Lustre语言可信代码生成器研究进展
2020-05-04侯荣彬
兰 林,马 权,侯荣彬,蒋 维,杨 斐
(中国核动力研究设计院 核反应堆系统设计技术重点实验室,成都 610213)
0 引言
安全攸关的嵌入式控制领域(如核仪控、轨道交通等领域)常使用基于Lustre语言描述的图形化逻辑建模工具(如SCADE等)来开发控制逻辑,然后使用代码生成器将控制逻辑翻译为C代码。这些领域对软件的安全性要求非常严格(如在核仪控领域中必须满足核电标准IEC60880)。因此,为保证嵌入式软件的可靠运行,必须考虑代码生成器(编译器)的可靠性。如果代码生成器存在潜在的错误,将会有产生不安全代码的风险,由此可能带来巨大的灾难和损失。目前,主要是通过反复的测试和严格的过程管理等传统方法来保证代码生成器的可靠性。但代码生成器在开发过程中引入的错误通常是很难发现的,采用传统的方法无法杜绝代码生成器的误编译。经过传统方法开发的编译器如GCC、LLVM,通过Csmith工具发现了多个错误,即使工控领域广泛使用的SCADE Suite也不能证明它不会出现误编译。而通过形式化方法开发的代码生成器,能够在开发的同时,对其翻译前后语言语义一致性进行逻辑推理证明,能够最大限度地消除误编译。本文将在阐述可信代码生成器形式化开发方法的基础上,介绍同步数据流语言Lustre的特征及相关可信代码生成器的形式化研究进展。
1 Lustre语言
Lustre作为一种同步数据流语言,最早出现在P.Caspi的论文中[1],多用于嵌入式控制系统和信号处理系统。它在工控领域主要用于描述实时控制逻辑,核仪控、航天航空、轨道交通等安全攸关领域广泛使用的SCADE Suite就是基于Lustre语言描述实现的。Lustre语言具有数据流特征和确定性语义[1],适用于反应式控制系统编程、模块化的代码生成[2]以及程序的形式化验证[3-5]。Lustre程序是由一系列的node或 function声明、常量声明和数据类型声明组成,node或function是用于处理输入流并输出的函数,node体是由一系列等式组成。与串行命令式语言(如C语言)相比,具有许多独有的特征[6],如下所示:
1)数据流和时钟
Lustre语言的变量、等式都是一个数据流(Stream)。一个数据流由相同类型的数据值序列和逻辑时钟两部分组成,默认情况下逻辑时钟都为true,叫作基本时钟。Lustre程序具有周期性循环执行的特点,对应着无穷多个周期,循环作用在数据流上。一个有基本时钟的数据流,在程序执行的第n个周期,取值为数据流的第n个值。另外,可以利用布尔值自定义一个时钟,使用时态算子对数据流进行过滤等处理。
2)时态算子
pre算子:用于访问前一周期的值。若表达式E的无穷多个周期对应的值序列为(e1,e2,...,en,...),则表达式pre(E)的逻辑时钟与E相同,且当周期n=1时,它的值为nil(nil表示一个未定义的值);n>1时,它各周期的值为表达式E前一个周期的值。即最后结果为pre(E)=(nil,e1,e2,...,en-1,...)。
->算子:用于初始化,可以和pre算子结合使用,以消除pre算子使用过程中第一个周期可能出现的nil。若表达式E和F的值序列分别为(e1,e2,...,en,...)和(f1,f2,...,fn,...),且它们的逻辑时钟相同,那么,E->F 的时钟也和E、F的时钟相同,且当n=1时,其值为E第一个周期的值;当n>1时,其各周期的值分别为F对应的各周期的值。即最后结果为E->F =(e1, f2,f3,...,fn,...)。
二元fby算子:相当于pre算子和->算子的结合体。若表达式E和F的值序列分别为(e1,e2,...,en,...)和(f1,f2,...,fn,...),且它们的逻辑时钟都相同,那么E fby F的时钟也和E、F的时钟相同,对应的值序列为(e1, f1,f2,...,fn,...)。
三元fby算子:若表达式E和F的值序列分别为(e1,e2,...,en,...)和(f1,f2,...,fn,...),且它们的逻辑时钟都相同,那么fby(E,n,F)的时钟也和E、F的时钟相同,对应的值序列(e1,e2,...,en,f1,f2,...,fn,...)
