基于可信度的Android恶意代码多模型协同检测方法
2020-04-07,,,,,*
,,,,,*
(1. 中国民用航空华东地区空中交通管理局,上海200335;2. 南开大学网络空间安全学院,天津300350;3. 国家计算机病毒应急处理中心,天津300457)
根据中国互联网络信息中心发布的研究报告[1],截止2018年5月,我国监测到的移动应用程序在架数量为415万款,其中基于Android平台开发的应用更是占据了大部分市场。由于开源性和高占有率,Android操作系统成为恶意攻击者针对移动平台的首要攻击目标。同时,由于用户的盲目授权使攻击者可以轻易绕过系统自带的安全屏障,如权限声明机制、访问控制机制等。利用机器学习算法进行恶意应用检测是目前常用的静态检测手段。
恶意应用检测方法实际上是二分类问题,指从大量的Android应用中区分出哪些应用是恶意应用。一般分为以下2个步骤:第一步,通过对应用的解析,能够得到应用的各种描述信息,再从描述信息中提出多种用于分类的特征;第二步,利用数据挖掘技术,再根据提取的特征构造分类器。相比于以往的人工分析,利用机器学习检测可以降低成本、提升效率。
但这种检测技术也存在一定的问题,一方面大多数检测方法的特征空间是公开的,并且仅仅依赖于单模型。黑客可以根据特征的权重,修改恶意代码的部分内容,使得恶意样本能够规避单模型的分类,从而使模型的准确度下降。另一方面,恶意代码变异和进化速度快、结构复杂,每一次恶意代码变种的出现和大规模繁殖都是经济效益驱动的结果,严重阻碍着数据挖掘技术的有效应用。为了有效缓解模型退化带来的预测效果下降的问题,本文提出基于可信度的多模型协同检测方法。
1 相关工作
1.1 Android恶意代码检测技术
恶意代码检测技术主要分为2种:基于签名的检测方法和基于行为的检测方法。基于签名的检测方法比较传统,由于Android手机的计算能力、存储能力有限,因此基于签名的检测方法无法应用在手机上。而基于行为的检测技术不需要依赖签名,是当前主流的恶意代码检测方法。依据是否需要实际运行程序,可以将基于行为的检测技术分为以下3种。
1.1.1 静态分析方法
静态分析方法是当前应用最广泛的恶意代码检测方法。超过一半的检测方法是基于静态分析方法或静态分析方法和其他方法相结合的方式设计的。其优势是在应用安装前进行分析,不必在监测环境下运行代码。Ma等[2]提出了一种组合检测恶意代码的方法。该方法从应用的控制流图中提取API调用、API使用频率、API调用序列这3种静态特征,并分别使用C4.5、DNN、LSTM分类算法训练模型,最终采用投票的方法确定测试样本的标签。Vinod等[3]从随机输入和人工交互输入中提取系统调用,使用2种特征选择方法得到2个系统调用集合并构建特征矩阵,最后输入到RandomForest、RotationForest、AdaBoost这3个训练模型。
1.1.2 动态分析方法
动态分析要求在沙箱或隔离的环境中安装、执行应用,这样做的目的是为了能够尽可能准确地记录应用运行时的行为。网络流量分析是动态分析的实例,分析过程中的所有网络数据包均会被捕获分析。动态分析方法能够监控应用执行过程中应用的行为,并检测应用中是否存在恶意行为。该方法能提供更高的安全性,在分析正确的前提下,可以检测出使用混淆技术的恶意代码。缺点是需要在安装完成后执行检测操作。
