复杂环境下一种基于SiamMask的时空预测移动目标跟踪算法
2020-06-05张浩博付冬梅赵志毅
周 珂,张浩博,付冬梅,赵志毅,曾 惠
1) 北京科技大学高等工程师学院,北京 100083 2) 北京科技大学自动化学院,北京 100083
视频图像的跟踪及特征分割,是视频应用中的一项基本任务,如自动监视[1],车辆导航,视频标签,人机交互[2]和行为识别等. 如何在使用场景中,对视频流在线执行目标跟踪,满足图像跟踪及后续处理的实时性、可靠性需求,是目前图像识别领域的重要研究方向.
2016年,Bertinetto等[3]提出 SiamFC算法,利用CNN的全卷积(Fully-convolutional)神经网络进行实时图像的跟踪处理,克服了传统深度学习在实时视频图像处理中计算量大、效率过低的缺陷.2018年,Li等[4]结合了 SiameseFC和 Faster RCNN中的 RPN(Region proposal network),使得实时图像的提取速度大大加快,同时也达到较高精度效果,其目标跟踪算法的代码实现精度在VOT2018排名第一,鲁棒性大大增强. 2019年,中科院Wang等[5]提出新算法SiamMask,实时进行目标跟踪和半监督视频对象分割,采用基于数百万视频帧上离线训练的全卷积网络Siamese,缩小任意目标跟踪与VOS之间的差距,在视频跟踪任务上达到最优性能,并且在视频目标分割上取得了当前最快速度.
上述算法在已有开源数据库的实时识别中均有出色表现,但在应用场景里,由于识别背景的复杂性及遮挡性、目标特征的差异性、环境影响的随机性等因素,会存在一定的目标误识别现象[6−7].针对如何在识别准确度要求较高的应用场景中(如生产安全智能预警系统中的移动目标实时图像识别),实现高效、快速的实时图像识别,开展了本文研究内容. 提出一种基于SiamMask的时空预测移动目标跟踪算法,克服环境干扰、目标遮挡对跟踪效果的影响,实现视频序列中的目标快速识别,对移动目标识别算法模型的复杂环境应用具有借鉴意义.
1 基于 SiamMask 的时空预测移动目标跟踪算法设计
1.1 应用场景提出
机床加工在工业生产中应用极为广泛,实际生产操作环节里,由于人的安全防护不符合规范,操作人员的头发往往是导致严重安全事故的隐患之一. 如女性操作车床时,若未扎好头发或未戴帽子,散落的发梢极易被卷进高速旋转的车床部件中,带来严重的人身安全事故. 随着数字化管理手段的普及,操作环节的全时监控已在生产过程中得到普遍应用,预警系统可通过监控视频的目标识别,达到对危险因素监测、预警的目的. 然而头发由于移动中的非规则性、运动无规律性,使得头发区域在运动图像中的分割较为困难. 常见的动态图像识别Camshift算法以颜色直方图为特征对目标进行跟踪[8−9],对刚性目标的跟踪具有较强的鲁棒性. 但当目标过于复杂、目标被遮挡或做加速运动时,很容易发生目标跟丢的情况. 目前国内外头发区域分割多集中在二维图像中[10−12],对移动目标的头发区域分割尚无工业实现的先例.
本文的动态识别检测以北京科技大学工程训练中心金工实习车床加工环节为样本,其结果需满足生产环节的安全操作预警,要求较高的识别准确性及算法效率. 因此提出了一种基于PyTorch深度学习框架,将SiamMask单目标跟踪算法与ROI(Region of interest)检测及 STC(Spatio-temporal context learning)时空上下文目标跟踪算法融合的方法[13],满足实际场景中对人员头发区域动态分割识别的任务需求.
1.2 基于 SiamMask 模型的面部动态检测实现
动态视频检测的重要技术难题就是如何更快、更有效,本文基于2019年5月PySOT目标跟踪库[14]的最新成果SiamMask模型进行面部动态检测[15]. SiamMask是当前视频图像目标跟踪模型中,最为出色的快速跟踪和分割方法. 该算法基于PyTorch深度学习框架,实时进行目标跟踪和半监督视频对象分割,通过增加目标分割的损失,改进了全卷积网络Siamese跟踪方法的离线训练过程. 经过训练,SiamMask完全依赖于初始化单个边界框并在线操作,产生类别未知的目标分割Mask和实时每秒35帧的旋转边界框. 在VOT-2018、DAVIS-2016和DAVIS-2017上均有极为出色表现.
