基于深度强化学习的公路初始路径寻优方法
2020-05-14李懿韩春华钱熙孟靖凯
李懿,韩春华,钱熙,孟靖凯
(昆明理工大学 交通工程学院,云南 昆明 650500)
选线是新建道路从规划设计到投入使用过程中的关键环节。目前,中国的道路设计选线仍然采用人工的方式。通过设计者的经验对路线进行比选。且通过经验选取的路线没有一个标准对其优劣进行评价,只存在相对而言较优的路线。因环境复杂决定了路线设计将是一个漫长且包含着大量重复工作的过程[1]。因此,采用智能化的方式进行选线可以缩短设计路线和节省许多重复工作。
具备学习能力是人类智能的特点,人们在处理问题时之所以能判断问题的关键并给出正确的决策,其原因在于人们擅长在处理问题的过程中总结经验教训,找到正确处理某项事务的规律性。使计算机具备学习的能力且模拟或实现学习以专家经验为目的的机器学习[2]是人工智能运用于智能选线的一个全新领域,它的研究对于智能选线的进一步发展有着举足轻重的作用。
本研究在 Mnih[3]用强化学习的方式让智能体自动学会玩游戏,探索强化学习在选线领域的方法应用。Mnih提出了“利用强化学习从高维输入中直接学习控制策略”的深度学习模型。该模型使用卷积神经网络,经过Q-learning算法的训练,输入图像像素,输出预估的奖励值(reward)函数,并将此方法应用于7款atari游戏,且在3款游戏中超过了人类专家。得益于Mnih的研究,很多基于感知识别并采取决策的问题得以解决。智能选线的条件与Mnih的研究相关的众多决策问题拥有共同的理论基础,都遵循于马尔科夫决策过程:理想的状态是可检测的;可以进行多次尝试;系统的下个状态只与目前的状态信息有关,而与较早之前的状态无关;决策过程还与当前采取的动作有关。采用强化学习来解决路线优化问题。因此,作者提出基于深度强化学习的公路初始路径寻优方法,拟实现的过程为:①构建基于马尔科夫决策过程的最优路径问题模型和适用于选线的强化学习方法模型。以全局最大价值奖励为目标,建立适合于线路标准的智能体奖励规则。②将Q-learning算法思想采用神经网络进行优化。使用“时间差分”的方法,对神经网络参数进行更新(神经网络解决了 Q-learning算法“维度灾难”的问题,使网络能够快速达到收敛)。③采用神经网络接收状态和行为信号,并输出所采取行为的价值。经过多个回合训练后,神经网络收敛到一定的水平,生成一条较为合理的最优路径。
