融合启发式搜索的改进极快决策树算法在多规格货物智能混合装载中的应用
2020-02-03杨超宇孟祥瑞
李 伟, 杨超宇, 孟祥瑞
(安徽理工大学经济与管理学院, 淮南 232001)
在物流管理中,货物装载是一个极为重要的环节。货物的装载情况决定了物流配送的运输成本和订单的时间成本。由于需求的货物各不相同,即涉及多规格货物的混合装载问题。为了提高运输过程中集装箱的利用率和货物装载效率,目前已有很多学者对其进行了研究。
从提高集装箱利用率出发,George等[1]最先提出了基于“层”概念的启发式算法,提高了集装箱的横截面利用率;Gonçalves等[2]研究了有偏随机密钥遗传算法,通过利用箱内的空闲空间极大提高了箱子的利用率;Yang等[3]和Hifi等[4]提出了基于整数线性规划启发式的简单策略求解三维装箱问题。刘胜等[5]提出了启发式树搜索算法,显著提高了集装箱的利用率;那日萨等[6-7]利用了三维装箱问题的多目标混合整数规划模型,给出了一种启发式搜索算法的求解方法;朱莹等[8-9]针对集装箱船装载提出了一种新型的混合遗传算法,明显提高了空间利用率;崔会芬等[10]提出了一种改进的遗传算法,提高了集装箱的装箱效率。
从提高装箱效率出发,尚正阳等[11]通过剩余空间最优化算法可以快速计算装箱结果;郑琰等[12]基于空间管理思想,将“砌墙”式建构算法与一种四规则深度优先搜索法相结合,在提高集装箱利用率的同时缩短了计算时间;张雅舰等[13]针对现有遗传算法求解装箱收敛速度慢的问题,提出了一种改进的遗传算法,提高了计算速度;张钧等[14]提出了混合遗传模拟退火算法,对强异构和弱异构货物都有很好的装载效果;廖星等[15]采用自适应权重法改进了粒子群优化算法,大幅加快了计算速度;崔雪莲等[16]采用树搜索策略,以空间切割、货物组块及装载套数迭代法为基础,构建了一种启发式搜索算法,提高了装载效率和算法实用性。
现有的货物装载问题的研究方向大致是提高集装箱利用率和提高装箱效率两个方面。针对这两个方向提出了以极快决策树为主,空间合并和装载空间再利用为辅的启发式搜索算法。在保证集装箱利用率的前提下,提高货物的装载效率。
1 问题及目标描述
1.1 问题描述
多规格货物装载是指将货物大小、尺寸不同的待装货物装载到固定尺寸的集装箱内。由于货物的尺寸不同,每装入一个箱子可能产生不同的剩余空间,若不考虑货物装载后产生的空间问题,很容易造成空间浪费。在装载过程既要保证集装箱的利用率又要保证货物装载的高效性,相比单一货物的装载,其条件限制更多。
1.2 目标描述
为使研究目标更直观,将目标描述如下。
给定一个集装箱C和一系列待装货物的集合B,假设集装箱和待装货物均为长方体。集装箱的长为L,宽为W,高为H,体积V=LWH;每个待装货物bi的长为li,宽为wi,高为hi,体积vi=liwihi。目标是在集合B中寻找一个子集F,使得集装箱C的空间利用率最大,即
max fitness=VF/V=∑liwihi/V
(1)
并且满足以下约束:
(1)任何bi∈F在集装箱C中都有一个装载位置。
