一种基于核聚类的多分类器选择算法
2020-02-21陈风妹
陈风妹
摘要:本文针对目前人们对分类性能的高要求和多分类器集成实现的复杂性,从分类器分类错误的分布特性和识别性能出发,对基于核聚类的多分类器选择算法内容及应用要点进行了探讨。这种算法是围绕核的可能性聚类算法作为核心构建的,找出各分类器在特征空间中局部性能较好的区域,并利用具有最优局部性能的分类器的输出作为最终的集成结果。理论分析和实验结果表明:该算法具有很好的分类性能。
关键词:多分类器集成;核聚类;分类器的选择
1 引言
近年来,分类器集成化成为了计算机行业相关设备及机器识别技术的研究新方向,并且随着学者的深入研究,也促成了计算机技术水平的提高和多分类集成器的改革与优化。传统的多分类集成模式采用的均是分类器输出的综合,其输出端设计是根据测试样本的类型而确定的,采用合适的集成算法集成多分类器输出的每一个结果,最终得出决策的最终结果。多分类器输出的集成是在分类器相互独立的假设下进行分类的,而为了更好地解决集成算法设计与实际使用需求之间存在的矛盾问题,需要凭借现有技术设计和优化采用全新计算路径的集成算法。同时也可以从另外一个角度来考虑,这就是设计多分类器选择的模式识别系统。
由于分类器在特征空间中不同区域的性能参数往往不尽相同,因此分类器选择模式识别系统的核心技术便是通过对样本所在区域的特征分析,实现对分类器性能选择方案的最优化处理。并以该分类器的输出作为整个集成系统的输出结果。
本文提出了一种新的多分类集成算法一一基于可能性核聚类的多分类器集成算法。这种算法的创新性在于将核的可能性聚类作为算法运行时参照的主要标准,能够科学地对样本特征空间进行识别与分类,然后根据分类器对各聚类中的测试样本的分类误判率决定每个聚类的特征区域上的最优分类器;测试样本周围局部性能最优的分类器的输出作为最后的集成结果。
2 可能性核聚类算法原理
2.1 聚类分析
与传统模式识别方式相比,聚类分析方法对于具有一定“相似度”的特征模式的划分更加高效而科学,这对于解决实际的预算问题提供了很大的帮助。聚类分析的主要特点在于,它所划分出的不同特征模式之间既在某种度量上保持了较好的相似关系,同时又将不同集合和特征模式之间的区分度变得更加明显,因此脱离了传统而简单的分类效果。聚类分析方法的应用优势是能够不依靠对分类数据属性的依赖,在无监督的学习环境下自主探寻目标的分类属性值,对于分析对象之间相似性与差异性的更为全面和客观。同时,聚类分析是通过获取研究对象的真实参数和属性值作为进一步计算的理论基础,因此运行算法后得出的结果与事物本身的实际情况存
2.3可能性核聚类算法定义及内容描述研究
KPCM[3]算法以是核函数与PCM的聚类算法作为融合基础形成的一种复合算法。在该算法的运行环境下能够有效发挥出核函数的价值,将在观察空间线性不可分的样本非线性映射到高维的特征空间而变得线性可分,这样样本特征经很好的分辨、提取并放大后,可以实现更为准确的聚类。而且只要非线性映射是连续和光滑的,观察空间中样本的拓扑结构将会在高维特征空间中得到保持,并且基于核的聚类算法在类分布不为超球体或超椭圆体时依然有效。