1.2.1 算法移植测试优势
如图1所示,Mask生成的网络采用的两层1*1卷积,分别是256通道和63*63通道数,并采用了Refinement module(微调模块),这是一种不同分辨率的特征融合策略. 在SiamFC和SiamRPN基础上分别加上目标分割分支网络,形成两分支和三分支的SiamMask网络. 图1左边是共享权值的孪生网络,在对模板(上分支网络)和搜索区域(下分支网络输入)特征提取后,进行卷积生成与模板最相似的相应区域. 图中,★d表示深度相关权重叠加,Row表示响应窗口,Mask表示视频目标物体,Box 为预测盒,Score为预测得分.fθ、hϕ、bσ、sφ、pω分别为 CNN、目标物体、预测盒、预测得分、响应窗口预测得分的处理函数[5].
SiamMask模型通过大量的深度学习网络离线训练,将在线学习工作量节约至最小状态,整个模型通过初始帧跟踪目标设定即可完成整段视频的目标跟踪处理,具有非常强的实时性、便捷性、计算低成本性. 考虑应用场景对识别快速性的要求,采用SiamMask对图像进行初步处理. 为更好的测试算法可用性,算法处理环境为工业环境中易于实现的单GPU处理板.
图2为SiamMask模型在工业系统视频中的测试效果,对不同发型及尺寸视频目标的头部追踪,该模块表现出较高的识别效率,平均识别速度可达每秒26.8帧.
1.2.2 算法移植测试误识别现象
尽管算法识别效率高,但在环境嘈杂时,会出现跟踪误识别情况. 如图 3(a)、(b)所示,当追踪对象周围出现深色服装、肉色物体等干扰源时,算法产生误识别现象;图3(c)为人脸被头发遮挡后,该模型失去跟踪目标. 此外,在目标出画面之外再进来的情况下,继续跟踪效果不佳.
将SiamMask模型对7段测试视频的追踪效果进行统计,得到表1所列情况.
结合图3和表1数据可以看出,SiamMask网络模型会在以下情况产生误识别现象:
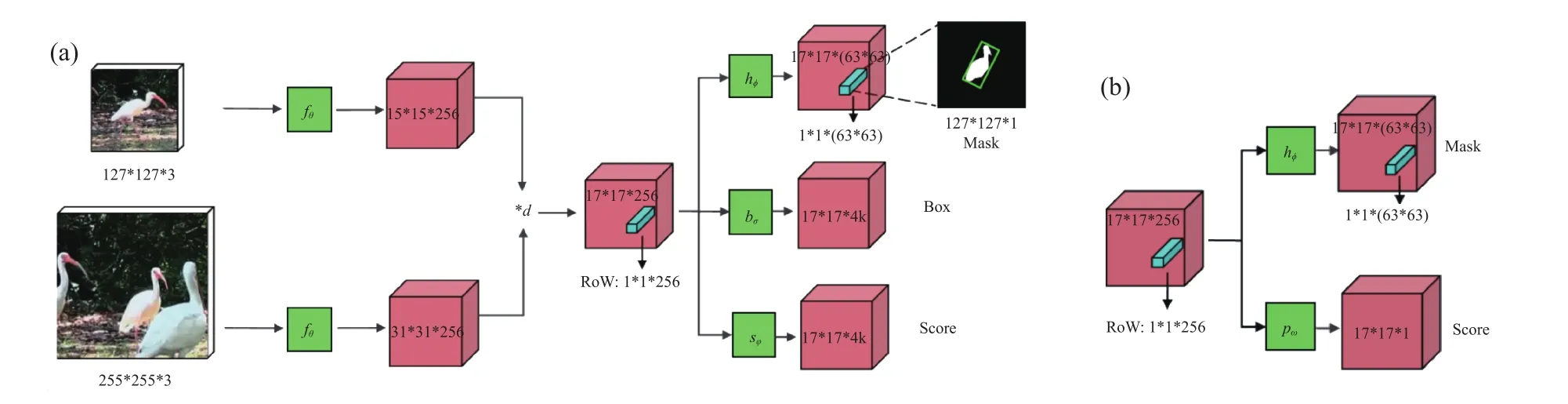
图1 SiamMask模型算法流程图[5]. (a)三分支变型架构;(b)二分支变型架构核心Fig.1 SiamMask model algorithmic flow chart[5]: (a) three-branch variant architecture; (b) two-branch variant head

图2 SiamMask模型面部检测效果. (a)束发头部跟踪;(b)长发头部跟踪Ⅰ;(c)长发头部跟踪ⅡFig.2 SiamMask model face detection effect: (a) bundle head tracking; (b) long hair head tracking I; (c) long hair head tracking II