(2)F中的任意两个箱子的装载位置都不能重叠。
(3)所有bi∈F中的箱子都必须可以放入在C中。
(4)稳定性约束,即每个被装载的箱子必须有容器底部或者其他已经装载的箱子作为支撑。
2 融合启发式搜索的改进极快决策树智能装箱算法
本文算法是在极快决策树(extremely fast decision tree,EFDT)上融合了启发式搜索算法(heuristically search,HS)形成了融合启发式搜索的改进极快决策树智能装箱算法(EFDT-HS),此算法首先计算并择优选取样本信息熵,然后构建生成货物装箱决策树模型,最后基于启发式搜索方法对货物装载后的剩余空间进行合并再利用。
2.1 极快决策树算法
极快决策树是HATT(hoeffding anytime tree)的系统实现[17]。HATT是由HT(hoeffding tree)改进得来的VFDT(very fast decision tree)发展而来[18]。追根溯源,HT与HATT的本质都是决策树。
2.1.1 度量标准
(1)信息熵。
在决策树的生成中,获得信息量的度量方法是从反方向来定义的。若一种划分能使数据的“不确定性”减少的越多,意味着该划分能获得越多的信息。采用度量不确定性的方法是信息熵,即
(2)
对于具体的随机变量y生成的数据集D={y1,y2,…,yN}而言,在实际操作中通常会利用经验熵来估计真正的信息熵,即
(3)
这里假设随机变量y的取值空间为{c1,c2,…,ck},pk为y取ck的概率:pk=p(y=ck);|ck|为有随机变量y中的类别为ck的样本个数;|D|为D的总样本个数,即|D|=N。
(2)信息增益。
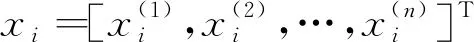
单一特征的情况(n=1):设特征为A,数据集D={(A1,y1),(A2,y2),…,(AN,yN)};此时所谓信息的增益,反映的就是特征A带来的关于y的“信息量”的大小。
引入条件熵H(y|A)[式(4)]的概念来定义信息的增益。所谓条件熵,就是根据特征A的不同取值{a1,a2,…,am}对y进行限制后,先对这些被限制的y分别计算信息熵,再把这些信息熵(一共有m个)根据特征取值本身的概率加权求和,从而得到总的条件熵。换句话说,条件熵是指被A不同取值限制的各个部分的y不确定性并以取值本身的概率作为权重相加得到的。所以,条件熵H(y|A)越小,意味着y被A限制后的总的不确定性越小,从而更易做出决策。
(4)
其中:

log2p(y=ck|A=aj)
(5)
为经验条件熵。
根据条件熵的直观含义,信息的增益就可以定义为
g(y,A)=H(y)-H(y|A)
(6)
(3)霍夫丁边界。

2.1.2 计算思想
(1)快速决策树。
快速决策树(very fast decision tree,VFDT)通过Hoeffding不等式实现从无限的样本中通过有限的样本在一定的置信度以内找到符合条件的决策节点属性。VFDT决策树的生长是样本通过叶子节点时,叶子节点保存样本的属性值,当叶子节点内的属性值符合Hoeffding不等式的要求,也就是其中一个属性的信息熵差值大于预先计算好的阈值,就可以判定该节点的属性,从而叶子节点再继续生长。样本从根结点开始,根据其属性不断划分遍历直到叶子节点,叶子节点保存其属性值用来判定。随着数据流中的样本在决策树的各个节点的遍历,叶子节点的属性统计值不断更新。
