基于运算符信息的数学表达式检索方法
2020-04-20徐以聪田学东左丽娜
徐以聪,田学东,左丽娜
(河北大学 网络空间安全与计算机学院,河北 保定 071002)
0 概述
在目前搜索引擎已经具备快速准确检索文本的功能,同时关于文本相似度检测的研究也较为成熟[1-3]的背景下,数学公式相似度的检索问题被广泛关注[4-6]。然而,数学表达式具有复杂的二维结构特征,传统面向一维文本的检索方法难以满足其检索需要。
关于数学表达式的检索,国内外研究者取得了较多研究成果,但由于数学表达式的种类繁多且结构复杂,在其索引结构的建立与匹配方面仍有待研究。考虑到决定数学表达式含义的往往不是运算数,而是由运算符构成的表达式结构,本文设计一种基于运算符信息的数学表达式检索方法,提取数学表达式中的运算符作为骨架并建立索引,在此基础上寻找与目标表达式相似的数学表达式。
1 相关研究
目前,国内外学者已针对数学表达式检索的问题提出了多种方法和模型。MCAT search system[7]采用基于路径与基于哈希散列相结合的编码方法对数学表达式进行编码,从数学表达式、段落、文档3个层面提取文本信息,并参与了NTCIR-12 MathIR任务[8]。文献[9]设计的语义检索系统支持盲人用户进行数学学习,其先将数据库中的数学表达式转换为MathML编码的表达式,再对MathML表达式中的公式进行语义分析,构造每个公式的树状子结构,通过该树状子结构以特征向量的形式提取特征。MathPD[10]通过定义表达式符号特征、特征描述符和粒度,运用粒度比较、特征比较、相似度度量的方法来判定2个文档的相似度。VMEXT[11]是一款数学表达式可视化工具,其同时将表示元素和数学表达式的语义结构可视化,使用户能够快速发现MathML标记中不影响表达式表示的缺陷。文献[12]针对数字数学图书馆设计和开发的Web用户界面WebMIaS,允许用户将文本自动生成的标准关键字与LaTeX或MathML格式的数学公式形式的关键字组合在一起,通过Web界面进行查询操作。Min[13]是一个多模态的数学搜索界面,可以在台式机以及平板电脑等设备的标准Web浏览器中运行,并通过外部Web服务实现数学符号的识别与解析功能。
