基于节点映射与标签数据构建的链接预测方法
2020-03-07周娅,杨邦
周 娅,杨 邦
(桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004)
0 引 言
网络链接预测主要是研究如何使用已知的网络信息对未知和缺失链接进行预测[1]。社会网络在近些年互联网的发展过程中也得到了巨大的发展,并已经成为各种信息传播和关系承载的重要媒介。凭借着这些规模日趋庞大的社会网络,人们构建更加广阔的链接关系成为可能,随之而来的是社会网络的日趋复杂和庞大。另一方面,当我们对复杂系统中的关系构建网络结构来近似模拟研究时,数据缺失或者链接信息不足等问题时有发生,而且对于关系网络,其中的关系链接往往又是动态变化的,具体说来就是,网络中某些暂时不存在的关系链接可能会出现[2]。因此,从网络拓扑结构中预测和发掘隐藏的链接就显得很有意义了。链接预测在很多研究和应用领域中都有重要应用,比如说生物网络中的疾病-基因网络、蛋白质-蛋白质相互作用网络[3],除了生物网络领域之外,在学术网络中用以推断论文的合作关系网络,在电子商务中用于对客户的商品推荐,在移动网络中预测移动网络用户是否有切换运营商的倾向。在犯罪监控网络中,可以利用链接预测方法来发现犯罪分子间隐藏的联系[4]。
对于网络链接预测问题,从使用方法的层面来说,主要有基于相似性计算的方法、基于统计学似然估计的方法以及基于概率模型的方法等。基于节点相似性计算的方法是通过对网络节点的某些维度的相似性进行计算,如果两个节点的相似度计算结果越大,那么它们之间链接存在的概率就越大。基于此种假设前提,发展出了不同的相似性计算指标。
基于统计学似然估计的方法一般是将网络的结构看作是具有某些层次结构或者是随机分块模型结构。所以此类方法主要分为两类:基于层次结构模型和基于随机分块模型。分层次模型在呈现层次结构的网络中能有较好的效果,但是这类方法每次计算都需要生成若干临时网络样本,这个过程会使模型复杂度大大增加,对于大规模的网络,这类方法的综合性能就不是很好了。而基于随机分块模型的链路预测方法能够较好的弥补这方面的缺点,其不仅可以预测缺失的链接,而且能够预测某些异常链接。例如在生物作用网络中纠正蛋白质相互作用关系之间的错误链接[4]。
基于概率模型的方法主要步骤是在特有的网络中构建一个带有多个待调优变参的数学模型,然后通过对原网络上节点之间的连接关系以及连接上的权重关系的表示方法进行转换并作采样处理,将节点上的网络信息转换成与节点为中心的特征值表示的形式,最后是不断迭代进行参数调整和模型优化,最终得到误差值允许范围内的最优参数解。网络中未知链接关系的存在性就可以通过计算节点对在当前最优参数模型中的条件概率[4]得到。
近年来,机器学习与深度学习技术也得到了迅猛的发展,也得到了广泛的应用,其中深度学习已经在包括计算机视觉、自然语言处理等领域取得了较大的成果[5]。在自然语言处理领域,基于神经网络方法的语义空间模型和文本分布式表达等模型得到了较为充分的研究。词语特征的分布式表达主要思想是将词语的语法或者语义特征映射到一个固定维度的连续向量空间,以此解决原有方法中存在的词语矩阵所包含的稀疏性问题以及计算的维数灾难[1]。
本文提出了基于节点特征构建的链接分类预测框架(classification method for link prediction based on node vector building,Net2Vec-CLP),下文记作Net2Vec-CLP。框架分为两个子部分,即Net2Vec部分和CLP部分。在Net2Vec子部分使用node2vec方法获得网络在低维度下关于节点的向量表达,在使用随机游走方法获得节点周围环境节点序列时,对于普通随机游走策略未考虑节点游走概率的情况,采用改进的具有重启机制的随机游走方式生成节点环境向量集合,在对node2vec超参的更新过程中,创新性地使用改进的牛顿下降法达到更快的收敛速度。此过程将输出节点向量。对于传统的直接对节点向量对计算相似度来评估链接存在性的方法做出改变,本文对获得的节点向量,根据原网络中存在链接边的节点对以及无链接的节点对构造带标签的组合向量元数据,全部的有链接节点对、无链接节点对构成新的带标签数据集,针对此新数据集设计使用采用了Sigmoid核函数的SVM的分类算法得到针对原网络的预测结果。
1 相关工作
在基于节点相似性的方法中,主要有基于局部信息相似性指标的共同邻居(CN)指标,Salton指标,Jaccard指标[1],TAES(time-aware actor-level evolution similarity)指标[6],LDAcosin指标[7],TBS(topology-based similarity)指标[8],Scop指标[9],LP-SSN指标[10],基于路径相似性的节点路径联合指标[11]方法(PNC)等。在基于节点相似性的方法集合中,还有一些使用随机游走理论的方法,比如SimRank指标,平均通勤时间(average commute time)指标[1]等。
在对有节点内容属性的网络链接预测方法中,张昱等[12]提出了一种方法,该方法为网络中不同类型的连边分配边权重,最后通过随机游走的方法进行网络链接的预测。
机器学习与深度学习思想的方法在网络链接预测问题中的应用,最早是Grover A等[13]提出Node2Vec算法,首先将所有节点初始化成指定特征数的向量化表示,通过对网络节点进行基于边连通的游走,生成节点环境节点集合,通过BP神经网络参数回退更新策略,通过参数学习和更新过程,同步完成节点向量表示的更新,直到游走序列结束和参数收敛,得到保留了网络性质的节点向量化表示。然后节点之间连边存在的概率值可以通过两节点之间的相似度来评估。
同时,基于网络表示学习的方法也被一些研究者运用到了链接预测工作中来,网络表示学习方法将原网络中的信息转换成以节点实体为中心的低维向量表示,以这种方式尽可能完整保留原网络的拓扑信息和属性信息。在获得网络的低维向量表示之后,使用机器学习以及统计分析的方法对向量数据集进行分析和预测[14,15]。
在数据分类方法的研究领域,SVM模型有了很多的应用,也达到了较好的效果。汪生等[16]提出了基于模糊SVM模型的入侵检测分类方法,能够较好地适用于入侵检测问题中的训练样本少的问题,提高了分类准确率。曲蕴慧等[17]提出了将SVM模型运用于工业中纸病检测分类的方法,有效解决了以前的方法中存在的实时性差、难以适应生产线在线检测要求等问题。SVM模型方法在数据分类,特别是二分类数据集上,有着运用范围广,准确率较高,可扩展性强,适用领域广泛等优势。
2 问题与符号定义
2.1 基础符号定义
本节会给出所涉及到的基本问题的定义(见表1),主要是模型涉及到的一些概念以及对应的简称表示。

