大数据背景下数据预处理方法研究
2020-02-18周党生
周党生
(青岛科技大学,山东 青岛 266000)
随着人类的进步社会的发展,信息和科学技术也飞速前进,大数据成长势头愈发迅猛,各个行业也以极快的速度产生海量的且形式各异的数据信息。但是,从这些大量数据中提取出的有用的信息却是相当匮乏的,若没有一个系统性的提取工具,那么提取有用信息的效率是相当低下的。所以,各种数据挖掘工具随着时代的需求应运而生。然而,随着挖掘工具的实际应用,人们发现这些数据是不能直接用来挖掘的,是非结构性的,于是,数据的预处理成为了挡在大数据前进路上的第一个关卡。在真实世界中,数据来源各式各样质量良莠不齐,所以原始数据一般是有缺陷的,不完整的,重复的,是极易受侵染的。这样的数据处理起来不仅效率低下而且结果也不尽人意,这种情况下数据的预处理显得尤为重要。一方面,数据预处理把原始数据规范化、条理化,最终整理成结构化数据,极大地节省了处理海量信息的时间;另一方面,数据预处理可以使得挖掘愈发准确并且结果愈发真实有效。本文指出了大数据背景下处理原始数据时极易遇到的难题,并且针对这些难题得出了一些常规的数据预处理方法。在这些方法的应用过程中,删除多余数据,拨正偏差数据,填补不完整数据,使得数据趋向结构化且准确性大幅提高,为下一步工作打下了基础,极大地节省了数据挖掘的成本。
1 大数据预处理
数据预处理在整个大数据工作中占据极其关键的位置,在真实世界里,数据来源各式各样质量良莠不齐,所以原始数据一般是有缺陷的,不完整的,重复的,是极易受侵染的。这些数据完全不适用于直接进行数据挖掘,所以为了得出更加准确的结果,我们不得不将原始数据进行预处理。从整个大数据的处理流程来看, 数据预处理技术的水平决定了数据的真实性、完整性,对后续的数据分析起到十分关键的作用[1]。
数据清洗(Data Cleaning)的主要内容就是按照一定的规则和标准把原始数据中存在的如数据缺失、奇异值和离群点等问题处理掉,也包括处理原始数据中留存的重复信息和噪声干扰。
数据集成(Data Integration),数据集成顾名思义就是按照一定的特征规则将数据有机地集中,将来源各异的现实世界的数据相互匹配和统一的过程。这一过程改善了系统的协作性和统一性,大大节省了准备和分析数据所需的时间成本,提高了数据资源的利用率。这个过程的主要难点包括如何选择数据,如何解决数据不兼容,如何根据不同的理论和规则将数据统一起来。例如冗余问题,常用的冗余相关分析方法有皮尔逊积距系数、卡方检验、数值属性的协方差等。
数据变换(Data Transformation)是大数据工作中的重要一环,就是按照规则将数据进行转换,使其满足一定的条件来适用于下一步的工作。是找到数据的特征表示,用维变换或转换来减少有效变量的数目或找到数据的不变式,包括规格化、切换和投影等操作[2]。它的主要转换形式:(1)数据光滑。即运用分箱、聚类等进行数据光滑。(2)数据聚集。即将数据进行集中汇总。(3)数据概化。即用高一级的概念代替低一级的概念。(4)数据规范。把特征数据缩放,将原始数据映射到指定的区域中。(5)特征构造。即构造出新的特征并汇合到原本特征集中。(6)规范化。最小-最大规范化;零一均值规范化;小数定标规范化。