文献[14]提出一种基于2个索引的数学公式局部匹配检索系统,其中一个索引将公式视为表达式树,以每个节点到根节点的路径构造反向索引,另一个索引是一个表,用于存储表达式树中每个节点的父节点和文本字符串。文献[15]提出的数学表达式检索和索引方法,索引中的每个键都是一对符号以及它们在表达式中的相对距离和垂直距离,可以解决部分匹配问题。文献[16]设计的一种MathML格式的数学公式匹配算法,将数学公式表示为二叉树,层次遍历二叉树得到结构码,根据先序遍历序列与中序遍历序列是否相同判断2个数学公式是否匹配。文献[17]提出一种基于Ontology的数学表达式检索方法,运用Ontology建立数学表达式及其概念之间的联系并构建数学表达式语义本体库,以达到输入关键词、概念、短语和数学名词即可检索数学表达式语义相关文献的目的。
文献[18-19]将数学表达式转化为自底向上等价的树结构用以解答数学应用题,首先构造具有不同结构和内部节点的候选树,然后通过定义评分函数选择最佳的候选树。文献[20]提出一种多方程数学表达式问题的求解方法,设计了语义表示语言DOL,用来表示自然语言文本的结构语义,其通过语义分析器将文本转换为DOL树,根据得分函数选择得分最高的DOL树。
文献[21]提出一种基于协同过滤的数学表达式推荐方法,通过在数学表达式查询输入端加入数学表达式子式位置选择模式,使检索结果初步贴近用户偏好。在此基础上,采用模糊集方法以多特征指标对用户偏好进行建模,并依据用户行为的隶属度函数构造用户对数学表达式的评分矩阵。最后根据协同过滤算法的思想,通过设置阈值产生数学表达式的推荐列表,实现数学表达式的协同过滤推荐。
文献[22]提出一种基于semi-operator树生成子树的层次泛化方法,该方法支持子结构匹配和模糊匹配,其在索引阶段构建2个索引文件计算查询公式与文档的混合相似度得分,提高了在线查询效率。文献[23]在文献[22]方法的基础上设计改进的数学信息检索系统,增加了表达式周围的文本信息属性,提高了查询结果的合理性。
为使用户可以方便地以数学公式作为查询语言对科技文档进行检索,文献[24]提出了一种基于数学表达式特征的科技文档检索模型。首先通过将公式解析为二叉树得到数学表达式的子式信息,利用数学表达式及子式构造检索特征向量;在索引阶段,利用所提取的文档特征向量构建分层结构的索引表;在匹配阶段,对文档向量采用tf-idf进行加权操作,利用余弦相似度对检索向量和文档向量进行相似度计算,从而得到一个有序的文档检索结果。
