基于协同过滤的电子商务推荐研究
2020-02-21陶建强

摘要:本文针对基于协同过滤的电子商务推荐做出一定研究。通过对电子商务个性化推荐模型的设计,在K-Means聚类算法的基礎上针对基于用户的协同过滤算法、基于聚类优化后的协同过滤推荐算法以及基于内容的协同过滤推荐算法做出一定的研究,最后通过实验验证得出最适合个性化推荐的一种推荐算法。
关键词:个性化推荐;K-Means聚类;协同过滤
随着现代科技的发展,大众对电子商务的需求越来越大。当电子商务的发展跟不上大众信息化的需求,会导致用户难获得需要的信息。因此,在信息化背景下,如何加强对用户的精准推荐,是电子商务发展关注的重点。但传统的协同推荐算法存在一定的弊端,如数据的稀疏性导致推荐精度不高。因此,针对该问题,人们提出很多解决方案,如通过对稀疏数据进行填充,但效果都不理想。而聚类具有易收敛、运行时间短、效率高的优点,因此本文结合聚类算法的优点,提出一种基于聚类改进数据稀疏性的协同过滤算法,并通过试验进行验证。
1 基本方法
1.1 K-Means聚类
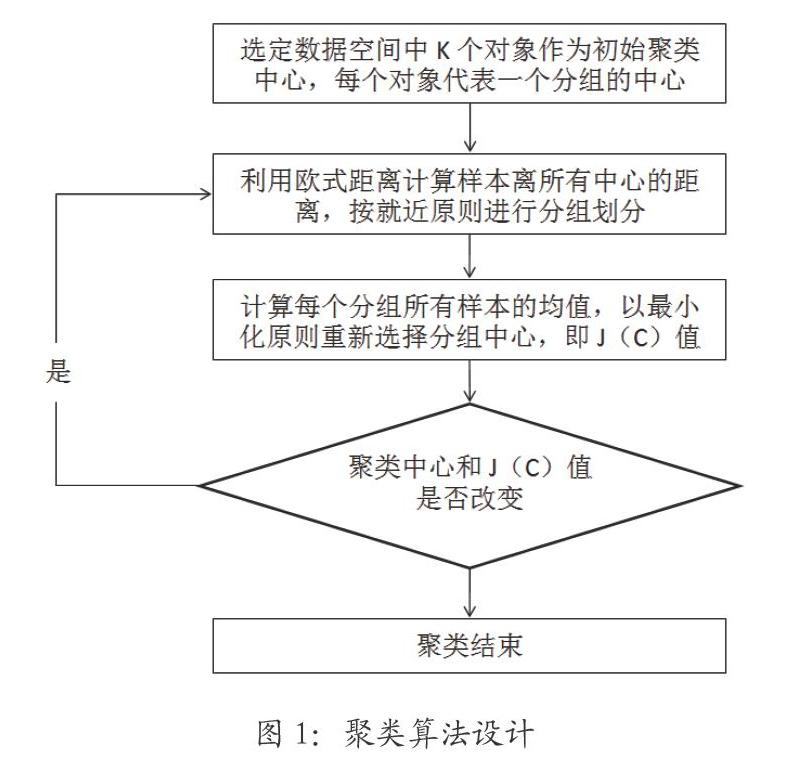
K-Means聚类算法是将输入的用户及商品数据进行划分,将分解出来的簇分为有效和无效两个部分,并且将无效部分过滤删除。这样就极大的降低了数据集所需的空间规模,提高了数据集的质量。具体步骤为:给定数据集,选择初始质心K。选定K后,可用误差平方和来计算训练样本到初始质心的距离。待计算得出结果以后,判断是否可以将训练样本加入到簇中。再运行一次后,再对新样本进行划分,重新选择质心。重复以上步骤,直到所有的簇达到最大的迭代次数,或者是所有簇都不会发生变化,即样本到聚类中心的距离平方和J(C)最小。详细步骤如图l所示。
如图1所示,在进行K-Means聚类算法的时候,需要先选定一个数据空间中的K个对象为初始的聚类中心,这K个对象都代表着每一个分组的中心。选好以后再利用欧氏距离公式来进行分组计算,根据计算的结果重新选择分组中心J(C)值,最后利用J(C)值判断算法终止条件。具体流程如下:
1.2基于用户的协同过滤推荐
基于用户的协同过滤可以根据需求的不同分为不同的类型。分别是在用户的基础上、在算法的基础上以及在项目的基础上做出研究。本文主要的研究方向是基于用户的协同过滤对商品个性化推荐系统设计,特点是能通过公式(3)计算出用户对商品喜爱程度,然后根据用户的喜好做出最适合的推荐,让用户能够快速有效的找到自己喜欢的商品。