(2)极快决策树。
EFDT作为HATT的系统实现,是通过Hoeffding不等式来确定在最佳属性上进行拆分的信息熵是否超过没有拆分的信息熵,或者当前拆分属性的优点。在实践中,如果一个节点上不存在分裂属性,那么当最优候选属性的性能超过次优候选属性时,HATT将在最优候选属性带来的信息增益为非零且具有所需的置信度时进行拆分,而不是只在最优候选属性的性能优于次优候选属性时进行拆分。且当前最优属性和当前拆分属性之间的信息增益差异非零时,HATT将进行分割,并假设这比没有分割要好。
总而言之,VFDT是通过设定一个阈值,选取信息熵大于这个阈值的节点作为叶节点;EFDT是通过计算样本数据中每个样本的信息值,在满足Hoeffding不等式的前提下选择相对上一节点信息增益不为零且在样本中信息增益最大的节点为叶节点,即择优选取。
引用极快决策树的择优思想。在集装箱装载时,把每一层的装载看作一棵树的形成,把每个要放入的箱子看作一个叶节点,在满足条件约束的情况下,选择体积最大的箱子装入。
2.2 启发式算法
启发式算法是人们在解决问题时所采取的一种根据经验规则来处理问题的方法。其特点是在解决问题时,利用过去的经验,选择已经行之有效的方法去寻求答案。
启发式算法的设计具有很大的随意性和创造性,而且一般缺少严格的理论推导和数学证明,因此,一般也只能通过大量的试验数据来检验算法的性能好坏。由于对于完全类的组合优化问题,目前缺少一般的算法来求解,精确算法又太耗时,因此启发式算法被越来越多的应用到这些问题的求解中[19]。对于装箱问题也是如此,自从该问题被提出以来,学者提出了很多应用于装箱问题的启发式算法。车玉馨[20]的三维块生成算法是将Zhu等[21]提出的块生成算法中的块分为简易块和通用块,使两种块相互组合生成新的更符合装载空间的长方体。
货物装载过程中存在不同的情况,一种是货物装载过程中可以把两种不同类型货物完美组合,使空间利用率达到100%;另一种是货物装载过程中两种类型货物组合后仍有剩余空间,于是在待装货物中寻找符合剩余空间的货物块,三种或多种类型货物块的相互组合,使空间得到充分利用。在利用右图思想的同时考虑到放入的货物的宽度和高度会小于上一装载的货物,于是在货物装箱过程中考虑了“空间合并”和“装载空间再利用”的启发式算法。
2.2.1 空间合并
在上一节提到要将每一层的装载看作一棵树的形成,在每一层的装载中都可能会有剩余的长度,为了充分利用每一层的剩余长度,采用了上下剩余空间合并的方法。上下空间合并分为如图1所示三种情况。
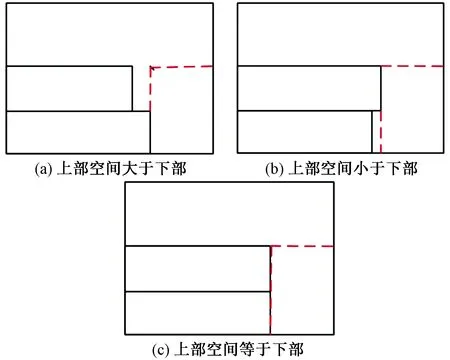
图1 上下空间合并Fig.1 Upper and lower space merge
