Text Detection in Natural Scene Images Using Morphological Component Analysis and Laplacian Dictionary
2020-02-29ShupingLiuYantuanXianHuafengLiandZhengtaoYu
Shuping Liu, Yantuan Xian, Huafeng Li, and Zhengtao Yu
Abstract—Text in natural scene images usually carries abundant semantic information.However,due to variations of text and complexity of background,detecting text in scene images becomes a critical and challenging task. In this paper, we present a novel method to detect text from scene images. Firstly, we decompose scene images into background and text components using morphological component analysis (MCA), which will reduce the adverse effects of complex backgrounds on the detection results.In order to improve the performance of image decomposition,two discriminative dictionaries of background and text are learned from the training samples. Moreover, Laplacian sparse regularization is introduced into our proposed dictionary learning method which improves discrimination of dictionary. Based on the text dictionary and the sparse-representation coefficients of text, we can construct the text component. After that, the text in the query image can be detected by applying certain heuristic rules. The results of experiments show the effectiveness of the proposed method.
I. INTRODUCTION
NOWADAYS vast number of images and videos are produced routinely everyday. But, how to find a way to retrieve interested images or video frames from the image and video collections effectively becomes an important and challenging task. Text in natural scene images provides direct semantic information. Text detection and recognition play important roles in image retrieval and recognition. Furthermore,the technology of text detection and recognition can also be used in many applications such as image classification, image annotation and video event detection.
In recent years,text detection has attracted a lot of attention and many text detection methods have been proposed. The most popular method for text detection in recent years is sparse representation (SR), which inspired by the sparsecoding mechanism of human vision system [1], [2]. SR technology has been successfully used for face recognition[3], [4], image classification [5], [6], image restoration [7],[8], compressed sensing [9], and image denoising [10].
Recently,researchers have demonstrated the effectiveness of sparse representation in text-detection of natural scene images[11]-[13]. In [11], Zhaoet al.proposed a new text detection method using a sparse representation with discriminative dictionaries. In this method, the edges of the scene images must be detected by the wavelet transform and then scanned into patches by a sliding window.Thus the performance of the method is highly dependent on the edge detection results, and when background and text have similar edge properties, this method may misclassify the text and background. In contrast to this method,Doet al.[13]proposed an approach to segment the text from complex backgrounds using sparse representation, and the curvelet transform and Harr wavelet transform are chosen as dictionaries to represent the background and text. However, these analytically designed dictionaries are insufficient to characterize complex structures of background and text of natural images.
To address problems mentioned above, we proposed a new text detection method based on the SR theory,which can locate text in natural scene images with complex backgrounds. In our method, to avoid the effect of complex backgrounds on the detection results, we convert the problem of text detection into image decomposition, and the SR-based morphological component analysis (SRMCA) is employed to decompose the source image into background and text components. In this process, one important issue of the SR-based text separation is the selection of dictionaries for background and text. To further increase the discrimination capability of dictionaries,we enforce the sparse representation coefficients having small within-class scatter.After the sparse representation coefficients of the input scene image over the learned text dictionary are obtained, we can reconstruct the text components by using the learned discriminative dictionary and the sparse representation coefficients. By applying certain heuristic rules to the reconstructed text component, the text in the query image can be easily detected.
In summary, the main advantages and the contributions of proposed method for text detecting from scene images are as follows:
1) We firstly convert text detection problem into image decomposition, which reduce the influence of complex backgrounds on the text detection result.Then,text and background are separated by SR-based morphological component analysis(SRMCA).
2) We learn dictionaries of text and background from training samples, rather than analytically designed by discrete cosine transform (DCT), wavelet, or curvelet. By introducing Laplacian sparse regularization term into dictionary learning method, the discrimination capability of dictionaries are improved,and characterize complex structures of background and text well.
The rest of the paper is organized as follows. Section II proposes an overview of the text detection task in scene images. Section III, the MCA based sparse representation is reviewed. Section IV presents the proposed text detection methodology, describing the designed steps in details. Section VI presents experiments carried out to validate the proposed solution and finally conclusions close the paper.
II. RELATED WORK
