基于PCA的哈希图像检索算法
2020-03-07马绍覃
马绍覃,张 鸿
(1.武汉科技大学 计算机科学与技术学院,湖北 武汉 430065;2.武汉科技大学 智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉 430065)
0 引 言
基于哈希[1-6]的图像检索技术致力于解决大规模数据集下图像的查找问题,通过将原图像转化为二进制编码表示,图像特征转化为对应的二进制编码,不仅可以极大压缩存储空间,还能够大幅度提高检索速度。
图像哈希技术的主要步骤可分为投影与量化,已有学者证明[7],两个阶段对于图像哈希编码的性能都有着巨大的影响。而现在的研究更加偏向于投影阶段,对于量化阶段研究较少。本文同时从两个方面进行分析,在投影阶段,将主成分分析(principal component analysis)嵌入,对原数据特征矩阵进行降维,将其投影到新的特征空间中,同时尽量降低了信息的损失。在量化阶段,不同于现在大多数哈希算法所采用的单比特量化(single-bit quantization,SBQ),使用了一种全新的量化方法,称为适应性比特量化(adaptive-bit quantization,ABQ),减少量化带来的误差。最后,通过综合性的实验验证了所提算法的有效性。
1 相关工作
图像哈希技术源自于20世纪90年代末,其思想是利用哈希函数将表示原图像的高维特征映射到低维的汉明空间中,同时以一定的概率保证在原空间中距离较近的点投影后距离也近,而距离较远的点投影后距离也远,然后在低维的汉明空间中,利用汉明距离来衡量点之间的相似度。如果能产生良好的哈希编码去表示原图像,不仅能够显著地提升计算速度,因为比较距离只需要进行简单的位运算,而且还可以大幅度降低存储量,比如,原来空间中每个数据样本都被一个1024 B的向量表示,一个包含一亿个样本的数据集需要占用100 GB的存储空间。但是,如果把每个数据样本都映射为128位的哈希码表示,一亿个样本的存储空间只需要1.6 GB。
图像哈希算法基本上可分为两大类,一类是数据独立型的,较为经典的是局部敏感哈希(locality sensitive hashing,LSH)[8]和其扩展方法[9]等,这类方法不依赖于具体的数据,采用多个随机生成的函数构成投影函数簇,然后量化得到最终的哈希编码,随着编码位数的提高能获得较好的编码效果。一类是数据依赖型的哈希算法,也称为基于学习的哈希算法[10-12],通过分析样本数据的信息来构造投影函数,如数据固有的结构信息和语义信息等。在两类哈希算法中,通过学习得到的哈希函数相比较随机映射的哈希函数,在编码位数相同的情况下,前者比后者编码的效果普遍更好,所以现在的研究热点基本上都是针对于前者。在数据依赖型的方法中,基于PCA的哈希算法是较为经典的[13-15],其大致做法是首先对原数据做PCA,得到降维矩阵后再进行量化处理。但是,对于PCA来说,方差越大的方向携带的信息也越多,将各个方向的投影数据等比特编码会导致极大的量化误差,现在的大多数方法都是采用的单比特量化,即将投影后的数据,每一位都与设定的阈值相比较,大于阈值量化为1,小于则量化为0。这样不仅忽略了不同方差方向所携带信息的不同,也使得阈值两边极为接近的数据被量化成了不同的比特位。Weiss等[13]为了减少量化的损失,使用拉普拉斯特征函数公式在数据范围大的方向分配更多的比特,但是这种方法依赖于数据在高维空间均匀分布的假设之上。Wang等[14]为了捕获数据方差大的方向,对其目标函数进行了一系列的放松,虽然最后的实验效果有所改善,但是没有摆脱单比特量化的局限性。