文献[25]提出一个能够在维基百科中检索数学公式的工具WikiMirs,基于文本和空间相似性搜索相似的数学公式。该文提出一种从数学公式表示树生成子树的层次泛化方法,并根据这些树在不同层次上的匹配程度计算相似度。
文献[26]提出MIaS,设计了一个基于MathML表示树的索引结构来检索数学表达式,其利用tf-idf权重法对表达式进行排序。文献[27]则针对线性代数表达式,设计了一种线性代数表达式的索引与匹配方法,根据线性代数表达式的种类对其进行分类,并定义相应的扩充运算,据此构建索引文件,设计线性代数表达式匹配算法,实现灵活的检索模式,提高检索结果的相关性。
2 数学表达式骨架提取
公式描述结构[28-30](Formula Description Structure,FDS)用于对数学表达式的描述,更便于建立数学表达式索引和实现数学检索。因此,本文利用改进的FDS解析算法对LaTeX格式数学表达式进行分析,并提取数学表达式的结构信息。
2.1 FDS提取算法
数学表达式每个节点上的信息存储在FDS向量(Symbol,Level,Operator,Flag)中,其中:Symbol为表达式的当前符号;Level表示当前符号所在的层次信息,主基线层次为0,其余层次在上一层次的基础上加1;Operator表示当前符号是否为运算符,如果是运算符,值为1,否则为0;Flag表示当前符号的空间位置,对应over、superscript、subscript、under、inclusion、upper left(ul) 和lower left(ll)7种情况,Fcode为Flag的值,分别对应1、2、3、4、5、6、7。部分表达式符号空间位置关系如表1所示。

表1 部分表达式符号空间位置关系
例如,LaTeX公式“[x=frac{{-bpmsqrt{{b^2} -4ac}}} {{2a}} ]” 对应的原型公式为:
(1)
其FDS解析数据见表2。当Fcode为0时,表示该节点位于主基线层。

表2 式(1)的FDS信息
由于本文设计的索引结构不需要存储表达式的所有节点信息,因此有必要对原有的FDS算法进行修改,如算法1所示。