图3 SiamMask模型测试误识别现象. (a)深色干扰源误识别;(b)肉色干扰误识别;(c)头发遮挡误识别Fig.3 SiamMask model test misrecognition phenomenon: (a) misidentification of dark interference sources; (b) misidentification of flesh color interference; (c) misidentification of hair occlusion
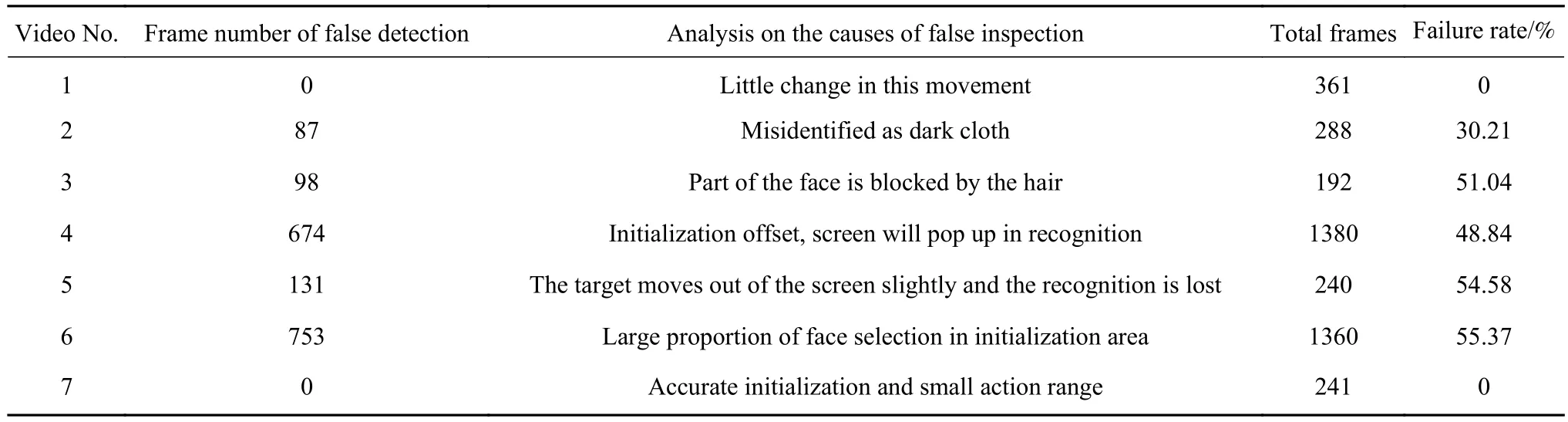
表1 SiamMask模型目标跟踪效果统计Table 1 Statistics of target tracking effect of the SiamMask model
1)初始化区域选定的面部比例较大时,效果存在较多误识别现象.
2)干扰项出现时若产生误识别现象,在干扰因素消失时,无法及时恢复目标跟踪. 在本文的对象视频中表现为,目标移出视频后再返回则不再跟踪. 由图3所示,目标误识别后,即便目标仍在同一区域,也难以校正.
1.3 SiamMask 模型的修正处理
针对SiamMask模型的应用不足,提出算法修正. 对原始工业视频做ROI提取,并以STC时空上下文跟踪法[16−17]对视频序列进行匹配校正,从而减少工业环境中的目标漏检、误检率,实现复杂环境中头发区域的精准检测. 算法框架图如图4所示. 图中,Pk为第k帧图像,Pk’为STC预测的第k帧图像,Φ为判断函数.
修正1:ROI区域提取. 如上文所述,SiamMask模型初始Mask对视频后序识别的误差具有积累性,因此在算法修正时首先对视频进行了识别目标与非相关性背景的分离预处理[18].
修正2:STC匹配校正. STC模型是一种考量了目标与背景相关性的算法理念,具有较高的目标跟踪精度与速度. 本文基于STC算法,结合时间与空间信息,根据对头发目标时空关系的在线学习预测新的目标位置,并与SiamMask模型的跟踪结果进行匹配校正.
1.3.1 工业视频ROI提取
本文所使用的视频来自于实际车工场地监控镜头录制的彩色视频,分辨率为1920×1080,帧率为每秒24帧,总帧数截取3427帧. 从图5(a)可以看出,视频画面中包含多个机床工位,往来人员较多,这给单个目标的跟踪、检测带来一定干扰. 面对实际情况,针对单个车床目标,需要对获得的视频进行ROI提取操作. 其中包括:视频ROI区域设定、全图运动检测两部分.
(1)ROI区域设定.