表1 基础符号定义
2.2 节点N的周边环境节点Env(N)
与邻居节点不同的是,Env(N)不仅仅包含N的邻居节点,还有可能包含非直接相连的节点。另外,周边环境节点是通过随机游走产生的,所以在每一次的运算过程中,甚至是同一次运算的不同游走序列中,其结果都是动态变化的。
2.3 Windows(N)
环境窗口Windows(N)用于表示每一个待预测的节点的周边节点的个数。对于当前节点N,其Windows(N)数值大小就是Env(N)中节点数目。
2.4 节点结构特征表达嵌入矩阵M
节点结构特征表达嵌入矩阵M是由节点特征向量构成的矩阵,在Node2Vec框架体系中[14],一个重要概念就是节点结构特征向量,即网络的向量化,对于原网络,Node2Vec过程之后,转变成 |V|×m型矩阵数据,即我们此节所表述的M,而M中的行数据即为每个节点的特征向量表示。对于矩阵M的更新,会在算法开始之前的初始阶段进行随机初始化赋值,在映射层阶段对节点特征向量进行迭代更新,当训练数据运算完毕时,M矩阵中所有节点向量更新完毕。
2.5 节点Huffman树
在Net2Vec-CLP算法中,节点Huffman树是为了提升节点查找效率,降低算法的复杂度而做出的一个设计,其是按照节点度的大小为关键信息指标,构建Huffman树。此树基于这样一种假设:度较大的节点在游走数据集中更大概率出现,所以会涉及到更多次数的节点信息访问,正好可以结合Huffman树的特点进行网络节点重构存储。且此Huffman树的分支可以看作一个个分类器。原网络结构中的所有节点保存在Huffman树的叶子节点,所以此Huffman树存在 |V| 个叶子结点。在每次对网络节点的查找过程中,会经过若干个非叶子节点,每一个非叶节点都存在待学习更新的m维参数向量。
3 基于节点特征构建的链接分类预测模型(Net2Vec-CLP)
3.1 模型流程概述
如图1所示,Net2Vec-CLP框架主要分为映射层和学习层。本章后续内容会对整个流程作更详细的介绍。