In recent years, many methods for text detection have been presented,that prove effective for text detection in various configurations.Yeet al.[14]presented a review of the research on text detection. Text detection approaches typically stem from machine learning and optimization methods, and these methods can be roughly classified into four categories: connected component(CC)based methods,texture-based methods,edgebased methods and hybrid methods (involving combinations of the above methods). CC-based methods [15]-[18] usually separate text from background by grouping pixels with similar colors into connected components, and the non-text components are then pruned with heuristic rules. In [19], conditional random field was used to produce connected component of text or non-text labels. Based on the CC method, Wanget al.[20] presented a coarse to fine method to locate characters in natural scene images. By using CC analysis, Wanget al.[21] developed a method to locate and segment text in natural scene images automatically.Yinet al.[18]presented a learning framework for adaptive hierarchical clustering, it constructs text candidates by grouping characters based on the proposed adaptive hierarchical clustering. In general, these approaches are suitable for detecting captions and superimposed text.The CC-based methods can be implemented rapidly. More importantly,the located text components successfully detected by the CC-based methods can be directly used for text recognition. Nevertheless, these methods may fail when text is not homogeneous and/or has complex backgrounds.
Texture-based text detection methods [22], [23] which treat text as a special type of texture, are proposed based on the assumption that text in images have distinct textural properties.In these methods, local binary pattern (LBP), wavelet decomposition, Fourier transform and Gaussian filtering are usually used as the texture analysis approaches to detect and assess textural properties such as local intensity and filter response.In [24], Zhouet al.proposed a multilingual text detection method by integrating the texture features of histogram of oriented gradient, mean of gradients and LBP. Angadiet al.[25] used the highpass filtering in DCT domain to avoid the impact of background on the text detection result. Based on local Harr binary pattern,Jiet al.[26]developed a robust text characterization approach. Generally, texture-based methods can detect and localize text accurately when the text regions have distinct textural properties from non-text ones. However,in some case, the texture property of a text region is similar to non-text region. Even worse, the texture of non-text and text may blend in together in a local region. For these cases,the texture-based methods may produce an incorrect detection result.
As we all know, text is composed by stroke components with a variety of orientation. Based on the fact, edge-based methods are developed to detect potential text areas by identifying regions where edge strength is higher in a certain direction. The edge-based methods are usually efficient and simple when the edges of text and background vary considerably. Own to the property of the above mentioned, edgebased methods attracted much attention in these years and some effective methods have already been developed in many literatures.Sunet al.[27]used color image filtering technique to extract board text under natural scenes. In this method,the rims are first obtained and then the text is extracted by analyzing the relationships among inherent features and characters. This method is efficient for extracting the board text under natural scenes. Yeet al.[28] located edge-dense image blocks using edge feature and morphology operation,and then a SVM classifier was employed to identify the texts blocks. Jainet al.[29] developed an effective edge-based text extraction method which was implemented by investigating the location of text in complex background images. Yinet al.[30] developed a method to detect text, which firstly group text candidates using clustering algorithm, and identified texts with a text classifier. Edge-based methods can achieve a good performance when scene images exhibiting strong edges.However,the image quality of a natural scene is easily affected by the presence of shadows and illumination. So, in some circumstances, image with good edge profiles is very hard to obtain.In this case,the performance of the edge-based method may be degraded.
Due to the variations of text and background in scene images, single text detection method may produce a disappointing result under certain conditions.To solve this problem,approaches by combining methods mentioned above were proposed.Panet al.[31]presented a hybrid approach by combing conditional random field (CRF) and CC-based methods. By combining the complimentary properties of Canny edges and maximally stable extremal regions, Chenet al.[32] proposed a new texts detection method. The detection results generated by this method are binarized letter patches, thus they can be directly used for text recognition. Leet al.[33] proposed to use the parallel edge feature of text stroke to locate the text in natural scene images. In this method, mean-shift clustering is utilized to group similar pixels into candidate text CCs,and then the parallel edges are detected and used to determine which CCs are text strokes. Although the hybrid approaches can overcome the disadvantages of the single method,the good performance cannot always be gained under certain conditions such as non-uniform illumination,non-uniform color and nonuniform shadow.
III. MCA BASED SPARSE REPRESENTATION
Sparse representation is developed based on the assumption that the natural signals such as natural images can be modeled as a linear combination of a few elementary atoms of dictionary.LetD={d1,d2,...,dm}∈Rn×mbe an over-complete dictionary, mathematically, signaly ∈Rncan be represented as

