基于多维度和多模态信息的视频描述方法
2020-03-05丁恩杰刘忠育刘亚峰郁万里
丁恩杰,刘忠育,刘亚峰,郁万里
(1.中国矿业大学物联网(感知矿山)研究中心,江苏 徐州 221008;2.不来德大学电动学与微电子研究所,不来德 28359)
1 引言
随着大数据、计算机算力、机器学习模型不断发展,视频描述技术再度掀起研究热潮。视频描述有着十分广泛的应用,如视频检索、视频标注、行为识别、人机交互、视频内容讲解等场景[1-2]。然而该任务相对复杂,涉及计算机视觉理解和自然语言处理2 个领域,本质上属于跨模态的映射问题,现有的方法还有较大的提升空间[3]。
视频描述主要分2 类。一类是抽象概括一段视频的主要内容,该类任务的输入通常是一个视频片段,而输出则是一句或若干句自然语言[4]。另一类则是视频内容的密集描述,通常需要将视频片段中的人、物、场景状态及其相互关系和变化过程描述清楚[5-6]。本文所提方法主要解决第一类问题。
传统的视频描述方法是基于模板的方法[7-10],如主语-动词-宾语三元组(SVO,subject-verb-object)[9]和主语-动词-宾语-地点(SOVP,subject-verb-object-place)[10]等。这类方法通常预先设定产生句子的词法和语法规则,并且预先定义主语、谓语和宾语等要素的视觉类别,当检测到相应的视觉目标时,将视觉语义映射到模板中。显然,该方法总能够根据视觉要素在预定义的模板中直接生成语法正确的描述,不足之处在于该类方法高度依赖预定义的语言模板,生成语句受到预定义的视觉类别和语法结构的限制,句子描述的形式和内容缺乏灵活性和多样性。另一类方法是基于深度学习的方法。鉴于循环神经网络(RNN,recurrent neural network)在自然语言翻译中的惊人表现[11],相关学者逐渐开始使用此类方法生成视频的语言描述。文献[12]首先用卷积神经网络(CNN,convolutional neural network)提取视频中的图像特征,然后用RNN 类的方法对图像特征进行编码,最后解码生成视频内容的自然语言描述。然而,该方法提取的视觉特征较单一,对视频内容的语言描述不够丰富[13]。文献[14]提出递归编码器并结合注意力模型,使用在Imagenet 上预训练的深度卷积神经网络提取视频关键帧的视觉特征,然后按照时序输入长短期记忆网络(LSTM,long and short term memory network)[15]进行编码。文献[16]提出基于多模态融合的视频描述方法,提取视频中动态特征和静态视觉特征,并融合音频特征产生语言描述。然而对于视频中单帧图像而言,没有充分考虑场景中的背景和语义信息。文献[17]提出一种提取视频关键帧的方法来提升描述语言的准确度,然而该方法同样没有考虑视频的物体、背景和时空等多维度信息。此类方法使用预训练的CNN 提取目标视频的特征,本质上是采用迁移学习对目标视频的视觉特征进行提取。然而,迁移学习要求选取的源域和目标域特征分布越接近越好[18],但由于描述视频内容的多样性和随机性,目标域的特征很难和某个图像数据集特征分布完全相同,因此该问题是此类方法的主要瓶颈之一。