(1)当前装载层的剩余长度大于上一装载层的剩余长度,如图1(a)所示。在这种情况下,以较短的上一装载层的剩余长度为剩余空间的最大长度,以这一装载列最底层根节点的宽度为最大宽度,以要合并的两层装载空间根节点的高度之和为最大高度。在待装货物中判断是否有符合此空间的货物。
(2)当前装载层的剩余高度小于上一装载层的剩余长度,即图1(b)所示。在这种情况下,以较短的当前装载的剩余长度为剩余空间的最大长度,以这一装载列最底层根节点的宽度为最大宽度,以要合并的两层装载空间根节点的高度之和为最大高度。在待装货物中判断是否有符合此空间的货物。
(3)当前装载层的剩余高度等于上一装载层的剩余长度,即如图1(c)所示。在这种情况下,以较短的当前装载的剩余长度为剩余空间的最大长度,以这一装载列最底层根节点的宽度为最大宽度,以要合并的两层装载空间根节点的高度之和为最大高度。在待装货物中判断是否有符合此空间的货物。
2.2.2 装载空间再利用
由于是多规格货物装载,很有可能出现上一个装载货物要比下一个装载货物宽或者高,于是提出了装载空间再利用的想法,目的是尽可能地把空闲空间利用起来。装载空间再利用分为如图2所示两种情况。

图2 上部剩余空间利用、平行剩余空间利用Fig.2 Upper residual space utilization, parallel residual space utilization
(1)当前装入的货物高度小于上一装载货物的高度,即图2(a)所示,在这种情况下,以当前放入货物的长度为最大长度,以当前装载层根节点的宽度为最大宽度,以当前装载层根节点与当前放入货物的高度差作为待利用空间的最大高度。在待装货物中判断是否有符合该利用空间的货物。
(2)当前装入的货物宽度小于上一装载货物的宽度,即图2(b)所示,在这种情况下,以当前装载层根节点与当前装入的货物的宽度差作为最大宽度,以当前装入货物的长度作为最大长度,以当前装载层根节点的高度作为最大高度。在待装货物中判断是否有符合该利用空间的货物。
2.3 融合启发式搜索的改进极快决策树智能算法在装箱问题的应用
在集装箱中把每一个装载层的装载过程看作一棵树的创建过程。
将集装箱看作三维坐标系,假设x轴为集装箱的长,y轴为集装箱大的高,z轴为集装箱大的宽,从最里面靠左开始装载,先沿x-y面进行装载,x-y面装载完成后再沿z轴增加一列继续沿x-y面进行装载。
在对货物进行装载时,把装载情况分为两种:底层装载和非底层装载。
2.3.1 底层装载函数
底层装载,即此时装载层的长度占用为0,高度占用也为0的情况,反映到坐标系中即为x=0,y=0的情况。底层装载函数步骤如下:
步骤1初始装箱,选取待装货物中体积最大的货物作为装入的第一个货物,作为根节点。读取此货物的长宽高,计算当前装载层的剩余长度、最大宽度、最大高度、剩余宽度。
步骤2在剩余待装货物中取出符合剩余长度、最大宽度、最大高度的箱子,计算这些箱子的体积,并按照箱子编号和对应体积降序排列。取体积最大的箱子装入。在装入每层非第一个箱子后,都判断装入箱子的上部空余空间和平行剩余空间是否还能放入箱子(箱子可旋转)。