图1 Net2Vec-CLP架构流程
3.2 映射层
3.2.1 映射层模型构造
此阶段主要是对网络进行节点向量化转换。首先是使用随机游走的方式对网络进行多轮采样,多轮随机采样之后获得网络关于节点集的序列化表示。此过程中需要仔细考虑的是对节点游走的策略合理性,较好的游走策略会对原网络信息有较好的覆盖性,能够较充分表达原网络的拓扑信息和属性信息。本文使用带重启机制的随机游走方法来实现序列化过程。重启机制应用于度为1的网络节点,在这种情况下,当前节点游走完毕后下一游走起始节点是从已有的序列中随机选择一个节点(非当前节点)作为重启后的新的游走起始节点,如图2所示。

图2 网络游走序列化示例
图2中MAX_LENGTH表示每个游走序列的最大长度,WALK_TIMES表示整个游走过程所需要的游走总次数。Windows(N) 根据经验值取为8,得到节点的Env(N)。则整个网络的游走过程的输出训练集为式(1)
Training set={(N,Env(N))},N∈V
(1)
然后,在游走产生节点N的周边环境节点之后,参数优化的最终目标函数为式(2)

(2)
式(2)表示模型的最终目标是通过对游走得到的Env训练集进行参数更新迭代运算,使得模型在某套参数解的条件下出现当前训练集的概率p取到最大。
图3表示了对节点的周边环境节点取样策略的示例。我们以节点A为例,示例中节点A的向量序列表示由 {H,D,B,H,G} 5个节点聚合运算结果来表示,本文采用线性求和聚合策略,此聚合操作输出Env(VA)。在对每个节点向量的处理过程中,借助构造的节点Huffman树进行快速查询。从根节点到每一个叶子节点会经历若干个分类节点。每一个分类节点相当于一个二分类器角色。分类节点上的决策激活函数采用Sigmoid函数。

图3 节点向量映射
我们使用VEnv(N)表示叶子节点N关于周围环境节点的向量表示,式(3)表示在节点Huffman树查找的过程中,此叶子节点被按照正常路径正确分类的联合概率
(3)
其中
(4)
所以需要优化的最终目标函数式(2)即为

(5)
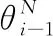
3.2.2 模型参数更新过程

(6)
为了方便阅读,记Φ(N,i) 为式(7)

(7)
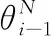
(8)
(9)
(10)

