LHAASO地面簇射粒子阵列在线实时分布式数据处理
2020-04-18卢晓旭顾旻皓朱科军
卢晓旭 顾旻皓,3 朱科军,3 李 飞,3
1(中国科学院高能物理研究所 核探测与核电子学国家重点实验室 北京 100049)
2(中国科学院大学 物理科学学院 北京 100049)
3(中国科学院高能物理研究所 天府宇宙线研究中心 成都 610000)
高海拔宇宙线观测站(Large High Altitude Air Shower Observatory,LHAASO)是“十二五”期间批复立项的国家重大科技基础设施,是一个正在边建设边运行的处于国际领先水平的高海拔宇宙线观测项目。项目选址位于四川省稻城县海子山,海拔4 410 m,投资超过10亿元人民币。项目的核心科学目标为:探索高能宇宙线起源并开展相关的高能辐射、天体演化、甚至于暗物质分布等基础科学的研究[1-2]。
LHAASO现在的设计中,共有三种探测阵列,包括地面簇射粒子阵列(square KiloMeter detector Array,KM2A)、水切伦科夫探测器阵列(Water Cherenkov Detector Array,WCDA)[3]和广角切伦科夫望远镜阵列(Wide Field Cherenkov Telescope Array,WFCTA)。其中地面簇射粒子阵列(KM2A)分布在方圆1 km2,由5 242个电磁粒子探测器(Electromagnetic Detector,ED)和1 171个缪子探测器(Muon Detector,MD)组成[4],具体分布如图1所示。4种探测器独立运行,产生的数据共同参与软件触发,对空气簇射的不同组成部分进行区分,从而实现对于宇宙线和γ射线的高精度测量。
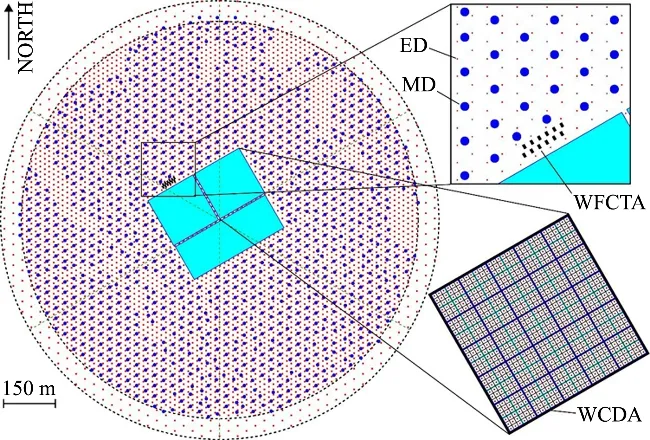
图1 LHAASO各探测器分布Fig.1 Distribution of LHAASO detectors
作为LHAASO的重要组成部分,地面簇射粒子阵列主要科学目标是借助1 km2的观测面积,以及大视场、全天候的工作特点,覆盖20 TeV~20 PeV,对γ射线源的巡天灵敏度在50 TeV附近达到1%蟹状星云流强[5]。KM2A采样探测广延空气簇射(Extensive Air Shower,EAS)到达地面的次级粒子,包括正负电子、γ和μ等。ED主要用于探测正负电子、正负μ和γ,精确测量这些粒子在某一位置处的数目密度和到达时间。多个ED共同观测,实现对簇射事例的方向、簇射芯位与能量的重建。ED是塑料闪烁体探测器,闪烁体产生的光子经光纤收集传输到光电倍增管转化成电信号读出。ED表面覆盖铅板,用于将EAS中的光子转化成电子以提高探测效率和角分辨。MD是水切伦科夫探测器,表面覆盖厚土层,厚土层用于吸收电子与光子。由于原初宇宙线强子簇射中产生的缪子数与原初强子的核子数相关,因此,MD提供的缪子数可以用于区分原初强子成分。而通过测量簇射中次级缪子成分进行原初粒子识别,KM2A可以进行γ射线源百TeV能谱测量。
图2为典型的高能物理实验的结构示意框图。探测器系统负责侦测微弱的粒子信号,并将之转化为电信号,电子学系统负责将电信号转化为数字信号,并打包成数据包。触发判选系统负责完成数据的筛选工作。数据获取系统负责进行高速海量数据读取、在线处理与存储[6]。LHAASO数据获取系统主要分为数据流软件与在线软件。在线软件作为一个分布式数据获取系统的架构系统,为数据流软件提供通用框架服务。而数据流软件对于原始物理数据的海量数据进行获取、传输、处理与存储[7]。