算法1FDS解析算法
输入LaTeX数学表达式
输出数学表达式的FDS信息
步骤1将隐式运算符关键字添加到现有运算符字典中。
步骤2递归遍历LaTeX表达式,查找运算符字典,确定每个关键字节点长度,并为每个节点分配Level编号。
步骤3依次分析每个关键字节点,并记录该节点的Level、Operator和Fcode信息。
步骤4如果Operator为1,则保留该节点,否则舍弃。保留的节点构成了表达式的FDS信息表。
上述算法的主要过程是线性扫描LaTeX格式的数学表达式,以一层循环为主,循环体内包含选择语句对每个关键字进行判断,若为运算数则返回循环条件对下一个关键字进行判断;若为运算符则提取其信息。对一个长度为n的LaTeX表达式,共需执行n次元操作,算法的时间复杂度为O(n)。
除了存储关键字本身,字典还存储关键字的类型,这些类型之间用“#”分隔。根据关键字的类型,可以判断当前关键字是否为运算符,然后由运算符判断当前关键字的层次信息。算法修改后获取的式(1)的FDS信息如表3所示。可以看出,原有信息表中Operator字段值为1的节点全部保留,为0的全部舍弃。此外,将隐含的指数符号“^”视为运算符添加进来,层次与标志位均与其指数位相同。“^”作为一种隐含符号,与层次的变化有关,其他像“ab”中的乘法将不包括在内,因为它不会导致左右2个节点的层次变化。
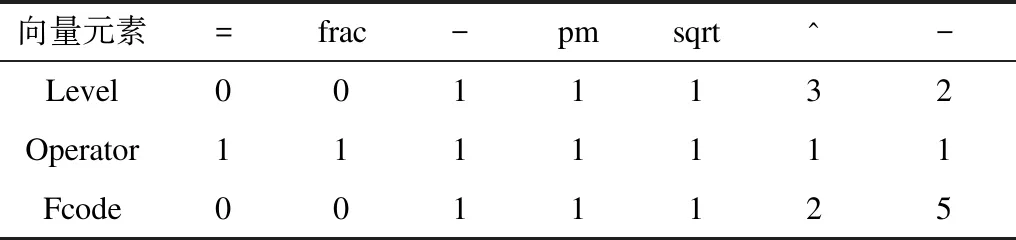
表3 算法修改后式(1)的FDS信息
2.2 公式骨架提取
数学表达式的结构由运算符组成,运算符决定了数学表达式的基本运算含义。考虑以下2个公式:
a2+b2=c2
(2)
x2+y2=z2
(3)
虽然构成上述2个表达式的运算数不同,但结构与含义实际上是完全相同的,其一般形式如下:
i*+j*=k*
(4)
其中,“*”表示指数,不限于等于2。为便于观察,将式(2)和式(3)以二叉树的形式描述并提取它们的骨架,分别如图1~图3所示。显然,式(2)和式(3)除了构成表达式的运算数不同以外,运算符及其所在层次是相同的,2个表达式具有完全相同的结构。因此,式(2)和式(3)互为相似表达式。

图1 式(2)的二叉树