(11)
3.3 学习层
3.3.1 标签化数据集构建
映射层进行迭代更新,最终输出网络节点构特征矩阵M,已有的方案是直接对此节点向量矩阵进行相似度计算,并根据相似度值高低给出链接存在性预测结果。但是由于很多网络中节点相关信息比较少,可能简单到只有稀疏的度信息,简单进行相似度计算的方式难免会存在数据稀疏,数据分布不均,算法稳定性较差的问题。文献[1]采用余弦相似性指标计算节点间的相似程度。从原网络中的边集中选择部分边集,对每一条边的两个端点计算相似度,并与网络中随机的两没有链接关系的节点对之间的相似度进行比较,如果链接预测准确,则前者值大于后者。文献[16]是根据DeepWalk算法得到向量矩阵Φ,然后根据节点之间的转移概率矩阵计算得到节点的相似度矩阵。
本文对节点特征向量进一步进行处理,通过对节点特征向量进行标签化训练数据集构建,将两个节点向量对构成的新向量分为两个明确类别:链接存在和链接不存在。并在此基础上训练二分类模型,从而在划分的测试集上对链接存在与否进行计算验证。具体的构建策略如下:其中式(12),式(13)分别为节点a,b的特征向量。Eab表示a,b构成的边。
Va=(a1,a2,…,am)
(12)
Vb=(b1,b2,…,bm)
(13)
通过向量聚合方式,a,b构成的边向量表示为式(14)
(14)
其中,边向量的标签划分参考式(15)
(15)
选择数量为0.3*|E| 的无链接节点对作为分类标签为-1的数据。加上链接存在的数据,数据集总共有 (1+0.3)|E|条。
3.3.2 SVM二分类器设计
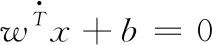
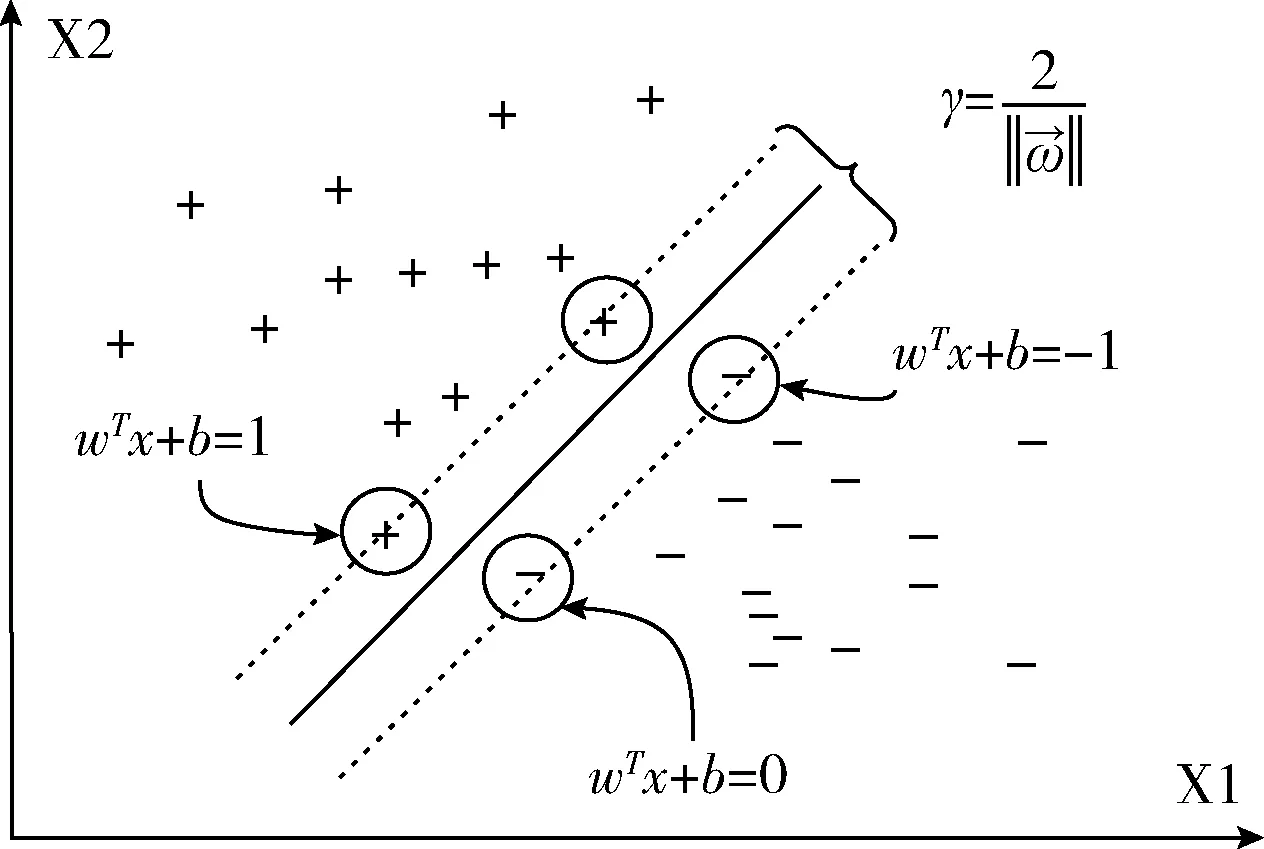
图4 SVM超平面与决策边界
除此之外,对于线性不可分的数据集,SVM方法引入核函数的概念,其具体操作是将原数据映射到更高维度以使得转换后的数据在新的维度能够线性可分。这个过程中的数据映射方法即前文提到的核函数概念,基于此,svm二分类优化问题可以表示为式(16)
(16)
式(16)所对应的拉格朗日对偶问题可表示为式(17)
(17)
(18)
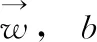
3.4 算法小结
Net2Vec-CLP框架主要流程主要分为3个子部分:第一部分是Net2Vec子过程,完成网络节点的向量化过程,输出网络节点特征向量表示矩阵;第二部分是标签化数据集构建;第三部分是对第二部分输出的标签化数据集,采用Sigmoid核作为映射函数的SVM模型训练过程。
4 实验与结果分析
4.1 实验数据集介绍
本文实验使用了4个公开的社会关系数据集,以下是相关数据集的简要介绍。
(1)Facebook社交网络,其中包含4039个节点和 88 234 条边。
(2)Email-Enron 电子邮件通信网络,其中包含36 692个节点和183 831条边。
(3)CA-HepTh科学家合作网络,其中包含9877个节点和51 971条边。
(4)Epinions 用户信任关系数据网络,其中包括 49 290 个顶点和487 182条边。这4个数据集的网络拓扑结构如表2所示。其中N表示节点数,E表示边数,