为解决上述瓶颈问题,本文采用迁移学习,从视频包含的物体、背景和时空动态关系等多个维度提取视频中静态、动态和语义信息,并采用LSTM处理多维度和多模态信息完成编解码,最终生成视频的语言描述。根据以上分析,本文的主要贡献如下。
1)提出采用多个源域预训练的模型提取视频中的静态、动态和语义信息,以提升视频语言描述的准确度。
2)提出一种多模态信息融合方法,将视频的关键帧进行语言描述,并将视觉模态信息和语言模态信息融合,从而进一步提升模型生成语言的多样性。
3)在微软视频描述(MSVD,microsoft video description)[19]和微软视频到文本研究(MSR-VTT,microsoft research-video to text)[20]公共数据集上进行模型验证,并采用多种评价指标对产生的语言进行评价,结果显示所提方法取得了良好的效果。
2 改进的视频描述方法
本文提出的视频描述方法分为编码和解码2 个阶段,如图1 所示。在编码阶段,首先对输入视频预处理,获取包含静态特征的图像和动态特征的视频片段2 种模态。然后分别用二维卷积神经网络(2DCNN,two dimensional convolutional neural network)和三维卷积神经网络(3DCNN,three dimensional convolutional neural network)对图像模态和视频模态进行特征提取。近几年,人们对单幅图像的语言描述取得了较大进展,且视频关键帧的语义信息对整个视频的描述有较大帮助。本文采用文献[21]中的方法提取关键帧中的语义信息,然后用多层LSTM 对获取的语义信息和视觉信息进行编码,并将各层LSTM 的隐藏层状态作为解码阶段的输入,最终生成视频的语言描述。
2.1 视觉信息提取
视频中存在大量的物体、场景及时空关系等多维度信息,提取并融合这些信息对视频的准确描述至关重要,本文采用迁移学习的方法提取目标视频的视觉特征。为解决源域和目标域特征分布不一致的问题,本文采用在多个源域预训练好的模型提取目标域的特征。具体而言,对于所要描述视频中的物体和场景特征提取,采用在数据集Imagenet[22]和Place365[23]上预训练的2DCNN 模型。Imagenet数据集用于图像分类任务的模型训练和检测,包含约1 400 万张图像,共1 000 个物体类别。Palce365数据集用于场景识别,包含约1 000 万张场景图片,共365 个场景类别。对于视频中时空动态特征的提取,采用在行为识别Kinetics[24]数据集上预训练的3DCNN 模型。本文采用的Kinetics 数据集包含约50 万个视频片段,平均视频长度约为10 s。
