一种基于Newton迭代法的累积Logistic回归模型参数估计
2020-02-15印明昂王钰烁孙志礼
印明昂, 王钰烁, 孙志礼, 郭 兵
(东北大学 机械工程与自动化学院, 辽宁 沈阳 110819)
累积Logistic回归又称为有序多分类Logistic回归、次序Logistic回归[1],其具有模型变量少、分类效率高的特点.近年来,该方法在医药、金融及制造等领域得到了广泛的应用.文献[2]选取2015年3月至2017年4月接受培非格司亭(Pegfilgrastim)联合化疗的166例癌症案例,采用多变量有序Logistic回归分析,确定符合Pegfilgrastim预防以维持相对剂量强度的预测因素.文献[3]基于发动机健康变化的Logistic回归模型,实现了贝叶斯状态估计的健康状态序列更新,进而预测引擎未来的健康变化.文献[4]通过审查2003至2011年外来资本流入的综合影响,检验了次序Logistic回归模型应用于基于柯布-道格拉斯生产函数的实证经济增长研究的可行性.
在应用领域日益扩展,数据数量和维度不断增大的现状下,目前,累积Logistic回归模型的参数估计通常采用统计学软件SPSS或SAS的自带功能实现.本文基于Newton迭代法提出一种累积Logistic回归模型的参数估计方法,对其中比较敏感的迭代初值选取及迭代过程Hessian矩阵奇异问题进行了自适应控制,最后利用美国凯斯西储大学轴承数据库(CWRU)[5]数据对该算法模型与SPSS模型进行了对比验证.
1 参数估计
1.1 迭代格式的构建
设(x,y)为有序J分类样本,其中输入观测值x为nM矩阵,n代表容量,M代表维度;有序输出观测值y为n1列向量,其元素yi,i∈{1,2,,n},yi可取值为1,2,,J.则第i个输入xi=[xi1,xi2,,xiM]的前j(j∈{1,2,,J})类累积Logistic表达式为[6]
(1)
其中:p(yi≤j|xi)为累积概率(简记为pij),且有p(yi≤J|xi)=1;αj为截距,对于累积Logistic模型共有J-1个;βm为回归系数,所有分类的系数相同.由此可得
(2)
则该输入属于第j类的概率为
(3)
最后由概率最大者确定其所属类别.不妨设Y为n×J矩阵,其元素yij为
(4)
则它的对数似然函数可表示为
(5)
由Newton迭代公式得到迭代格式:
bk+1=bk-H(bk)-1f(bk) .
(6)
(7)
(8)
H(bk)元素如下
pij-1(1-pij-1)];
(9)
(10)
(11)
其中,r,j=1,2,,J-1;s,m=1,2,,M.
1.2 迭代初值的选取
Newton迭代法虽然具有平方收敛速度,但它对迭代初值非常敏感,如果选取不当往往会导致迭代发散.下面通过数学推导,给出一种初值的选取方法.
首先将数据归一化,使所有输入数据统一映射到[0,1]区间上[7],即
(12)
其中:xim表示输入i第m列的数据;xm为所有第m列数据组成的向量,i=1,2,,n,m=1,2,,M;min(·),max(·)分别表示向量中的最小、最大值.
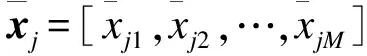
(13)
(14)
-fd1≤β0i≤fd1,i=1,2,,M.
(15)
由式(14)可推出:
(16)
其中,c=ln(1/p1-1) -ln(1/p2-1).进而有
α10>>α(J-2)0>α(J-1)0.
(17)
式(14)~式(17)给出了b0的大致范围.为进一步压缩区间,提高选取成功率,将b0分为三部分:b0=[α0T,β01T,β02T]T,其中α0=[α10,,α(J-1)0]T,β01=[β10,,βk0]T,β02=[β(k+1)0,,βM0]T,k[1,J].将式(14)的第一和最后一式进行缩放:
(18)
(19)
其中fd2=M·fd1.设α0,β01已知,代入式(14)整理为关于β02的不等式组:
(21)
算法描述见算法1.
算法1 迭代初值的选取
输入x,fd1,k.
2) 区间[-fd1,fd1]内随机生成β01;
3) 以式(19)计算区间,在该区间内随机生成α0;
4) 将α0降序处理,判断式(16)是否成立.若是,转步骤5);若否,转步骤2);
5) 以式(15),式(20)为约束,判断式(21)是否存在最优解.若是,得到β02,结束;若否,转步骤2).
输出b0=[α0T,β01T,β02T]T.
通过此算法得到的b0即可作为Newton法的迭代初值.
1.3 迭代过程的控制
虽然得到了较好的迭代初值,但是在迭代过程中可能会出现如下情况:
1)αk+1元素之间大小关系错乱;
2)βk+1与βk之间差距过大.
这些问题会导致Hessian矩阵奇异,迭代失败.通过分析,这些情况通常是由步长Δk=H-1(bk)·f(bk) =[Δαk; Δβk]过大造成.下面给出一种自适应控制方法.
当出现情况1)时,利用下式减小步长:
bk+1=bk-w·Δk.