1.1.3 混合分析方法
混合分析方法能够结合动态和静态的优势,能够提高检测的准确程度。DroidCat使用方法调用和组件间通信调用(ICC)2种动态特征进行恶意代码分类,能够实现比静态方法和基于系统调用的动态分析更好的鲁棒性[4]。MalDAE研究静态和动态API调用之间的联系,基于语义将它们合并为混合序列,并定义了多种恶意代码的行为类型,且提供可解释的检测结果,最终实现了97.89%的检测精度和94.39%的分类精度[5]。MADAM利用4个级别(内核、用户、应用、包)的特征实现了恶意代码检测和实时阻断恶意行为的功能,并能检测到来自125种恶意家族的恶意行为[6]。混合分析的缺点在于检测系统的设计十分复杂。
1.2 静态检测技术的改进
基础的静态检测方法因为模型退化,预测效果随之下降,可以从多方面改进检测模型。一种思路是对提取的特征进一步提纯,选择其中更具有代表性的特征,在提高运算效率的同时也能够提升模型预测的准确度[7]。Chen等[8]提出将二元特征矩阵通过数学分析改为连续计数的向量元素,连续计数取值区间为0到1。相比于二元矩阵,连续计数会更加精确。王全民等[9]也提出一种协同训练恶意代码的检测方法,具体做法是选取权限特征、API调用序列特征和Opcode特征形成3类非重叠的子视图,针对每一种特征选择最优的分类算法生成3个分类器,预测得到3个结果。当出现不一致情况时,根据少数服从多数的规则作出最终的决策。
2 Conformal prediction算法
Conformal prediction算法可以用于分类或回归分析的点预测,如SVM分类方法、决策树、boosting提高弱分类算法和神经网络等等[10]。利用该算法能够得到预测结果的可信程度。
2.1 不一致性度量函数
不一致程度测量的关键是一个实值函数A(B,z),该实值函数得到项z与集合B的不一致程度,以具体数值的形式表现出来。在一般情况下,z与z′(z′B)的距离可以表征这个程度,距离越大时,二者越不相似,故函数A的定义如下:
A(B,z):=d(z′(B),z)。
(1)
在分类算法中,假设B={z1,z2,…,zn-1},其中zi=(xi,yi),yi是xi的标签,那么不一致函数可以表示为:
(2)
另外,一致性程度与不一致程度是一组相对概念,取决于实值函数A(B,z)的定义。不论是利用一致性得分还是不一致性得分,对p-value的计算结果都不会产生影响。
2.2 p-value
Conformal prediction算法的关键是计算p-value,该值体现了待预测项的不一致性得分在所有项中的排名情况。计算所有训练集样本和测试集样本的不一致性得分,每计算一个训练集样本i的不一致性得分,需要利用其他样本训练一个新模型,用该模型预测i的标签并得到i的不一致性得分。循环得到所有样本的不一致性得分。
给定初始数据集{z1(x1,y1),z2(x2,y2),…,zn-1(xn-1,yn-1)},待预测zn(xn,yn)。Conformal prediction算法通过观察(z1,z2,…,zn-1,xn)预测yn,结合前文不一致程度测量函数A,Conformal prediction算法计算p-value的具体过程如下:
①假设yn=y,即zn:=(xn,y);
②i=1,2,…,n时,计算αi=A({z1,z2,…,zn}