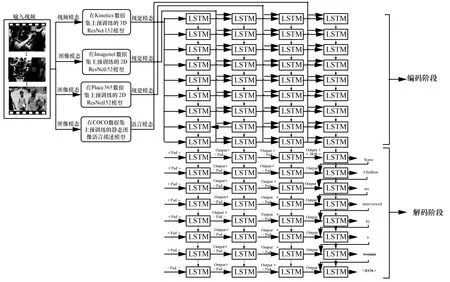
图1 模型原理
对于2DCNN 和3DCNN 模型,均使用152 层的残差网络(ResNet,residual network)[25]。ResNet因其网络深度、残差块以及在图像分类问题上的优异表现而成为经典的CNN。该网络引入残差块解决了梯度消失问题。152 层的二维残差网络(2DResNet152,two dimensional ResNet152)和152层的三维残差网络(3DResNet152,three dimensional ResNet152)分别采用二维和三维的卷积核,并且以残差块为其基本单元。残差块如图2 所示。其中图2(a)表示2DResNet152 的卷积块,其卷积核大小分别为1×1 和3×3,F表示卷积核的数量,BN 表示批量标准化(BN,batch normalization)[26],ReLU表示激活函数。图2(b)表示3DResNet152 的残差块,其卷积核大小分别为1×1×1 和3×3×3。
2.2 语义信息提取
视频是由多帧静态图像按时序构成的,因此提取视频中的关键帧并对其内容进行描述有助于理解整个视频的内容。本文采用在微软通用目标检测(COCO,microsoft common object in context)[27]数据集上预训练的静态图像描述模型,对视频的关键帧进行描述。视频中往往包含大量的冗余信息,因而只需抽取视频中若干关键帧进行描述。由于视频内容大多是缓慢变化的,因此采用固定时间间隔的方法来提取5 个关键帧作为图像描述方法的输入,而输出为图像的语言描述。然后将描述语句中的单词表示为512 维度的向量,将2 个单词拼接成1 024 维度,最后将拼接后的词向量与视觉特征向量进行融合。视觉语义特征提取单元原理如图3 所示。

图2 二维和三维ResNet152 网络的残差块

图3 视觉语义特征提取单元原理
2.3 特征融合模型
如图1 所示,第一层LSTM 主要对动态信息建模,将3DCNN输出的特征向量按照时序作为LSTM的输入。将第一层LSTM 的输出与场景特征向量拼接后作为第二层LSTM 单元的输入。同理,由第三层和第四层LSTM完成物体信息和语义信息的特征融合建模。将视频按照时序每 16 帧一组作为3DCNN 的输入,取平均池化后的输出作为动态信息的特征向量。由于视频的长度不一,3DCNN 产生的视频动态特征向量个数不同。本文取50 个该特征向量,对于超过50 个的则将多余的部分舍去;对于不足50 个特征向量的,不足部分用维度相同的零向量代替。对于场景特征向量和物体特征向量均取50 个。而对于语义信息,将视频等间隔切分,取其中5 帧生成静态图的语言描述。
本文的视频描述模型以LSTM为基础网络进行编码,LSTM 可以有效地提取时序特征,LSTM 原理如图4 所示。假设在时刻t,输入的特征向量为xt,对应输入的隐藏层特征为ht-1,记忆单元的特征为ct,则任意时刻LSTM 单元的计算式为
