近红外高光谱图像的宁夏枸杞产地鉴别
2020-05-07张小波于丽娜李卫军黄璐琦
王 磊,覃 鸿*,李 静,张小波,于丽娜,李卫军,黄璐琦
1. 中国科学院半导体研究所高速电路与神经网络实验室,北京 100083 2. 中国科学院大学材料科学与光电子工程中心,微电子学院,北京 100049 3. 中国中医科学院中药资源中心道地药材国家重点实验室培育基地,北京 100700 4. 中国中医科学院道地药材国家重点实验室培育基地,北京 100700
引 言
宁夏枸杞(Lycium barbarum)是茄科枸杞属的一种,果实称为枸杞子[1]。 近现代医学研究表明,枸杞子具有抗氧化、抗疲劳、降血脂、降血糖等多方面的药理功效[2]。 宁夏枸杞是《中华人民共和国药典》中唯一列为药品的枸杞品种[3]。 宁夏产地的枸杞由于色艳,皮薄,肉厚,甘甜,活性成分多以及药用价值高而受到消费者的青睐。 但是品质优良的枸杞子受制于种植面积,产量有限,市场流通的商品来源无法确保,致使枸杞子市场混乱,以其他产地假冒宁夏产地的现象频发[4]。
鉴别枸杞子的传统方法有性状鉴别、显微鉴别、化学成分分析鉴别、分子生物学技术鉴别等,但是这些方法周期都比较长且具有破坏性,不能批量鉴别[5-6]。 王欢[7]等研究了不同产地宁夏枸杞药用活性成分的差异,发现不同产地的枸杞多糖及甜菜碱含量存在显著性差异。 曲云卿[8]等研究了不同产地枸杞类胡萝卜素含量的差异。 不同产地中枸杞成分含量的不同,可以反映出枸杞内部含氢基团对近红外谱区具有不同的吸收强度,以上研究为使用近红外光谱建立枸杞产地鉴别模型提供了依据。 然而枸杞子样本较小、形状不规则、成分分布不均匀,近红外光谱鉴别通常需要把样品碾碎成粉末,无法做到无损批量地采集光谱数据。 近红外高光谱图像结合了近红外光谱和图像,包含丰富的空间信息和光谱信息,可以实现无损批量地采集非均匀样本光谱信息。
采用近红外高光谱图像技术进行枸杞产地的鉴别,为建立快速有效的枸杞产地鉴别模型提供实验依据。 通过比较ZCA白化[9]预处理和常用的标准化预处理,采用偏最小二乘降维[10-11]算法对输入数据进行降维,验证SVM[12],LDA[13],Softmax[14]不同分类器性能表现,提出了在当前应用场景下快速有效鉴别枸杞产地的方法。
1 实验部分
1.1 枸杞样本
样品的品种都为宁杞1号,产地分别为内蒙新安镇、甘肃靖远县、青海都兰县、新疆精河县和宁夏银川市。 样品从产地收集,每个地方采集330个样本,统一烘干保存。 使用近红外高光谱图像设备分三批采集数据,每批每个产地采集110个样本的高光谱信息。 接下来使用随机采样的方法分割训练集、验证集和测试集。 从第一批和第二批中每个产地随机选取150个样本作为训练集,剩下的作为验证集,第三批数据单独作为测试集,该方法重复50次用来观察模型稳定性。
1.2 近红外高光谱图像系统
采集数据用的是实验室级别的高光谱相机,相机是Norsk Elektro Optikk AS(NEO)公司研发的HySpex系列的SN3124 SWIR-384。 光谱范围是948.72~2 512.97 nm,波段间隔5.45 nm,总共288个波段。 采集数据参数设置包括高光谱成像仪的镜头与枸杞子距离为20~30 cm; 平台移动速度为1.5 mm·s-1; 积分时间4 500。 高光谱图像采集系统示意图如图1所示。

