基于模型融合的搜索引擎用户画像技术
2020-04-26王佳斌马迎杰朱新龙
郭 梁,王佳斌,马迎杰,朱新龙
(华侨大学 工学院,福建 泉州362021)
1 引言
1.1 研究背景及意义
搜索引擎是互联网的基础应用,它是用户访问网站的最重要的通道。搜索引擎用户画像是分析用户查询关键词的一个重要研究领域。搜索引擎通常通过创建用户画像来分析用户的个人偏好[1]。因此它具有极高的商用价值,很多营销项目或很多广告主,在投放广告前,都要求媒体提供用户画像。一种新的搜索引擎技术可以根据用户的兴趣、偏好和信息需求,为不同的用户提供不同的搜索结果[2]。但是由于搜索引擎便捷的特点,用户在使用时不会留下太多的用户信息,比如年龄、性别、学历等用户的标签信息,因此也就无法根据用户属性对用户进行分群处理,所以在分析用户数据时会存在一定的困难。
1.2 国内外研究现状
早期的用户画像构建技术利用数据库、Web 技术对用户数据进行统计分类,例如CRM(客户关系管理系统)。随着技术的不断发展,FAWCETT 等人[3]将数据挖掘和机器学习结合,通过用户行为生成的日志构建用户画像来检测用户中存在的欺诈行为。ADOMAVICIUS 等人[4]通过用户浏览历史和交易记录等建立用户画像,并用于推荐系统领域中。这些用户画像包含每个用户的个人行为,其通过各种数据挖掘的技术从用户历史行为中提取用户的偏好和习惯,更具体地说是从用户的交易历史中得到他们的用户画像。SUGIYAMA[5]在搜索引擎系统中使用基于改进的协同过滤方法构建用户画像,可以详细地分析用户一天内的浏览记录,然后根据用户对相关信息的反馈调整搜索结果。王庆福[6]提出用基于Bayesian Network 的用户画像来构建互联网用户爱好的不同层次。杨双亮[7]将DNN 算法应用到移动网络用户画像的爱好标签预测中,实现了用户的个性化推送。近几年的研究中,机器学习逐渐被引入NLP(Natural Language Processing)的领域中。本研究在搜索引擎用户画像的应用中,提出了基于BP 神经网络的Stacking 融合模型,并与传统模型进行对比实验。
2 用户画像简介
用户画像是根据用户的网络行为或现实行为产生的数据记录而抽象出的标签化的用户模型,是针对具有某些相同标签的某一类人的模型表达,并不是特指某一个人的表达。用户画像是分析用户属性的基本组件[1]。
用户画像的构成属性一般包括用户的静态属性、动态属性、消费属性和心理属性。静态属性用来描述用户的固有属性,比如用户的性别、出生年月等;动态属性指用户产生的行为属性,比如用户的出行习惯、学习偏好、娱乐活动等;消费属性主要包括用户的消费偏好、消费水平、消费心理等;心理属性指用户的生活、工作、情感趋向,通过这些属性预测用户新的行为。根据用户画像,公司可以通过用户的偏好来制定产品的模式与功能,或者修改自己的产品战略,以适应当前的市场。
用户画像的表示方法还可以分为以下几类:基于本体/概念的用户画像,基于主题/话题的用户画像方法,基于用户兴趣/偏好的用户画像方法,基于用户行为习惯的画像方法[8]。用户画像的数据可以通过数据挖掘技术来获取,将用户上网产生的日志通过合适的模型进行分析,并构建出用户画像。
3 用户画像的标签预测模型
3.1 基于TF-IDF 的传统机器学习模型
实验选用如今广泛使用的基于TF-IDF 的传统机器学习模型进行实验对比,TF-IDF 即词频-逆文本频率指数,是一种文本挖掘中广泛使用的特征向量化方法,尤其应用于搜索引擎的特征工程构建中,用来评估一个字词在语料库中的重要性[9]。TF(Term Frequency)表示词频,即一个词在一篇文章中出现的次数,但在实际应用中,介词、语气词等没有实际意义的词会在句子中大量出现,这些词语对于判断文章的关键词几乎没有什么用处,即为“停用词”,在度量相关性的时候不应当考虑这些词的频率。所以在数据预处理中已将这些词剔除。IDF(Inverse Document Frequency)逆文本频率指数,用总的文章数量除以包含该关键词的文章的数量得到某关键词的IDF 值,结果取对数得到,某关键词的IDF值越大,则区分能力越强,包含此关键词的文档越少,公式如下:
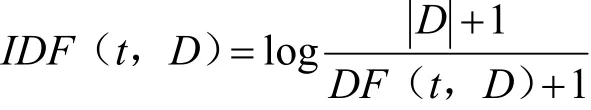
一个词语预测主题的能力越强,权重就越大,反之,权重越小,因此一个词的TF-IDF 公式如下:
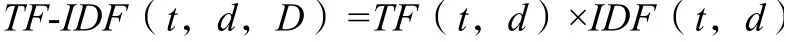
对于搜索引擎用户画像的分类问题,基于TF-IDF 的传统机器学习模型如下:先对数据进行预处理,将数据中有用的信息提取出来,再用分词工具对文本进一步分割;然后将这些处理过的数据用TF-IDF 进行特征提取,其效果与运用的算法有关;最后用分类器训练和预测,选择不同的分类器将出现不同的结果。其模型结构如图1 所示。
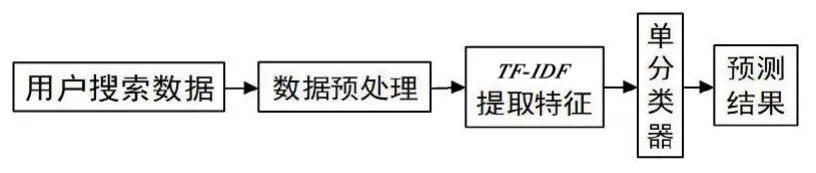
图1 基于TF-IDF 的传统模型结构图
3.2 基于BP 神经网络的Stacking 模型融合
传统的单个机器学习模型容易发生过拟合,所以本实验采用模型融合的方法。模型融合方法属于集成学习,它不是单独的机器学习算法,而是将许多机器学习算法结合在一起,因此往往比单一的学习器有更优越的泛化性,可提升模型的预测能力。集成学习可以分为三大类,即bagging、boosting 和stacking。bagging 使用装袋采样来获取数据子集训练基础学习器,以降低基分类器的方差,但是对提升泛化性能没有很大帮助;boosting 可将弱学习器提升为强学习器,每个基学习器都是为了最小化损失函数,更注重减少偏差;stacking 是一种分层模型集成框架,可以设置很多层级,包含不同的学习算法,所以比较灵活,有很强的泛化能力,可以明显提升预测结果。因此研究选择stacking 构建模型,一般stacking 模型为两层结构,过多的层级容易过拟合,运用stacking 模型,可以在过程中间结果融合新特征,进一步提升预测能力[10]。Stacking 模型融合结构如图2 所示。
TF-IDF 算法虽然考虑了单词在文档中的词频和单词在整体语料库中分布的影响,但没有考虑到单词在不同类别间的分布差异,而且忽略了单词之间的语音信息和排列顺序,所以实验采用Doc2Vec 弥补TF-IDF 的缺点。反向传播(Back Propagation,BP)神经网络是20 世纪80 年代由RUMELHART 等人提出的,是目前被广泛应用的神经网络学习算法[11]。对于Doc2Vec 得到的文本特征向量,实验使用BP 神经网络模型对其进行训练,并用Stacking 模型将TF-IDF 的训练结果融合,再输入到Stacking 第二级模型中,其模型结构如图2 所示。该模型相较Logistic Regression 等模型,其拟合能力更强,并在实验中进行了对比。
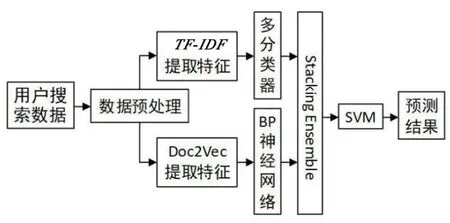
图2 Stacking 模型融合结构图
实验中Stacking 结构第一层使用多分类器训练TF-IDF特征向量,而不是传统的单一分类器,考虑到分类速度和分类效率,在分类器的选择上实验选择了SGD Classifier(随机梯度下降)、Naive Bayes Classifier(朴素贝叶斯)、LinearSVC(线性支持向量机)、Logistics Regression(逻辑回归)和Hard VotingClassifier(一种集成分类器),多分类器训练模型如图3 所示。
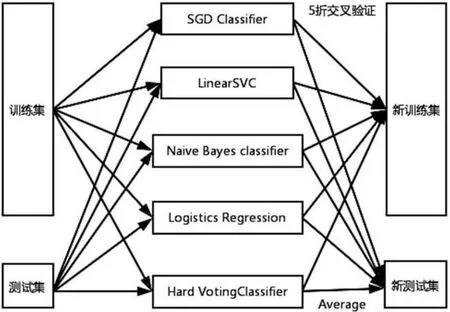
图3 多分类器结构
实验使用BP 神经网络训练Doc2Vec 特征向量,根据训练特征向量的网络结构,Doc2Vec 可分为Distributed Memory Model(DM)与Distributed bag of words(DBOW)两种模型,其中DM 模型不但拥有上下文的语义关联信息,而且包含了特征词的词序信息,DBOW 模型则不考虑特征词的排序信息,而只关注文档中的特征词的语义信息。实验中同时采用了DM 和DBOW 两种模型,用BP 神经网络进行特征训练,以保证特征构建中信息的完整性,其结构如图4 所示。