when算子:用于过滤某些周期的值。若E是一个算术表达式,B是一个布尔表达式,它们具有相同的时钟。那么,表达式E when B 的逻辑时钟就是B对应的布尔值序列,它的值序列就是当B为true时,E的取值。
2 可信代码生成器形式化开发方法
广义的讲,形式化方法是使用数方法来解决软件工程领域中遇到的问题,主要内容是建立数学模型以及对其进行充分、合理的分析;狭义的讲,形式化方法是使用形式化语言对规则进行描述,然后进行逻辑推理和证明的方法。经过形式化开发的可信代码生成器,其最大的特点是生成的目标代码的行为是严格符合源语言语义的,即源程序与目标代码之间语义具有一致性,不会产生有歧义的代码,从而保证了代码生成的可靠性。用于开发可信代码生成器的形式化方法主要有对代码生成器本身的证明和翻译验证,接下来分别对这两种形式化开发方法进行介绍。
2.1 翻译验证
在可信代码生成器形式化验证领域,John Mccarthy等人已经做了大量工作[7-10],但仍然无法自动证明给定的优化编译器的目标语言和源语言语义的一致性。如果不能证明代码生成器本身的正确性,也许可以检查每个编译过程的正确性。这启发了翻译验证技术,翻译验证的概念最早由Pnueli等人于90年代提出[11-13],作为一种形式化验证代码生成器正确性的技术,用于避免代码在转换过程中引入语义的歧义。翻译验证属于等价性验证的一种,它通过验证源程序和目标代码的语义等价性来证明代码生成器的正确性[14,15]。从而避免了对代码生成器本身的证明,只需要对验证器进行定理证明,具有较好的可重用性。带有翻译验证的代码生成过程如图1所示,与普通代码生成器的编译过程是一样的,只是从源程序到目标代码翻译完成后,没有立刻输出目标代码,而是增加了一个形式化开发的验证器,用于验证源程序和目标代码的语义是否具有一致性。把验证器看做一个函数Validate(S,C),代码生成过程看作函数Comp,验证语义等价性S≈C。如果由源程序S翻译生成了目标代码C,即Comp(S)=OK(C),并且通过了验证器的验证,即Validate(S,C)=true。那么,生成的目标代码C就被认为是可信的。因此验证器是翻译验证方法的核心,目标代码通过了验证器的验证后,才输出目标代码,否则编译报错。随着翻译验证技术的逐渐成熟,在商用代码生成器中也得到了应用,Michael等人[16]为商用RTW代码生成器开发了一个翻译验证工具TVS(RTW[20]代码生成器实现了从Simulink模型转换到C代码过程)。文献[17]中,基于翻译验证技术为GNU C优化编译器实现了一个验证器。
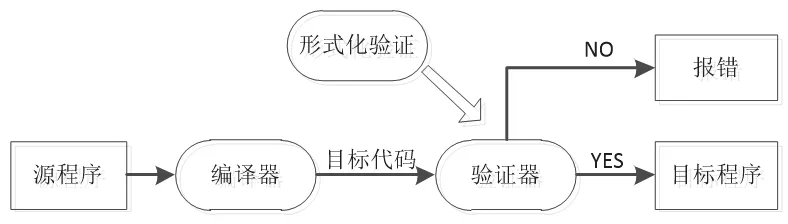
图1 带有翻译验证的代码生成过程Fig.1 Code generation process with translation validation
2.2 对代码生成器本身进行证明
另一种形式化开发可信代码生成器的方法是对代码生成器本身进行证明。这是一种将源语言的语法、语义模型及其满足规范的性质抽象为逻辑公式,然后使用逻辑推理技术来证明其语义一致性的技术,是最严格的开发方式。这种方法和数理逻辑相联系,常使用高阶逻辑系统进行形式化描述,可通过Coq[18]、Isabel/HOL等辅助定理证明工具进行证明。该形式化开发方法贯穿整个可信代码生成器的开发过程,为了降低形式化验证的难度,整个开发过程一般会划分为包含不同中间语言的多个翻译阶段,逐步翻译到目标代码。第一个形式化证明在1967年[8]手工完成的,用于将算术表达式的编译成堆栈机器码,并在1972年[19]对其进行了机械证明。Xavier[20]等人使用定理辅助证明工具Coq,使用定理证明方式开发的CompCert编译器,实现了从结构化的命令式语言到汇编代码的生成。CompCert由两部分组成,编译器前端:把C语言子集Clight[21]转换成一种低级的、结构化的中间语言Cminor;编译器后端[22,23]:把中间语言Cminor生成为汇编代码。定理证明方法开发可信代码生成器的基本流程如图2所示,Language1和Language 2分别代表可信代码生成器翻译过程中的两个中间语言,首先分别定义好源语言和目标语言的形式化语法、语义,然后证明翻译前后对应Language 1和Language 2的语义是否具有一致性,如果一致,则说明这个过程是可信的,利用Coq的抽取功能(Extraction)把翻译算法抽取成Ocaml代码。否则,迭代修改其形式化语法、语义的形式化定义,直到证明得到翻译前后语义具有一致性,再抽取翻译算法。把各翻译阶段的可信翻译算法抽取出来与代码生成器前端结合起来,最后就得到了一个经过证明的可信代码生成器。