图1 高光谱图像系统示意图
1.3 获取高光谱图像数据
批量的把样本按图1所示摆放在移动平台上,样本之间没有重叠,高光谱设备采集数据,数据分析全部采用MATALB 2017b。
枸杞在近红外谱区吸收较弱的波段,对应的反射率相对较大,可以体现出样本与黑板之间更明显的差异性,有利于通过图像处理分割出样本位置。 选择1 107 nm波段进行图像处理操作,然后进行掩模处理。 阈值分割可以从背景中分离出样本,通过公式(1)计算样本平均反射率,Iraw其中表示样本光谱反射值,Idark表示黑板光谱反射值,Iwhite表示白板光谱反射值,Inew为计算得到的光谱反射率。
(1)
1.4 数据处理
1.4.1 ZCA白化
采集的高光谱图像光谱波段之间具有很强的相关性,常用的去均值和标准化(特征去均值除方差)等方法都是基于高斯归一化去平移或缩放原始数据的特征,并没有有效的去除特征之间的相关性。 因此,采用白化让原始数据经过一个线性变换得到的新数据的协方差矩阵为单位矩阵来去除相关性。 白化的方式并不唯一,本实验选择了ZCA白化得到接近原始数据的新特征。 ZCA白化的算法实现步骤如下:
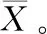
(3) 接下来对Σ进行奇异值分解得到左特征向量矩阵U和特征值矩阵S。
1.4.2 偏最小二乘降维(PLSDR)
近红外高光谱图像系统波段较多,数据具有多维度的特点。 对输入数据降低维度可以使后续的分类器设计在计算上更容易实现。 常用的主成分分析(principal component analysis, PCA)在映射过程中只是保留数据集中对方差贡献较大的特征,映射时没有利用数据内部的分类信息,所以降维后的特征在分类器的表现可能相对较差。 PLSDR结合PCA的优点,使得原始数据的隐藏特征和预测变量具有最大相关性,可以减少原始数据中与预测变量无关的信息,使新的隐藏特征更有利于分析,该方法在光谱数据处理中应用十分广泛。
定义矩阵T=[t1,…,tK]∈Rm×K表示m个观测样本的K个隐藏特征,T与预处理后的数据X的关系表述如式(2)。
T=XW
(2)
W=[w1,…,wk]∈Rn×K是线性映射矩阵。 第一个隐藏特征为t1=Xw1,通过拉格朗日乘子法求解公式(3)可以得到w1=XTY/‖XTY‖。
(3)
基于第一个隐藏特征,X和Y可以按照式(4)做如下分解。
(4)
式中,p1和q1可以通过最小二乘算法求解,残差矩阵E,F可以作为新的X和Y,通过迭代继续求解新的隐藏特征。
1.5 产地鉴别模型
要对多个产地进行分类,一般有one vs all和one vs one投票的方法进行多分类。 为了避免分界面具有不确定性区域、投票时票数相同以及增加模型复杂度等问题,采用了基于统计学中最大似然估计框架的Softmax进行多分类,同时和SVM和LDA模型做比较。
2 结果和讨论