值得注意的是,对于LHAASO实验而言,并没有设计硬件触发系统,因此,LHAASO实验的触发判选功能由软件承担。所以,必须需要设计一个在线分布式软件,作为数据流软件的一部分,用来对阵列完成在线的数据筛选处理,执行“触发判选”的功能。
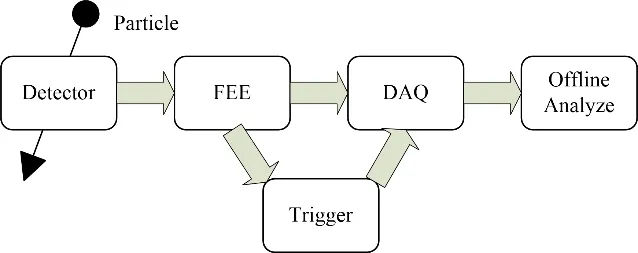
图2 典型高能物理实验结构图Fig.2 Structural diagram of a typical high-energy physics experiment
1 需求分析
LHAASO KM2A设计由5 242个ED和1 171个MD组成,ED估算总数据量为230 MB·s-1,MD估算数据量为316 MB·s-1,总数据量约546 MB·s-1。由于KM2A并不具备硬件触发能力,需要设计一套LHAASO地面簇射粒子阵列在线分布式数据处理软件,通过对输入数据进行在线的处理,降低数据量的同时,筛选有效数据,从而送入磁盘阵列,进行数据存储。
功能上,这个在线分布式数据处理软件采用基于标准以太网和TCP/IP协议的数据传输方案,需要能够接收包括来自所有探测器单元的同一时间的组包完毕的数据,利用配置的触发算法对数据包进行在线处理与计算,将具有物理意义的数据提取、打包,组成为一个个标有物理标签的事例,并按照配置的输出规则将这些事例送出至不同的接收方。
性能上,数据处理软件既不能在在线处理与计算前,丢失来自某些探测器的数据;也不能将数据包处理与计算的时间拉的过长;同时,处理完的事例要及时送出。
2 框架设计与功能实现
2.1 软件框架概述
由于对于该在线数据处理软件性能要求较高,且出于配置灵活性等方面的考虑,软件设计采用在线分布式数据处理方案。
软件配有一个管理节点和多个处理节点。处理节点负责进行数据的接收与处理,并将处理后的数据依照输出规则配置文件,将不同标签的事例发送至不同的接收节点。管理节点负责对于所有处理节点进行性能监督与调度。
软件采用ZeroMQ作为消息和数据通信中间件,采用Protobuf进行消息的(逆)序列化,采用Redis作为信息共享平台,负责发布软件各个节点的运行信息。软件的业务层框架设计如图3所示。
2.2 软件运行流程
图4为软件的运行示意图。软件的运行分为配置阶段与数据处理阶段。
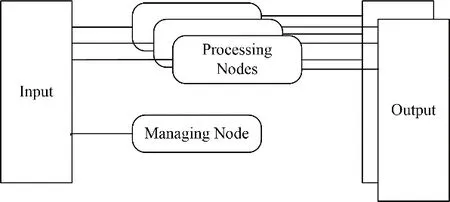
图3 软件业务层框架图Fig.3 Business layer framework diagram of software
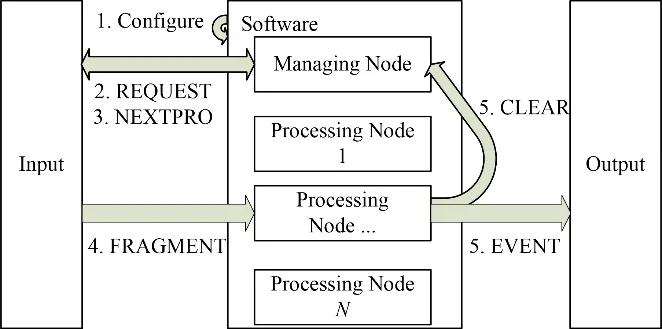
图4 软件运行示意图Fig.4 Software operation system
配置阶段,主要完成的是对于软件节点部署与节点内参数的配置。节点部署,即配置软件一共需要的节点种类,各种类型的节点个数,节点运行位置,节点ID,节点是否启用等。节点内参数配置,即配置某个节点的内部参数,如节点内Worker数量,节点挂载的动/静态链接库,节点是否开启输出/节点内部存盘功能,节点调用的数据处理阶段需要使用的参数配置文件等。