具体ROI提取步骤中有两个关键点:ROI区域起点位置、ROI区域的分辨率. 应用先验知识,可以确定ROI区域左上角起点像素位置A(x,y),ROI区域宽度为lw,高度为lh,如式(1)所示:

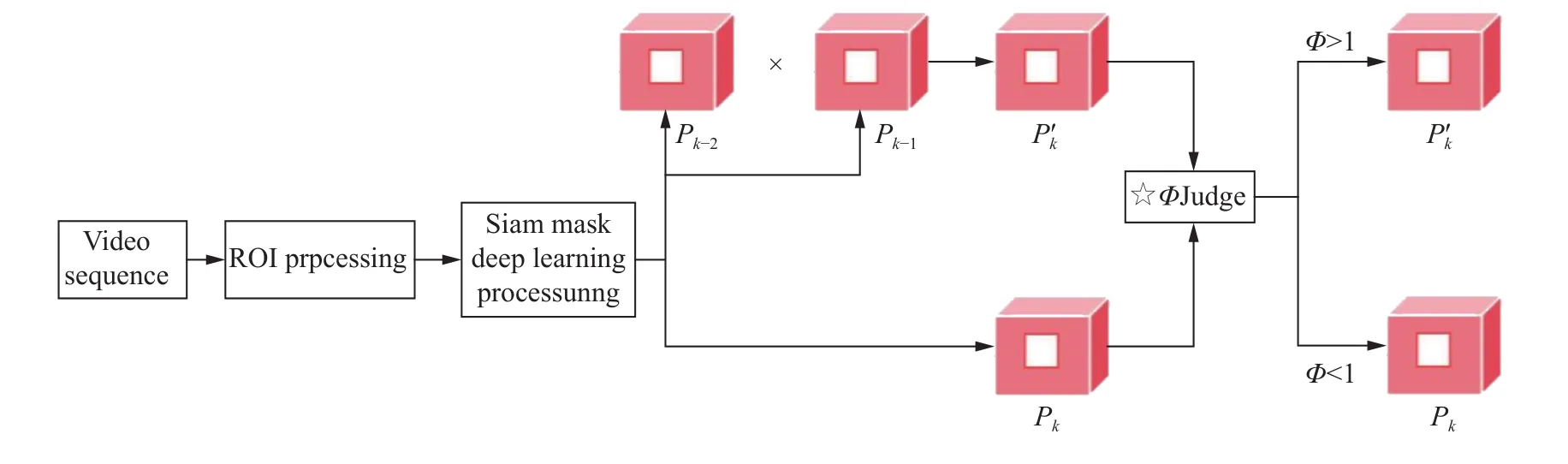
图4 基于SiamMask模型的时空预测移动目标跟踪算法框架图Fig.4 Framework of spatiotemporal prediction moving target tracking algorithms based on the SiamMask Model

图5 车工监控视频 ROI提取结果. (a)原始画面;(b)ROI提取画面Fig.5 ROI extraction result of a locomotive monitoring video: (a) original picture; (b) ROI extraction picture
通过自动获取原始视频的信息,按照式(1)进行相对比例的计算,处理结果如图5(b)所示,裁切得到的视频宽度为816个像素、高度为536个像素、ROI左上角起点坐标像素为(516,541).
(2)ROI全图运动检测及自动提取.
步骤1:设Ik(z)为像素点z(xz,yz)灰度值,对输入视频相邻的三帧图像,进行像素点灰度值变化计算.
步骤2:判断相邻帧之间灰度变化,对差值标志赋值. 在训练中选取灰度差阈值ΔIT=30.
步骤3:判断两个差值标志位逻辑结果同时为1时,代表三帧中有运动目标存在.
步骤4:对于输入的序列图像,按照时序统计每三帧之间的灰度变化像素点的个数,当运动目标出现时,灰度变化像素点个数成跳变趋势,从该时刻进行ROI区域的提取,即按照ROI区域先验设定尺寸进行裁切. 如图6所示.

图6 运动图像检测灰度图. (a)无运动目标时的原图/灰度图;(b)运动目标出现时的原图/灰度图Fig.6 Gray level image of moving image detection: (a) original image / gray level image without moving object; (b) original image / gray level image when moving object appears
1.3.2 STC匹配校正
为了解决复杂环境、头发遮挡等对头部跟踪的影响,在深度学习框架后的滤波跟踪框架中融合了图像空间上下文信息,以实现对目标变化的自适应调整. STC图像空间上下文算法通过贝叶斯框架统计目标及其背景的相关性并进行置信图计算,根据置信图的似然概率最大位置预测新的目标位置.