2.1 光谱特征曲线
不同产地的宁夏枸杞的全波段(948~2 512 nm)平均反射率光谱如图2所示。 通过图2可以看出不同产地的平均曲线趋势相似,但是每个波段对应反射率值不同,代表内部的化学成分含量不同。 相似性可以体现在它们都是宁夏枸杞这一品种; 差异性的影响因素可能比较多,包括地理环境,天气,种植培育过程等。

图2 不同产地的枸杞的全波段(948~2 512 nm)平均反射率
Fig.2MeanreflectancespectraofLyciumbarbarumfromdifferentregionsinthefull-bands(948~2512nm)
NM: Inner Monglia; GS: Gansu; QH: Qinghai;
XJ: Xinjiang; NX: Ningxia
2.2 ZCA白化预处理结果
训练集经过ZCA白化预处理后,对青海和宁夏两个产地的数据取平均得到图3。 从图3可以清楚的看出经过ZCA白化处理后的数据变的具有离散性,放大了每一个波段的差异性,同时去除了原始数据不同波段之间的相关性,结合ZCA白化的理论分析表明ZCA白化可以很好的去除特征之间的相关性。
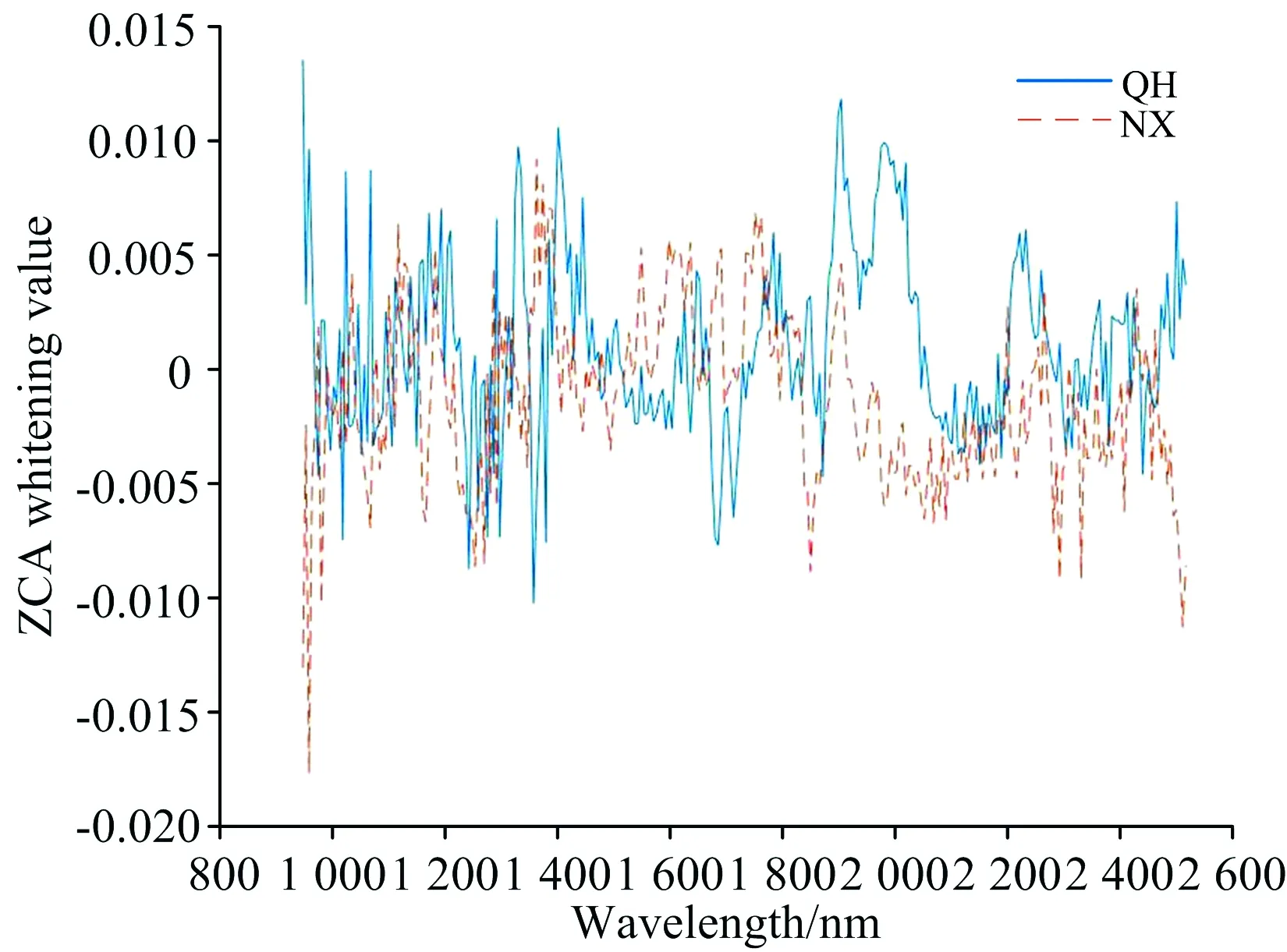
图3 ZCA白化预处理结果示意图
2.3 调参结果
使用不同的数据分析方法建模时,都需要进行调参。 采用PLSDR和Softmax进行分类时,可以设定主成分数ncomp=[1∶60]以及正则项参数λ(lambda)=[1e-1,1e-2,…,1e-8]进行网格调参。 图4和图5是分别使用标准化和ZCA白化预处理后的调参结果。 从图4可以看出经过标准化预处理后PLSDR算法降低到40个主成分,识别结果趋于稳定(96.54%±0.05%),当主成分数大于40时,正则项参数的影响弱化。 ZCA白化预处理后的调参结果与标准化类似,但是可以降低到4个主成分来表示。 正则项参数是用来防止模型过拟合的,但是这个参数不是非常敏感。 如果设置太大,会出现欠拟合现象。 由于降低到一定主成分数之后,正则项参数的影响效果不是很明显,本实验统一设置λ为1e-6。
图4 标准化模型的调参结果

图5 ZCA白化模型的调参结果
当使用SVM分类器时,也有两个重要的参数c和g进行调参。 参数c是惩罚因子,表示对错误分类的容忍度。c越大越容易导致过拟合,反之c越小越容易欠拟合。 参数g是RBF核自带的参数,隐含地决定了数据映射到新的特征空间后的分布,g越大,支持向量越少,g越小,支持向量越多。 同样使用网格调参法,设定c=[0.1, 0.3, 1, 3, 10, 30]和g=[0.01, 0.03, 0.1, 0.3, 1, 3]寻找一组相对较好的模型参数。 最后寻找到合适的参数为c=1,g=0.01。
2.4 识别性能