软件数据处理阶段,主要完成的是数据消息的传入、处理以及数据的传出。
软件的输入为REQUEST类型消息与FRAGMENT类型消息。软件每次信息交互,首先是管理节点收到的REQUEST类型消息。REQUEST类型消息主要意义为请求分配当前最空闲处理节点。当收到此类型消息后,管理节点会返回一个NEXTPRO类型消息,其内容为当前最空闲处理节点ID。
随后,软件的处理节点会收到FRAGMENT类型的消息,消息内容是打包好的某一时间段的来自全部种类全部探测器的数据。在线分布式数据处理软件的配置会为该节点选好需要加载的触发算法。当该节点在运行过程中收到消息后,会利用加载的触发算法对于数据进行在线的数据处理与筛选。对于筛选后需要保留的事例,依据触发算法的不同,根据数据单元的类型,每一个保留的事例打一个类型标记。随后,根据配置的输出规则,处理节点可以将不同的事例类型发送向不同的输出端。
当处理节点完成某个FRAGMENT的处理与发送后,处理节点会向管理节点发送CLEAR类型消息以进行汇报,通知管理节点更改自身的工作状态的记录。
2.3 软件各功能模块详述
2.3.1 软件管理模块
软件管理模块对所有处理节点进行性能监督与调度。模块分为模块管理单元、模块配置单元、模块处理单元、模块信息管理单元等,如图5所示。
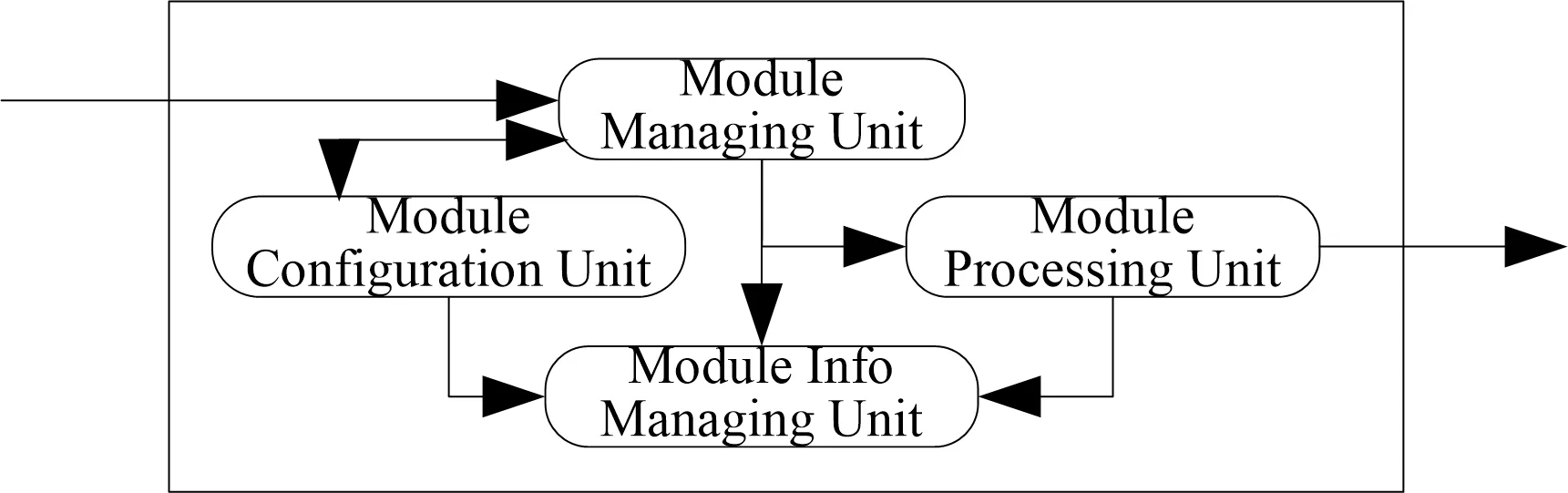
图5 管理模块结构图Fig.5 Managing module structure diagram
1)模块管理单元。App单元是软件管理模块的管理单元。在软件初始化阶段,App单元负责调用配置单元,设定软件管理模块的运行参数,并初始化模块处理单元与模块信息管理单元。在软件数据处理阶段,App单元负责接收所有流入软件管理模块的消息,进行消息解析,判断消息类型,调用模块处理单元完成消息处理。
2)模块配置单元。Config单元为模块的配置单元,负责在初始化阶段完成参数设定。考虑到配置单元仅需要实现一次,该单元采用单例模式实现。而考虑到多线程的运行环境下仍需要保证该单元的参数不会被多个线程同时改变,单元采用饿汉模式实现单例[8]。
3)模块处理单元。模块处理单元负责在软件数据处理过程中,对于流入软件管理模块的不同类型的消息进行不同的处理。该单元主要需要处理的消息类型为REQUEST类型消息与CLEAR类型消息。
处理单元内部存有表格,表格内容节点ID,节点当前任务数量,节点Worker数量,节点CPU效率因子等。同时,会利用这些参数,计算出每个节点ID对应的节点综合负载量。当收到REQUEST类型消息时,处理单元会查询表格,寻找到综合负载量最小的节点,将其ID返回,同时更新此ID的当前任务数量,并重新计算此ID对应的节点综合负载量。
当收到CLEAR类型消息时,处理单元会查找表格,更新消息发送节点的当前任务数量,同时更新该节点的综合负载量。
4)模块信息管理单元。Info单元为模块的信息管理单元。该单元在模块的配置阶段,会配置好所有需要进行信息管理的键。在模块的数据处理阶段,所有其他单元会在有消息操作时,更改模块信息管理单元相关键对应的值。而模块信息管理单元会定期将所有键与值发布到Redis数据库上,以供用户查询运行状态。
考虑到多线程安全问题,模块信息管理单元也采用的是饿汉模式实现的单例模式。
