基于Anchor-free架构的行人检测方法
2020-06-04张庆伍关胜晓
张庆伍,关胜晓
(中国科学技术大学 微电子学院,安徽 合肥 230026)
0 引言
行人检测是智能安防和车辆辅助驾驶等实际应用的关键技术。随着计算机视觉技术的快速发展,目标检测算法的性能也不断提升。目前基于深度学习的目标检测方法按照是否提出预选框可以分为两大类:一类是基于预选框的检测算法,该类算法首先预先设置预选框,然后通过预选框和真实目标进行匹配,最终选出合适的预选框进行训练,这类算法以Faster-RCNN[1]和SSD[2]为代表;另一类是不使用预选框的检测算法,该类算法首先对预测目标的关键点进行标注,然后将深度神经网络的输出设置成相同的格式,直接进行训练,这类算法以YOLO[3]和DenseBox[4]为代表。其中,Anchor-free的算法框架结构简洁,更加适用于计算资源较少的实际应用场景。本文在Anchor-free算法的基础上,首先使用不同的基础网络构建检测算法,然后选出性能稳定的基础网络,利用特征金字塔结构[5]对不同卷积层上的特征图进行融合,提升检测效果,最后使用多尺度预测的方法,通过不同尺度的预测图生成了更多的检测结果,再次提升了检测效果。本文算法在Citypersons[6]数据集上进行了验证,其检测精度相较其他行人检测算法有一定提升。
1 相关工作
1.1 行人检测
到目前为止,行人检测的发展大致分为三个阶段:早期的图像处理阶段(基于背景建模的方法)、特征模型分类阶段(基于统计学习的方法)和深度学习方法阶段。DALAL N等人[7]提出了梯度方向直方图特征(HOG)。HOG基于梯度信息并允许块间相互重叠,用于刻画人体的边缘特征。FELZENSZWALB P等人[8]提出了DPM(Deformable Parts Model)算法,这是一种基于部件的检测方法,对目标的形变具有很强的鲁棒性,采用了改进后的HOG特征、SVM分类器和滑动窗口的检测思想。Zhang Liliang等人[9]将Faster RCNN用在了行人检测领域,通过在RPN网络后添加随机森林,对RPN网络筛选出来的候选区域做分类,提高了网络对于小目标的检测能力。Zhou Chunluan等人[10]为了解决行人检测中的遮挡问题,提出训练两个卷积神经网络分支网络来分别做全身估计和可见部分估计的方法,并将两个分支网络的输出进行互补,以减少遮挡对检测的影响。Liu Wei等人[11]提出了一种级联结构,并将其使用在单步检测框架中,在保证检测速度的情况下,进一步提升了检测精度。
1.2 Anchor-free检测框架
早期的深度学习检测框架多是基于预选框(Anchor-base)的,在使用时,需要在特征图上密集平铺大量预选框,但其中仅有少量样本是正样本,最终导致计算资源花费在无用的样本上。另外,对预选框的预处理进一步增加了算法的计算量。同时,预选框的各项参数都需要人为设置,这使得算法的检测性能会很大程度上受到预设参数的影响,而且调参的过程十分复杂。基于上述原因,Anchor-free算法开始受到关注。DenseBox构建了一种Anchor-free检测框架,即特征提取网络和检测头组合的方式。FSAF[12]则将Anchor-base和Anchor-free两种检测方式相结合,在原有的FPN网络上添加一个分支网络,同时利用两种检测方式生成的结果,在COCO[13]数据集上做出了有竞争力的结果。随后Anchor-free框架逐渐被使用到行人检测的任务中,Song Tao等人提出了基于Anchor-free架构的行人检测方法TLL[14],将人体中轴线作为标注。为了提升检测效果,又采用了基于马尔可夫随机场的后处理方案。Liu Wei等人设计了基于Anchor-free的检测方法CSP[15],将行人的中心点作为标注,其主要关注的是如何用尽量简单的结构完成检测并获得好的效果,其网络结构相较其他工作更加简洁。
Anchor-free框架抛弃了提出预选框的步骤,将算法的流程简化为特征提取、检测头和后处理三个部分。但一味地简化会造成检测精度的损失,所以本文在Anchor-free架构的基础上将算法流程增加为特征提取、特征融合、检测头、后处理四个部分,按照该流程重新设计了卷积神经网络,并使用中心点和高度作为标注训练神经网络,最终在Citypersons数据集上进行验证。
2 算法设计
2.1 模型设计
模型的结构共包括三个部分:特征提取网络、特征融合网络、检测头。模型为全卷积的网络结构。通常将特征提取网络中生成的第N层特征图命名为StageN,特征提取网络可以描述为:
φi=F(φi-1)
(1)
φi表示第i层的特征图,φi-1表示第i-1层的特征图,F表示两个特征图之间的卷积、池化、归一化等操作。可以将N层的特征图表述为一个集合:
Φ={φ1,φ2,…,φN}
(2)
式中,φi表示第i层的特征图,Φ表示所有特征图的集合。然后使用这些特征层构建特征融合模块。构建的方式可以表述为:
(3)
其中,f表示反卷积操作,φ表示特征融合网络的特征图,φ表示特征提取网络的特征图。算法网络结构如图1所示。特征提取网络将输入图像转化成不同分辨率的特征图。以ResNet为例,ResNet的所有中间层可以被划分成5个部分,本文取其中的后四层,分别下采样至原图大小的1/16,1/64和1/256,然后经过特征融合网络生成特征金字塔结构,最后通过检测头生成预测图。训练时使用640×1 280大小的图像,将其下采样至160×320,80×160,40×80这三种大小,然后分别用检测头生成预测结果。