表2 各数据集拓扑结构特征
4.2 基准方法
(1)CN指标:如果NBx与NBy分别表示节点x与y的邻居节点,则基于CN指标的相似性可表示为Sx,y=|NBx∩NBy|。
(2)Node2Vec:主要还是网络结构向量化映射的思想,不过在随机游走序列生成过程时增加p,q两个超参来平衡随机游走的深度和广度。此方法在获得网络节点的向量化表示之后,借助余弦相似度指标来衡量节点之间相似度,并以此为判断链接存在性的根据。
(3)ACT指标:平均通勤时间相似度指标(average commute time,ACT)是基于这样一个理论假设:假设有一个随机粒子从节点x到达节点y平均要走的步数为m(x,y), 在此基础上,节点x与节点y的平均通勤时间定义为式(19)
n(x,y)=m(x,y)+m(y,x)
(19)

(20)
4.3 评价指标
算法的结果评估采用AUC(area under curve)和平均准确率(average precision,AP)两个常用指标。AP指标能够很好展现Precision-Recall曲线下面积,能较好反映算法整体性能。AUC方法能较好评估方法的准确程度,链接预测问题中的准确率定义为在网络中存在链接的节点对链接存在可能性高于不存在链接节点对的概率。假设进行了n次评估实验,其中有n′次结果存在链接节点对得分较高,其中n″次的结果中两类节点对得分相同。则AUC结果的计算公式如式(21)
(21)
4.4 实验结果
第一部分实验是AUC指标下的结果评估,此过程中还考察了数据集分类比例对算法以及基准方法的结果的影响,实验数据集总共进行了4种不同比例测试数据集的划分方案,分为10%,20%,30%,40%,每种方案运行50次,最终取值取多次结果的平均值。如图5的几组柱状图中可以观察到:本文提出的方法在测试集的比例为20%和30%时表现较优异,其中最突出的是在Facebook数据集和Email-Enron数据集上。在Epinions数据集上受测试数据集划分比例影响最小,只在测试数据为20%和30%比例的情况下与排名其后的Node2Vec方法有微小优势。同时还能够发现,当测试数据比例选取到40%时, Net2Vec-CLP方法甚至会低于其它基准方法。所以,Net2Vec-CLP方法的优势还应该受测试数据集划分比例这一参数的影响,当测试数据集划分比例为一个比较合理的数值时,能体现出结果优势。
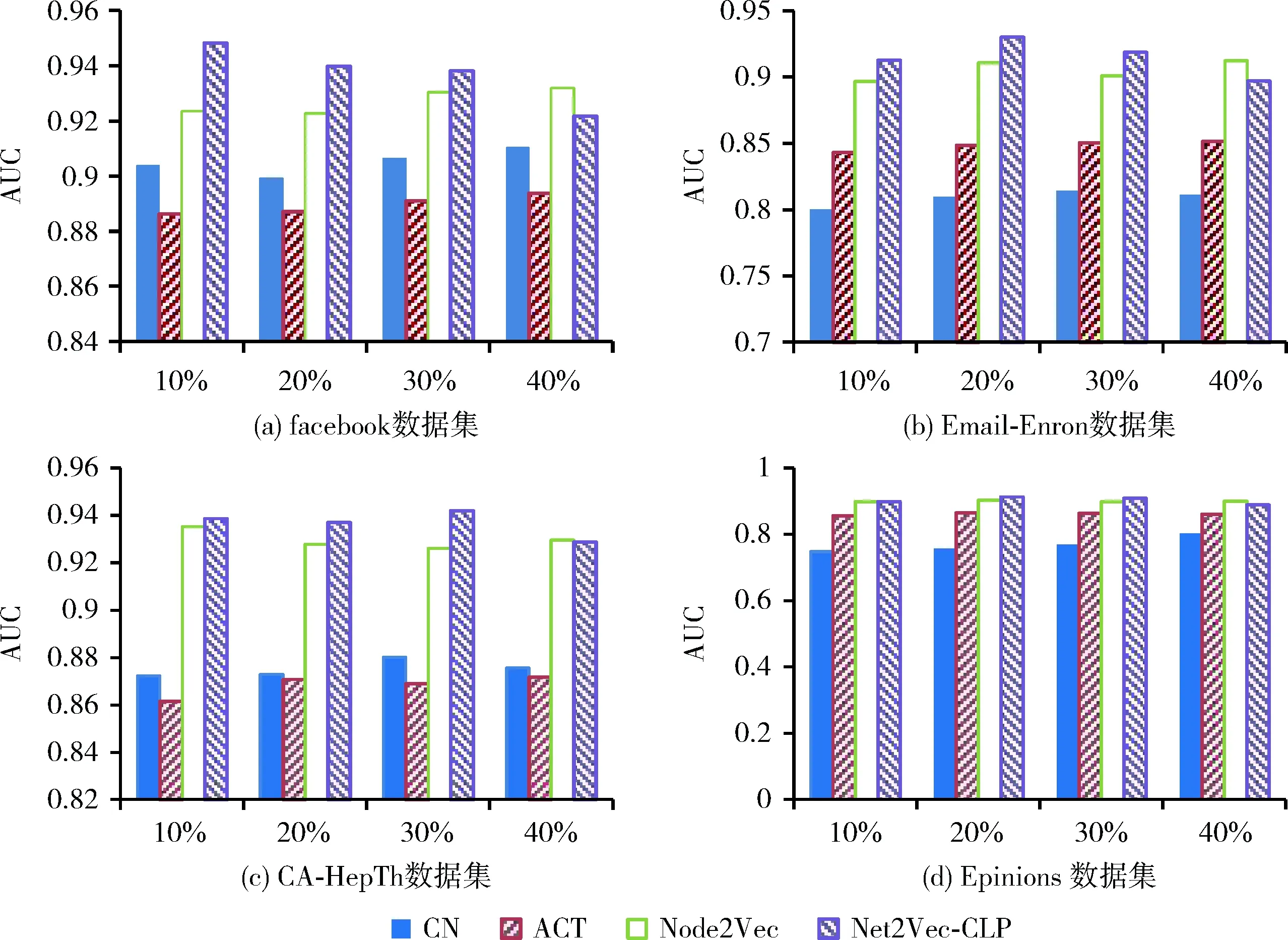
图5 不同数据集上AUC结果数据比较
同时,在分类方法角度考虑本文提出的Net2Vec-CLP方法,二分类的方法能够双向又全面的对能对数据集中有链接节点对、无链接节点对进行分类预测,相对于相似度计算的方式,其能从反向将无链接节点对与任选存在的链接进行比较计算,因为按照网络模型规律,所有存在链接节点之间的相似度都要尽量大于无链接节点对之间相似度,模型才会比较准确。
第二大部分实验是基于AP指标的结果评估,这个阶段我们的测试数据集选取为30%。具体结果见表3。