2.3.2 软件处理模块
软件处理模块主要工作内容为对流入模块的消息与数据进行处理,对处理后的消息数据参照配置的发送规则进行发送,以及对于软件管理模块进行状况汇报。软件处理模块分为模块管理单元、模块配置单元、模块计算单元、软件输出单元、软件信息管理单元等,如图6所示。
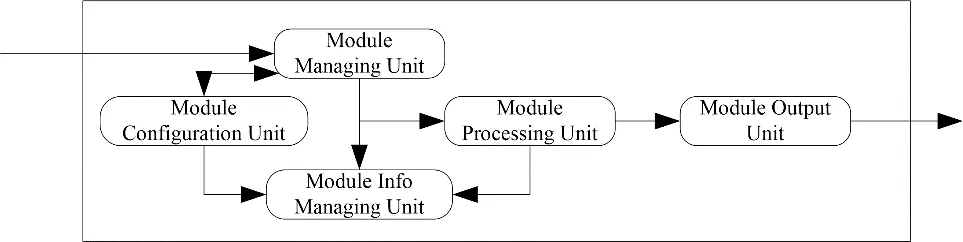
图6 处理模块结构图Fig.6 Processing module structure diagram
1)模块管理单元。App单元是软件触发模块的管理单元。在软件初始化阶段,App单元负责调用配置单元读取环境变量,完成基本参数设定,随后根据参数配置初始化一定数量的模块计算单元与模块输出单元,加载用户指定的触发算法库。而在软件的数据处理阶段,模块管理单元作为软件处理模块的消息接收节点,接收所有流入软件处理模块的消息并进行处理。软件管理模块对消息解析与类型判断。当消息类型确认为FRAGMENT类型后,管理单元会将消息放入模块输入队列,以供计算单元进行后续处理。
2)模块配置单元。Config单元为模块的配置单元。该单元主要任务为,读取环境变量,加载关键配置参数,如模块实现的Worker数量,模块调用的触发算法库的路径与名称,模块的本地存储与输出功能的开关等。
3)模块计算单元。Worker是模块中担任在线数据计算处理的单元。在线分布式数据处理软件中,Worker数量用户可以根据需求自行配置。Worker的主要任务就是从前面的输入队列中拿到数据包,调用配置指定的触发算法,对于数据包进行在线的数据计算与筛选,并将处理后的数据依照物理意义封装成事例,并打上对应物理意义的标签,放入输出队列中,以供模块输出单元进行数据输出。
KM2A的具体触发策略等在§3.4将给出详细描述。
4)模块输出单元。Output是模块中负责处理后的数据分发的单元。当触发模块打开本地存储功能时,模块输出单元会从输出队列中拿取处理好的数据存储到本地磁盘。当触发模块打开数据输出功能时,模块在完成本地存储相关工作后,会将数据拟成消息格式,进行消息的序列化,并判断数据类型,将序列化的数据发向所有配置时指定该类型需要发送的节点。当发送完成后,会将相关的内存删除。
5)模块信息管理单元。Info单元为模块的信息管理单元。该单元主要功能与执行方式与软件管理模块的信息管理单元相同。
2.4 软件通用模块概述
软件的内存管理主要由队列模块、内存池实现。软件内部节点间信息交换采用Protobuf进行消息的序列/逆序列化,采用ZeroMQ作为消息中间件。
2.4.1 队列模块
软件处理模块内部符合生产者-消费者模型,因此,考虑引入数据模型作为数据的缓冲区,从而使得模块可以在异步的状态工作,达到提高其抗性能波动能力的目的[9]。通常在此情况下考虑的数据模型有队列、环形缓冲区[10]等。本软件采用的是队列模型。首先,队列模型的队列长度可以自由变化;其次,队列的长度易于观察,从而能够在调试与运行阶段更加便捷地观察生产者与消费者间的性能差异与性能波动。队列模块相较于其他数据模型(如环形缓冲区)的开发与测试难度也更低。
2.4.2 内存池模块