4 实验和分析
4.1 数据预处理
数据集是由搜狗搜索引擎提供的10 0000 用户一个月内的搜索引擎查询词,其中90 000 作为训练集,10 000 作为测试集。数据的格式如表1 所示。在测试集中,ID、Age、Gender 均为缺省项。
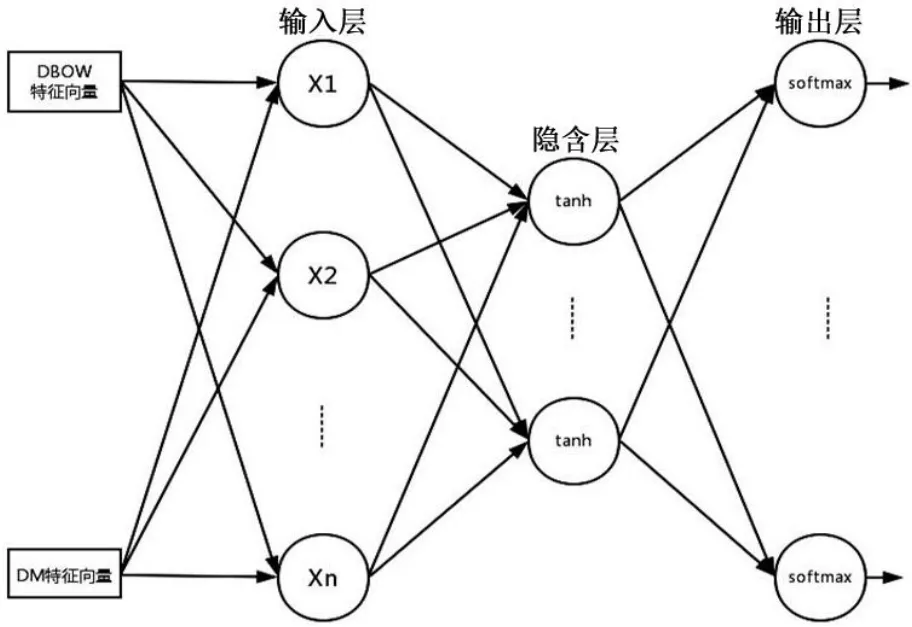
图4 BP 神经网络结构

表1 实验数据格式
在数据预处理的环节中,通过对训练数据的统计分析,发现包含空值的行并不多,所以直接舍弃以减小噪声。分词使用了jieba 分词组件,并使用带有词性的精确模式进行分词,结合人们进行日常检索的先验知识,在进行分词处理及特征计算的过程中,保留了名词、动词和简略词,在该任务中是最具有代表的特征。
4.2 基于TF-IDF 的传统模型分析
实验根据TF-IDF 的传统模型进行了训练和预测,并选用了不同的分类器进行对比。分类器中,逻辑回归(Logistics Regression)是最常用的分类方法,其速度快、易于理解,但适应能力有一定的局限性;朴素贝叶斯模型也常用于文本分类,有着较为稳定的分类效果,对小规模数据分类效果很好,实验选用文本分类常用的多项式分布朴素贝叶斯(MultinomialNB)与伯努利分布朴素贝叶斯(BernoulliNB)进行实验。作为对比,基于TF-IDF 不同分类器模型的实验准确率如表2 所示。

表2 基于TF-IDF 不同分类器模型的实验准确率对比(单位:%)
从实验结果可知,在基于TF-IDF 特征的分类模型下,选用不同的分类器会对结果产生不同的影响,对于TF-IDF特征向量训练的任务,使用逻辑回归分类会有更好的效果。
4.3 基于BP 神经网络的融合模型分析
为了使结果更加直观,实验使用TSNE 对模型的输出结果进行降维可视化展示,如图5 所示,Education 和Age 分为6 类,Gender 分为2 类。

图5 TSNE 降维可视化
根据以上模型结构进行实验,基于BP 神经网络的融合模型与其他模型准确率的对比实验数据如表3 所示。表3 中,TF-IDF(多分类器)表示用多分类器训练TF-IDF 特征向量,但在Stacking模型中不进行融合Doc2Vec 特征向量得到的结果;TF-IDF&Doc2Vec(LR)表示实验在Stacking 模型第一层使用TF-IDF 多分类器训练特征,第二层中融合的是用Logistics Regression 分类器训练的Doc2Vec 特征向量;TF-IDF&Doc2Vec(BPNN)表示实验在Stacking 模型第一层使用TF-IDF 多分类器训练特征,第二层使用BP 神经网络训练Doc2Vec 特征向量。

表3 基于BP 神经网络的融合模型与各模型准确率对比(单位:%)
从实验结果可以看出,使用TF-IDF 多分类器效果比使用传统模型中单分类器准确率高,用Stacking 融合模型加入Doc2Vec 特征向量后,效果进一步提升,最后将Doc2Vec 特征向量的训练方法由Logistics Regression 改为BP 神经网络后,准确率在一定程度上又有所提升。
5 总结
本实验构建了用于预测多维用户标签的Stacking 模型融合结构,并与传统的分类模型进行实验对比。从实验结果可以看出,选择不同的分类器对准确率有很大影响,在搜索数据的分类任务中,使用Logistics Regression 分类器要比其他单分类器有更好的效果,而使用Stacking 融合模型中的多分类器可以进一步提升分类效果,如果将基于BP 神经网络训练的Doc2Vec 特征词向量进行融合,则可以在一定程度上继续提高预测的准确度。所以本文提出的Stacking 模型融合方法对搜索引擎用户画像的标签预测有一定的意义。