高斯核函数作为可能性核聚类算法中组成内容发挥了不可或缺的重要作用,在计算其目标函数时应按照以下公式进行:
3 基于核聚类的多分类器的选择算法
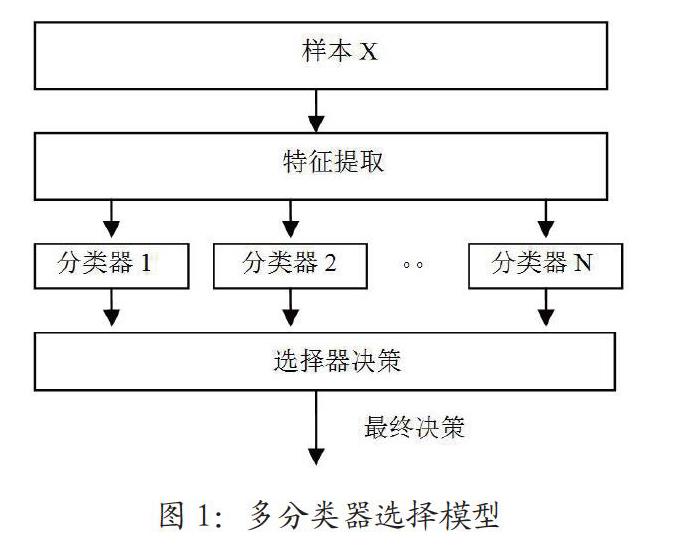
多分类器选择系统[4]从多个分类器中参照样本识别的结果选择分类标准最科学的一种分类器,并且为了便于对数据进行管理还要在样本类别中添加分类器运算结果。图1为多分类器选择的基本模型。
本文给出的基于核聚类的多分类器选择算法。首先利用bagging方法[5]训练神经网络分类器,之后以样本特征空间的分布情况作为作为参照标准实现聚类分析,然后按照分析得出的原始数据结果对每个聚类的识别率进行计算和比较,将其中具有最高识别率的分类器作为整个综合运算的决策结果:
3.1用bagging方法训练分类器
利用bagging方法对训练样本集进行多次抽样,产生新的新的样本子集。用所得的样本子集对神经网络进行训练,产生多个神经网络分类器。
3.2 空间特征的聚类方法
对于大部分空间特征而言,基于核的可能性原理聚类分析方法大多是以聚类中心的数目C作为识别对象和运算目标的,在运算时按照分类方法与聚类分析的原理逐步进行求解。在完成对不同特征空间的聚类后,要按照聚类中心的数目C为数量标准划分区域,同时对每个特征区进行标注以确保特征空间聚类分析达到标准化要求。
3.3 选择每一局部区域的最优分类器。
3.4 聚类分析的最终决策
根据对目标特征空间样本进行聚类和分析后所选择的最优分类器类型,进一步检验输出结果的准确性和可行性,若判断无误后则确定该输出结果为预测样本的最终决策。
4 实验分析
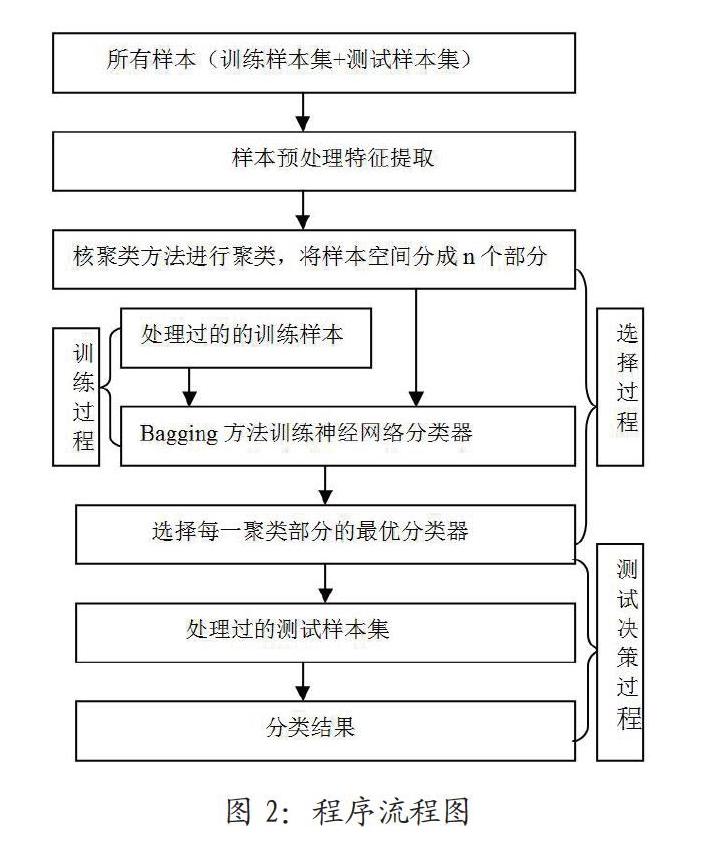
在对基于核聚类的多分类器进行实际应用研究和选择性集成效果分析时,说采用的方法是将GASEN代码[6]作为算法的运行基础。通过对该算法的标准化运行产生相应的分类器,并与bagging方法生的的分类器一起对同一测试样本进行选择性集成,最后比较测量结果和集成效果判断所选择的集成方案是否科学。其实验过程流程图如图2所示。
实验中采用bagging方法来训练产生基分类器,而在生成分类器的过程中为了确保核的可能性聚类应用优势得到充分的发挥,还可以配合使用BP神经网络技术大幅度提高运算的速度和保障结果准确性。
BP神经网络技术的应用主要作用于分类器的训練与生成阶段,在BP神经网络模式下所形成的分类器主要是由输入层、输出层和中间隐含层构成。在该分类器中每一层的节点数都反映了不同的数据类别,例如输入和输出节点数目反映的分别是数据的属性数和类别数,而隐含层节点数则需要根据分类器的实际使用需求自定义值,通常可设置为5个节点。另外还需要MATLAB软件中的神经网络工具箱[7],对训练步数和其他参数进行设置。