p-value统计比αn大的αi的数量在总体n中的占比,p值越大,说明αn与原数据集越相似,yn=y的可能性越大。
2.3 两个概念:Vcredibility与Vconfidence
该算法引入2个概念,分别是Vcredibility和Vconfidence[11]。若有n种标签时,则循环假设y=yi(i= 1, 2,…,n),可以得到n个p-value值,记为P1,P2,…,Pn。那么:
Vcredibility=max(Pi),i=1, 2, …,n,
(3)
Vconfidence=1-max(PiVcredibility),i=1, 2, …,n。
(4)
当有4种标签时,Vcredibility与Vconfidence的说明如图1所示。

图1 Vcredibility与Vconfidence说明Fig.1 Instructions of Vcredibility and Vconfidence
Vcredibility越大,说明预测的准确度越高,但仅有这一项评价指标是片面的,Vcredibility较高并不能肯定预测项属于该类别,因为其他的p-value值可能也很高,所以引入Vconfidence这个概念,它计算的是待测样本与其他类别的不一致性,Vconfidence越大,说明待测样本与其他集合越不相似。
3 基于可信度的协同检测系统
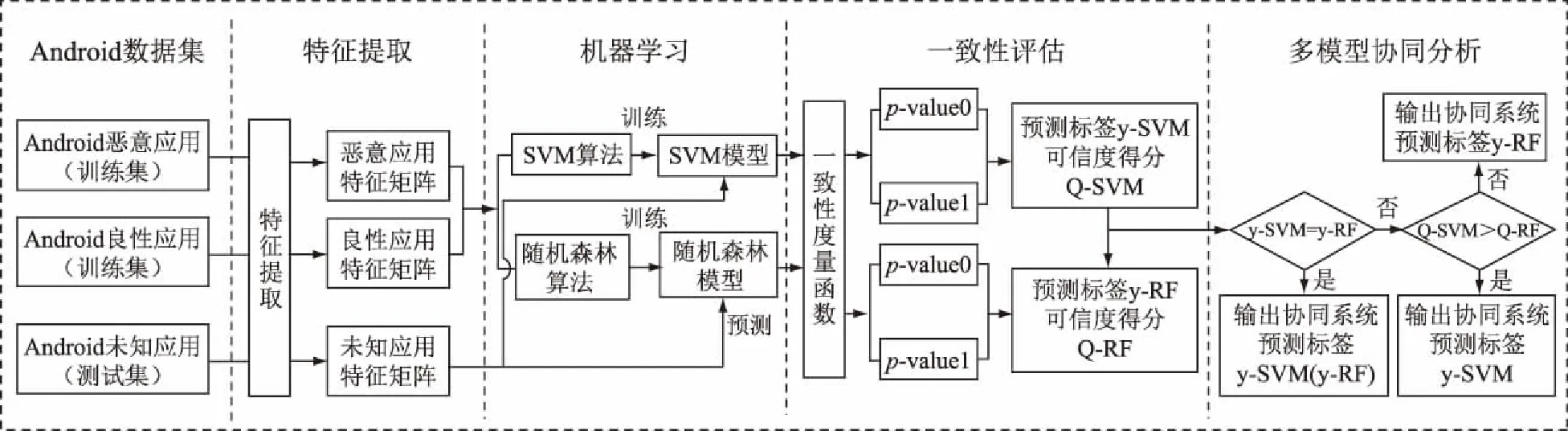
图2 系统的设计框架Fig.2 Framework of system
多模型协同检测系统的设计框架可分为如图2所示的5个部分:第一部分是Android应用的数据集,包括良性与恶意的训练集样本以及测试集样本;第二部分是特征提取,包括所选特征的相关信息和特征统计技术(TF-IDF)等;第三部分是根据机器学习算法建立2个模型,分别是SVM模型和随机森林模型;第四部分是利用Conformal prediction算法计算2种模型预测结果的可信程度;最后一部分介绍多模型协同分析方法,即最终协同系统的决策方法。
3.1 特征提取
本文参照DREBIN[12]算法中提出8种特征进行选择。从Android应用的manifest文件和字节码文件中各提取4种。然后将样本中涉及到的8类特征存储在后缀为data的文件中,样本与其特征文件一一对应。提取的特征信息如表1所示。

