数据库时,采用数据库抽取。数据库注册时必须填写:数据库类型、数据库连接方式、最大连接数、最小连接数、数据库用户名、数据库密码、schema名称、测试sql语句,表名称,表增量字段,抽取方式。数据库支持主流的关系型数据库如MySql、SqlServer、Oracle、PostgreSQL并支持定期从数据库中抽取数据。数据源为文件系统时,采用文件抽取,应用系统将需要抽取的业务数据保存为有格式的文本文件,文件抽目标源必须支持FTP文件系统和Linux文件系统进行数据抽取。通过在页面中填入:ftp文件系统相关信息、linux文件系统相关信息、存放目标路径信息。采集系统会通过页面的注册信息读此文件信息进行文件抽取。
转换管理实现源数据库和目标数据库之间的信息的转换,在页面中操作人员根据需求对抽取的数据进行必要数据处理配置。把采集的数据中的某一列进行数据转换,如常量转换、码值转换、字段拆分。在数据采集中,数据有出现数据质量较差的情况如特殊字符、特殊符号 输入替换字符进行替换。数据二次拆分对分割符拆分的字段进行二次拼接产生新的数据[9-12]。
加载管理对数据经过抽取、转换后的数据进行数据存储。作业调度将在页面配置的抽取管理、转换管理、分类管理组成的流程进行任务管理。包括任务状态监控、任务日志浏览,任务的调度方式以cron表达为任务调度策略。在作业调度过程中,提供执行过程记录,各步骤执行结果,各步骤完成时间,调度完成结果,便于操作人员对采集流程进行优化调整。
2.2 数据整合
数据整合对接入的多源多模态数据进行整合和聚合,包括数据清洗、模式对齐、数据标签和数据聚合等。
数据清洗删除原始数据集中的无关数据、重复数据、错误数据,处理缺失值、异常值或按规则进行数据补全;模式对齐根据预设标准进行数据类型转换、数据标准映射、数据格式转换;数据标签根据数据特征对数据进行标签处理,为业务智能分析基础;数据聚合通过定义计算规则/过程脚本/计算服务对数据进行通用或自定义的聚合与分组。
2.3 主题融合处理
根据不同主题,提供多种数据融合计算能力,支持多类数据融合算法。通过算法属性与融合场景属性的动态匹配,进行主题融合处理。定义算法模式框架,实现算法种类动态扩展[13-15]。
2.4 场景化数据组织与管理
根据不同应用场景,提供关系型、非关系型、内存、图、文件等数据组织与管理模式。其中,关系型数据库主要用于存储、管理结构化的、需频繁进行事务处理的口岸业务数据、平台配置数据。No SQL数据库主要用于存储、管理海量、高并发访问的口岸业务数据。内存数据库主要用于存储、管理需要快速响应得到结果的即席查询、分析、挖掘数据,将整个数据库或其主要数据处理放入内存,减少每个事务在执行过程中传输。采用分布式文件系统存储、管理大文本、图片、视频等非结构化数据。
2.5 数据服务管理与接口
通过数据融合形成的各类原始汇集库、整合融合库、元数据库和主数据库等,通过数据服务进行管理和访问。数据服务管理主要功能包括数据服务的发布、服务注册、服务查询、服务修改、服务删除、服务发布、服务测试、统计查询。数据服务管理和服务调用流程设计如图4。
服务管理是由服务提供方发起的服务创建的过程,通过服务注册配置。完成服务的创建。服务类型包括RESTful服务、WebService服务、JMS服务、Kafka服务。RESTful服务注册时指定输入源服务地址、服务类型(get/post)等参数信息;JMS服务注册时指定服务器信息、提供queue、topic选择和名称。Kafka服务注册时指定topic选择、支持Kerberos认证。等。
各类服务通过目录进行管理和访问。目录管理主要有目录分类和目录索引组成,通过目录分类可以把数据共享和数据服务管理进行分类,使用者通过目录分类可以更加高效便捷的查询数据服务内容和查询数据共享内容。
3 批量和实时结合的数据融合技术设计
3.1 数据融合问题分析
贸易口岸贸易口岸数据庞杂,数据量巨大。数据融合技术上主要需解决如下问题:
(1)复杂指标的计算融合
计数、求和、平均等指标能够依靠查询结果合并实现,但大部分复杂指标的方差、标准差、熵等融合计算无法依靠简单合并完成。对具有长周期时间窗口的复杂指标,多次重新计算的开销巨大。
(2)基于数据生成的进度的内存分配
在每天的定义固定时间将流数据导入批处理系统会造成内存资源的极大浪费,需要实现一种融合存储策略,能基于数据产生进度,进行内存分配和使用。
(3)多粒度多角度查询请求的动态数据融合
口岸业务系统的数据查询时间窗口具有多尺度、多角度,如“本月物流业务结算金额”、“某公司去年报关单数和金额”等。如果每次查询请求都重新计算将会对系统性能造成极大的影响,需实现多时间窗口尺度、多种窗口漂移方式的动态数据实时融合处理方法。
(4)高可用、高可扩展的内存计算
由于内存介质的易挥发的特性,一般需要采用多副本的方式,以保证基于内存存储和计算的高可用性,这产生“如何确保不同副本的一致性”的问题。