图1 算法网络结构
相比CSP和TLL两种方法,本文的方法增加了特征融合网络,代替了原有的对特征图直接反卷积然后拼接的方式。
2.2 标注方法和损失函数设计
2.2.1 标注方法
使用Anchor-free框架的检测算法的标注方式有检测框的角点、目标中轴线、目标中心点等。为了减少计算量,本文使用目标中心点和目标高度作为标注。通过该种标注方法,生成一张高斯热图,该图可以表述为:
(4)

(5)
其中,x,y是目标中心点在高斯热图中的坐标,(i,j)表示高斯热图中的位置,k表示目标的标号,(σw,σh)为目标的宽和高。生成的高斯热图如图2所示。

图2 高斯热图可视化
可以看出,越靠近目标中心点,标注的值越接近1,越远离目标中心点,标注的值越接近0。
2.2.2 损失函数
总的损失函数由两个部分组成:中心点损失和目标尺度损失。对于中心点的预测,使用Focal Loss[16]。为了平衡正负样本对于总的损失函数的贡献,增加了αij项。

(6)
式中,W和H为原图的宽和高;r为预测图的缩放比例;k表示该原图中目标的个数;Pij表示预测图中坐标为(i,j)的点上的预测值;yij表示预测图中坐标为(i,j)的点上是否存在中心点;γ和β是两个可以设置的超参数,分别用于控制训练速度和正负样本平衡;Mij的含义如式(4)所示,表示预测图中坐标为(i,j)的点上的标注值。
对于目标高度的预测,使用SmoothL1[17]损失函数使训练过程更加平滑,函数表述为:
(7)
(8)
其中,sk、tk分别是目标高度的预测值和真实值,将sk、tk的差值作为SmoothL1函数的输入。k是目标的标号,K表示所有目标的个数。
总的损失函数可以表述为:
L=λcLcenter+λsLscale
(9)
其中,L表示总的损失函数,Lcenter和Lscale的含义如式(6)和式(7)所示。λc和λs分别设置为0.01和1,用于控制两部分损失函数的比重。
3 实验
为了对本文提出的方法进行有效的评估,使用Citypersons数据集进行验证。该数据集共有2 975张图片,包含19 238个行人,平均每张图片上含有行人6.47个。其中被轻微遮挡的目标占整个数据集的55.9%,被一般遮挡的目标约占整个数据集的20%,检测难度相对较大,更加适合验证算法的性能。实验均在Ubuntu16.04操作系统,GTX080Ti的GPU集群上使用Keras框架完成。
为了更好地评估算法的性能,将检测指标分成三类,各种遮挡情况下的数据示例如图3所示。严重遮挡示例(遮挡率60%以上)如图3(a)所示,普通遮挡示例(遮挡率30%~60%)如图3(b)所示,轻微遮挡示例(遮挡率30%以下)如图3(c)所示。其中遮挡率是被遮挡部分与目标大小的比值。

图3 验证集部分样本图
3.1 不同基础网络的实验效果
特征提取网络是Anchor-free算法的基础网络,为了选择合适的基础网络,首先对各种基础网络的性能进行测试,也就是分别利用不同的基础网络进行特征提取,然后比较检测效果。比较的结果如表1所示,评估指标使用漏检率(Miss Rate)。

表1 各种基础网络性能比较 (%)
经过比较,ResNet的性能最为稳定,MobileNet的速度更快,但是检测精度略有下降。由于显存爆炸问题,本文将DenseNet的批尺寸(Batchsize)设置为4,但其整体性能仍略逊于ResNet。所以本文使用Resnet-50进行后续实验。
3.2 特征融合策略
为了能将含有更多细节信息的浅层特征图和含有更多语义信息的深层特征图进行融合,本文在算法中加入了特征金字塔网络(FPN)结构。加入FPN后的实验结果如表2所示,结果从100到150 Epoch中选取。