步骤3更新此装载层的剩余长度,重复步骤2,直到没有满足的箱子。
步骤4返回装箱结果、待装货物、此装载层的最大宽度、剩余空间的长度、集装箱剩余高度、集装箱的剩余宽度。
2.3.2 非底层装载函数
非底层装载,即此时装载层长度占用为0,高度占用不为0的情况,反映到坐标系中即为x=0,y≠0的情况。非底层装载函数步骤如下:
步骤1取出符合剩余高度、最大宽度的箱子,并计算这些箱子的体积,按照箱子编号和对应的体积降序排列。取体积最大的箱子装入,作为根节点。
步骤2读取根节点货物的长度和高度,即为当前装载层的最大高度,计算此装载层的剩余长度、集装箱此列的剩余高度。
步骤3在剩余待装货物中取出符合剩余长度、最大宽度、最大高度的箱子,计算这些箱子的体积,并按照箱子编号和对应体积降序排列。取体积最大的箱子装入。在装入每层非第一个箱子后,判断装入箱子的上部空余空间和平行剩余空间是否还能放入箱子(箱子可旋转)。
步骤4更新此装载层的剩余长度,重复步骤3,直到没有满足的箱子。
步骤5读取此装载层的剩余长度,若上一步装载层的剩余长度大于0,则合并上下两层的高度,得到一个新的空间,返回新空间的长宽高,遍历剩余装箱货物,若有符合合并空间的货物则取体积最大的一个放入,并将此装载层的剩余长度重置为0。(箱子可旋转)
步骤6返回装箱结果、待装货物、此装载层的最大宽度、剩余空间的长度、集装箱剩余高度。
2.3.3 函数的应用
在集装箱剩余宽度不为零且待装货物中有符合条件的箱子时:
步骤1执行底层装载函数
步骤2执行非底层装箱函数,在剩余高度大于0的前提下,循环执行非底层装箱函数,直到没有符合剩余高度的箱子为止。
步骤3沿y轴增加一列,继续执行步骤1、步骤2,直到没有符合y轴剩余宽度的箱子为止。
3 实例计算与结果分析
基于Python程序、Django框架和JavaScript实现了该算法并可对装载结果进行三维展示。为验证提出方法的有效性,采取OR-Library[22]中BR1~BR7算例数据进行测试,7个算例中每个算例包含100个子算例且每个子算例箱子种类数分别为3、5、8、10、12、15、20,异构性从弱到强,实例计算中所用集装箱尺寸为587 cm×233 cm×220 cm。通过Python程序分别对7组算例进行计算,算例结果如表1所示。
由表1对比可知,异构性逐渐增强,体积利用率也不断增加,且计算时间较短并基本保持不变。

表1 BR1~BR7计算结果
对于OR-Library(http://people.brunel.ac.uk/~mastjjb/jeb/or-lib/thpackinfo.html)中国际装箱数据的700个算例,许多学者也对其进行过测试。比较的算法包括混合模拟退火算法(hybrid simulated annealing,HSA)[22]、可变邻域搜索算法(variable neighborhood search,VNS)[23]、最新的基于整数拆分的树状搜索算法(container loading by tree search,CLTRS)[24]、FDA(fit degree algorithm)算法[25]以及多层启发式算法(multi-layer heuristic search,MLHS)[26]。