Memory是一个内存池[11]。由于软件需要不停地创建和销毁内存,而大量的创建、销毁操作会产生很大的时间开销与内存碎片,因此,软件设计采用了内存池的内存管理方法。在软件开始接收数据之前,Memory负责创建好一定量的不同大小的内存。每次节点需要创建一个内存,实际操作就是从内存池拿一块已经创建好、最接近所需内存大小且比所需内存大的内存,并在拿取内存后设置内存的实际使用大小。而每次节点需要销毁内存,实际的对应操作就是将内存归还到内存池。如果内存池里的某大小内存“售罄”,则内存池在下次收到此大小内存的获取操作时,将创建一个具有这个大小的内存到内存池中,再将这块内存交给节点调用。当软件收到结束指令后,内存池里的内存统一销毁。
2.4.3 消息序列化与逆序列化
消息从结构化数据到流的解析过程成为序列化,反之为逆序列化。软件的序列化与逆序列化采用的是Protobuf工具。Protobuf是一种以字节流为载体的序列化协议和工具套件,规模小、速度快、性能高,所以广泛应用于通信协议、数据存储[12]。软件采用Protobuf对于消息进行序列化封装,随后采用ZeroMQ进行消息发送。消息接收方在利用ZeroMQ完成消息接收后,再采用Protobuf进行消息逆序列化解析,即可以得到消息的内容。
2.4.4 消息中间件
软件采用的是分布式结构,各节点间通信尤为重要,软件选取ZeroMQ完成此项工作。ZeroMQ是一个基于消息队列的套接字通信并发框架。它是一个面向消息的、开源的、跨语言的简单灵活的网络通信库,且在数据量很大的使用场景下依然能保持高性能数据传输,而且能屏蔽底层通信细节。考虑到性能优秀、开发简单等诸多优点,软件选组ZeroMQ完成节点间通信[13]。
3 触发算法实现
该软件为用户提供了N-Hit触发算法作为样例,为用户开发个性化触发算法的参考。LHAASO地面簇射粒子阵列中,主要设计采用的就是N-Hit算法。
Hit,即击中数据包。N-Hit触发算法是指在某个时间窗口内,着火探测单元的数量大于“N”时,判定触发,这是当今宇宙线实验中最常见的触发方式。在整体实验中,只有电磁粒子探测器参与触发条件判选,当满足触发条件时,将触发时间内来自电磁粒子探测器的数据包和缪子探测器的数据包统一进行打包,封装成事例。软件设计中,采用滑动时间窗口的方式,从排序后的击中数据流中挑选满足“N”触发条件的事例的算法。
3.1 击中数据包排序
算法的第一步是对所有击中数据包进行排序。输入在线分布式数据处理软件的击中数据包是按照单个通道保序的,但不同通道的击中数据包之间不遵循序列号递增的原则。因此,为满足滑动时间窗口的条件,需要进行击中数据包间排序。
算法采用的排序方法为合并排序方法。将两个有序数列合并为一个有序数列为“归并”。合并排序是建立于归并操作上的一种非常有效的排序算法。属于分治法的一个典型应用。合并排序的主要作用为:将两个或者两个以上的有序表合并成一个新的有序表。首先,将待排序的序列分成若干个子序列,每个子序列都是有序的。然后再把有序的子序列合并为整体有序的序列。
3.2 滑动时间窗“N-Hit”算法
该算法在时间保序的击中数据包数组上实现,主要负责挑选满足“n>N”的触发条件的时间窗内数据,并打包成事例。首先,算法会开一个Tw时间宽度的时间窗,搜索整个数据包,当发现时间窗内“n>N”时,记录“触发开始”;随后,当发现时间窗内“n<N”时,记录“触发结束”。“触发开始”与“触发结束”之间的击中数据包会被打包成新的事例。算法时间复杂度为O(N)。