通过公式(4)就能够得到其他相似用户对该商品的综合评分,在根据计算出来的结果给用户做出针对性的推荐,节省了时间,提高了用户选择商品的效率。这里要特别的说明的一点是,这种方式只针对他们评论的交集部分,所以能够大程度的减少某些用户对商品过分的评分因素。
2 模型构建
2.1 个性化推荐模型构建思路
个性化推荐指的是以用户的基本信息、上网行为等作为基础,从而在海量的用户中找到相似用户,然后通过这些相似用户对商品的评价,来预测其他用户对该商品的喜好程度。基于聚类的协同推荐就是在相似的用户中,通过聚类的方法将相似用户分类,从而合并为新的簇,并筛选出新的用户作为簇类代表,加入到协同推荐中,并按照协同推荐的计算步骤进行预测。
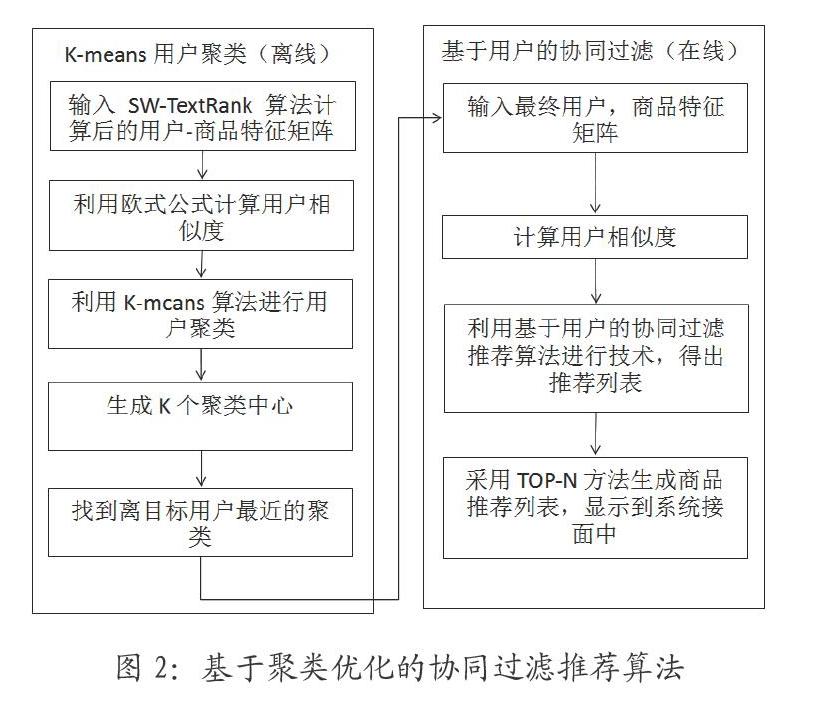
本文提出的基于聚类的协同过滤算法分为两步骤:一是通过聚类改进数据的稀疏性;二是提出基于用户的协同过滤。聚类优化采用K-Means聚类,该聚类方法的特点是先利用欧氏距离公式将用户的相似度计算出来,然后在运用K-Means聚类将相似的用户特征分在同一个簇内,形成一个完整的簇。基于用户的协同过滤指的是通过计算目标用户与分解出来的簇之间的距离,然后得出距离最近的簇信息,计算出簇信息以后再运用基于用户协同过滤推荐算法进行评分计算,最后根据评分的结果生成展示列表。
2.2 基于聚类的协同过滤推荐构建
图2为基于聚类的协同过滤算法流程。由图2可以看出,相对于传统的协同过滤算法,优化过程主要是加快了聚类距离的计算时间以及簇的更新时间。假设聚类距离Du是一个NxN的矩阵,距离计算时间复杂度为O(N2),随着不断进行迭代重复,提取出来的数据也越来越精简,提取出来簇的数量也是越来越少,由此,时间的复杂度也会有所减小,设立为O(N),这时候设立的聚类距离的整个计算时间复杂度为O(N2)。虽然在理论上看起来比较复杂,但是这些过程都可以在离线情况下进行,也就是如果将这个方式应用到整体上,对在线推荐效果时间影响很小。所以需要先利用K-Means聚类算法将选定的数据集进行划分,划分以后再利用协同推荐算法进行计算,以此来降低个性化推荐的时间消耗,达到高效效果。
通过分析得知,基于聚类优化的协同过滤推荐优点在于在离线模式下,将输入的模型用户和商品数据集划分成很多个数据子集,对个性化推荐算法的运行时间不产生影响。将划分好的数据子集用基于用户的协同过滤推荐算法进行推荐,很大程度的降低了数据计算复杂度,提升运行效率。
