一种基于复合特征的恶意PDF检测方法
2020-03-04李国黄永健王静徐俊洁王鹏
李国 黄永健 王静 徐俊洁 王鹏
摘 要: 为了提高特征有效性和扩大检测范围,提出在提取PDF文件的恶意结构特征的基础上再提取JavaScript的恶意特征;为了减少检测时间,提出在特征提取前,增加基于信息熵差异的预检测过程。先利用恶意PDF和良性PDF的信息熵差异筛选出可疑PDF文件和良性PDF文件;然后在检测过程中,提取可疑PDF文件的结构和JavaScript特征;再利用C5.0决策树算法进行分类;最后,通过实验检测,验证了提出的方法对恶意PDF文件检测有效。实验结果表明,与PJScan,PDFMS等模型做对比,该方法检测率比PJScan高27.79%,时间消耗低390 s,误检率比PDFMS低0.7%,时间消耗低473 s,综合性能更优。
关键词: 恶意PDF文档; 文档检测; 文件筛选; 文件特征提取; 信息熵预检; 实验验证
中图分类号: TN911.23?34; TP393 文献标识码: A 文章编号: 1004?373X(2020)02?0045?04
Method of malicious PDF detection based on composite features
LI Guo1, HUANG Yongjian1, WANG Jing1, XU Junjie1, WANG Peng2
Abstract: A method that the JavaScript malicious features are extracted on the basis of extracting the malicious structural features of PDF files is proposed, so as to improve the feature validity and expand the scope of detection. A scheme that the pre?detecting process based on the information entropy difference is added before the feature extraction is proposed to shorten the detection time. The information entropy difference between malicious PDF and benign PDF is utilized to screen out the suspicious PDF files and benign PDF files in pre?detection process. The structures and JavaScript features of the suspicious PDF files are extracted during the detection process, and the C5.0 decision tree algorithm is adopted to classify them. The experimental results verify that the proposed method is effective for detecting malicious PDF files; in comparison with the PJScan, PDFMS and other detection models, the proposed method′s detection rate is 27.79% higher and the time consumption is 390 s lower than the PJScan, and the proposed method′s error detection rate is 0.7% lower and the time consumption is 473 s lower than PDFMS; its comprehensive performance is more superior.
Keywords: malicious PDF file; file detection; file screening; file feature extraction; information entropy predetection; experimental verification
0 引 言
近年来,对商业组织和政府机构的高级持续性威胁 (APT)攻击时有发生,而恶意PDF文件是APT攻击的重要载体[1]。目前大部分杀毒软件采用基于启发式或字符串匹配的方法进行查杀,但这些方法无法有效处理多态攻击的问题[2]。在解决该问题时,最近的研究主要集中在以下三個方面:
1) 先提取PDF文件中的JavaScript特征,再经过机器学习进行分类。这类方法可应对基于恶意JavaScript的攻击,但易受到代码混淆的影响。如2011年,Laskov开发的经典工具PJScan存在检测率低,无法分析混淆代码的问题[3]。2014年,Doina Cosovan等人提出的基于隐马尔可夫模型和线性分类器检测恶意PDF文件的方法,存在误报率高的问题[4]。2017年,徐建平提出的改进N?gram的检测模型只针对三种代码混淆技术进行反混淆[5]。