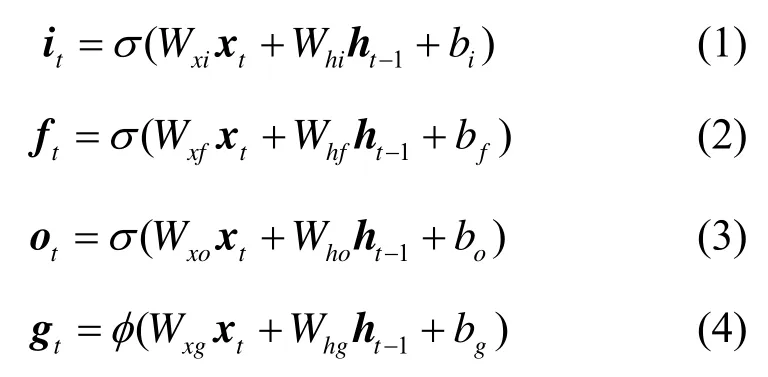
其中,it、ft、ot、gt分别为LSTM 的输入门、遗忘门、输出门、输入调制门,W和b为需要优化的参数。
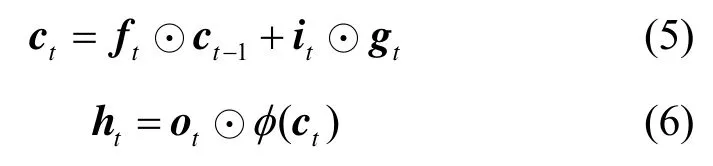
其中,σ为sigmoid 函数,φ为tanh 函数,⊙为哈达玛积运算,即向量的对应元素相乘。σ φ和 的计算式分别为
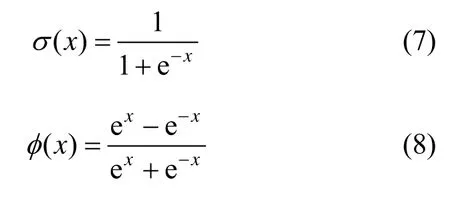
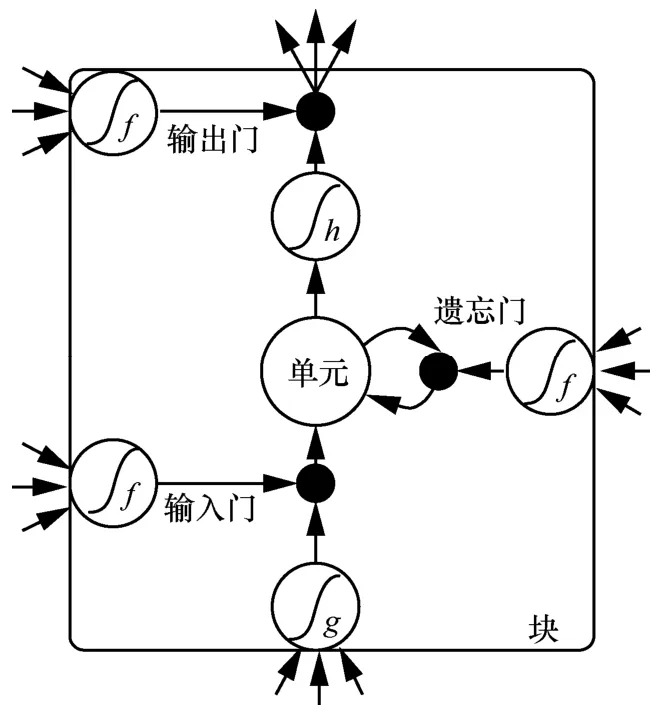
图4 LSTM 单元原理
在编码阶段,连续选取视频的 16 帧作为3DResNet152 的输入,经过网络计算得到平均池化输出的2 048 维向量。等间隔地选取视频的50 帧分别作为2DResNet152 在Imagenet 和Place365 预训练模型的输入,选取2DResNet152 网络的平均池化输出的2 048 维向量作为输出,获取场景描述向量和物体描述向量。等时间间隔地选取视频中的5 帧作为在COCO 数据集上的静态图像描述模型的输入,输出为5 句语言描述,采用词嵌入方法将每一个单词编码成512 维的向量,2 个向量拼接到一起组成一个1 024 维的向量st∈S(s1,s2,s3,…,st,…,sn)。其中LSTM 单元的隐藏层状态表示为H(h1,h2,h3,…,ht,…,hn),hn+t-1表示LSTM 某一时间步的隐藏层状态。模型产生的句子描述为Y(y1,y2,y3,…,yt,…,ym)。Y关于Xd、Xs、Xg和S的条件概率分布可表示为
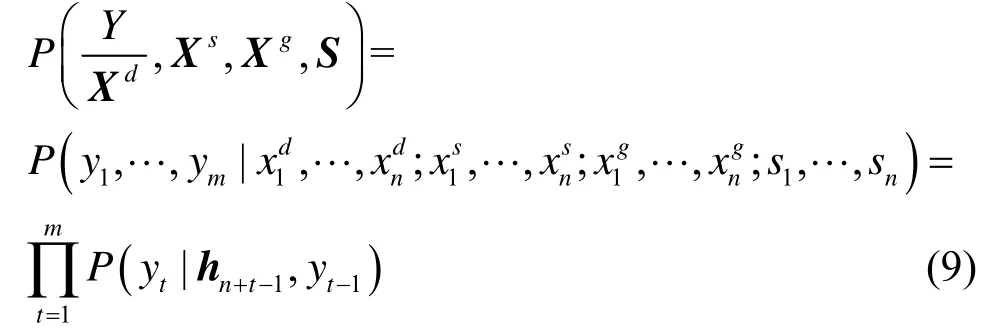
其中,条件概率分布P(yt|hn+t)是整个词汇集在softmax 层对应的输出概率。对于给定的帧序列F,获取的Xd、Xs、Xg和S特征描述向量使最大的词序列Y即为预测的句子。本文模型采用
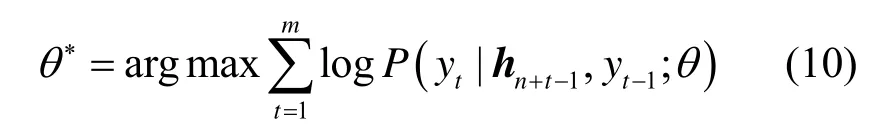
3 实验结果与分析
3.1 视频描述数据集
模型验证采用常用的MSVD 和MSR-VTT 这2个公共数据集。MSVD 是由微软研究院于2010 年公开的公共数据集,该数据集由1 970 个视频片段构成,平均每个视频片段包含40 个人工标注语句。MSR-VTT是由微软于2016年公开的一个用于测试视频描述模型的公共数据集。该数据集由10 000 个视频片段构成,平均每个视频片段包含20 个人工标注语句。模型训练均采用上述数据集中的英文标注语句。
3.2 评估指标
对模型结果的评价采用 METEOR、BLEU(bilingual evaluation understudy)、ROUGE-L 和CIDEr 共4 种指标。