表2 加入FPN后的实验效果 (%)
从表2可以看出,加入FPN后,轻微遮挡和一般遮挡情况下的检测效果并没有明显变化,遮挡严重情况下的检测效果提升较为明显,检测结果如图4所示。产生该现象的原因是被遮挡目标的信息在池化过程中会不断丢失,而浅层特征图能保留这些信息,深层特征图能更好地描述目标的位置信息。所以使用FPN融合两种特征图能够提升严重遮挡情况下的检测效果。

图4 加入FPN后的部分检测结果
3.3 多尺度预测
为了获得更好的检测效果,本文采用了多尺度预测的方法。分别使用FPN三个不同尺度的特征图生成预测结果。预测得到的高斯热图分别为原图大小的1/16,1/64,1/256,再将所有的检测结果整合。将结果在Citypersons数据集上与其他算法对比,结果如表3所示。
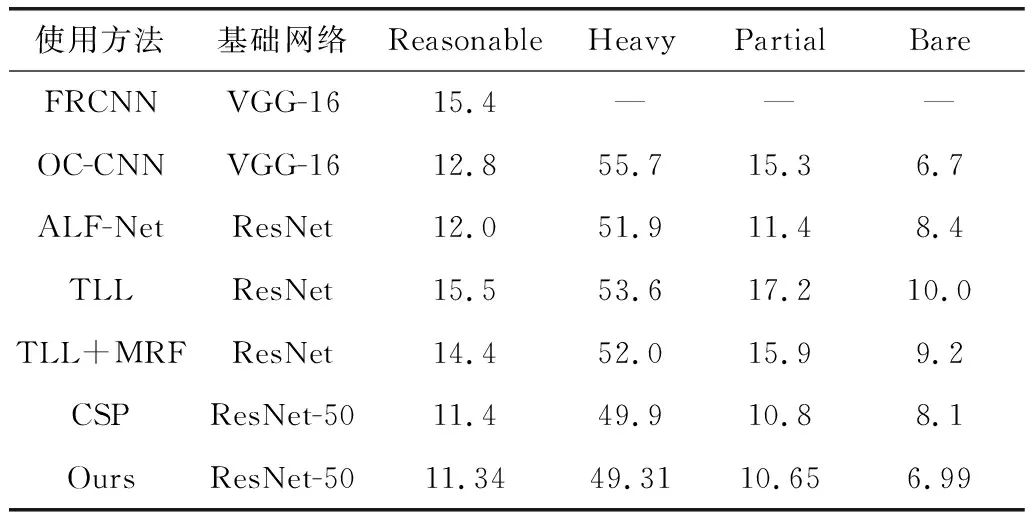
表3 行人检测算法效果对比 (%)
与其他算法的实验结果相比,本文算法在目标遮挡严重和普通遮挡的两个指标上有更好的表现,原因是由于使用了多尺度的检测结构,同一目标的周围产生了更多的高质量预测框,且多尺度预测针对不同大小的目标有着不同的预测效果,小尺度的预测图更加适合预测大型目标,大尺度的预测图对小目标的预测效果更好。
使用多尺度检测方法后,在严重遮挡情况下的漏检率有所上升,但是普通遮挡和轻微遮挡时漏检率均有所下降,检测结果如图5所示。产生该现象的原因是由于在严重遮挡情况下,在目标周围生成的预测结果更多,但后处理过程使用了非极大值抑制(NMS),并没有处理这些无效预测框,反而将正确结果抑制删除。

图5 使用多尺度预测方法后的部分检测结果
从上述结果可以看出,检测失败的情况多为无效检测或重复检测。造成该现象的原因是多尺度预测策略同时增加了正确和无效的检测结果,且无效检测结果的数量更多。针对该问题,本文尝试了不同的输出阈值,即为预测得到的高斯热图设置一个阈值,若预测值大于该阈值则认为该点存在目标中心点。实验结果如图6所示。

图6 漏检率和输出阈值的对应关系
从图6可以看出,随着输出阈值的提高,漏检率先降低后升高。算法在输出阈值设为0.15时检测效果最好。这是由于输出阈值过小会导致算法输出大量的无效预测,而过高的输出阈值又会抑制算法输出正确结果。
本文使用的测试用例共500张,测试图片大小为1 024×2 048,测试10次取平均值。平均每张图片耗时0.36 s。将图片缩放至480×640大小后,平均每张图片耗时约61 ms,基本满足应用要求。
4 结束语
本文基于Anchor-free架构,设计了一种特征提取、特征融合加多尺度检测头的网络结构。融合了不同特征图的信息并对同一目标提出了更多的有效预测,实验证明该方法提高了检测效果。
由实验结果还发现,在使用多尺度预测方法后,目标周围产生的部分无效预测会抑制正确结果,导致检测失败。解决这个问题需要对检测结果做进一步后处理。Anchor-free架构往往采用NMS进行后处理,所以下一步可以通过优化NMS进一步提升检测效果。