2 研究方法
在本文中,为了保证最后哈希编码性能的优越性,将从投影和量化两个阶段进行研究。投影阶段,通过分析,嵌入PCA算法;量化阶段,结合投影方法的特性,提出了适应性比特量化算法(ABQ)。具体来说,即将PCA投影后的数据,根据阈值划分量化空间,对不同空间的数据采取不同的量化方法,减少误差的同时,保证量化速度。
2.1 PCA嵌入
根据Weiss等[13],Wang等[14]以及香农定理,要想得到紧凑且有效的哈希编码,编码后每个比特之间的方差应该最大且编码之间要互不相关。所以最大化如下目标函数

(1)
W为投影矩阵,其维度与具体的量化函数有关,后面会做具体的分析,x={x1,x2,…,xn} 为数据集,xi∈Rd, var(·) 表示一个向量或矩阵的方差,h(x) 表示数据集x对应的哈希函数,q(v) 表示量化函数,hk(x)=q(xtk),B是量化后编码矩阵,B∈Rn×c。 由于式(1)的离散问题和编码之间正交的限制,我们将目标函数进行放松
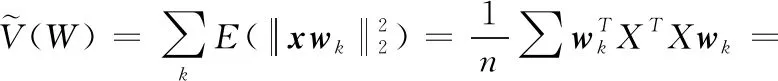
(2)
X∈Rn×d是由xi组成的数据矩阵,式(2)所寻求的目标和PCA正好是一致的,寻找协方差矩阵XTX的前k个最大的特征值对应的特征向量所组成的投影矩阵W, 用于最大限度保留原始数据的整体相似性。W的维度或者说k的大小与具体量化方法有关,后面会做相关的分析。
2.2 适应性比特量化
针对单比特量化和双比特量化(double-bit quantization,DBQ)在基于PCA哈希量化过程中的优势与缺陷,我们提出了ABQ。按照PCA的理论之一,其投影矩阵W是逐一选取方差最大的方向所组成的,方差大的方向上的投影所包含的信息量会更大,也就是说,这一部分的信息会更加重要,应该在量化的过程中体现这一重要特性,仅仅使用SBQ或者DBQ这样等比特编码方式是无法做到的。上一小节提到过W的维度或者说特征向量k的个数是与量化函数和编码长度有关的。设编码长度为c,若采用SBQ,则k的大小等于c,因为投影后每个数据位量化为一个比特位,这样SBQ最大程度的利用了投影矩阵,保留了更多的编码信息,但缺点是量化误差较大。采用DBQ则k等于c的一半,相比SBQ,DBQ只利用到投影矩阵的一半,加快了速度,但是同时也丢失了更多的编码信息。本文提出的ABQ不仅速度上要快于SBQ,而且相比DBQ保留了更多的编码信息。对于长度为c的编码,首先确定一个比例系数λ,依据λ去划分待量化的数据域,对于原特征空间中投影后的新特征空间中的向量,认为数据位的前λc位是比较重要的,每位量化为两个比特,而数据位的后c-λc位相对来说次要一些,每位量化为一个比特。
3 算法实现
本文算法大致分为两步,投影与量化。投影阶段运用PCA,将数据矩阵X∈Rn×d映射到新的低维空间(这里假设数据矩阵是零中心化的),得到降维矩阵Z∈Rn×k。 对于新的特征空间采用ABQ进行量化。
投影阶段之前已做了较为详细的分析,不再重述,在量化阶段,首先确定一个比例系数λ, 实验结果表明设置λ=0.75在不同位数的编码上都能取得较好的效果,我们也会给出λ 取不同值情况下的实验对比效果。对于待量化的数据,单比特量化的部分,使用如下方法

(3)