基于深度强化学习的公路初始路径生成的实现可解决人工选择路线无法趋近于最优的问题,为基于深度强化学习的公路路线路径的生成提供基础。
1 模型的建立
1.1 马尔科夫决策过程
马尔科夫决策过程(Markov Decision Process,简称为 MDP)是强化学习中最基本的理论模型[4]。通常情况下,MDP可以表示为 < S , A, R, T >四元组的形式:S为状态空间(State Space),包含了智能体可能感知到的所有环境状态的集合;A为动作空间(Action Apace),包含了智能体在每个状态上可以选取的所有动作集合;R:S × A × S → R 为奖励函数(Reward Function), R ( s , a, s′)表示在状态s上选取动作 a,并转移到状态 sʹ时,智能体从环境变换中所反馈的奖励;T: S ×A×S→[0,1]为环境的状态转移函数(State Transition Function),T ( s , a, s′)表示在状态s上选取动作a,并转移到状态sʹ的概率。
在MDP中,智能体和环境之间的交互过程如图1所示。智能体感知当前环境状态st,从动作空间A中选取动作at并执行;当环境接收到智能体所选取的动作之后,智能体反馈到相应的奖励信号rt+1,并移动到新的环境状态st+1,等待智能体做出新的决策。因此,可以对基于栅格的最优路径问题建立模型。
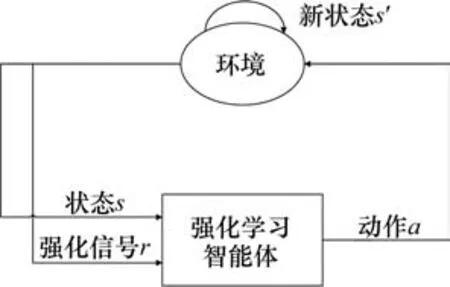
图1 强化学习模型Fig. 1 Reinforcement learning model
1.2 基于栅格地形的最优路径DMP模型