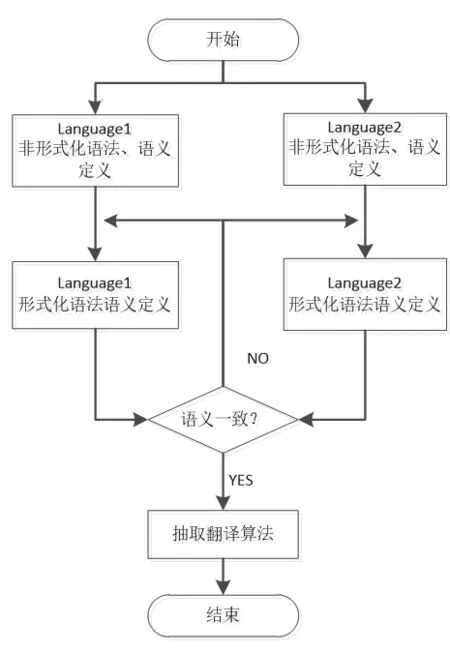
图2 对代码生成器本身进行证明的开发流程图Fig.2 The process of theorem proving method to develop trusted code generator
3 Lustre语言的可信代码生成器
学术界做了许多关于Lustre语言特性的形式化研究,Jakubiec L[24]等人在Coq中使用归纳类型定义了Lustre语言的一个子集;G. Hamon[25]等人研究了同步数据流语言Lucid的高阶特性,并完成了Lucid时钟演算;E. Gimenez 等人在开发Scade3代码生成器过程中,完成了Lustre语言的语义和时钟的定义[26]。基于前人对Lustre语法语义及性质的研究基础上,法国INRIA的Poute团队和清华大学计算机系的L2C团队利用对代码生成器本身进行证明的方式,各开发了一款用于学术研究的Lustre到Clight的代码生成器。Poute团队于2006年启动了Lustre语言代码生成器的形式化验证的研究工作,使用定理证明技术,在Coq中开发得到了Lustre到Clight的可信代码生成器Velus。Velus的架构如图3所示,主要由两部分内容构成,包括对源程序Lustre的预处理和代码生成及优化。该团队成员BERTAILS A等人[27]完成了Lustre程序的预处理过程,包括把源程序解析成没有注入时钟和类型的抽象语法树(parsing);对程序注入时钟和类型(elaboration)以对程序进行静态检查;简化程序中的复杂等式(normalization);对程序进行因果分析和拓扑排序,使并行程序串行化(scheduling)等工作。该团队成员Bourke等人[28],完成了中间代码生成及优化和目标代码生成,以及语义一致性的证明。包括从源程序到中间语言Obc的翻译(translation),该阶段消去了Lustre程序中的fby等时态算子;对Obc代码的优化(Fusion optimization);从Obc到目标程序Clight的代码生成(generation)等工作。由图3中虚线连接的部分表示,经Velus生成的Clight代码可直接在CompCert中编译,生成能在嵌入式设备中运行的可执行代码。为了简化证明过程,Vleus定义了一个中间语言Obc,这是在Lustre语言可信代码生成器的开发过程中常用的手段,一种中间语言对应了一个翻译阶段,一个翻译阶段只完成部分Lustre算子的消去工作。

图3 Velus架构图Fig.3 The architecture of Velus compiler
清华大学L2C项目组于2010年开始着手研究Lustre到Clight的可信代码生成器(简称L2C),经过形式化验证的L2C单时钟版本[29]已经实现了开源,在此基础上又为国内某核电企业开发了多时钟版本[30]。Velus和L2C都是参考了CompCert成功的技术路线,在Coq中利用定理证明技术来进行形式化的开发。它们的目标语言Clight的形式化定义也都是借鉴CompCert的定义。因此,L2C(开源版本)的架构跟Velus非常相似,这里不再赘述。但它们还是存在许多的不同,主要体现在支持的Lustre语言特性上。为了结合实际工业控制领域的需要, L2C、SCADE等工具在前述的Lustre语言特性的基础上,为了满足工业控制的需要,又增加了一些如用于处理数组的高阶算子等特性。如表1所示,为Velus、L2C(开源版本)和SCADE特性上的比较。
4 结束语
Lustre的可信代码生成器的形式化开发方法包括翻译验证和对代码生成器本身进行证明,翻译验证开发的核心在验证器,开发方式较简单、重用性好,多用于代码生成器的优化;定理证明是对代码生成器本身进行证明,是最严格的形式化开发方式,经过此方式开发的代码生成器能够达到人们所期望的最高的可信程度。未来在Lustre可信代码生成器的形式化开发中,可考虑把两种开发方式结合起来,把翻译验证作为对代码生成器本身进行证明的一种补充,如在CompCert编译器开发中,就混合使用了这两种方法,可以很好地平衡可靠性和工作量的问题。通过形式化方法开发的Velus和L2C代码生成器还未真正实现商用,主要用于学术研究。结合现有的学术成果和工业控制的需求,完善适用于工业控制的算子,优化Lustre到C的可信代码生成器,成为Lustre可信代码生成器真正用于安全攸关领域的关键一步。

表1 Velus、L2C和SCADE的特性比较Table 1 The comparison of Velus, L2C and SCADE
