基于混淆矩阵的分类器性能评价指标比较
2020-02-21赵存秀
摘要:本文主要研究在模拟实验中,实验数据类别是平衡也即是训练的数据类别比例差别不大,实验结果关注的是正确率与错误率,但是随着实际问题的处理,如信用卡错误交易研究、疾病症断研究…,实验结果更多关注的是数据集中其中少类的分类精度,而不是整体的分类情况,因此不平衡数据的分类问题[2]评价成为了实验员的挑战。针对实际分类模型评价时,有以下几种方法:混淆矩阵(ConfusionMatrix)、接受者操作特性曲线(ROC Chart)、收益图(Gain Chart)、提升图(Lift Chart)、KS图(KS Chart)。
关键词:分类问题;ROC; Gain Chart:Lift Chart;KS图(KS Chart)
机器学习中,分类问题是一种输出属性类别的、离散的问题,通过对样本数据机器学习,可以将新输入样例指派到其中一个类别中的问题。那么模型的性能如何评价是我们研究的重点。在之前已经有很多的工作者对此问题进行了分析,使用不同的方法来,如交叉验证的方法,选择泛化误差最小的模型。但是也有一些研究主要是对不同的分类器的分类精度进行评价。
1 混淆矩阵[3]
1.1 混淆矩阵的建立
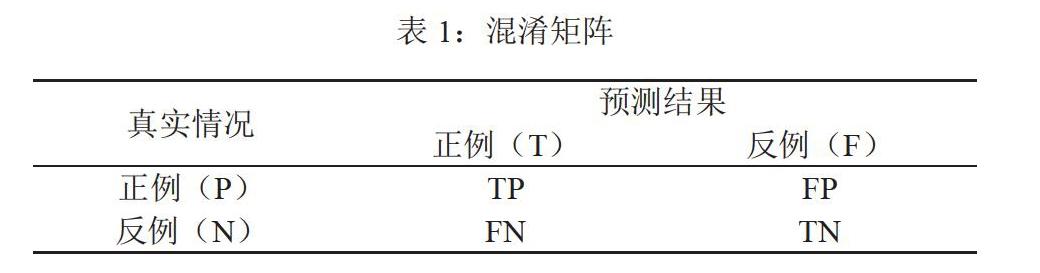
针对二类数据问题,在实验过程中,通过在训练数据上训练得到对应的分类器,然后在测试集上测试得到分类器的分类结果,通过将分类预测结果与真实情况进行比较,建立混淆矩阵的表格,如表1。
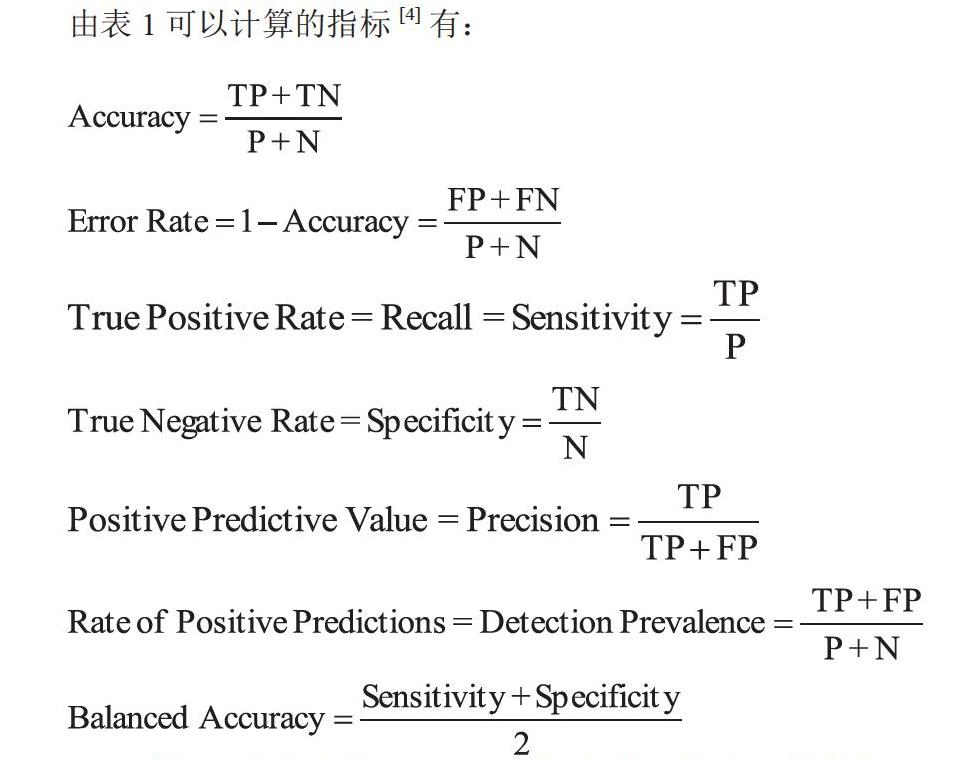
由表1可以计算的指标[4]有:
在一般的分类问题中TP和TN越高越好,混淆矩阵中的4个元素的确定都依赖于实验者主观设定的阈值0.5。如果只依靠混淆矩阵这种原始的方法,那么不经过繁琐的实验我们无法确认哪个阈值是最好的。一些positive事件发生概率极小的不平衡数据集(imbalanced data),混淆矩阵精确率的评价可能效果不好。比如对信用卡交易是否异常做分类的情形,很可能在成千上万的交易中只有1笔交易是异常的,我们这时候更关心的是这笔交易异常的,而不是其他交易成功的。在医学界,我们临床关心的犯病的病例,但是犯病的类别占比比较少,那么一个将所有交易都判定为正常的分类器或者是所有的病人都判定为正常人的准确率是99.99%。这个数字虽然很高,但是没有任何现实意义。
相比較于上面列举的各种基于混淆矩阵建立的分类模型评价方法,接受者操作特性曲线(ROC ChaIt)、收益图(Gain Chart)、提升图(Lift Chart)、KS图(KS Chart)都对混淆矩阵的缺点的有改进。
1.2 ROC曲线AUC面积[5]
ROC曲线也即是受试者工作特征曲线(Receiver OperatingCharacteristic Curve)。横轴表示“False positive rate”数,即在所有真实值为Negative的数据中,被模型错误的判断为Positive的比例。纵轴表示“True positive rate”,即在所有真实值为Positive的数据中,被模型正确的判断为Positive的比例。
ROC曲线上的一系列点,代表选取一系列的阈值(thre shold)产生的结果。ROC曲线上众多的点,每个点都对应着一个闽值的情况下模型的表现,多个点连起来就是ROC曲线了。
AUC( Area Under Curve),即曲线下的面积,每一条ROC曲线对应一个AUC值。AUC的取值在0与1之间,AUC -1,代表ROC曲线在纵轴上,预测完全准确,0.5< AUC<1,代表ROC曲线在45度线上方,预测优于50/50的猜测。AUC -0,代表ROC曲线在横轴上,预测完全不准确,需要选择合适的闽值后,产出模型。
1.3 收益图与提升图[6]