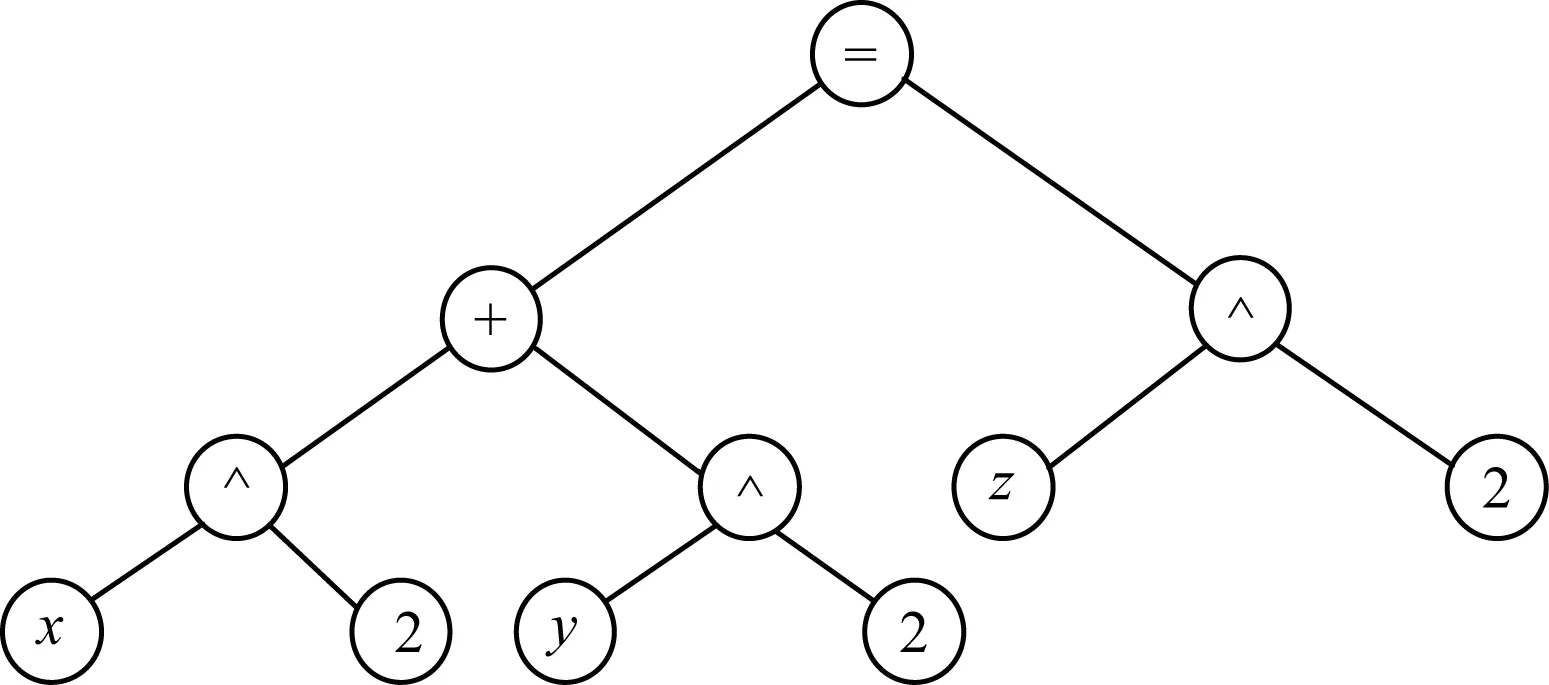
图2 式(3)的二叉树
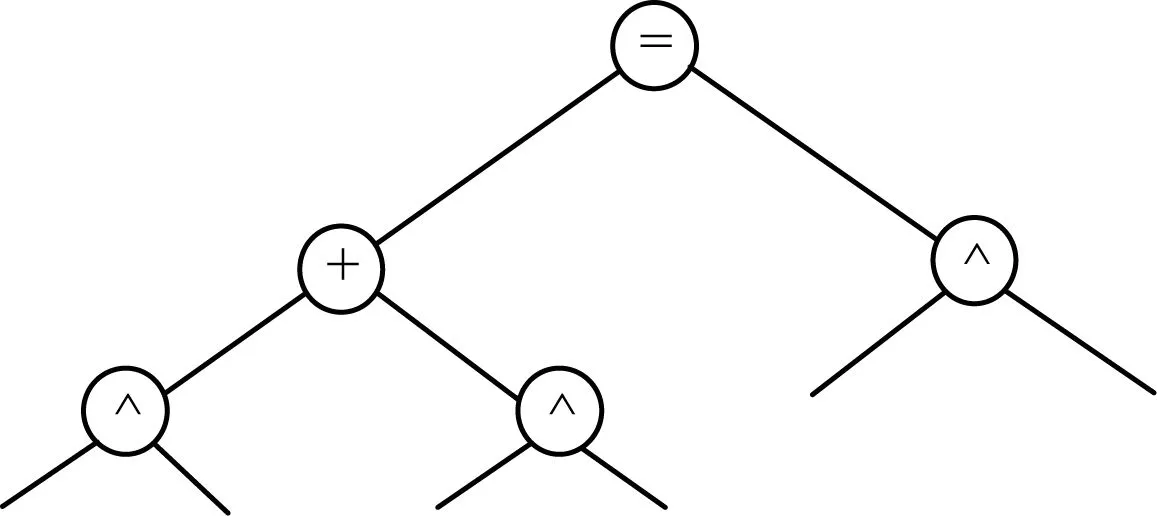
图3 式(2)和式(3)的骨架树
本文的研究目标是检索出具有完全相同或是部分相同结构的相似表达式,其中部分相同是指2个表达式的结构至少具有一个在同一层次相同的运算符。
3 数学表达式索引结构设计与匹配
3.1 运算符与骨架存储结构设计
在对数学表达式的结构(以下简称为骨架)建立索引之前,首先对单个运算符进行结构化设计,除了考虑构成骨架的运算符本身以外,还需要考虑运算符在表达式中的层次。
定义1每个运算符与其层次组成一个S-L对(S:Symbol,L:Level),其中,Symbol表示当前运算符本身的符号,Level表示当前运算符的层次。单个运算符的存储结构如图4所示。
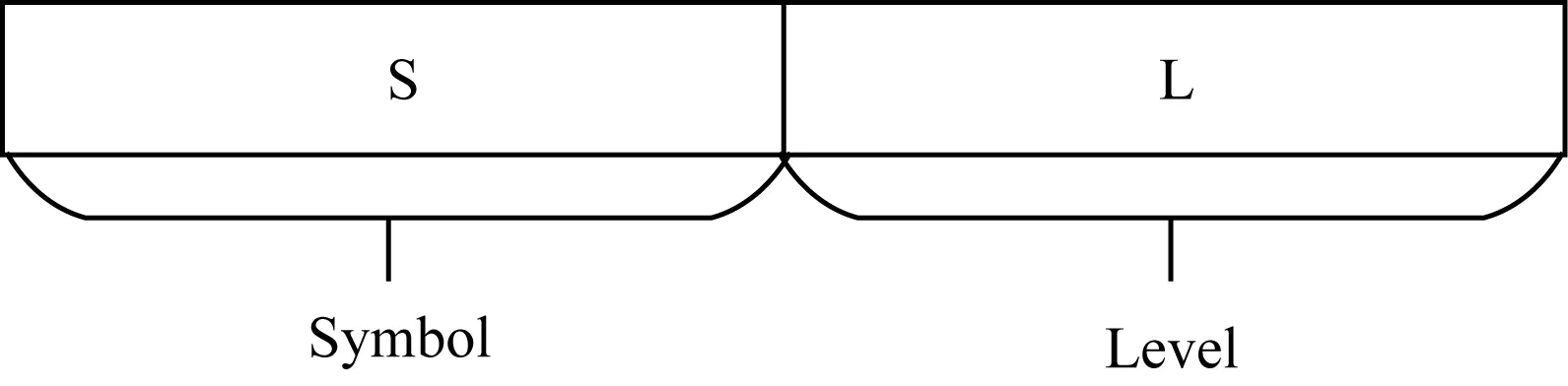
图4 单个运算符的存储结构
对于一个完整的表达式,假设共有N个操作符,将表达式所有的单个操作符存储结构连接起来即可得到表达式的完整骨架存储结构,如图5所示。由于N的取值不同,因此不同表达式的完整骨架结构是不等长的。
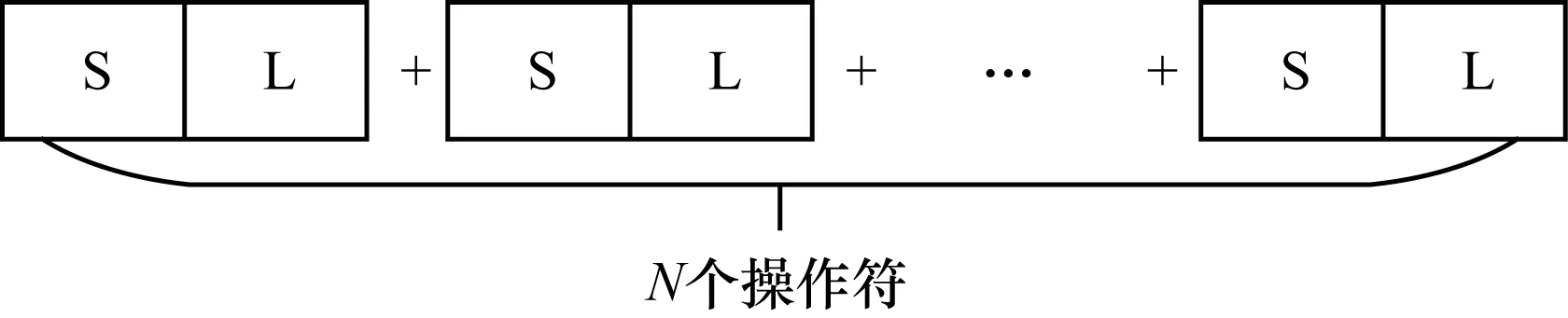
图5 完整骨架存储结构
3.2 数学表达式索引结构
定义2一个完整的数学表达式具有如下形式的索引结构:expIndex:{expId,fileId,expCode,expInfo},其中,expId为表达式的序号,fileId为当前表达式所在文档的编号,expCode为表达式的骨架结构编码,expInfo为LaTeX形式的表达式本身。
定义3含有表达式的文档索引结构形式为fileIndex:{fileId,fileName},其中,fileId为文档的编号,fileName为当前文档的名称。在检索时,首先提取待检索表达式的expCode,然后在数据库中检索是否有相同或相似的expCode与之匹配,若匹配结果不为空,即可根据检索结果表达式中的fileId找到对应的fileName。
3.3 数学表达式匹配算法