2) 利用 PDF文件的结构信息来检测恶意 PDF文件,其特点是不分析其携带的攻击代码,能够检测到非JavaScript攻击,并且不会受代码混淆的影响,但是如何增强模型的健壮性是其所面临的大挑战。如2012年,Maiorka等人设计的经典工具PDFMS存在一些结构性弱点[6]。2015年,Davide Maiorca等人从PDF文件的结构和内容中提取信息的方法存在对样本数据的质量要求较高的问题[7]。
由于大多数的恶意PDF文件的大小比良性PDF文件小,而且恶意PDF文件的间接对象数量比良性PDF文件少,因此,除了上述所提的标识JavaScript,Actions,Triggers和Form Action关键字的7种动态结构特征以外,所提取的结构特征集还包括两种结构的一般特征:文件的大小和间接对象的数量。
2.2.2 JavaScript代码分析
在这个阶段,分析PDF文件结构部分的JavaScript代码和文件中嵌入的JavaScript代码,并提取JavaScript代码中经常出现的恶意特征。基于以前的研究,本文方法所提取的JavaScript特征共有9种,分别是:
1) 用于混淆代码的字段(5种):substring,document.Write,document.create Element,fromCharCode和stringcount。其中,恶意攻击者可以利用fromChar 将Unicode值转换为字符,利用stringcount分解字符串。
2) 用于动态解释恶意Javascript的字段(4种):Eval,setTime Out,eval_length和max_string。其中,恶意攻击者可以使setTime Out代替eval,在超时后运行随机的JavaScript代码。
2.3 分 类
为了对PDF文件进行分类,可以使用任何学习算法创建的分类器。本文选取C5.0决策树作为分类算法,PDF文件样本集合S={S1,S2,…,Sn}(n为样本总数),共分为两类C={C1,C2}(C1代表良性PDF文件;C2代表恶意PDF文件)。每个PDF文件将由一个向量表示,该向量由结构的一般特征、结构的动态特征和JavaScript特征组成,即:
Si={T1,T2,T3,T4,T5,T6,T7,T8,T9,T10,T11,T12,T13,T14,
T15,T16,T17,T18 }, i=1,2,…,n
其中:
1) 结构的一般特征:T1表示文件Si的大小,以字节为单位;T2表示文件Si的间接对象的数量。
2) 结构的动态特征:T3~T9分别表示文件Si中以“/JS”为标识的JavaScript关键字的数量、以“/JavaScript”为标识的JavaScript关键字的数量、以“/Go To”为标识的Action关键字的数量、以“/Go To R”为标识的Action关键字的数量、以“ /Go To Z”为标识的Action关键字的数量、以“/open action”为标识Triggers关键字的数量、以“/Submit Form”为标识的Form Action关键字的数量。
3) JavaScript特征:T10~T16分别表示文件Si中substring,fromChar Code,stringcount,document.Write,document. create Element,Eval,setTime Out出现的次数;T17表示文件Si中传给eval的最长字符串长度eval_length;T18表示文件Si中最长字符串的长度max_string。
定义p(Ci,S)表示样本属于类别Ci(i=1,2)的概率,则样本集合S的信息熵Info(S)计算公式为:
[Info(S)=-i=12(p(Ci,S) )·log2(p(Ci,S))] (3)
[p (Ci,S)]的計算公式如下:
[p(Ci,S)=fre(Ci,S)n] (4)
式中:n为样本总数;[fre(Ci,S)]是样本集合中,类别是Ci的样本个数。
样本的特征属性为T,每个属性变量有N类,属性T的条件熵Info(T)的计算公式为:
[Info(T)=-i=1N((Ti|T|)·Info(Ti))] (5)
引入特征属性变量T后的信息增益Gain(T)的计算公式为:
[Gain(T)=Info(S)-Info(T)] (6)
C5.0算法利用信息增益率Gainration(A)来生成节点,其中A为假设情况,Gainration(A)的计算公式为:
[Gainration(A)=Gain(A)Info(A)] (7)
式中,Gain(A)表示A情况下所生成的节点产生的信息增益,子节点越多,Info(A)越大。
3 实验结果与分析
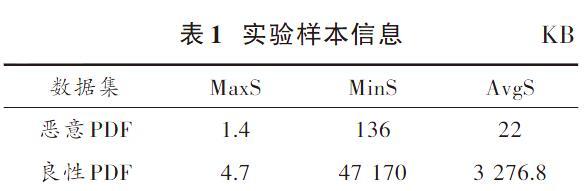
实验所采用的数据集是由从Contagiodump[11]中收集的11 207个恶意文件和从工作实验室中收集的9 745个良性文件组成,样本信息包括样本最大值MaxS,样本最小值MinS,样本平均值AvgS,如表1所示。
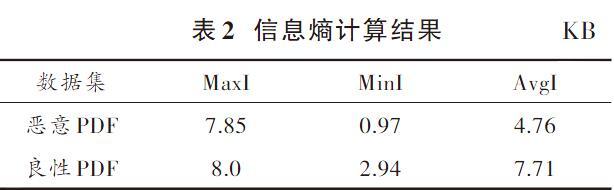
通过实验,样本的信息熵计算结果如表2所示,包括样信息熵最大值MaxI,信息熵最小值MinI,信息熵平均值AvgS。
根据表1和表2可以看出,恶意PDF文件的大小和信息熵明显比良性PDF文件小。
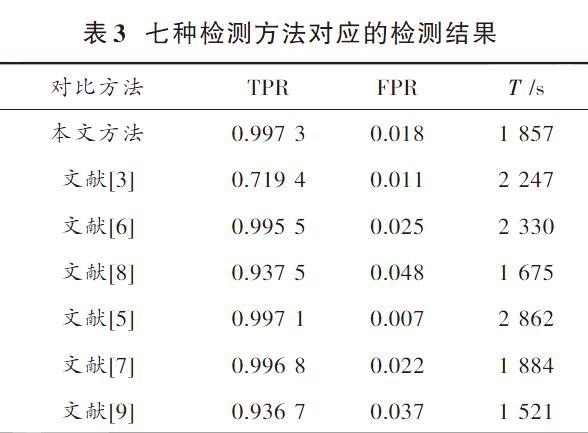
正式检测通过10折交叉验证重复10次,当α值取7.74时,准确率达到99.73%,误检率达到1.8%,时间消耗降至1 857 s。与文献[3,5]提出的基于JavaScript特征的检测方法、文献[6,7]提出的基于结构特征的检测方法和文献[8?9]提出的直接对整个PDF 文件进行分析的检测方法相比,结果如表3所示。