假设N设为25,则算法处理示例如图7所示。
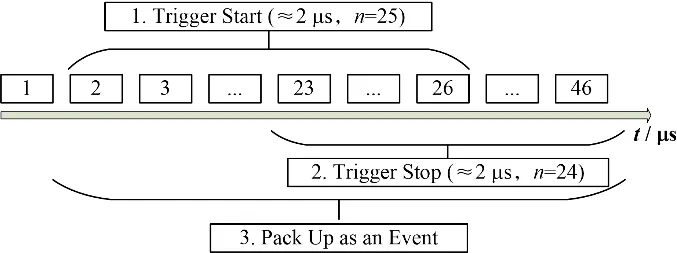
图7 N-Hit算法示例图Fig.7 N-Hit algorithm diagram
3.3 数据包边界处理
以上算法可以从一个数据包内挑出满足“NHit”条件的事例,但是若单纯逐个数据包处理,则会遗失跨两个数据包的满足“N-Hit”条件的事例。为防止此类事例丢失,算法对于输入的打包数据有一定的要求,需要输入的每个数据包内保留一小段后一个数据包的时间的数据。这样,跨数据包的事例将会在前一个数据包的在线数据处理中被处理,从而防止了跨数据包事例的漏处理。
3.4 KM2A触发策略
KM2A选取N-Hit作为触发算法。采用部分探测器参与触发判选,全部探测器参与数据打包的策略。在KM2A触发过程中,首先进行ED击中数据包时间提取与时间排序。随后,利用滑动时间窗“NHit”算法对于ED进行时间窗搜索。当搜索到“触发开始”和“触发结束”后,对于此区间内ED与MD的数据包进行打包,从而达到ED重建出原初宇宙线粒子的能量和方向,MD区分质子与γ,和鉴别原初强子宇宙线的种类的功能。
4 软件测试
软件的测试分为模拟测试与实际运行测试两方面。模拟测试采用模拟数据输入,主要用于测试软件的功能,软件的实际运行测试采用真实探测器系统进行测试,主要用于测试软件是否满足性能需求。
4.1 模拟测试
为了方便用户对于个性化开发的触发算法进行功能测试,另外提供了离线触发算法测试的软件,以及数据解析软件。离线触发测试软件的主要功能:接收FRAGMENT类型消息作为输入,调用某一指定的触发算法对消息进行处理,并将处理后的事例进行存储。数据解析软件的主要功能:读取离线触发测试软件产生的存储文件,对其中的数据进行格式解析,检查数据格式是否符合约定。
图8为N-Hit算法产生的数据文件开头部分的截图。数据文件采用的是“文件头+事例”的格式标准。前256字节为文件头,主要包含文件的基本描述性信息,如文件格式版本号、运行编号、文件开始/结束录入时间、文件名、文件名大小、文件头保留位等。事例采用的是“事例头+事例数据内容”的格式,事例头包括事例头标志位、事例头长度、事例长度、事例编号、事例时间、事例流标志位等。事例数据内容包括事例类型标签与事例数据包。
如图8所示,“ee34 12ee”为事例头标志位,“2400 0000”为事例头长度。“0000 0000”为事例头扩展部分长度,“8e12 0000”为事例总长度,“0100 0000”为事例类型标签。综合数据文件与数据解析程序分析,N-Hit算法能产生符合要求的数据。

图8 N-Hit产生数据文件的数据片段Fig.8 Data fragment in data file generated by N-Hit
4.2 实际运行测试
实际运行测试:将该在线分布式数据处理软件集成到数据流软件中,在数据获取系统对实际的地面簇射粒子阵列进行数据采集与处理工作时,对数据处理软件的功能与性能进行测试。
数据获取系统硬件采用的是两组共28片刀片服务器,CentOS Linux release 7.4.1708版本64位操作系统,内核版本采用的是3.10.0,CPU配置为48×3.00 GHz CPU(超线程开),CPU型号为Intel(R)Xeon(R)Gold 6136 CPU@3.00 GHz。