根据当前帧确定上下文特征集合:Tc={c(z)=(I(z),z)|z∈Ωc(t*)},其中,t*(xt,yt)是目标区域中心,I(z)是目标区域像素z的灰度值,Ωc(t*)是由目标矩形确定的局部上下文区域的图像灰度与位置的统计建模,c(z)为置信图函数[19]. 如图7所示,对灰度级图像进行阈值化处理,得到的二值化图像可进一步排除背景冗余信息.
设SiamMask模型第k帧追踪目标图像为Pk,空间上下文预测第k帧目标图像为. 设计判断函数Φ进行Pk与中目标位置的相似度比对,根据比对结果进行更新校正,形成新的目标跟踪结果.
步骤1:计算k-1帧ROI区域置信图:
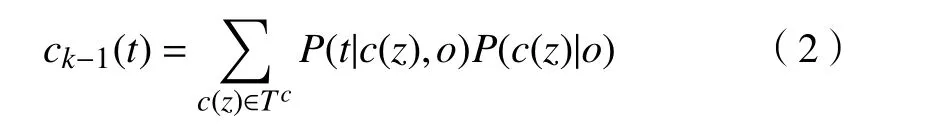

图7 图像灰度及阈值化处理. (a)原始视频图像;(b) 灰度化处理结果;(c) 阈值化处理结果Fig.7 Gray level and threshold processing of image: (a) original video image; (b) grayscale processing results; (c) threshold processing results
式中,o表示所跟踪目标,P为上下文先验模型.
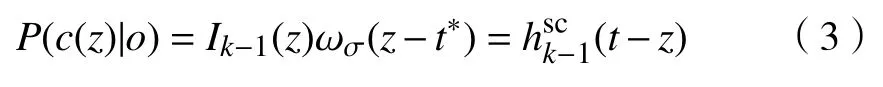
步骤2:计算k-1帧Ωc(t*)上下文区域的空间上下文模型:
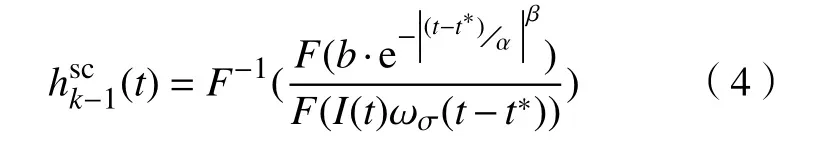
式中,b是归一化参数,α是尺度参数,β是目标形状参数.
步骤3:更新空间上下文模型:
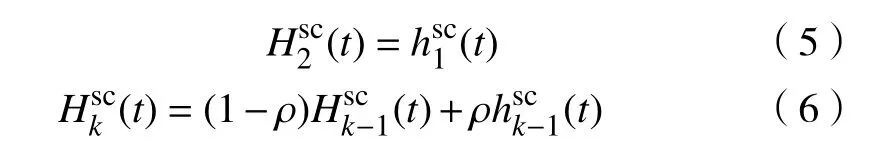
式中,ρ为模型更新的学习率.
步骤4:在第k帧计算上下文先验模型及置信图:
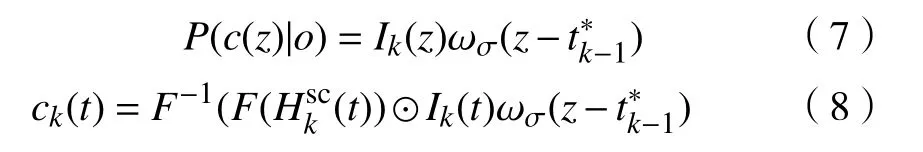
步骤5:将第k帧得到的置信图极值点作为目标在k帧的位置输出:
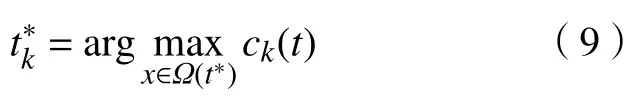
2 算法研究结果及分析
2.1 算法训练
与SiamMask[15]一样,使用Warmup预热学习率的方式,在Davis2017[20]数据集中进行训练,并在机加工操作数据视频集中进行头部识别测试.其中,训练输入为图像尺寸127像素×127像素,255像素×255像素,数据增强采用随机抖动与搜索策略,网络初始化权重采用SiamMask模型在ImageNet-1k Datasets上预训练的权重,梯度下降策略采用SGD. 训练时在开始进行的5轮训练中,先将学习率从10-3线性增长到5×10-3,之后通过15轮训练将学习率以对数规律降为5×10-4.
图8为本文算法在训练及测试集中的准确率、损失率曲线图. 可以看到,在训练集上,15轮次左右训练后,准确率及损失率均有效收敛. 在测试集上,由于数据特征更为集中,呈现了更快速的收敛性.