表1 Android应用提取的特征
前四类特征分别与硬件组件请求、权限信息、系统接口以及进程间交互的介质有关。恶意代码通过获得这些权限达成控制或入侵的目的。后四类特征从字节码文件中提取,由于dex文件是安装时生成的二进制文件,所以可以从中获得许多有用的信息。
以上选择的是字符串形式的特征,而机器学习算法输入的是数值向量。因此,需要利用统计方面的技术将字符串特征转化为数值向量。TF-IDF是一种词频统计技术,常用于信息检索和数据挖掘等方面。该技术的主要思想是:特征串i在Android应用j中出现的次数多,则它的词频(TF)就大,而在其他应用中出现的次数较少或甚至不出现,则认为特征串可以用来区分应用。同理,若包含特征串i的文件很少,特征串i的逆向文档频率(IDF)很大,也表明特征串i也有区分应用的能力。利用该技术可以保留重要的语料,完成字符串到向量的转化。
3.2 分类算法
根据特征提取部分,使用相同的特征构建SVM模型和随机森林模型。
SVM算法建立二分类模型,主要思想是在空间中寻找一个能将所有数据划开的超平面,使得点到超平面的间隔最大。针对恶意代码检测,SVM根据输入样本得到能够区分良性与恶意应用的超平面,并根据未知应用的特征向量预测其所属类别。
随机森林算法是集成学习思维的应用。该算法建立多棵决策树,通过投票表决得到最终结果,具有分类效果好,不容易产生过拟合等优势。
2种算法在不同场景下各有优势。随机森林算法可以处理缺失属性的样本以及样本特征关联性不强的情形。SVM算法能够应对特征量巨大的情况,同时不需要依赖全部数据[13]。正是因为两者依据完全不同的分类方法,各有优劣,所以本文利用2种算法协同检测,选择可信度更高的结果,能够在一定程度上提高预测的准确度。
3.3 可信度计算
传统学习模型的分类结果只说明未知应用“是”或者“不是”恶意应用,不能给出预测结果的可信度,更无从得知模型是否存在退化的问题,所以我们将一致性评估方法应用于协同检测系统中,用于计算每一个单模型预测结果,得到其可信程度。
3.3.1 计算未知应用xi的一致性得分
分类问题依赖于评分函数,而评分函数是用来测量一个样本与一组旧样本之间的差异性。对于不同的算法,测试样本的一致性得分就等于算法评分函数的输出值。因为一致性评估和算法本身无关,所以可以在多种机器学习算法的顶层利用预测结果的可信度进行恶意代码检测。本文利用SVM和随机森林分类模型实现协同分析,使用2种模型分别预测未知应用xi的标签,而后计算每个模型对未知应用的评分。由于恶意代码检测是二分类问题,故只有恶意与良性2种标签,且每一类标签都有对应的评分(衡量未知应用xi与其他应用之间的差异性程度)。对于未知应用xi,每个模型都输出2个评分,总共可以得到4个一致性得分:
(5)
3.3.2 计算未知应用xi的p-value
p-value是表示一个新应用与已知应用集合之间一致性的统计量,反映了新应用在已知集合中的显著程度。计算一致性得分是计算p-value的基础。根据一致性得分与标签数量的关系,并且协同分析系统是在2个模型的基础上实现的,所以未知应用xi对应4个一致性得分。同样地,可以计算出xi的4个p-value值:
(6)
3.3.3 计算未知应用xi的Vcredibility与Vconfidence
对于未知应用xi,可以从每个模型的预测结果中得到1组Vcredibility和Vconfidence。根据本文中使用的SVM和随机森林分类模型,可以得到2组Vcredibility和Vconfidence:
(7)
3.3.4 计算未知应用xi的Vquality
本文定义一个综合评价模型预测指标Vquality,即预测结果的可信程度。Vquality的计算表达式如(8)所示。
Vquality=Vcredibility×Vconfidence。
(8)
Vcredibility越大,说明待测样本与预测集合越相似,Vconfidence越大,待测样本与其他集合的相似程度越小,所以将二者相乘得到的Vquality可以更加全面地、放大地考虑某一模型预测结果的可信程度。
3.4 决策方法
协同检测系统的预测结果从2个单模型的预测结果中选择。
①当2个单模型预测结果一致时,可以相互印证,协同检测系统的结果与二者相同。
②当2个单模型预测结果相异时,比较2个单模型的Vquality,选择Vquality更大的模型预测结果作为最终预测结果。
4 实验结果
4.1 实验数据
AndroZoo是一个从多种渠道收集Android应用的平台,并以APK的形式呈现给使用者。本次实验的数据全部来源这个网站。
取2015年1月到10月的部分应用作为本次实验数据,其中1月、2月为训练集,3月至10月为测试集,每月取良性样本与恶意样本的比例为1∶1,共获得训练集样本13 028个,测试集样本66 972个,训练集样本分布见表2,测试集样本分布见表3。