设定一个智能体在实际地形中执行寻路任务后,定义栅格地形中包含地理属性的每个单元所组成的集合为智能体进行交互的环境,其中:M{m0,m1,m2,…,mt}为每个栅格单元所包含地理属性的集合。在与环境交互的过程中,智能体每移动一个单元,都会获得环境变化所反馈的奖励,而智能体最终的目标是寻求一个最优策略π*,使它在任意状态s和任意时间步骤t下,都能够获得最大的长期累积奖励。即:
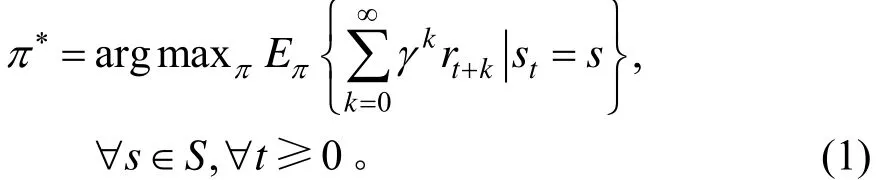
为了最优策略π*,在智能选线中寻求的最优状态值函数为:
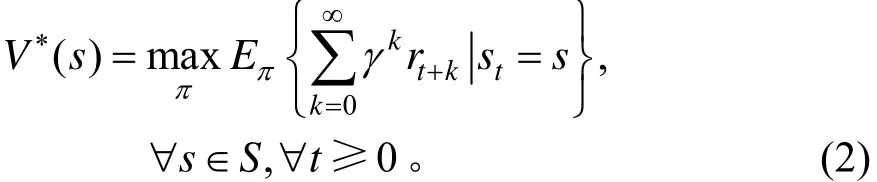
或最优状态-动作值函数为:
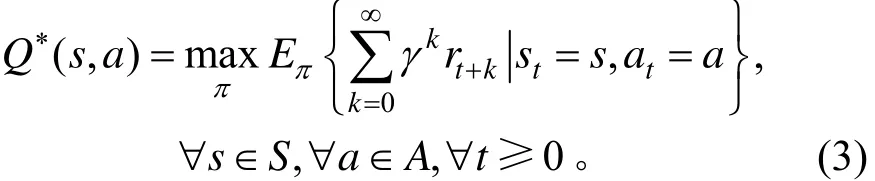
因为动作空间A,状态空间S均为有限集合,所以可以采用求和的方式来计算其对应的期望,对于策略π和任何状态S,都可以将式(2)表示为:
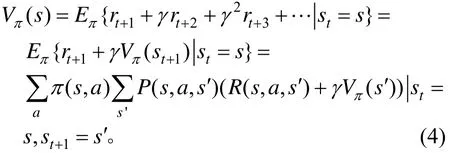
式(4)即为著名的贝尔曼(Bellman)方程。由式(4)可知,若状态转移概率和奖励函数已知,则可求得态值函数。由状态值函数与状态-行为值函数的关系,可以将状态-行为值函数表示为:
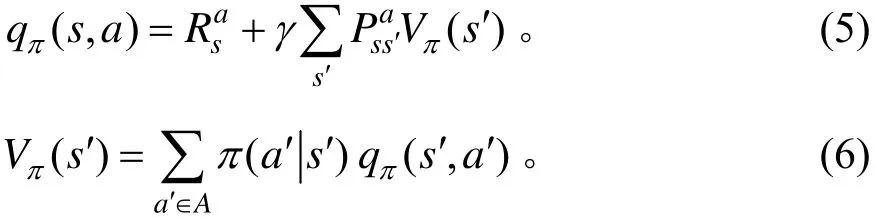
将式(6)代入式(5)中,得:
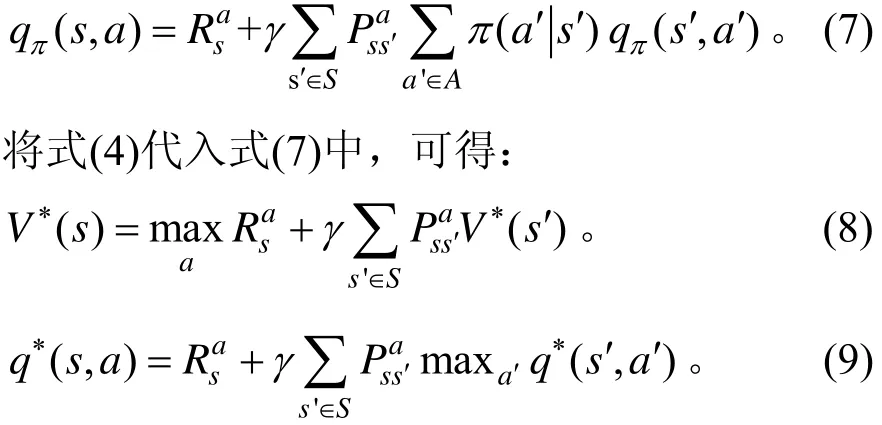
由式(8),(9)可知,在某个状态下的最优价值函数为智能体在当前状态下所能获得的累计期望奖励的最大值。
1.3 奖励函数的设定
奖励函数定义了智能体在专家采取策略时所要选择的目标特征,智能体在所感知的环境状态中反馈一个强化信号 r,对其动作所产生的影响给出一种评价。因此,对智能体变换环境所产生的属性变化设定一个评价规则,即:

式中:Δm为环境属性的变化。
设:当环境变化时,高差的变化或者坡度的变化为属性的改变。当高差的变化大于c时,智能体就会从环境中反馈到对其不利的信号 r,其他的情况保持奖励不变,这样能够保证智能体在满足约束条件下有探索最短路径的能力。
如图2所示,以s(2,3)为例,将s(2,3)作为状态s,则处于当前状态可以选取的动作空间有上、下、左、右 4种方式,以高差最小为智能体选择行为所回馈的最大奖励,则智能体将有较大概率学习上、下、左、右的行为中价值最大的行为,并在每个回合中不断强化,最终使奖励函数达到最大值。