此时数据获取系统共计连接2 380台ED和570台MD,数据获取系统总计输入带宽约230 MB·s-1。共计配置处理节点27个,管理节点1个。由于软件管理节点负荷很轻,此处给出处理节点负荷变化。图9、10与表1为实际运行一段时间后某一节点的负荷情况,每45 min采样一次,共采样约8 h。值得提出的是,出于对前期触发产生事例的分析考虑,实际触发算法较原设计N-Hit触发策略稍有修改,如此处采用的是ED与MD均可参与触发的方式等。

图9 某处理节点输入带宽Fig.9 Input bandwidth of one processing node

表1 某处理节点待处理任务数量Table 1 Amount of buffered packs in one processing node
图10 某处理节点输出带宽Fig.10 Output bandwidth of one processing node
图9 ~12与表1~2为某段运行时间内不同时刻节点统计数据。图9~10与表1为单节点统计数据,图11~12与表2为所有处理节点总计统计数据。图9统计了软件某节点输入数据包的速率,可以看出,输入带宽相对比较稳定,没有随着时间的推移而出现显著的带宽不断上升或下降的趋势。表1为该节点的待处理数据包的数量。从表1可以看出,该节点待处理数据包在几次观测点均为0,证明所有输入到该节点的数据包均迅速完成了数据处理,不存在节点内部数据包堆积的现象。图10为该节点输出数据包的速率。从图10可以看出,节点的输出带宽虽然出现了部分抖动,但是抖动均不超过某一范围。
图11为软件所有处理节点总输入带宽。从图11中可以看出,处理节点总输入带宽与预计带宽稍有偏高但相差不大。由于不同时刻不同探测器的击中情况不同,导致预计带宽时只能依照设计指标与前期运行情况给出大致统计。而由于数据在全部数据流软件中进行传递时会进行多次格式变动(如数据组装时会添加部分数据格式),因此,可认为处理节点总输入带宽基本与预期相差无几。图12为软件所有处理节点的输出带宽,从图12可以看出,总输出带宽在某一范围内有一定抖动变化。抖动的产生与影响因素有很多,比如不同时刻输入带宽的变化,网络的性能抖动,以及节点的缓存机制,数据的统计方式等。虽然输出带宽存在较大抖动,但是长时间内软件处理节点输入带宽与预期基本相符,节点基本不存在任务堆积,处理节点不存在资源紧张问题,且产生的事例文件速率与预期差别不大,因此,可以认为软件并没有呈现出性能不足的问题。表2为所有处理节点总待处理任务数量。从表2可以看出,大部分观测时间点所有节点都没有待处理任务堆积,某个别时间点,可能存在少量的待处理任务堆积,但是随即被节点内部消化掉了,没有造成后续影响。
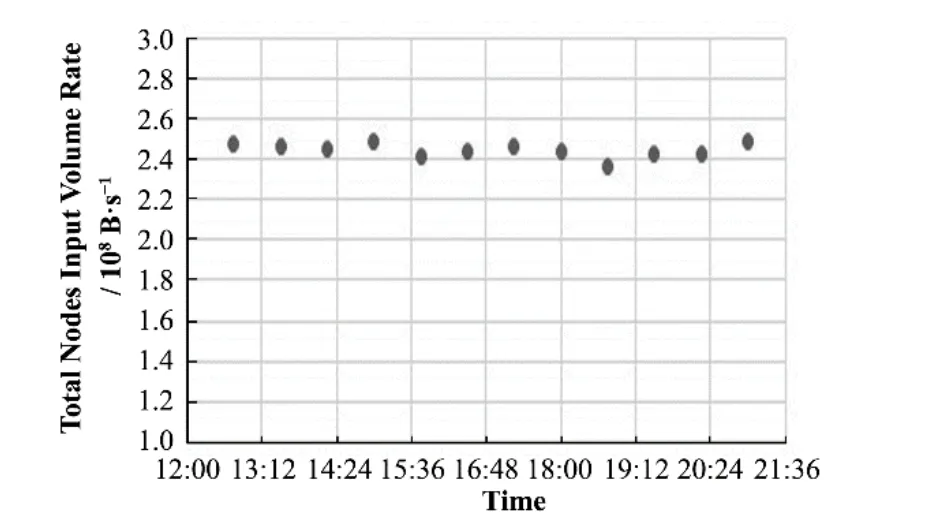
图11 总处理节点输入带宽Fig.11 Input bandwidth of all processing nodes
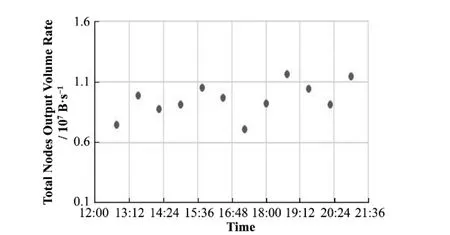
图12 总处理节点输出带宽Fig.12 Output bandwidth of all processing nodes