(22)
其中,w为调整系数,初值为1,一旦常系数在k+1次迭代不满足次序条件时便将w赋值为w/2,重新计算bk+1.
为防止情况2)的出现,需重点控制Δβk+1元素之间的差距.设置阈值td,令u=max(|Δβk+1|).若u大于阈值td,则需要对其进行约束:
(23)
其中:放大系数fd3推荐为1.2~1.5;阈值td为1~2.
算法描述见算法2.
算法2 迭代过程的控制
输入b0,fd3,td,收敛阈值ε.
1) 初始化参数k=0,w=1;
2) 利用迭代格式(6)计算bk+1;
3) 判断αk+1元素间大小关系是否正确.若是,转步骤4);若否,w=w/2,通过式(22)调整,转步骤3);
4) 判断u=max(|Δβk+1|)是否在阈值td之内.若是,转步骤5);若否,通过式(23)调整,转步骤3);
输出bk+1.
算法2中的“=”为赋值符号.由于算法1已保证了α0的顺序,因此只要w调整适当,总会保持αk的大小关系不变.
2 滚动轴承健康状态评估实例
文献[9]通过非线性时间序列Logistic模型,验证了检测滚动轴承非线性突变信号的敏感性和有效性,因此本文也以轴承健康状态评估为例.选取美国凯斯西储大学轴承数据库[5]中采样频率为12 kHz,负载为0,正常状态和滚动体故障(通过电火花加工设置故障,火花点直径为0.177 8,0.355 6,0.533 4 mm,分别模拟轻微磨损、一般磨损及严重磨损)的振动信号数据为原始数据,其中响应类别1,2,3,4分别表示正常状态、轻微磨损、一般磨损和严重磨损,模型建立过程如下.
首先,根据文献[10],提取振动信号中的30个特征,得到相应特征值,再利用逐步模型选择法,以Wald统计量为指标从中逐步筛选出8个主要特征:FC,F2,F5,F6,F7,F8,F9,F12;然后,利用文献[11]所述剔除离群点方法,从所有606组数据中筛选出有效数据597组;最后,通过本文方法和SPSS软件分别建立累积Logistic模型,所得回归系数如表1所示.

表1 不同模型的回归系数
根据回归结果,两种方法所得各系数在组内所占权重大致相同,且各自变量系数的正负符号相同,说明两种方法对于当前数据具有相同的解释性.模型评价指标数值结果见表2.
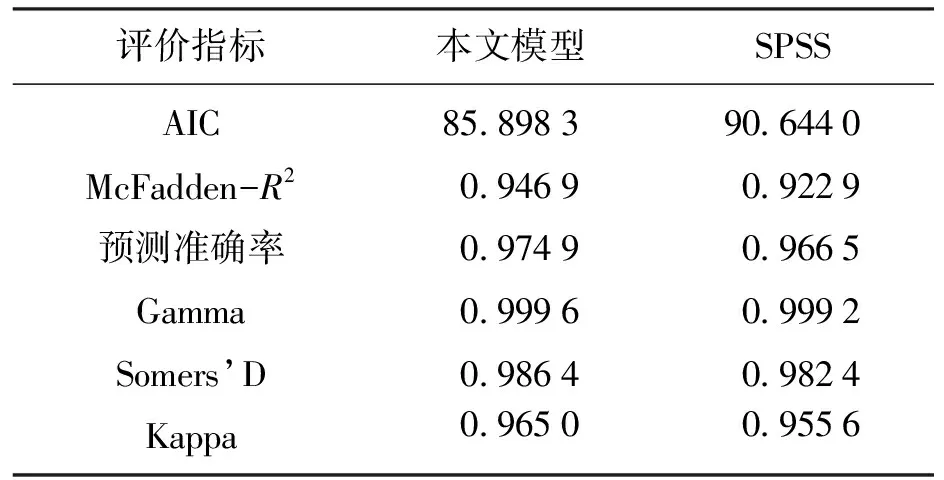
表2 不同模型的评价指标
表2中除赤池信息量AIC外,其余指标的数值越大越能证明模型的优势.可以看出,本文方法在各项指标上都更加突出,证明了该方法的有效性.为进一步验证稳健性,分别利用两种方法进行200次Booststrap随机试验.每次试验在正常、轻微磨损、一般磨损及严重磨损这4种类别中,分别随机选取25组共100组数据作为验证样本,其余作为训练样本.将试验结果制成柱状分布图.两方法的训练准确率及验证准确率如图1~图4所示.
由图1~图4可知,两种方法训练准确率和验证准确率的分布都大致符合正态分布;通过对比可以直观看出,本文方法无论训练准确率还是验证准确率,都处于更高水平,表明该方法具有较强的稳健性.
3 结 论
1) 通过自适应地选取迭代初值和控制迭代过程,避免了Hessian矩阵奇异的情况,使Newton迭代法能够有效地进行累积Logistic模型的参数估计.
2) 与SPSS累积Logistic回归模型数值结果对比,本文方法在各项模型评价指标上具有更高的水平,验证了该方法的有效性.
3) 基于200次的Booststrap随机试验对比,表明本文方法对于数据的依赖性较小,具有较强的稳健性.