表2 训练集样本分布

表3 测试集样本分布
4.2 评价指标
在机器学习算法中,需要用不同的指标对算法的预测情况作出评价,在本次系统设计中,选择精确率(Precision)、召回率(Recall)和综合评价指标(F1)三者作为衡量其预测优劣的依据。精确率体现的是预测正确的数据占全部数据的比值;召回率体现的是所有预测为正类的数据中预测正确的数据占比;而综合评价指标F1则是综合考虑精确率、召回率后给出的计算公式,其中TP代表将正类预测为正类的数量,TN代表将负类预测为负类的数量,TFP代表将负类预测为正类的数量,ηP代表精确率,ηR代表召回率。评价指标的公式见表4。

表4 评价指标公式
4.3 实验设计
用训练集数据分别训练SVM、随机森林和协同检测的模型,得到3个模型SModel、RModel、HModel。利用3种模型分别预测3月至10月的测试数据,计算其准确率、召回率和F1,观察协同检测系统的预测效果。
4.4 实验结果
4.4.1 SVM模型测试结果
利用SVM模型预测3月至10月的恶意样本与良性样本的结果详见表5。

表5 SVM模型预测结果
4.4.2 随机森林模型测试结果
利用随机森林模型预测3月至10月的恶意样本与良性样本的结果详见表6。

表6 随机森林模型预测结果
4.4.3 协同检测模型测试结果
协同检测模型预测恶意样本与良性样本的结果详见表7。

表7 协同检测模型系统预测结果
4.4.4 3种模型测试结果对比
F1能够综合反映预测效果,3种模型预测结果的F1平均值详见表8。

表8 F1平均值比较
4.5 结果分析
预测恶意样本时,2种单模型相比较,SVM预测的准确度低、召回率高。协同检测系统的效果最好:与SVM相比,F1值平均提升了0.875%。通过预测准确度计算,在33 468个恶意测试样本中有1 004个错误预测的样本被修正。与随机森林相比,F1值平均提升了1.625%,召回率也由单模型的0.87上升至0.91。
预测良性样本时,2种单模型中,SVM的预测准确度高,但召回率低。协同检测系统仍然具有最好的效果:与SVM相比,F1值平均提升了1.375%,召回率由原来的0.80提升至0.83。与随机森林相比,F1值平均提升了1.125%,通过预测准确度计算有1 339个良性样本被修正。
结果显示,SVM和随机森林的预测效果在不同场景下各有优劣,两种模型的结合能够优势互补从而有效提高协同检测系统预测的准确程度。
F1值能够综合反映预测结果,比较三者的F1值,恶意样本与良性样本的结果分别如图3、图4所示。因为恶意代码繁殖速度快、变形多,随着时间推移,模型退化也会影响预测效果,故3月到10月的预测结果总体呈下降趋势。其中7月F1值明显低于其他月份,初步分析是由于该月份测试数据中的应用特征在训练集中涵盖较少。协同检测系统在个别月份与单个模型的F1值相同,提升效果不明显。分析实验的不足,一方面是实验样本的训练集规模较小,这会影响p-value,即测试样本排名的计算。另一方面,在根据Vquality对2种模型预测结果相异进行取舍时,没有找到更好的方法对实际上正确的模型预测结果进行有效放大。但总体来说,协同检测系统能够保证在不低于每一种单模型的基础上有所提升。

图4 良性测试样本的比较Fig.4 Comparison of benign samples
5 结束语
模型退化将会使攻击者更容易躲避检测,为了缓解这个问题,本文提出基于可信度的多模型协同检测方法,用SVM和随机森林分类算法各训练一个模型,对待测样本进行预测会得到2个结果。利用Comformal prediction算法分别计算预测结果的可信程度,当2个模型的预测结果不一致时选择更为可信的结果作为协同检测系统的结果。