而在按照和可能性聚类方法时则大多采用的是MATLAB软件中的SVM工具箱[8],函数结构的主体通常为高斯核函数,并将聚类中心数目设置为对数据类别数的反映。
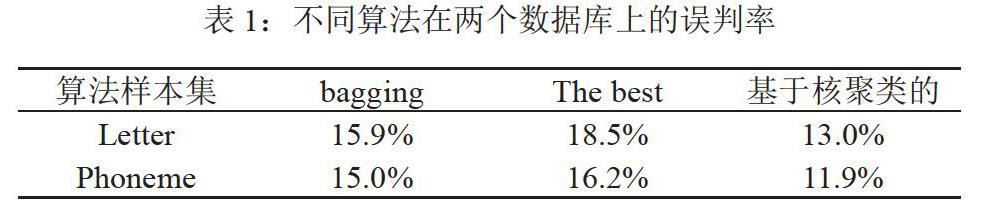
本实验中的数据主要来自UCI数据库的“letter”数据集和来自ELENA数据库的“Phoneme”数据集。同时,这些数据在测试分类器性能和比较选择性分类结果和聚类分析最终决策的科学性过程中,也体现出了较高的应用价值和特性水平。例如Letter数据集包括A-Z 26个大写字母,共26类。当将提取的特征目标数设置为16时,从数据集中调取的不同类别样本数平均值达到了800个,而样本总数更是超过了20000:而Phoneme数据库则主要由鼻元音Nasa和非鼻元音Oral组成,在实验过程中分别抽取两个不同类别的元音组成总数为5000的数据集,再将数据集中的数据进行随机分类形成六个实验组,以五组数据集的并集作为初始训练数据集合,剩余的一组作为测试集用于和初始训练集进行对照。
表1数据显示,基于核聚类的选择器算法相较于由bagging方法生成的多分类器,在进行选择性集成时效果更为明显并且效率更高。同时该算法的误判率和仅有一个最优分类器相比也得到了大幅度的降低,这说明基于核聚类的算法所测得的数据结果对于分类准确性与局部有效性的考虑更为全面,因此分类结果的可信度和科学性水平也更高。
5 结论
为了提高分类器系统的性能,简化系统的设计,本文将核学习方法的思想应用于多分类器的选择中,提出了一种新的用于分类的基于核的可能性聚类的多分类器选择算法,该算法既考虑了分类器错误的分布特性,又考虑了分类器的分类识别能力。从而通过对基于核的可能性聚类算法的应用与优化,实现了对聚类效果准确性与用于区域性分类器选择科学性的充分掌握。
参考文献
[1]张莉,周偉达,焦李成,核聚类算法[J].计算机学报,2002,25 (6):587-590.
[2]刘赛雄,耿霞,陆虎,基于深度自动编码器的小麦种子聚类识别方法[J].江苏大学学报(自然科学版),2020,41(03):294-300.
[3] UCL Machine Learning Group ELENA database.
[4]张松灿,普杰信,司彦娜,孙力帆.蚁群算法在移动机器人路径规划中的应用综述[J],计算机工程与应用,2020,56 (08):10-19.
[5]邓磷,王琳.盛步云,萧筝,基于变邻域蚁群算法的自动光学检测路径规划[J].计算机工程与设计,2020,41(02):354-360.
[6]李飞.基于多核概念分解的聚类方法研究[D].山西大学,2019.
[7]侯文太,普运伟,郭媛蒲,马蓝宇.基于高斯平滑与模糊函数等高线的雷达辐射源信号分选[J/OL].自动化学报1-10 [2020-07-28].
[8]吴一全,李海杰,宋昱.基于引导核聚类的非局部均值图像去噪算法[J].电子科技大学学报,2016,45 (01):36-42.
作者简介
陈凤妹(1979-),女,讲师。研究方向为人工智能、大数据应用技术。