表3 AP结果记录
Net2Vec-CLP在所有测试数据集上都有较好表现,其中表现最明显的是在Facebook数据集上,测试结果高出了Node2Vec方法3.35个百分点。但是在Epinions数据集上的结果低于Node2Vec方法。这种情况可能是因为Epinions数据集的节点的网络聚集程度较低,从而在随机序列生成过程中要依赖更多的重启机制获取新的游走起点,最终向量构造的过程中体现出的便是这些随机重启的信息,而并非原网络的网络信息,从而在分类训练阶段中的超参会出现过拟合的问题。对于这类问题,可以在进一步的后续研究中做专门的改进和研究。
5 结束语
本文在网络节点序列化表示思想的基础之上,提出Net2Vec-CLP方法,在向量化过程中采用增强的牛顿下降法更新参数,提升了参数的收敛速度,同时通过辅助函数f1(X)=ep(X-Xn)f(X) 解决在更新过程中梯度为0的问题。映射过程将输出网络节点的向量表示,然后将网络链接构造成标签化的分类训练数据集,运用以Sigmoid为核的SVM算法对标签数据集进行分类。在几个数据集上运行测试的结果表明,框架在几个数据集上,AUC指标和AP指标都能达到很好的效果。较以前对节点计算相似度的方法,此框架能够对原网络中无链接节点对有均衡,准确的度量。
下一步工作将会在本文工作的基础上扩展对有向社会网络数据预测问题的支持,针对有向网络中链接的有方向性特点,从节点游走策略,标签化数据集构建规则等方面为出发点来开展下一步研究工作。