wherexis the representation coefficient ofyand most entries are zero or close to zero. Usually, it assumes thatm ≫n,implying that the dictionaryDis redundant. Therefore, the solution of (1) is generally not unique. To find a solution that the number of nonzero component is the smallest, the sparse representation problem can be formulated as

where‖·‖0is a pseudo norm that counts the number of nonzero entries inx.
The above optimization is an NP problem and it is often relaxed to the convexl1minimization. Considering that the source signalymay contain additive noise,(2)can evolves into(3) by using Lagrange multiplier and relaxing the constraint in (2).

whereλis a constant.
Starcket al.[34]proposed a novel image separation method which based on MCA sparse representation. The method is developed based on assumption that signal atomic behavior to be separated can decomposed into different components due to the existence of the dictionary that enables every component to be constructed using sparse representation.Also,it is assumed that the dictionary used to represent a certain component is highly inefficient in representing the other component.In other words,given a dictionaryDk,the representation coefficients ofykare sparse, but not sparse forIf we assume that one image only contains textureytand cartoonyc, then, they can be sparsely represented by texture dictionaryDtand cartoon dictionaryDc. For an arbitrary imagey, sparse representation coefficients of texture and cartoon can obtained by solving the following optimization problem:

whereλ1>0 andλ2>0 are parameters to balance different terms in the objective function.
IV. PROPOSED METHOD
A. Outlines of Proposed Method
In this paper, we propose a novel text detection method using Morphological component analysis and Laplacian dictionary, which finally leads to performance improvement over other competitive methods. The components of the proposed method are presented in Fig.1. The proposed scene text detection method includes the following stages:
1) Text and background separation: We separate text and background of scene images using SR-based morphological component analysis. Details of separation procedure are described in Section IV-B.
2) Dictionary learning: dictionaries of text and background are learned from training samples. these dictionaries are used in text and background separation stage.
3)Reconstruction of text in scene images:once dictionariesDt,Dbare learned separately, the coding coefficients of a query samplecan be obtained by solving the following equation:
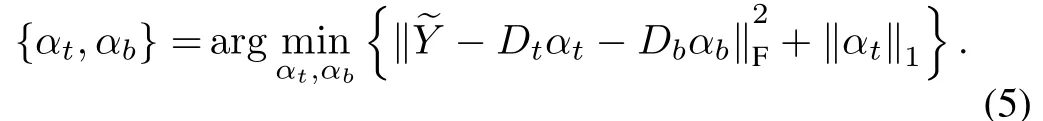

4) Text detection in reconstructed image: the gravity points in the reconstructed text picture are calculated and connected with the equivalent points in the original picture. Then, the candidate text areas are boxed. The final text area is obtained by merging the adjacent rectangles.
B. Text and Background Separation Based on SRMCA
Text and background separation plays a significant role in image recognition, image fusion, image enhancement, astronomical imaging and etc.In this paper we assume that natural scene images containing text can be considered as a mixture of background and text. Thus, imageYcan be modeled as