METEOR 指标基于wordnet 同义词库,预先给定一组校准Z,通过最小化对应语句中连续有序的块C来得出,计算式为

其中,α、γ和φ均为用于评价的默认参数,hk(ci)、hk(sij)分别是一个N元模子(n-gram)出现在候选句子ci和标注句子sij中的次数;METEOR 标准基于单精度的加权调和平均数和单字召回率,其结果和人工判断的结果有较高的相关性。
BLEU是由IBM提出的一种常用的机器翻译评测方法,BLEU 定义n元词的个数来度量生成结果和目标语句之间的语义相似度。因此该方法首先统计候选语句和参考语句中n元词的个数,然后相除即为精确率结果。实验采用BLUE-4 评测方法,其中4 为n元词中n的个数。计算式为
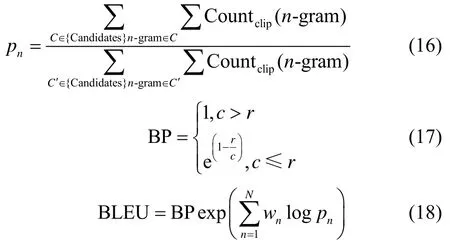
其中,BP 为惩罚因子,pn为计算所预测的n-gram的精确率,N为元组个数。
ROUGE-L 相比于BLEU,不需要预先指定n-gram 的值,因为其考虑的是单词的顺序性,更能评价句子层级的意义。但ROUGE-L 只考虑了一个最长子序列,其他序列不能对其产生影响。ROUGE-L 的评价计算式为
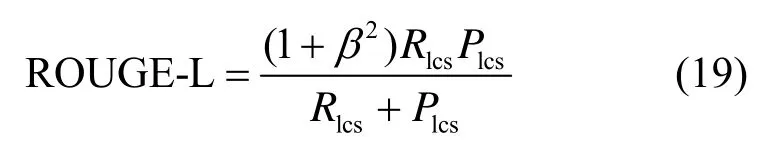
CIDEr 是Vedantam 等[28]于2015 年提出的专门用于图像或视频描述的一种评价指标,旨在度量待评价语句和真实语句间的匹配程度。其主要原理是,将待评价与真实语句表示成词频和逆向词频(TF-IDF,term frequency-inverse document frequency)的向量形式,然后求其余弦相似度来对句子进行打分。
3.3 实验过程
在UltraLab 图形工作站上进行方法验证,采用Pytorch 深度学习架构。工作站配备24 核的Intel Xeon Gold 6146 CPU和8块英伟达公司的GTX2080图形处理器,工作站的内存大小为200 GB。将数据集MSVD 和MSR-VTT 均划分为训练集、验证集和测试集。其中MSVD 训练集为1 300 个视频片段,验证集为200 个视频片段,测试集为470 个测试片段;MSR-VTT 的训练集为6 513 个视频片段,验证集为609 个视频片段,测试集为2 878 个视频片段。
首先,构建用于描述视频内容的字典,分别统计MSVD 和MSR-VTT 数据集语料库中的单词频率。去除语料库中的生僻字和标点符号,保留单词频率大于或等于5 的单词,对于不可识别的符号用
训练模型的批量处理和学习率分别设定为128和0.001。模型生成句子的最大长度设定为28 个单词,目标函数采用负对数似然损失函数,用于度量人工标注句子和模型生成句子之间的距离。采用Pytorch架构中的Adam优化器对模型的参数进行优化,训练的epoch 设定为40。测试时对模型生成的句子用3.2 节所述的方法进行评估。评估的参考句子为目标视频的人工标注语句,计算结果取其中最大值。