表2 某处理节点待处理任务数量Table 2 Amount of buffered packs in one processing node
图13为此次观测时间段内产生的某一个事例数据文件的文件头部分。软件实际运行产生的数据与模拟运行产生的数据格式没有区别。因此,可以套用§4.1中对于模拟数据的格式分析,对于图13的格式进行分析检查。

图13 事例数据文件中数据片段Fig.13 Data fragment in event data file
图14 为通过离线格式检查程序对事例数据文件进行初步检查。从图14可以看出,事例数据文件通过了格式检查,不存在格式错误问题。由图14可见,处理节点完成了数据筛选的功能,且性能足够满足需求。
5 系统部署与运行状况
LHAASO地面簇射粒子阵列在线分布式数据处理软件,已经作为LHAASO数据流软件的一个重要组成部分,集成到了LHAASO数据获取系统中。
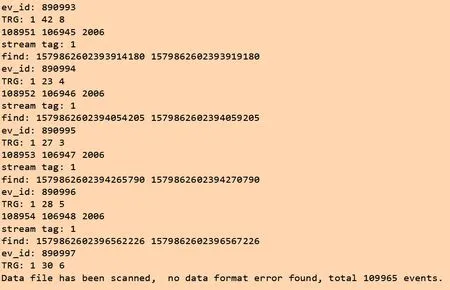
图14 事例数据文件检查Fig.14 Event data file check
2018年,LHAASO数据获取系统已经部署到了四川省稻城县海子山的计算机房。从2018年起,LHAASO数据获取系统已经配合着地面簇射粒子阵列的扩建,边调整部署边运行取数实验。2019年9月19~20日,LHAASO数据获取系统1/4规模的鉴定验收会在LHAASO测控基地(稻城)召开,会议针对数据获取开展了现场测试。现场测试表明,数据获取系统各项性能指标均达到LHAASO 1/4实验要求。专家组一致同意数据获取1/4系统通过鉴定。这表明数据获取系统数据流软件搭载的本在线分布式数据处理软件功能与性能均达到了项目的需求,能顺利完成软件的任务。
截止2020年1月6日,KM2A共计建成并投入科学运行2 398台ED和574台MD,达到了LHAASO实验1/2的规模。在此规模下,分布式在线处理软件运行良好。
6 结语
本文以LHAASO实验为项目背景与目标,设计与实现了一套针对地面簇射粒子阵列的在线分布式数据处理软件。该软件提供了无硬件触发的高能物理实验背景下,一种在线实时完成软件触发与数据筛选的通用解决方案与解决平台。一方面,在线分布式数据处理可以保证实时得到触发结果,便于掌握实验状况进行实验调整,另一方面,在线完成数据处理可以减轻数据存储负担,将冗余数据在存储前剔除掉。与此同时,可以挂载不同的触发算法并对触发算法的参数进行灵活调整,也保证了这种通用解决方案与平台的高可用性。该在线数据处理软件功能上能够灵活挂载多种多样的触发算法,性能上充分满足了LHAASO地面簇射粒子阵列及类似规模物理实验的性能需求。此外,软件设计结构简洁,模块划分合理,还具有高度的可移植性。
软件目前已集成到数据获取系统。至2020年1月6日,地面簇射粒子阵列1/2规模已完成建设并投入科学运行,在此规模下,软件运行稳定,状态良好。考虑到1/2规模下,软件运行压力适中,且只要增加处理节点个数即可提高软件性能,因此,当实验规模继续扩展时,可以通过继续增添硬件设备,灵活调整部署方案,使得软件也能满足全阵列规模的运行。下一步,该软件将继续作为数据获取系统数据流软件的一部分,配合项目阵列的扩展继续调整部署扩展运行。同时还将针对多阵列联合触发的需求与实际情况,对于多种触发算法联合挂载开发更加贴合实际需求的解决方案。