上述不同算法计算了BR1~BR7货物装入集装箱的集装箱体积利用率。自适应权重POS算法(adaptive weighting particle swarm optimization,AWPOS)、标准POS(particle swarm optimization,POS)、遗传算法(genetic algorithm,GA)[15]以及混合模拟退火算法(HSA)[22]计算了BR1~BR7的货物装入集装箱的集装箱体积利用率和计算时间。表2与表3分别为各算法BR1~BR7装入集装箱的集装箱利用率比较和利用率与计算时间比较,如图3所示为各算法对BR1~BR7的计算时间对比。
从表2可以看出,EFDT-HS的利用率虽然没有达到最优但始终保持增加的良好趋势。
由表3对比可知,本算法利用率在保持良好状态下,时间大幅度缩减。可见,本算法在保证货物装载率的情况下,实现了快速装箱。
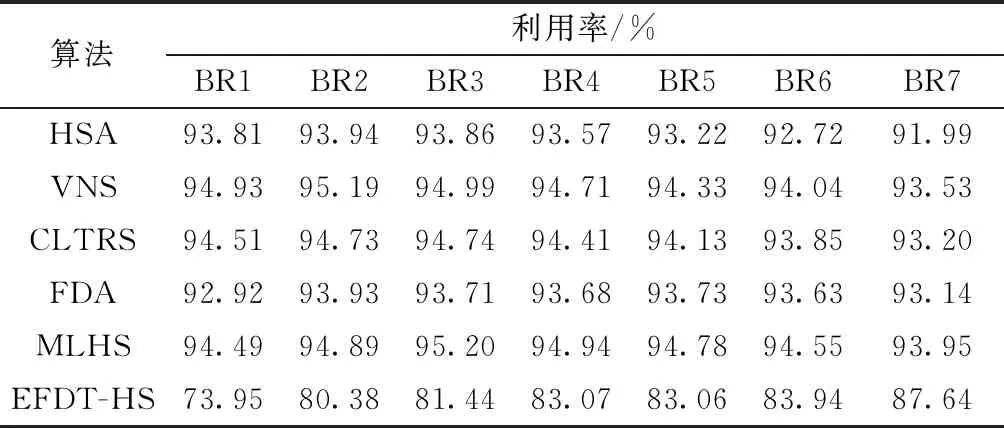
表2 各算法BR1~BR7的集装箱利用率比较

表3 各算法BR1~BR7集装箱利用率及计算时间比较

图3 计算时间对比Fig.3 Caculate time comparison
从图3可知,本算法需要的时间比起自适应权重POS算法(AWPOS)、标准POS(POS)、遗传算法(GA)以及混合模拟退火算法(HSA)这四种算法所需的时间几乎可以忽略不计,已经达到目前装箱效率最优。
通过不同算法对7组数据的比较结果来看,本文算法的利用率虽没有达到最优但一直保持较高状态且呈现增长趋势;在利用率与计算时间对比情况下,各算法随着货物异构性的不断增强计算时间不断增加,集装箱利用率也有所减少,而本文算法随着异构性的增强,利用率逐渐增加,计算时间一直保持在零点几秒,实现了货物的快速装载,并且本算法可以对装载结果进行三维展示,对货物进行装载后能够看到每个货物的装载位置。由于实验数据较多,只列出BR6及BR7算例中货物的集装箱装载结果图。图4(a)为BR6的装载结果图,图4(b)为BR7装载结果图。
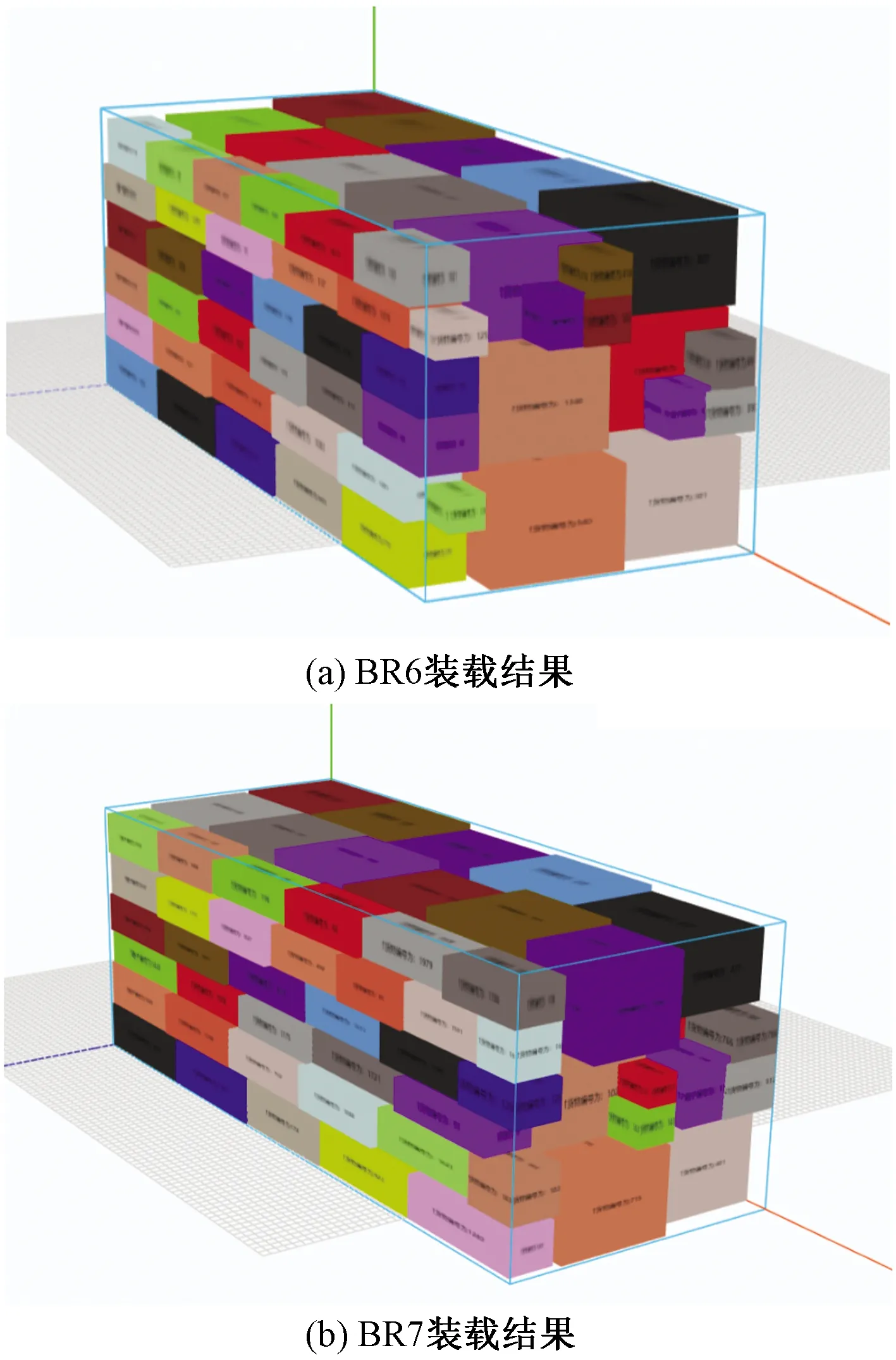
图4 BR6及BR7装载结果图Fig.4 Loading result of BR6 and BR7
4 结论
极快决策树与启发式搜索算法的结合使用,保证了每个装载层放入的货物体积最大,同时实现了对装入货物后的剩余空间进行再利用。经过对多种不同规格货物的测试,该算法在较短时间内取得了良好的装箱效果,证明了算法的有效性和可行性。本文算法中的空间合并和装载空间再利用方法模拟了人工装箱的过程,并通过具体的编程方法利用货物的装载顺序确定货物的装载位置,实现了集装箱装载结果3D展示和动态查看每个货物的装载位置的功能,为装载过程提供了智能化方案。多规格货物装载的特征主要是货物尺寸不同,不管是相邻放入的货物还是相邻两列的装载货物都会有类似间隙浪费等诸多复杂的情况,更多复杂情况有待进一步研究。