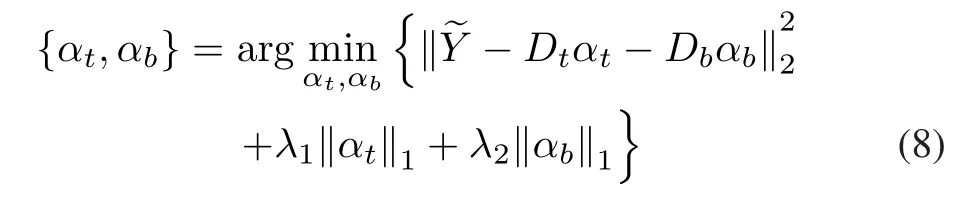
whereαt,αbare sparse representation coefficients ofonDtandDbrespectively.
As we know, characters in different languages usually have different structure characteristics and morphologies. Suppose that scene images containlanguages, the dictionaryDtcan be modified asDt= [Dt1,Dt2,...,Dt~m]. Accordingly,proposed model in (8) should be rewritten as

whereαt= [αt1,αt2,...,αt~m],αtiis the sub-vector associated with languagei.

Fig.1. Flowchart of the proposed method.
C. Discriminative Dictionary Learning
A key issue of text separation based on SRMCA is the discriminant of dictionariesDtandDb. Thus, strong discriminative capacity dictionaries have to be learned firstly. In this paper, a Laplacian sparse regularization term is introduced to model relationships between the local features. Since, the Laplacian sparse regularization term presents the consistence of sparse codes for similar features, the sparse codes for similar features are no longer independent. Moreover, the quantization error of the local feature can be significantly reduced and the similarity of sparse codes among the similar local feature can be presented well.
LetWbe the similarity matrix, we encode the relationship among the similar features by following equation:


For simplification purposes,we only compute theKnearest neighbors for each sample. In this case, (10) can be rewritten as

whereαiis the sparse codes for each clustered class andαbis the center of the class,Wibrepresents the similarity betweeniandb. We note that minimizing (11) makeαiconsist withαb. Thus, the regularization termf(α) encourages similar groups to have similar codes. Therefore, Laplacian sparse regularization term defined in (11) can be introduced into the dictionaries learning model to improve their discriminative capacity.
SupposeDt= [Dt1,Dt2,...,Dt~m] is the learned text dictionary, then dictionaryDcan be expressed asD=whereis subdictionary ofDtandDbis background dictionary.Data of text dictionary is divided intoclasses using spectral-clustering method before training.Since the background is very complex and there is no uniform criterion for classification,the training data of background were not classified.
Given training samplesY= [Y1,Y2,...,Yk], the sparse representation matrix ofYoverDis denoted byα.We expectDnot only representsYwell, but also have capability to distinguish text and complex backgrounds. To achieve this,we propose the following Laplacian discrimination dictionary learning (LDDL) model

where‖α‖1denotes sparse penalty which is used to control the sparsity of the sparse codes.λ1andλ2are coefficients,andf(α)is the Laplacian sparse regularization.By employing, eachdiofDis constrained tol2-norm, this will avoidDhas arbitrary largel2-norm. To reduce the affect of noise,(12)may be rewritten as(13)by relaxing the constraint.

V. OPTIMIZATION
Equation (13) is not convex forDandαsimultaneously.However, it is convex forDwhenαis fixed, and vice versa.Thus we can find the optimizedDand the corresponding coefficientαusing iterative optimization algorithm.
A. Update of α
Suppose that dictionaryDis fixed, (13) is reduced to a sparse representation problem. The objective function in (13)is reduced to

with
whereα=[αt1,αt1,...,αt~m,αb]denotes the sparse representation coefficients of training samplesYoverD. Coefficientsαtkcan be computed by fixed all other= 1,2,...,It should be note that the background of the scene images is considered as one class (15).
It is noticeable that terms in (14) are differentiable except‖α‖1. We rewrite (14) as

whereandτ=λ1/2.SinceQ(α) is strictly convex and differentiable, the objective function (16) can be solved by the iterative projection method (IPM) [35]. The update procedure ofαis outlined in Algorithm 1, whereis derivative ofQ(α), and
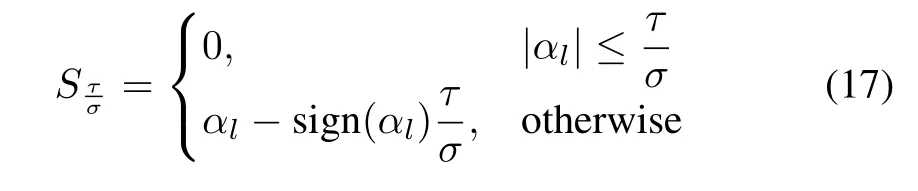