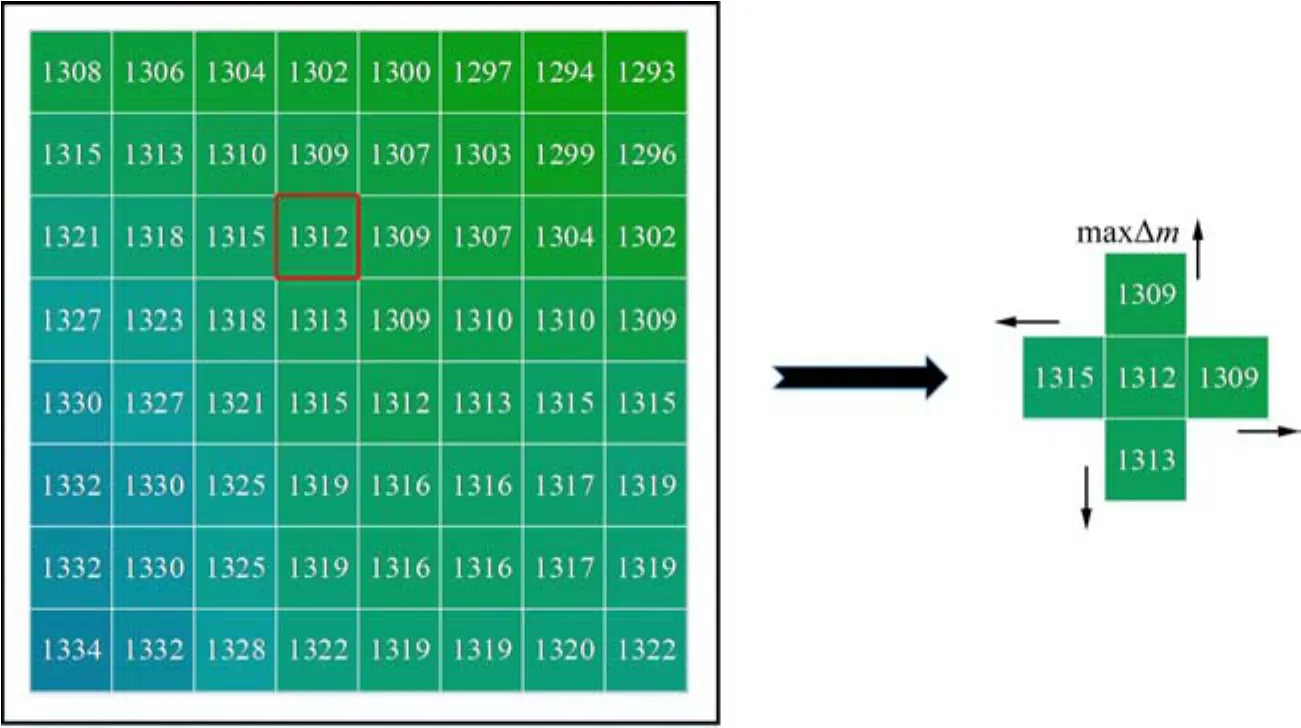
图2 奖励反馈过程Fig. 2 Reward feedback process
在实际选线的过程中,由于地形环境条件的限制,通常专家们会采取一些相对应的解决措施。如:自然保护区、地质灾害地段,在路线设计的过程中会合理地选择避开;或者有一些站点是路线必须经过的地方,在专家的选线经验中就得予以考虑。若该情形设置智能体在途径禁止通行区域时,环境反馈一个负向的信号 r;通过必经站点时,环境反馈一个正向的信号 r。这样,就能保证智能体在经历学习之后,会走符合要求的路线,也会顺利避开禁止通过的区域。设禁止通行的区域为集合o={o0,o1,o2,…},必经区域集合为p={p0,p1,p2,…},则环境反馈的信号为:

2 深度Q学习算法在的应用
基于提出的模型,将Q-learning的思想用神经网络来进行优化。把智能体所处的位置S和所要采取的行为A输入神经网络,再从神经网络输出状态-行为值,将状态-行为值函数表示为 Q ( s, a;θ) ,其中:θ为神经网络的参数。深度Q学习模型如图3所示。
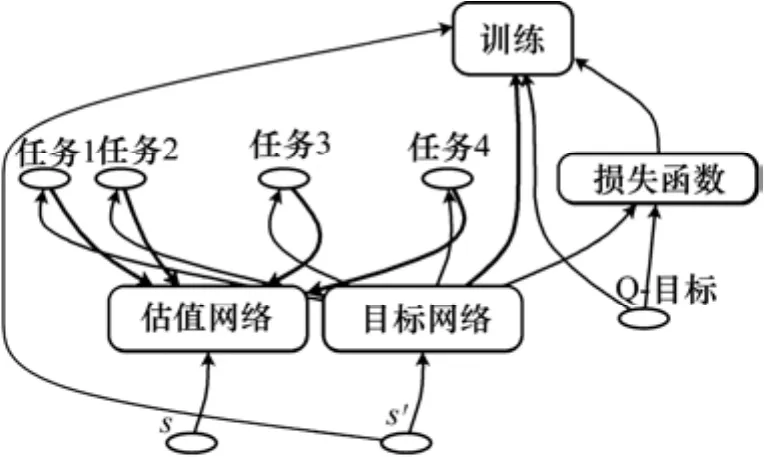
图3 深度Q学习模型Fig. 3 The deep Q-learning model
2.1 主体框架
考虑到有很多离散的方向选择动作和问题的应用情形,本研究采用的深度Q学习基于值函数的强化学习方法。先建立2个结构相同的神经网络:①值函数网络(target网络);②逼近值函数所用的网络(eval网络)。得到2个网络之间的偏差。通过时间差分的方式来更新当前的行为值函数。由此,深度Q学习中每一轮迭代的损失函数为[6]:
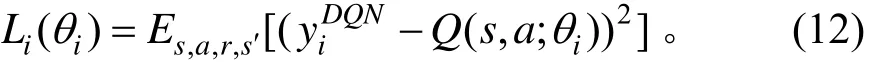
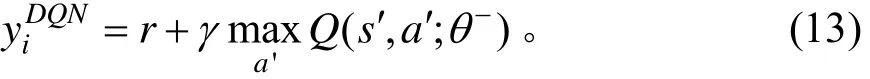