对于双比特量化的数据,我们采用一种动态阈值划分的方法,根据待量化的数据获取一个下阈值a和上阈值b, 通过a和b将需要量化的数据划分为3个子集S1={x|-∞ (4) μi表示子集Si的均值。首先设置μ2为0,表示中间子集S2以0作为均值,那么式(4)转化为 (5) |Si| 表示相应子集Si中元素的个数。可以看出,式(5)的第一部分为常量,则最终优化目标转化为最大化如下目标函数 (6) 通过式(6)学习到动态阈值a和b, 将待量化的数据划分为3个区域。采用如图1(b)的方法进行量化。结合单比特量化阶段数据编码的结果,组合成最终的编码矩阵B=[b1,b2,…,bc]。 DBQ算法流程如下所示: 算法1:DBQ算法流程 输入:数据集S; 输出:阈值上限a, 阈值下限b; (1)将数据划分为3个子集: S1={x|-∞ S2=∅, S3={x|0 (2)将S1和S3分别排序,设置max=0; (3)判断S1或者S3是否为空集,如果为空转向步骤(4),否则转向步骤(8); (4)计算S2中的数据和,如果小于等于0,则把S3中最小的数移到S2中,反之则把S1中最大的数移到S2; (5)根据式(6)计算F; (6)比较F与max的大小,如果F大于max, 则把max更新为F, 设置a为当前S2中的最小值,b为当前S2中的最大值; (7)回到步骤(3); (8)返回a和b。 图1 (a)SBQ与(b)DBQ的量化效果 算法的全部流程如下所示: 算法2:PCA-ABQ算法流程 4.地势高危,道路险要。因王罕岭山体三面腾空而起,而剩下的一面又是连接大湖山主峰,山势坡度大,悬崖峭壁分布众多,从而形成了古诗文所述的“高崖万沓,邃涧千回”“乔峰迥峭,擘汉分星”“其险如崩,其耸如腾”和“白云生石壁”等自然特征。如人要上王罕岭,必须沿腾空的山岩攀登,路途之艰险就不难想象了。 输入:训练集X∈Rn×d, 比例系数λ, 编码位数c; 输出:矩阵B∈Rn×c。 (1)通过式(2)计算出投影矩阵W; (2)根据步骤(1)的结果将原数据进行投影得到低维空间的数据,Z∈Rn×k; (3)将Z按照λ, 划分为两个子矩阵,Z1和Z2, 对于Z1采用双比特量化得到编码矩阵B1, 对于Z2采用单比特量化得到编码矩阵B2; (4)组合B1和B2得到最终编码矩阵B。 CIFAR-10:CIFAR-10数据集包括60 000张彩色的图片,被划分为10个图像类别,每张图片包含32×32个像素点,实验中以512维的GIST描述子表示。 CALTECH256:CALTECH256数据集包含256种类别的物体,大约30 607张图像,每类包含图片最少80张,最多827张。每张图片用一个2048维的特征向量表示。 LSH(locality sensitive hashing):数据独立型的哈希算法,其哈希函数为随机生成的线性函数。 SH(spectral hashing):将图像特征向量的编码过程视为图分割问题,借助于对相似图的拉普拉斯矩阵特征值和特征向量的分析对图的分割问题提供一个松弛解。 KLSH(kernelized locality sensitive hashing):核局部敏感哈希,将目标函数映射到核空间。 DSH(deep supervised hashing)[16]:针对单纯地使用随机投影带来的较大误差,通过分析数据的几何结构,选择与原始数据分布最相似的哈希函数。 SPH(spherical Hashing)[17]:使用基于超球面的哈希函数将数据点映射成二进制向量。 MAP(mean average precision):检索得到的所有训练样本的平均准确率,被广泛地应用在哈希算法性能的评判中。 