Algorithm 1 Updating α
B. Update of D
Supposeαis fixed, we can updatediof dictionaryDby fixed all the otherNow,the objective function(13)is reduced to
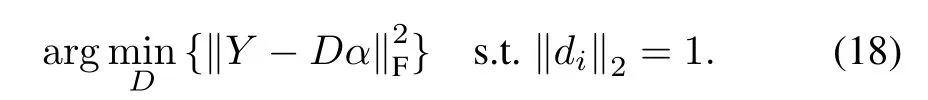
Each atom of the dictionary is normalized to a unit vector.Once the dictionaryDis initialized, we can learn optimizedDby Algorithm 2.

Algorithm 2 Updating D

VI. EXPERIMENTS AND RESULTS
A. Datasets and Evaluation Protocol
We tested the proposed algorithm on two public image datasets which consist of scene images containing text:ICDAR(2003, 2011, 2013)1http://algoval.essex.ac.uk/icdar/Datasets.html, http://www.icdar2011.org/EN/column/column26.shtml, MSRA-TD 5002http://www.iapr-tc11.org/mediawiki/index.php/MSRAText Detection_500_Database_ (MSRA-TD500)[36].
We noticed that the evaluation protocols of ICDAR and MSRA-TD are slightly different. However, in general, text detection performance criteria are defined by precision, recall and the f-measure. In order to fairly compare the proposed method with other state-of-the-art methods, we use the evaluation protocols defined by ICDAR and MSRA-TD respectively in our experiments.
B. Parameters Settings
The parameters for the proposed method are set using the values recommended in relevant papers and tested in numerous experiments. The values of these parameters are consistent across our experiments. Some of the parameters, such asλ1andλ2, appear in the formula; others, such asandnIter, are coded parameter settings.denotes the number of iterations in the process of sparse coding and nIter denotes the number of iterations in the process of dictionary learning. Specific values are provided in Table I.

TABLE I PARAMETER SETTINGS FOR PROPOSED MODEL
The size of the sliding window has a considerable influence on the performance of the learned dictionary.If the patch is too small, there will be little difference between the information in the background and that in the text, so candidate text patches may be erroneously classified as background patches.Conversely, if the patch is too large, it will contain both text and graphic components, neither of which will be sufficiently sparse to use the text dictionary or the background dictionary.In this paper, we use the same sliding window size for all datasets. According to experimental results for different patch sizes from 8 to 20 shown in Fig.2, we found that widow size 16 yielded sufficient text features and the best experimental results.

Fig.2. Experimental results for different sizes of sliding window (window size from left to right: 8, 12, 16, 20).
The number of classes in the spectral-clustering algorithm is another important parameter,because the sparse-representation coefficients are learned class by class. In addition, class number is closely related to the textural features of the text and background.Spectral classes number is selected according to experimental results of ICDAR2003 datasets.Text detection F-score for different numbers of spectral classes are shown in Fig.3.

Fig.3. Text detection F-score for different numbers of spectral classes.
The results show that the performance of the classification dictionary is superior to that of a dictionary without classification.Text reconstruction becomes more accurate as the number of spectral classes increases, reaching its optimal point at five spectral classes. The quality of text reconstruction decreases when more than five spectral classes are used.Therefore,class number is set at five in our spectral-clustering algorithm.
C. Residuals
The residual value is obtained using the formulaDuring the dictionary-learning and sparse-representation stages, we use a two-step iterative shrinking algorithm to calculate the residual value [37]. The maximum difference between residuals obtained in adjacent iterations indicates the optimal path, along which the overall residual curve stabilizes most rapidly.Fig.4 shows the residual curves for the dictionary-learning and sparse-representation stages, respectively.
Fig.4 shows that both residual curves decline very quickly,approaching their minimum values with the fourth iteration.The residual curves for both the dictionary-learning and sparse-representation stages reach their minimum values after 12 iterations.Therefore,we set the number of iterations in the process of dictionary learning to 12.