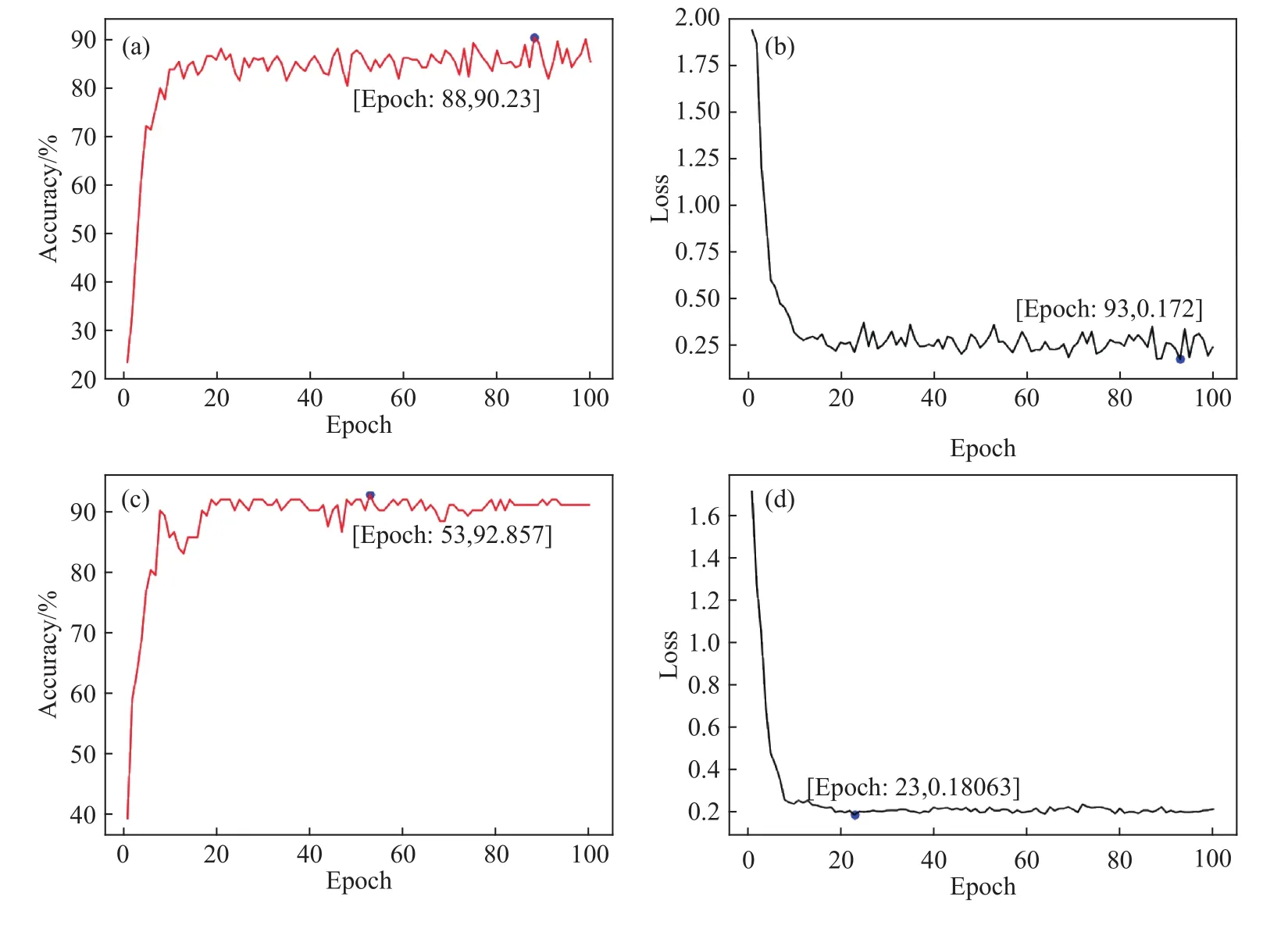
图8 算法训练/测试准确率及损失率曲线. (a)训练集准确率曲线图;(b)训练集损失率曲线图;(c)测试集准确率曲线图;(d)测试集损失率曲线图Fig.8 Algorithm training/test accuracy and loss rate curve: (a) training set accuracy curve; (b) training set loss curve; (c) test set accuracy curve; (d) test set loss curve
2.2 算法应用效果测试
2.2.1 测试指标设计
本文采用图像检测中常用的标准性能度量参数 IoU(Intersection over union)进行检测判断. 当检测到的目标位置与真实目标位置相交的重叠部分为0时为失败,即IoU=0认定为跟踪失败. 通过式(10)统计第i段视频误检帧所占的比例.