Precision-Recall:Precision即查准率,Recall为查全率,前者是指检出的相关目标数占检出总数的百分比,反映了检索的准确性;后者指检索的相关目标数占系统中相关目标总数的百分比,反映检索的全面性。通常是希望检索结果的查准率越高越好,同时查全率也越高越好,但实际上这两个指标是负相关的关系。在信息检索中常常使用Precision-Recall曲线来评判检索性能,其曲线高低和检索效果是呈现正相关关系的。 实验分别在两个数据集上进行,每个数据集随机取1000个样本作为测试数据集,剩余的样本作为训练数据集。为了保证实验效果的公平和准确,我们在每种方法上循环10次以获取最终的实验结果。并以图表的形式展现。表1展现的是λ 设置不同值时,在CIFAR-10数据集和CALTECH256数据集上MAP值。值得说明的是λ=0时对应为SBQ,λ=1时对应DBQ。从实验的结果可以看到λ=0.75时,在两个数据集上的检索效果基本上都是最好的,如在CALTECH256数据集上,相比SBQ其MAP值平均提高了12%,比DBQ提高了6%,这是因为此时不但很好地减少了量化误差,也尽可能多地保留了投影信息,这也可以说明量化阶段对于编码性能的重要性。其中CALTECH256上的MAP值在整体上要高于CIFRA-10,是因为样本特征提取方法不同的缘故,本文研究的重点不在于此,故不做赘述,但这并不影响对实验效果的分析与比较。图2和图3对应了不同哈希算法两个数据集上的PR曲线,我们提出的PCA-ABQ在不同位数上的编码效果均要优于现有流行的哈希算法。可以看到,PCA-SBQ方法在整体上的编码效果是比较差的,因为量化所带来的误差太大,虽然保留了较多的投影信息,但是量化的误差也较大,PCA-DBQ的检索效果整体上则要优于PCA-SBQ,因为减小了量化带来的误差,而PCA-ABQ充分利用了基于PCA哈希的特性,在减少量化误差,与保留投影信息之间寻找到一个平衡点,取得了最好的检索效果。相较于随机投影的哈希算法,PCA-ABQ无论是在低位和高位编码上都能取得较好的检索效果,而基于随机投影的算法,在低位编码上的性能是比较差的,因为其哈希函数的碰撞几率比较大,只有在编码位数比较高的情况下,才能达到较好的检索效果。 表1 λ取值不同时在两个数据集上的MAP值 图2 不同哈希算法在CIFAR-10数据集上的precision-recall曲线 图3 不同哈希算法在Caltech256数据集上的precision-recall曲线 本文基于PCA哈希的相关理论,提出了一种高效的哈希算法——PCA-ABQ。对于图像哈希的两个阶段,投影与量化,投影阶段我们采用现在流行的降维方法PCA将原特征空间的数据映射到新的子空间。量化阶段,针对PCA的特性,采用一种分段量化的思想,通过实验来确定最佳的比例系数。实验中,我们在不同数据集,不同评价指标上与现在主流的图像哈希算法进行了对比,验证了我们算法的优越性。但是仍然有值得改进的地方,在投影阶段,是基于PCA构造的投影函数,使得训练的时间比较长,量化阶段是建立在PCA降维的基础之上的,有一定的局限性。在今后的工作中,我们将进一步研究如何降低投影阶段的时间复杂度,如何把这种分段量化的思想应用到其它的哈希算法之中。


4 实验结果和分析
4.1 数据集
4.2 实验对比方法
4.3 评价指标
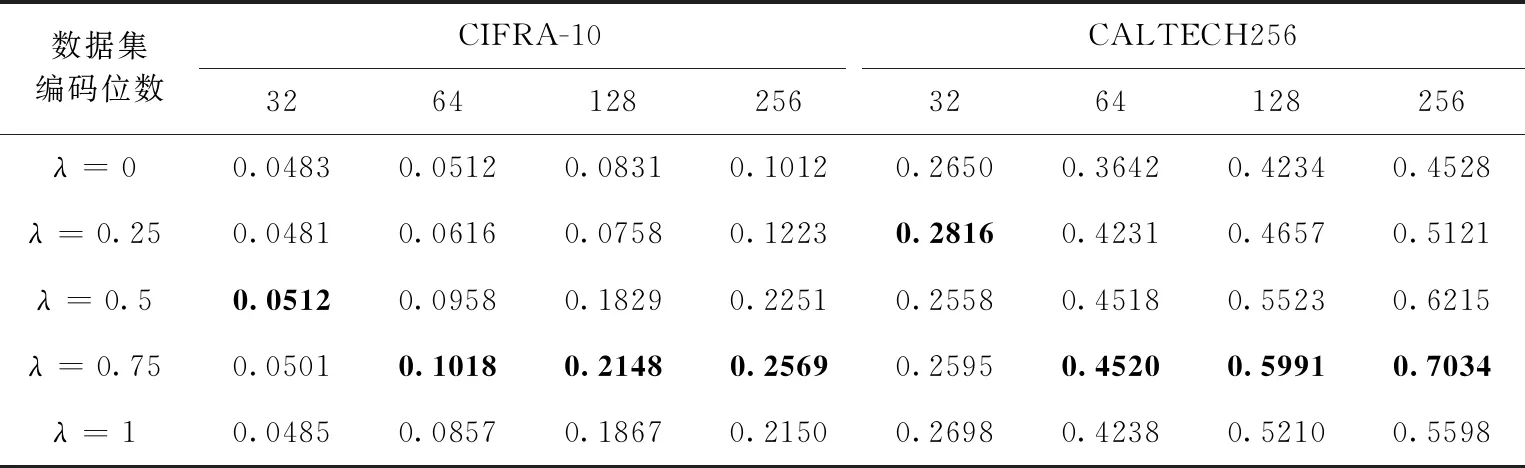
4.4 性能分析


5 结束语