3 实验验证
3.1 评价指标
为了得到最适合的个性化推荐模型,针对以上的方法做出一定的实验验证。为了得到最准确的结果,此次采用的是平均绝对误差MAE(Mean Absolute Error)的方式对实验结果进行验证。平均绝对误差均方误差指的是绝对误差的平均值。利用公式(5)计算出最适合的结果,能够很好的反应出设立的预测值误差的真实情况。
3.2 试验对比结果
通过对聚类的协同过滤编程,得到图3的对比结果。
通过图3对各个推荐算法的比较可以得知,基于聚类优化后的协同过滤推荐算法相较于基于内容的协同过滤推荐算法以及基于用户的协同过滤推荐算法都有更高效的作用,是比较适合个性化推荐的一种推荐算法。
4 结语
随着电子商务的发展,大众对于电子商务信息化的需求逐步提高,为了满足大众的需求,本文通过对个性化推荐模型算法设计,分别针对基于用户的协同过滤推荐算法、基于聚类优化后的协同过滤推荐算法以及基于内容的协同过滤推荐算法做出一定的研究.最后通过一系列的计算,得出最适合当代用户需求的个性化推荐算法。不仅减少了计算的难度,缩短了线上计算的时间,还能够通过计算目标用户与相似用户对商品的评分,快速高效的根据用户的需求给他们推荐适合他们喜好的商品,提高了用户对电子商务使用的效率,是非常有必要性的一项研究。
参考文献
[1]翟丽丽,邢海龙,张树臣.基于情境聚类优化的移动电子商务协同过滤推荐研究[J].情报理论与实践,2016,39 (08):106-110.
[2]李菲,基于关联规则优化的个性化推荐系统[J].内蒙古师范大学学报(自然科学汉文版),2016,45 (04):515-520.
[3]兰艳,曹芳芳,面向电影推荐的时间加权协同过滤算法的研究[J].计算机科学,2017,44 (04):295-301+322.
[4]田磊,任国恒,王伟,基于聚类优化的协同过滤个性化图书推荐[J].图书馆学研究,2017 (08):75-80.
[5]盛先锋.基于聚类优化的数字图书馆协同过滤个性化推荐服务研究[J].中国中医药图书情报杂志,2019,43 (03):37-40.
[6]翟烁.基于用户兴趣和双重聚类融合的协同过滤算法的优化研究[J].无线互联科技,2015 (05):124-127.
作者简介
陶建强(1978-),男,德州职业技术学院,讲师,电子商务专业。