收益图,提升图是用来评估模型找到数据中的正例与真实数据正例的比较。混淆矩阵中有一个指标RPP(Rate of positivepredictions),也是预测为正的比例。根据实验者设置的不同闽值,RPP的范围为[0,1]。将累计RPP作为收益图、提升图的横轴,纵轴为待评价模型在预测为正的样例中预测正确的概率,也就是TPR(True Positive Rate),TPR称为收益值(Gain Value)。提升值(LiftValue)用TPR/RPP计算。针对一个模型的收益图,若能快速达到很高的累计收益值,并很快趋于100%,则是较好的模型;而提升图则是在很高的提升值上保持一段,或缓慢下降一段,然后迅速下降到1。
1.4 KS (Kolmogorov-Smirnov)曲线[7-9]
相对比与ROC曲线是把真正率和假正率当作横纵轴,而K-S曲线是把真正率和假正率都当作是纵轴,横轴则由选定的阈值来充当。KS(Kolmogorov-Smirnov)值越大,表示模型能最大程度上将两类分开。KS值介于0与1之间,通常来讲,KS>0.2即表示模型有较好的预测准确性。KS需要TPR和FPR两个值:真正类率(truepositive rate,TPR),分类器所识别出的正样例占所有正样例的比例,计算公式为:
KS曲线是两条线,其横轴是阈值,纵轴是TPR(上面那条)与FPR(下面那条)的值,值范围[0,1]。那么KS两条曲线之间最大距离对应的阈值,就是最能划分模型的闽值。
2 模拟实验
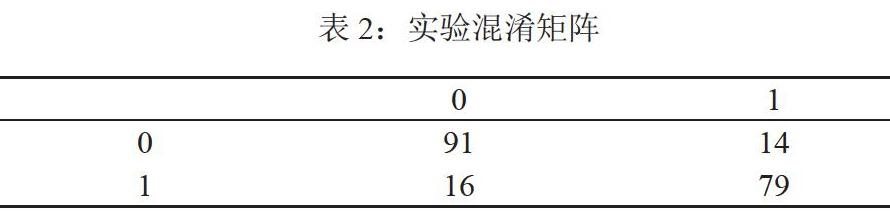
此模拟实验使用的数据是ROCR包中的ROCR.simple数据,有200个数据,其中有样本对应的预测值和真实的标签。在预测值的基础上利用caret包里的confusionMatrix可以得到结果。如表2所示。
在R软件中利用ROCR中的performance函数得到了auc-0.8341875,得到此数据应用的分类器预测的结果还是可以的。并利用ggplot2软件做出Roc的图像,如图1所示。
图2所示的是收益、提升图,对于收益图,收益图在以斜率为2的快速增加,然后又缓慢的增长到1,而提升图在1.8左右附近上保持一段然后迅速下降到1。由此可以看出,分类的效果也是很不错的。
图3中所示的是KS图像,KS-value为0.6999297由此可以看到两条曲线之间相差很大,分类器的分类性能较好。
3 结束语
针对于分类问题,可以有很多的不同的分类性能评价指标,本文在原有的混淆矩阵的基础上建立的度量标准,分析其在类别不均衡的数据中,分类效果评价不准确,因此建立了Roc、收益、提升图、KS图像,并通过模拟实验观察这些评价指标的度量性能。
参考文献
[1]张涛.不平衡数据分类研究及在疾病诊断中的应用[J].黄河科技学院学报,2019 (05):15-22..
[2]李永新.一种不平衡数据的分类方法[J].兰州理工大学学报,2008 (03):87-90.
[3]Craig J C.A Confusion matrix for tactually presentedletters [J]. Perception&Psychophysics, 1979, 26 (5): 409-411.
[4]周志华.机器学习[M].北京:清华大学出版,2018,28-35.
[5] Lobo J M,Jim 6 nez-Valverde A,Real R.AUC:a misleadingmeasure of the performance of predictive distributionmodels[J]. Global Ecology&Biogeography, 2 010,17 (2):145-151.
作者简介
赵存秀(1987-),女,山西省晋中市人。硕士研究生学历,中级(讲师)。研究方向为统计机器学习。