对于每种方法,都显示了检测率(TPR)、误检率(FPR)和时间开销T。从三类检测方案的七种方法的检测率、误检率和时间消耗的对比结果中可以看出:本文提出的方法检测率高于其他文献提出的方法,与误检率最低且检测率第二高的文献[5]相比,其检测时间为2 862 s,比本文提出的方法多1 005 s;与检测时间最少的文献[9]提出的方法相比,其检测率为93.67%,误检率为3.7%,比本文提出的方法的检测率低6.06%,误检率高1.9%;与文献[3]提出的PJScan和文献[6]提出的PDFMS相比,本文提出的方法检测率比PJScan高27.79%,时间消耗低390 s,误检率比PDFMS低0.7%,时间消耗低473 s,因此,本文提出的方法综合性能更好。
4 结 语
针对恶意PDF文件检测率低和检测时间长的问题,本文提出基于信息熵下结合结构特征和JavaScript特征进行恶意判别的方法。经过基于熵的预检测过程,确定可疑PDF,然后提取可疑PDF文件的恶意结构特征和JavaScript特征,最后利用C5.0决策树算法进行分类。通过实验结果表明,本文提出的方法在检测率和检测时间性能上更优。但是在预检测过程中,α值是通过实验确定的,而非经验值确定,因此在今后的研究中,应该实现阈值动态设置和范围调整算法以减少检测的时间。
参考文献
[1] 文伟平,王永剑,孟正.PDF文件漏洞检测[J].清华大学学报(自然科学版),2017,57(1):33?38.
[2] 林杨东,杜学绘,孙奕.恶意PDF文档检测技术研究进展[J].计算机应用研究,2018,35(8):1?7.
[3] LASKOV P. Static detection of malicious JavaScript?bearing PDF documents [C]// Twenty?Seventh Computer Security Applications Conference, ACSAC 2011.Orlando: DBLP, 2011: 373?382.
[4] COSOVAN D, BENCHEA R, GAVRILUT D. A practical guide for detecting the java script?based malware using hidden Markov models and linear classifiers [C]// International Symposium on Symbolic and Numeric Algorithms for Scientific Computing. Timisoara: IEEE, 2015: 236?243.
[5] 徐建平.基于改进的N?gram恶意PDF文档静态检测技术研究[D].南昌:东华理工大学,2017.
[6] MAIORCA D, GIACINTO G, CORONA I. A pattern recognition system for malicious PDF files detection [C]// International Conference on Machine Learning and Data Mining in Pattern Recognition. [S.1.]: Springer, 2012: 510?524.
[7] MAIORCA D, ARIU D, CORONA I, et al. A structural and content?based approach for a precise and robust detection of malicious PDF files [C]// 2015 International Conference on Information Systems Security and Privacy. Angers: IEEE, 2015: 27?36.
[8] SHAFIQ M Z, KHAYAM S A, FAROOQ M. Embedded malware detection using Markov n?grams [C]// Proceedings of 5th International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment. Paris: Springer, 2008: 88?107.
[9] 任卓君,陈光.熵可视化方法在恶意代码分类中的应用[J].计算机工程,2017,43(9):167?171.
[10] 李玲晓.基于静态分析技术的恶意PDF文档检测系统的设计与实现[D].北京:北京邮电大学,2016.
[11] Anon. Mila: Contagio malware dump [EB/OL]. [2017?12?21]. http://contagiodump.blogspot.in/2010/08/Malicious?documents?archive?for.html.
作者简介:李 国(1961—),男,河南新乡人,硕士,教授,硕士生导师,研究方向为民航智能信息处理与航空物联网、网络安全。
黄永健(1993—),女,河北秦皇岛人,硕士研究生,主要研究方向为机载信息系统、网络安全。
王 静(1980—),女,山西太谷县人,博士,讲师,主要研究方向为民航信息系统、网络安全。