3.4 结果分析
实验结果如表1 所示。由表1 中结果可知,本文方法在MSVD 和MSR-VTT 这2 个公共数据集上的得分最高。这是因为本文方法融合了多维度信息,在Kinetics 上预训练的3DResNet152 网络可以有效提取数据的动态信息,在Imagenet 物体分类数据集上预训练的2DResNet152网络可以有效提取视频中的视觉场景中的背景和目标信息,在Place365场景识别数据集上预训练的2DResNet152网络可以有效提取视频的场景信息。除了上述3 种视觉信息,本文方法还针对视频中的关键帧来提取语义信息,获取的语义信息本质是在COCO 数据集上预训练的静态图像语言描述迁移到视频的语言描述,然后将这些丰富的视觉和语义2 种模态信息通过有效方法融合,进而获得更加准确的视频描述。
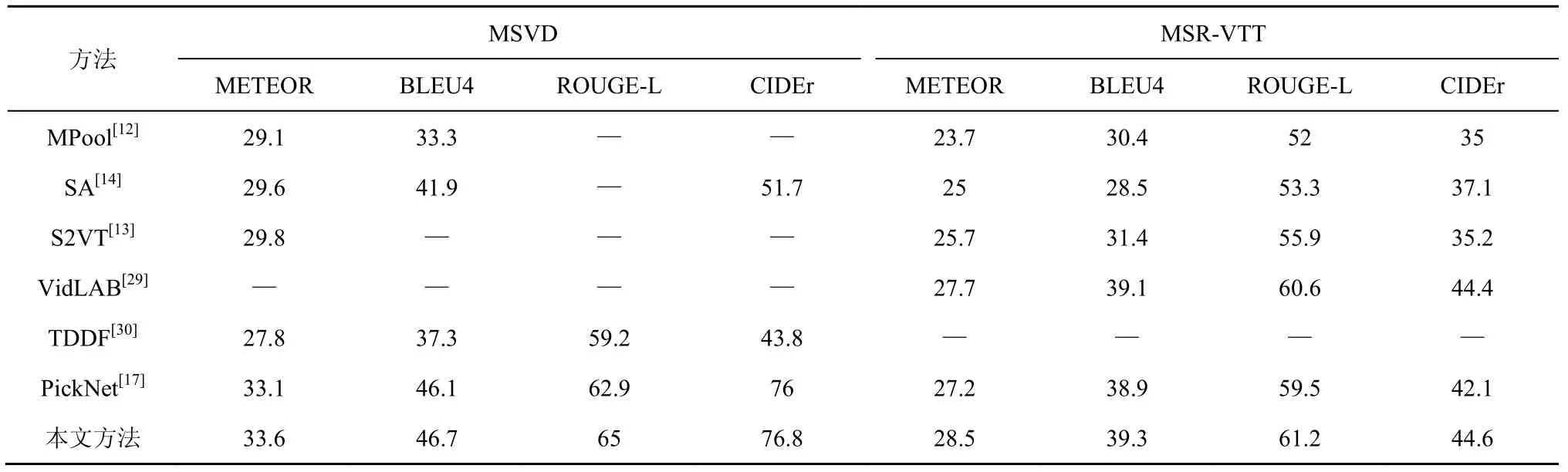
表1 MSVD 和MSR-VTT 的测试集在BLEU4、METEOR、ROUGE-L、CIDEr 上的测试结果
视频描述的目标是生成更加符合人类语言习惯的语言描述,所提模型对MSVD 和MSR-VTT 数据集的视频描述实例如表2 所示,展示了部分视频的原手工标注语句和模型自动生成的语句。由表2可知,与视频片段的原人工描述相比,模型自动生成的描述语句包含的语言要素更加丰富。一方面由于模型获得的特征更加多样化,使其能够适应内容多种多样的视频片段;另一方面是人工标注的语言会受到人们自身知识、兴趣和语言能力的限制,所以所提模型产生了效果较好的描述。
4 结束语
为解决视频的多维度信息的表示和提取,提高语言描述的质量,采用多种视觉任务预训练模型有效地提取视频中丰富的静态和动态视觉信息,并结合视频关键帧的语义信息,构建模型融合多维度和多模态信息,进而生成整个视频的语言描述。3DResNet152 深度卷积神经网络具有良好的时空特征表示的特点,可以提取目标视频的动态信息;而在Imagenet 和Palce365 公共数据集上预训练的2DResNet152 深度卷积神经网络,可以对场景中的背景和物体等静态信息进行特征表示。多维度的动态信息和静态信息形成互补,为视频的语言描述提供丰富的视觉特征。此外,采用在COCO 数据集预训练的静态图像语言生成模型对视频的关键帧进行语言描述,可为视频语言描述提供较丰富的语义信息。用多层LSTM 模型将获得的多维度视觉和语义2 种模态信息进行融合,生成较高质量的视频语言描述。通过在MSVD 和MSR-VTT 这2 个数据集上实验验证,所提方法在常用的METEOR、BLEU、ROUGE-L 和CIDEr 评价指标上均获得了良好的效果。

表2 MSVD 和MSR-VTT 数据集的视频描述实例
在今后的研究中,将继续探索多维度和多模态信息的特征表示和融合方法,并且将探讨注意力机制,让模型能够聚焦更加有用的信息,进一步提升视频描述的质量。