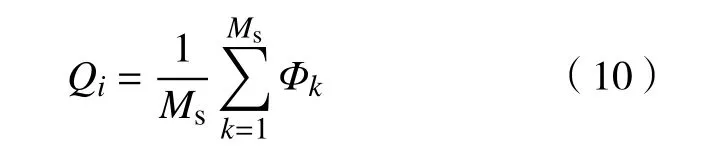
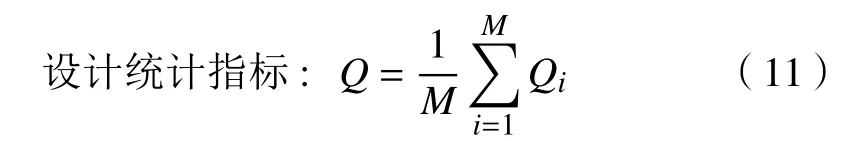
式中,M为视频个数.Q为所有视频片段的错误率的均值.
2.2.2 测试数据对比
为保证对比测试的初始区域一致性,SiamMask模型与本文所提算法均采用被测视频的初始帧人脸区域分割结果. 通过对7段测试视频进行统计,得到前文表1及下文表2的数值.
从表1中视频的测试数据可计算得知Q=34.29%,即算法误识别的平均可能性为34.29%.从表2数据可计算得知Q=0.156%,本文提出的算法误识别率有较大降低.
2.3 算法时间成本
由于本文算法必须满足智能安全识别系统实时、高效、可靠的要求,因此在实际使用环境中测试其综合时间成本.
为了检验效果,用外接矩形框对目标跟踪轮廓边界进行了包围,如图9(a)所示. 可以看到,经过算法校正,背景中的噪声轮廓得到了大幅度去除,保留得到的头部轮廓是大面积连通域的外轮廓. 对于头发轮廓的边界点坐标以向量的形式进行存储,即获取到视频序列中人员头发的位置坐标,为后续头发目标是否进入危险区的判定提供基础.
如图9(a)中所示,较大蓝色矩形框代表二级危险区,较小绿色矩形框代表一级危险区. 对于危险区的位置信息记录如下,二级危险区的具体设计为:左上角顶点像素位置坐标为(418, 274),宽度为164个像素,高度为147个像素. 一级危险区的具体设计为:左上角顶点像素位置坐标为(471, 311),宽度为107个像素,高度为93个像素. 在图9(b)中设计了四种报警级别的区域范围,分别是预警II级、预警I级、危险、非常危险.
对于两组坐标进行比对判别,判断头发目标进入危险区的程度以触发不同类别的报警. 得到结果如图10所示,图10(b)左上角为具体文字报警内容.
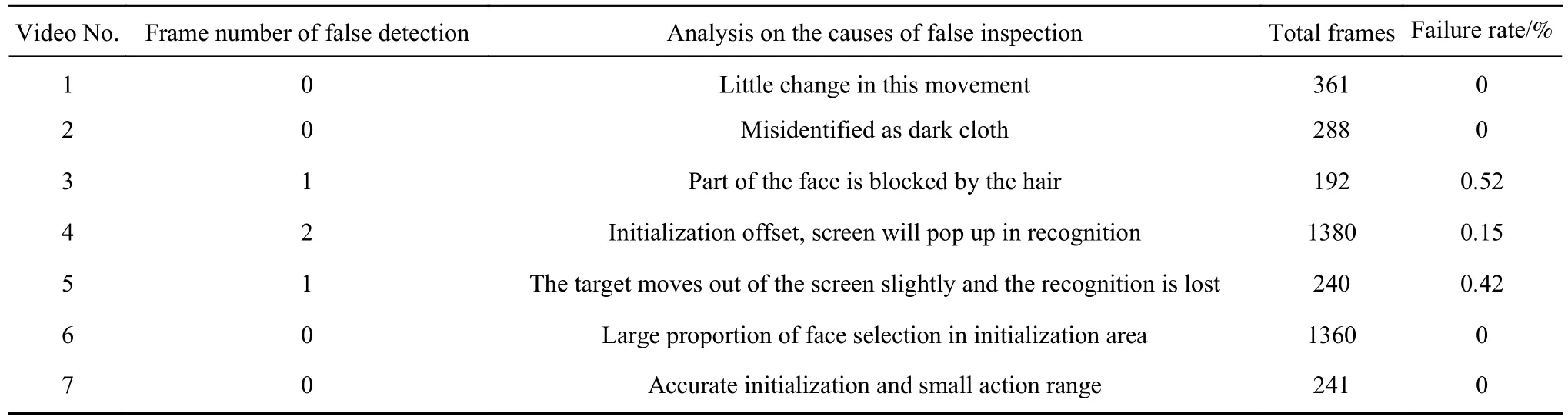
表2 基于SiamMask模型的时空预测算法目标跟踪效果统计Table 2 Statistics of the target tracking effect of the spatiotemporal prediction algorithms based on the SiamMask model