数据归约(Data Reduction)主要有三个方面:(1)维归约。利用主成分分析和小波变换将原始数据映射到较小的空间,常见算法有:LVF(Las Vegas filter)、MIFS(mutual informationfeature selection)、mRMR(minimum redundancy maxi-mum relevance)、Relief算法等。(2)样本归约。从原始数据中寻找出一个具有代表性的子集(估计量),使其能够体现整个原始数据集的特征。(3)数据压缩。若可以从处理后的数据中重构出原始数据且不丢失信息,则称之为无损的,反之,称之为有损的。(4)数值压缩。原始数据可以用较小或较短的数据来表示,也可以用数据模型来代替。(5)离散化。把数据离散化,用有限个区间数据代替原始数据。
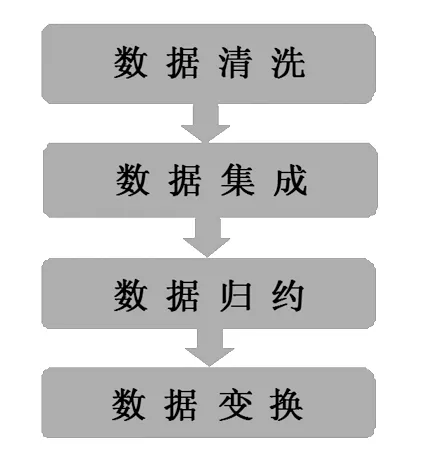
图1 数据预处理的一般步骤
2 典型问题和方法
由于数据产生于真实世界里各个真正运转的系统,所以原始数据有如下三个典型问题:
(1)无序性。数据来源各异并且质量良莠不齐,所以原始数据一般是无序杂乱的。原始数据都是来源于现实世界各个实际应用的系统,因为这些应用系统并没有统一的标准来要求原始数据如何定义,也没有统一的数据表达形式,所以原始数据间存在无序杂乱的状态,且存在大量的无用误导的数据,无法拿来直接使用。
(2)重复性。是指对于同一个客观事物在数据库中存在其两个或两个以上完全相同的物理描述。这是应用系统实际使用过程中普遍存在的问题,几乎所有应用系统中都存在数据的重复和信息的冗余现象[3]。
政工部门在企业中是一个重要部门,其对企业的发展起着重要作用。故需要对工作机制进行不断创新,优化工作管理制度,建立适应企业发展的管理机制。可以借鉴的建议为在制定企业管理制度时,将政工工作人员的利益放在第一位,对表现优秀的工作人员进行加薪和升职,需要建立合理的奖励制度和惩罚制度,从而有效提高工作人员对工作的热情和素质水平。政工工作人员需要留意在工作中遇到的问题,及时处理出现问题。此外,应该及时关注政工工作人员的政治思想,工作态度和工作人员对工作的反映情况,根据企业管理发展的具体目标完成对政工人员的管理,只有真真正正的考虑政工人员的利益,对企的发展才会更有益。
(3)缺失性。因为实际应用中的系统存在某些缺陷或是运行不当,可能使得数据集的某些属性值缺失和记录错误,甚关键数据的缺失导致整个数据集的价值大大降低,最后无法得出准确的结果。原始数据的缺失信息和随机信息极多,只有对数据进行预处理,处理重复数据、缺失数据、随机数据、不可用数据等原始数据存在的问题,下一步的数据挖掘工作才能更准确地展开。因此,数据预处理是数据挖掘前的一个非常重要的数据准备工作,是知识发现过程(knowledge discov-ery in database,KDD)的关键环节之一[4]。
数据预处理对下一步的工作来说是非常关键的,它直接影响最终的结果。针对"问题数据"比较典型的数据预处理方法:缺失值处理、异常值处理、重复值处理、去噪声等。

图2 问题数据种类
2.1 缺失值处理
1)删除。当缺失值样本对总体样本的影响不明显的时候可以通过删除这种简单有效的方法来解决问题,但是这种方法的缺陷也比较明显,若删除的缺失值恰好是关键需要的数据,则会直接影响到后续工作并且最终结果会产生较大偏移。
2)人工填补。只有用户自己最了解自己的数据,所以通过人工填补的方法处理缺失值产生的数据偏离最小。但是,当数据集规模很大并且缺失值问题较严重时会消耗大量的精力和时间,此情况下不建议使用。
3)均值插补。数据集中的信息特征分为数据特征和非数据特征,如果数据集中的缺失值是数据特征,则根据此特征上其他对象的值的平均值来赋予该缺失的特征值;如果数据集中的缺失值是非数据特征,那就根据此特征值上其他对象的众数来赋予该缺失的特征值。