Fig.4. Residual curves for dictionary-learning and sparse-representation stages.
D. Results and Discussions
To show the advantages of the proposed model,we compare the proposed method with ICDAR competition methods and other state-of-the-art methods in [11], [30], [38]-[41]. Table II show the comparison results.
On the ICDAR-2003 dataset,the proposed method achieves the best performance, with the greatest recall (0.73) and high precision (0.72). Though the method described in [44] is almost as precision (0.79) as the proposed method, its recall(0.64) is much lower. Methods that achieve higher recall separate more text from background. On the ICDAR2011 dataset,the proposed method achieves relatively high precision(0.78) and the highest recall (0.75) among these methods. As the ICDAR-2013 and ICDAR-2011 datasets are almost the same, with only a small number of images duplicated, the difference in performance between the two datasets is very small.
Comparing with ICDAR dataset, MSRA-TD500 has larger text size range and more flexible text direction [45]. We compare the proposed method with methods in Yaoet al.[36]and Yinet al.[18] on the MSRA-TD500 database. The data obtained by the proposed method is slightly higher than that of [36] and lower than that of [18].
Next, we compare the proposed method with the stroke width transform (SWT) method and the K-SVD method. The basic stroke candidates obtained by SWT [43] are merged using adaptive structuring elements to generate compactly constructed texts. Individual characters are chained using the knearest neighbors algorithm to identify arbitrarily oriented text strings.In some papers based on the K-SVD[6]method,sparse representation is used to learn an overcomplete dictionary for text detection. SWT is a traditional and efficient method of text detection, and K-SVD is a novel but effective method of text detection using traditional dictionary learning method.The results of the comparison between our method and these two methods are shown in Fig.5.
Fig.6 shows the processed results using our proposed method, and the source images are selected from ICDAR and MSRA-TD500 datasets.From Fig.6 we can see that the sourceimages contain a wide range of text types: text in real-world scenes, text in different languages, text in different colors and sizes and text with complicated backgrounds. For different types of image, our proposed method can produce pleasing detection results. These show that the proposed method has good detection performance in most case.

TABLE II COMPARISON ON THE ICDAR(2003,2011, 2013) AND MSRA-TD500

Fig.5. Comparison of original SWT method (in the left column), K-SVD method(in the middle column)and the proposed method(in the right column).

Fig.6. Sample text-detection results using the proposed method.
VII. CONCLUSION
This paper introduced a novel text detection model based on MCA and sparse representation.There are two key innovations for the good text detection result.One is that the discriminative power of the learned dictionary in the proposed method enhanced the ability of reconstructing the text. And the other is that we used the MCA based method to detect the text in the reconstructed text picture. The experimental part of this paper has demonstrated that the proposed method had outstanding performance on text detection from natural-scene images.The experimental results show that the proposed text-detection method outperforms existing techniques.In particular,it allows robust text detection without limitations on text size, color or other properties. It can detect text overlaying images as well as text within scene images.We next will try online-dictionary learning method to reconstruct a sparser text component and use intermediate frequency and high frequency of text for text detection problem.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Networked Control Systems:A Survey of Trends and Techniques
- Big Data Analytics in Telecommunications: Literature Review and Architecture Recommendations
- A Stable Analytical Solution Method for Car-Like Robot Trajectory Tracking and Optimization
- A New Robust Adaptive Neural Network Backstepping Control for Single Machine Infinite Power System With TCSC
- Algorithms to Compute the Largest Invariant Set Contained in an Algebraic Set for Continuous-Time and Discrete-Time Nonlinear Systems
- Asynchronous Observer Design for Switched Linear Systems: A Tube-Based Approach