定义4设O为任意表达式F的所有S-L对的集合,sl1,sl2,…,sln为O的元素,记为O={sl1,sl2,…,sln},其中,sli(1≤i≤n)分别为F的第i个S-L对,n为S-L对的个数。
设S为数据集中全部表达式S-L对的集合,O1,O2,…,Om为S的元素,S={O1,O2,…,Om},其中,m为表达式的个数,S的子集记为Si(1≤i≤n)。
算法的执行步骤数与目标表达式的长度成正比,表达式的长度越长,骨架结构就越长,从而n也就越大,执行的步骤也越多。如图6所示,可见式(1)的骨架结构为(=/0)+(frac/0)+(-/1)+(pm/1)+(sqrt/1)+(^/3)+(-/2)。
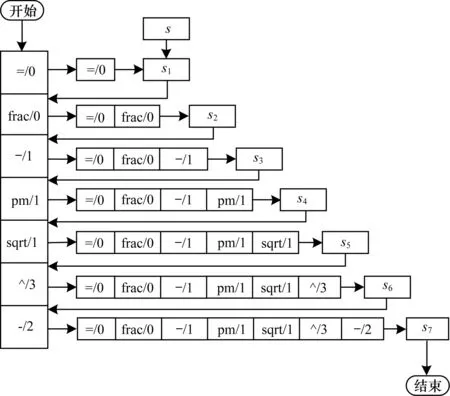
图6 式(1)检索过程
数学表达式匹配算法描述如下:
算法2数学表达式匹配算法
输入LaTeX数学表达式
输出与目标表达式相似的表达式集合
步骤1输入待检索的目标表达式F,利用算法1获得F的所有S-L对的集合O。
步骤2从O中提取sl1,并在S中检索出所有包含sl1的表达式,构成集合S1。
步骤3从O中提取sl2,并在S1中检索出所有包含sl2的表达式,构成集合S2。
……
步骤n+1从O中提取sln,并在Sn-1中检索出所有包含sln的表达式,构成集合Sn,即与目标表达式相似的表达式集合。
算法步骤1的时间复杂度为O(n),步骤2是第1次从S中提取运算符,因此,复杂度为O(m),从步骤2到步骤n+1,因为集合Si逐渐变小,所以每步的复杂度均小于O(m),又因为n远小于m,所以算法的总时间复杂度小于O(n)+nO(m),即小于nO(m)。
4 实验结果与分析
4.1 实验数据与环境
本文实验从ntcir_12_mathir_wikipedia_corpus数据集中获得31 742个文档,其中包含519 588个数学表达式。编程语言为C#,采用C/S模式,实验环境为Intel(R) Core(TM) i7-7700 CPU,3.6 GHz,内存为8 GB。操作系统是Microsoft Windows [version 10.0.17134.407]。
4.2 索引大小与查询响应时间
表4、表5分别列出了本文实验索引文件以及文献[25]索引文件的大小,图7显示了随着公式数量的增加索引文件大小的变化情况。

表4 本文实验索引数据