4)就近补齐。对于存在缺失值的特征,就近补齐是在所有数据集中找与之最相近的特征,然后用这个相近特征的值进行填充。但是此方法中的“相近”这一概念没有统一的标准,有较强的主观影响,可能造成较大的数据偏离。
5)多重插补。主要有三步:①为每个缺失值都生成一套可以用来填补的值,产生若干完整数据集。②用对完整数据的统计分析方法对每个插补数据集合进行统计分析。③根据分析结果进行评析,选择最优的插补值。
6)回归。在完整数据集的前提下建立回归模型,将已知的特征值带入模型预测出未知的特征值,然后将此预测值填补缺失部分。
7)极大似然估计。一般常见的缺失值填补算法包括EM最大期望值算法(expectation-maximization algorithm)、MI算法(multiple imputa-tion)和KNNi算法(k-nearest neighbor imputation)等。
2.2 异常值判别和处理
1)简单统计分析。例如对男性成人身高这个特征值进行规范统计:身高区间是[1.3:2.3],若样本中的某个身高值不在这个区间内,则说明这个身高值属于异常值。
2)3δ原则。根据正态分布定义可知P(|x-μ|>3δ)<=0.003,这种事件发生的概率不超过0.003,常规情况下不会发生,所以我们默认当样本的距离的平均值大于3δ时该样本为异常值。
3)基于模型判别。根据完整数据建立一个模型,其中不能同数据模型拟合的值就是异常值。
4)基于密度判别。当一个点的局域密度与其近邻的点的局域密度有显著不同时,我们可以判断这个点是异常的。
5)处理方法:删除;按照缺失值的方法来处理;用平均值修正。
2.3 噪声处理
1)分箱法。将预处理的数据分散到若干个箱中,考察数据近邻的噪声数据值来光滑有序数据值。分箱的具体方法有三种:用箱平均值光滑,用箱中所有值的平均值代替箱中的每一个值; 用中位数光滑,即用箱中所有值的中位数代替箱中的每一个值; 用箱边界光滑,将箱中的最值视为两边界,箱中的值都被更近的边界值所代替。
2)聚类法。用聚类的方法找出并删除孤立于簇之外的值,这些孤立点就是噪音。噪声过滤的常用算法包括IPF算法(itera-tive partitioning filter)、EF算法(ensemble filter)[5]。
2.4 重复值处理
重复数据即两次甚至多次出现的数据,因为在整体样本中占得比例大于其他类型的数据问题而更容易令结果出现倾向性,因此处理重复值的方法一般是降低重复值的权重,对于重复数量不多的重复值可以使用直接删除这种简单方法。对那些可控的也就是数量不多的重复数据,一般是将其带入代码中进行匹配进而删除多余的不需要的数据。一种混合删除机制(Hy-Dedup),Hy-Dedup能把离线删除和在线删除结合起来,先使用在线删除把重复数据删除节约存储空间,接着再使用离线删除将未能在线删除和删除不彻底的重复数据删除。
3 总结
随着时间的推进,大数据发展日新月异,各种行业以及新兴科技都会对数据预处理的发展产生巨大的推动作用,经过数据的预处理工作,删除冗余数据,填补不完整数据,拨正偏差数据,将数据清洗后再挑选出必要的数据进行集成,达到数据格式一致、表达简练、存储形式统一。本文主要阐述了数据预处理的几种典型方法,实际上由于外部环境干扰因素太多太杂,同时又因为各行各业对数据的要求形式不同,造成原始数据极大的不同且存在各样的问题。所以我们在进行数据预处理时应该针对不同的数据采用不同的方法,科学地对数据对症下药,这样才能把原始数据处理的适用于数据挖掘。