时间差分采用经验回放的方法来提升神经网络的效果。智能体从很多的回合中获得经验将它存储到经验池D中形成了一个缓存空间,然后,从这个空间中随机采样来获得样本进行网络的训练。则其损失函数可表达为:
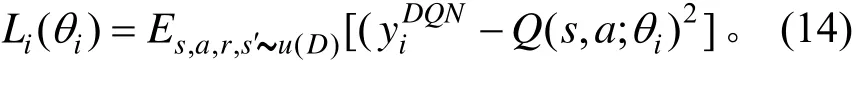
经验回放可以打破数据间的关联使神经网络能够收敛且稳定[7]。
2.2 ε-greedy 策略
通过神经网络,奖励被反馈到决策阶段,智能体是要采取当前最优价值下的路径还是选择探索更优的路径是当下需要解决的问题。在模拟环境开始的阶段,对Q-网络进行随机初始化。由于它给出的 Q最高的行为是随机的,智能体表现出随机的“探索”。当网络收敛时,随机“探索”的情况逐渐减少。但是,这种探索是“贪心的”,智能体只会探索当前模型认为最好的策略[8]。因此,本研究采用ε-greedy贪心策略来决定动作的选取,ε-greedy策略的最大化平衡了“利用”和“探索”之间的概率关系,选择动作空间中价值最大的动作为利用,其他非最优动作仍有概率去进行探索。
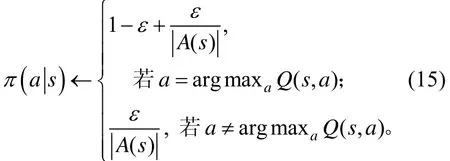
2.3 算法流程
采用强化学习的值函数估计的方法,并使用深度神经网络来进行拟合。为解决智能体在一个回合中走相同的位置或者陷入一些无效的区域,采用禁止智能体回头和重复走相同位置的方法,减少了智能体一些无效的学习。考虑历史学习经验的深度Q学习算法步骤为:
1) 开始。
2) 初始化经验池 D和设置经验池的最大容量N。
3) 初始化当前网络参数θ和目标网络参数θ-。
4) 初始化状态空间s0。
5) 利用概率ε选取随机行为at。若随机事件没有发生,则用贪婪策略选取最大动作值函数对应的动作。
6) 模拟动作 at并观察奖励 rt和执行动作下的环境st+1。
9) 从经验池D中抽取经验。
11) 执行一次梯度下降算法。
12) 更新动作值函数逼近的网络参数θ =θ+Δθ 。
13) 每隔 C步更新一次时间差分目标网络权值,即令θ-=θ。
14) 结束。
3 实验结果