表5 文献[25]索引数据
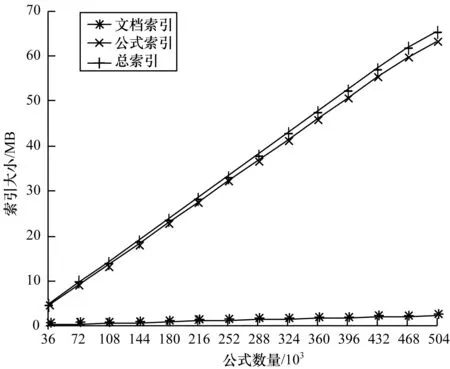
图7 索引大小与公式个数的关系
随着文档和公式数量的增加,文档和公式索引的大小逐渐增大,但增速较低。本文方法只对运算符建立索引,放弃了运算数,大幅减小了索引文件的大小,节省了存储空间。与表5所示的文献[25]索引相比,本文索引较为节省空间。同时由图7可知,最初公式索引和总索引2条曲线几乎重合。文档索引曲线一直在水平轴附近,与其他2条曲线不同,变化缓慢,公式个数则与3个索引曲线之间存在线性函数关系。
对不同结构的表达式进行检索实验,结果如表6所示,其中平均检索时间是指10次检索时间的平均值,均在可接受范围内。

表6 部分表达式检索情况
由表6可以看出:目标表达式结构越简单,骨架结构越简单,结果表达式越多,时间开销越低;目标表达式的结构越复杂,结果表达式就越少,所需的时间也就越长。
4.3 个例研究
对式(1)的部分检索结果如表7所示。由于查询结果数量较多,表中只列出前15个查询结果(本文排序方法的第一步是找到最接近目标公式长度的公式。如果有2个长度相同的结果公式,则ID较小的排在前面)。可以看出,除了能够检索出与目标表达式完全相同的表达式外,本文方法还可以检索出具有相同结构但运算数不同的表达式,例如第68 421个和第248 575个表达式,这样即可消除一般运算数的影响。
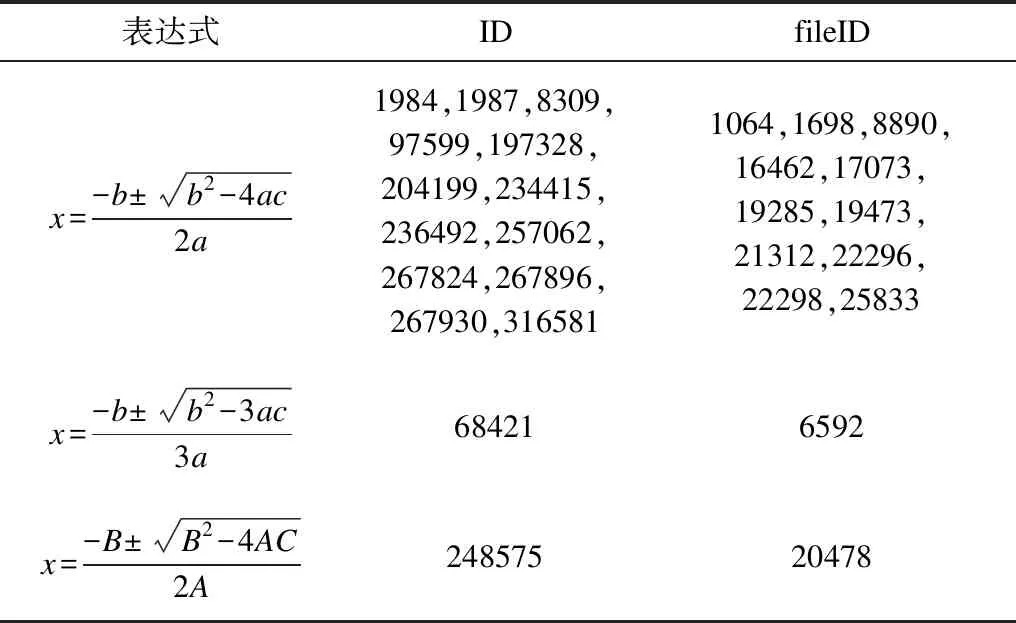
表7 式(1)部分检索结果
4.4 对比实验
表8给出了WikiMirs 和本文系统检索结果的前5个查询结果。

表8 2种方法的Top-5查询结果

5 结束语
本文通过引入公式描述结构,提出一种基于运算符信息的数学检索方法,其由FDS分析、索引和匹配3个主要步骤组成。将数学表达式输入到FDS程序中获得运算符信息,在此基础上建立数学表达式索引,并通过匹配算法找出与目标表达式相似的数学表达式。实验结果表明,该方法能够检索相似的表达式,具有较高的检索效率,并且不受一般运算数的影响。由于本文方法主要面向表达式,未考虑表达式在文档中的重要性,因此下一步将在表达式和文档之间添加关系属性,以检索出满足用户需求的文档。此外,还将优化其索引结构,加快检索速度。