通过对比实验,得到了如表1所示的不同模型的识别结果。 对比模型1和模型2的结果,ZCA白化预处理模型在测试集上的平均准确率(93.87%)比标准化预处理模型在测试集上的平均准确率(87.23%)要高出大约6.6%。 ZCA白化模型在测试集上的准确率标准差(0.008 8)相对较低,说明多次随机采样建模测试结果的离散程度较低,ZCA白化模型的鲁棒性更好,而且ZCA白化模型具有较低的建模测试运行时间(3.54 s)。 以上实验结果表明ZCA白化去除特征之间的相关性的同时,还可以提升模型准确率。 因此,ZCA白化是一个有效的预处理方法。

表1 不同模型的结果
从模型1(87.23%)和模型3(90.17%)的结果来看,PLSDR算法提升了模型1大约3%的准确率。 原始数据的288个特征可以降低成40个特征,这一点也可以表明原始数据的冗余性。 同时,建模及测试运行时间被大大压缩。
通过分析模型2(93.87%)和模型4(94.06%)的结果表明PLSDR算法稍微增加了模型2的准确率。 但是,使用PLSDR算法可以把输入特征降低成四个特征去表示。 经过ZCA白化变换后的数据,相对原始数据来说丢失了一部分原始信息,因此PLSDR并没有显著的提升ZCA白化模型的效果,但是可以从ZCA白化后不相关的特征中提取更有效表示输入数据的特征。 经过降维后,模型4的识别率仍是远远优于模型3的识别率,而且从模型复杂度角度来看,ZCA白化后的模型也是优于标准化模型,建模测试运行时间也更短,方便实时测试。
模型6使用了SVM分类器,编程实现借用了LIBSVM提供的工具箱。 另外,该多分类问题的实现采用了one vs one方法。 SVM模型降低到100个主成分时,在测试集上的准确率趋于稳定仅有88.25%,并且建模及测试运行时间为134 s。 这个结果表明SVM分类器表现相对较差,而且采用one vs one方法建模复杂度太高。
LDA多分类的实现同样采用了one vs one方法,建立了10个LDA分类器投票分类。 从模型5的结果可以看出在测试集上的准确率为93.85%。 同时该模型的准确率也具有较小的标准差(0.007 6)和建模测试运行时间(3.51 s)。 LDA的结果表现不错也可以反映出当前实验的数据集有很强的线性关系,所以使用Softmax的结果很好是可以预期到的。 仅从当前数据集来看,LDA和Softmax模型都表现不错,但是Softmax模型具有很强的泛化能力,当面对非线性数据时,它可以作为神经网络的最后一层处理非线性数据。
3 结 论
近红外高光谱图像结合图像和近红外光谱可以快速无损批量采集样本数据,通过图像处理可以有效提取出对应样本信息。 结合理论分析和实践验证,提出了一种快速有效处理高光谱数据的方法。 先使用ZCA白化预处理去除输入特征的相关性,接着通过PLSDR算法提取输入特征与类别之间具有最大相关性的主成分,降低模型复杂度,最后通过Softmax分类器从概率角度对输入数据进行分类。 这个模型在当前枸杞产地鉴别的应用场景得到了很好的表现,50次结果测试集的平均准确率达到了94.06%,同时标准差仅有0.009,说明模型的鲁棒性很好。 在当前数据量不是很多且分类类别相对较少的情况下,这个模型的优势并没有完全体现出来。 未来有新的应用场景,而且数据非线性特征较强时,模型也可以很好的迁移新问题上面,把Softmax分类器作为神经网络的最后一层去处理非线性数据。