依托云南某山地地形进行训练,选取地形范围为2.02×1.16 km2。为避免智能体过早地陷入局部最优以及权衡当前和远期的利益,需要合理设置学习率和折扣率,本实验设置学习率为0.01,折扣率为0.9,贪心度为0.1,坡度约束为8%。将实验的过程以可视化的方式进行了展示。训练过程曲线如图4所示。从图4中可以看出,在150个回合前,为智能体对路径的探索;在150个回合后,网络达到了收敛,路径探索终止。
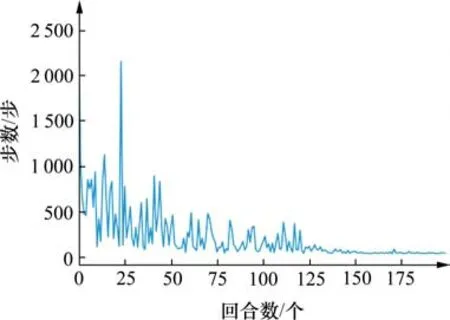
图4 训练过程曲线Fig. 4 Training process
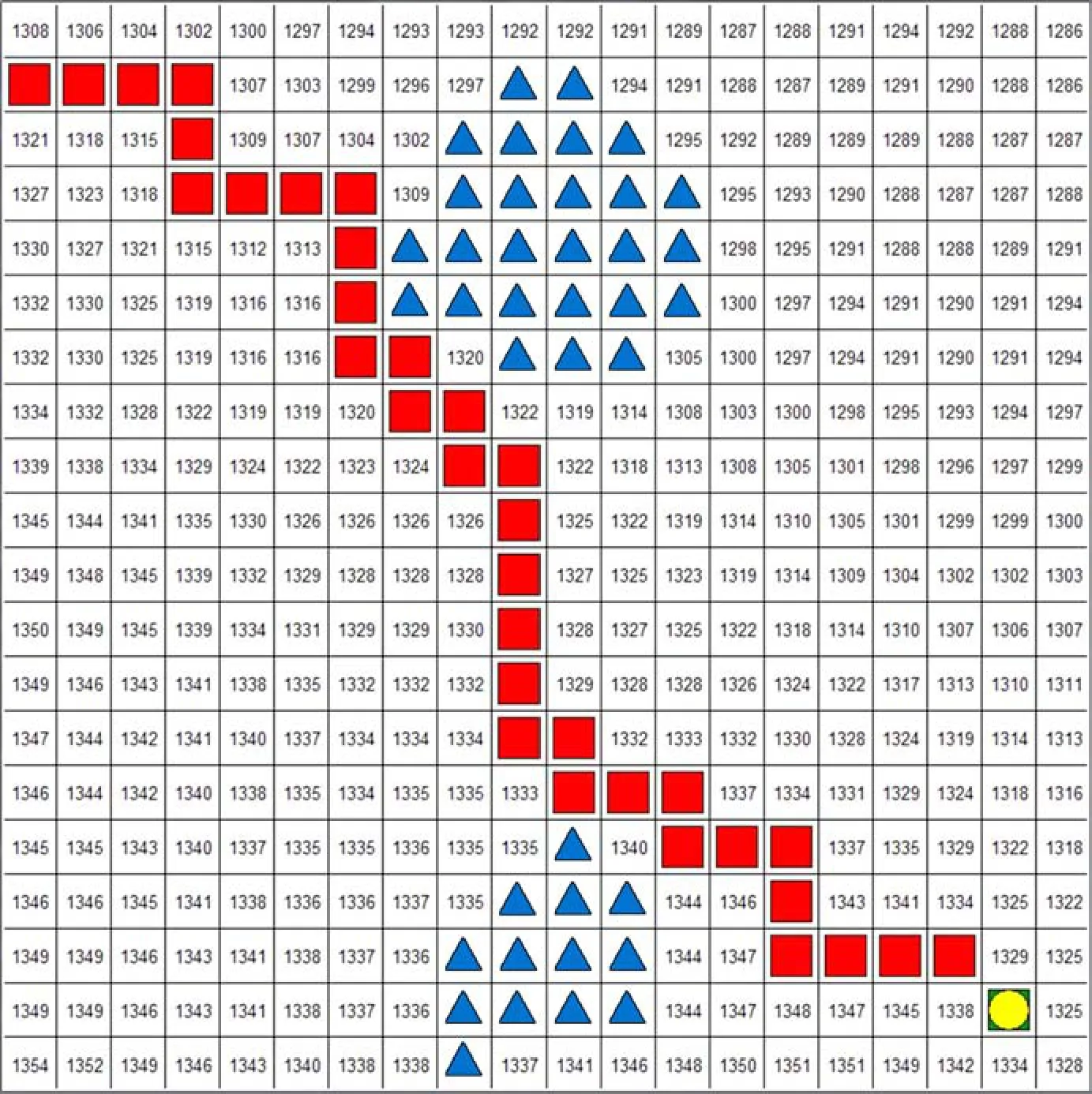
图5 虚拟环境下生成最优路径Fig. 5 The generation of the optimal path in the virtual environment
实验采用python语言进行了编程,以图形化的方式将智能体与环境交互的过程展示出来,并在模拟环境下绘制路径,如图5所示。在图5中区域为路线走向,蓝色区域为定义的禁止通行区域。导出最终路径数据,在地形图中生成路径,路径长度为2.21 km,如图6所示。智能体在山体中探索路径具有对禁止通行的区域进行绕避的能力,也能成功避开地势较高的区域,选择符合要求的最优路径。

图6 地形环境中生成最优路径Fig. 6 The generation of the optimal path in the terrain environment
4 结语
公路初始路径的生成以最小坡度为目标,通过智能体反复遍历全图栅格,不断强化目标信息,生成目标条件下的最优路径。该方法可以在指定的起始点和终点之间生成满足要求的最优路径,解决了选线过程中通过经验选择路线的弊端,也为基于强化学习的公路路线路径生成打下了基础。
本研究采用强化学习法在智能选线中的应用做出了一些尝试,但还未成熟。如:在复杂的地形条件下,智能体所学习的特征过于单一。在实际地形情况下,存在着高山变平地,平地变高山,或者需要跨过河流诸如此类的复杂地形,这就需要智能体有感知能力。监督学习能通过智能体对地形的识别来决定未来探索的方向。强化学习在选线方面的应用还存在着较大的潜力,且前景广阔。