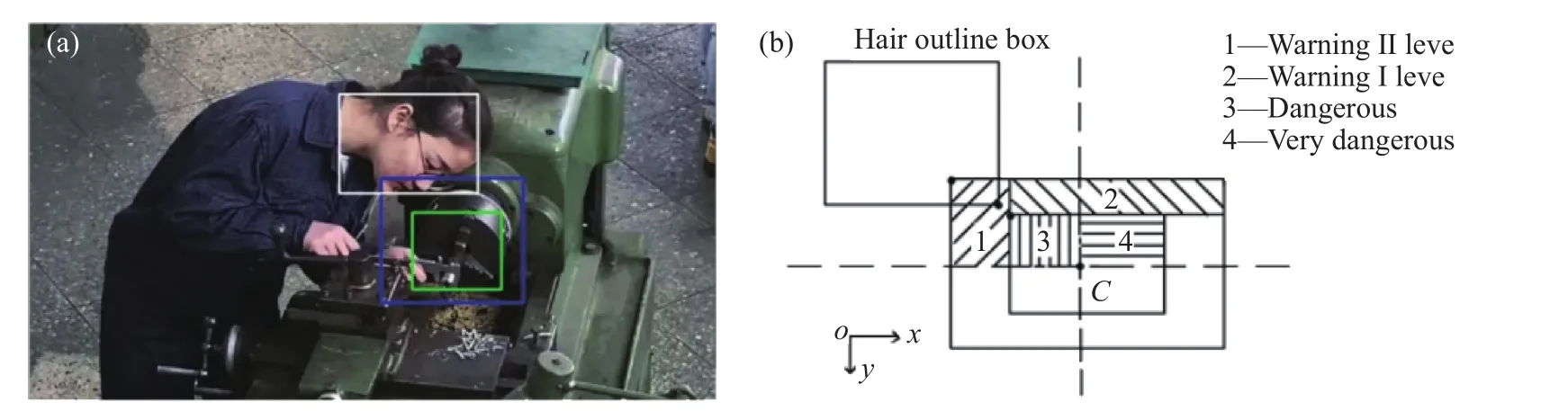
图9 固定危险区划分示意图. (a)视频危险区划分图;(b)危险级别划分示意图Fig.9 Fixed danger zone division diagram: (a) video dangerous zone division map; (b) diagram of hazard classification

图10 头发目标跟踪报警结果. (a)第 30 帧;(b)第 35 帧;(c)第 60 帧;(d)第 70 帧;(e)第 75 帧;(f)第 80 帧Fig.10 Hair target tracking alarm results: (a) frame 30; (b) frame 35; (c) frame 60; (d) frame 70; (e) frame 75; (f) frame 80
对于算法的处理时间进行统计. 利用cvGetTickCount函数得到从操作系统启动到当前所经历的时钟周期数,利用cvGetTickFrequency函数返回每秒的计时周期数N. 则程序运行时间T可以通过式(12)计算得到.

式中,nr为当前时钟周期数,ns为开始时钟周期数.
测试视频的基本信息为:宽度816像素,高度536像素,总帧数3426帧,帧率为每秒30帧,图像处理速度为每秒30帧. 按照式(12)计算,处理时间为0.137 ms.
算法的计算效率比改进前的SiamMask模型图像处理速度每秒提高3.2帧,算法效率提高约11.94%,可以满足智能安全预警系统的实时快速性要求.
3 结论
(1)基于PyTorch深度学习框架的SiamMask模型单目标跟踪算法,引入ROI检测及STC时空上下文目标跟踪算法,结合时间与空间信息,根据对头发目标时空关系的在线学习预测新的目标位置,对SiamMask模型进行了算法校正.
(2)提出的算法应用于复杂环境中头发目标视频图像识别. 研究结果表明:所提算法能够克服环境干扰、目标遮挡对跟踪效果的影响,将目标跟踪误识别率降低至0.156%.
(3)其计算时间成本为每秒30帧,比改进前的SiamMask模型帧率每秒提高3.2帧,算法效率提高约11.94%,可以满足智能安全预警系统的实时快速性要求.