3.2 实时和批量相结合融合处理
基于上述问题,本文采用批量大数据处理和实时流式处理结合的融合处理方法。
批量融合处理以Hadoop Hbase为基础,首先先将数据初步汇聚,预处理后加载到数据仓库,以支持业务的分析。这种方式无法查询到最新的实时数据,存在数据迟滞问题。
实时流式处理以Spark Streaming、Flink为基础,将数据通过流处理的方式实时逐条加载至高性能内存数据库中进行查询,数据迟滞低。这种方式,由于内存容量限制,需丢弃原始历史数据,无法在完整大数据集上支持Ad-Hoc查询分析处理。
为解决复杂指标的融合计算问题,采用“所见即所得”的在线作业编排管理,将复杂计算分解为一个个独立的计算单元,通过计算作业编排,将上线任务耗时降低到分钟级,提升流处理作业的编排效率,实现即时作业组合和结果融合的复杂计算。
对多粒度多角度查询请求的动态数据融合问题,采用在原始数据进入流处理平台时,通过顺序写的方式持久化一份原始数据,在需要上线新的计算作业时,即刻重发指定时间窗口内的原始数据,实现快速的计算作业上线和不同時间窗口查询请求的数据动态融合。
采用数据冲突智能规避的方法,解决流式处理中的热点数据处理和大颗粒数据维度的处理效率。通过Paxos一致性协议,解决内存存储计算时多副本一致性问题,并向运维人员提供透明的一致性解决方案。
采用智能分区的方法,基于一致性散列技术,将散列值拆解为散列块,通过散列块的平滑迁移实现存储集群的可伸缩性设计,并通过计算作业的动态运行时加载,规避了作业手工打包部署。
4 结束语
根据贸易口岸不同的业务间数据融合需求,场景和资源需求模式,本文阐述了贸易口岸数据融合系统的架构设计和主要功能设计,分析了数据融合面临的主要技术问题,阐述了针对这些问题的技术方案。
实践表明,该系统在多系统数据融合的灵活性、扩展性和实时性等方面都具有较好的效果。未来,将结合应用场景的大数据实时融合需求,进一步完善时序实时大数据处理能力,提高融合系统的处理性能。
参考文献
Suchanek F M, Weikum G. Knowledge bases in the age of big data analytics[J]. Procedings of the VLDB Endowment, 2014, 7(13): 1713-1714.
WAMDM. ScholarSpace[EB?OL].[2015-12-12]. htp:?c-dblp.cn.
Shvaiko P, Euzenat J. Ontology matching: State of the art and future chalenges[J]. IEEE Trans on Knowledge and Data Enginering, 2013, 25(1): 158-176.
Zhao L, Ichise R. Ontology integration for linked data[J]. Journal on Data Semantics, 2014, 3(4): 237-254.
Jan M. Linked data integration[D]. Prague, Czechia: Charles University in Prague, 2013.
Dong X L, Srivastava D. Big data integration[C]?Proc of the 29th IEEE Int Conf on Data Enginering (ICDE). Piscataway, NJ: IEEE, 2013: 1245-1248.
Belahsene Z, Bonifati A, Rahm E. Schema Matching and Mapping[M]. Berlin: Springer, 2011.
唐山峰, 王淑營. 面向电子政务的异构数据交换解决 方案[J]. 计算机技术与发展, 2011(4): 13-16.
侯晓岑. 政府信息资源管理系统的设计与实现[D]. 成都: 电子科技大学, 2014.
徐磊, 赵爱东 . 智慧港口公共信息平台标准化建设探 究[J]. 标准科学, 2015(4): 42-45.
基于商密体系的政务链解决数据安全共享交换的研究[J]. 赵睿斌, 杨绍亮, 王毛路, 程浩. 信息安全与通信保密. 2018(05).
我国政府数据开放共享政策体系构建[J]. 黄如花, 温芳芳, 黄雯. 图书情报工作. 2018(09).
浅谈政府数据共享交换平台建设[J]. 熊瑰. 信息通信. 2018(02).
大数据时代政府管理创新[J]. 陈冠蓉. 中国管理信息化. 2017(02).
电子政务系统中的数据交换和共享服务平台设计[J]. 刘麟乾. 电脑编程技巧与维护. 2016(11).
![]()