基于语义分割的草场生长状态分析
2020-02-02土登达杰普布旦增仁青诺布
土登达杰 普布旦增 仁青诺布
(西藏大学信息科学技术学院 西藏自治区拉萨市 850000)
草地退化是当前草原生态系统面临的主要问题;鼠虫、农牧民过度放羊等问题对草原植被造成极大破坏,而且由于对地表的破坏往往造成大面积风蚀和水土流失。草原毛虫以牧草茎叶为食,严重时牧草被采食殆尽。自然场景下的草地生长状态目标小、背景干扰复杂等因素增加了草地区域检测的难度。传统的区域检测算法不能准确的检测出图像中草地所在的具体位置,而且较多的超参会导致算法泛化能力差。
近年来,随着深度学习技术[1][2][3]的快速发展,神经网络在多个计算机视觉任务上展示出了惊艳的效果,学者们相继使用神经网络替换原始的一些图像处理算法。卷积神经网络(CNN)[4][5][6]在图像处理领域得到了广泛应用。图像语义分割[7][8][9]是一个基础研究问题,学者们相继提出了多种性能优异的语义分割算法。同时学者门提出了FCN[10]、U-Net[11]、Deeplabv1[12]、Deeplabv2[13]、Deeplabv3[14]、Deeplabv3+[15]、PSPNet[16]、ICNet[17]、HRNet[18]、Fast-SCNN[19]等算法,这些成果对语义分割、多尺度分割操作、语义分割算法的鲁棒性和运行效率、快速且高质量分割等问题的解决带来很好效果。
本文主要工作是获取图像中草地所占区域的大小。传统的图像处理算法并不能很好的解决这个问题,受到卷积神经网络的启发,本文尝试使用语义分割算法来解决,首先使用标注好的数据训练一个语义分割模型,同时在训练过程中对HRNet 网络的架构和损失函数进行了改进;使用训练好的模型在新的测试图片上进行推理,从而获得图像中草地所在的具体像素点;最后对图像中的像素点进行统计并计算出草地所占面积和整个图像面积的比值,当这个比值大于设定的阈值时,则认为这块草地的生长状态比较良好,否则认为这片草地的生长状态比较差,应该对其加以保护。
1 基于语义分割的草地生长状态分析方法
基于语义分割的草地分割算法具有精度高、泛化性能好、抗干扰能力强等优点,用户仅仅需要提供少量带有标签的图像就可以获得一个草地分割模型,它不仅可以获得很高的分割精度,而且可以很好地应用到其它类似场景中。通过语义分割算法我们可以准确获取到图像中属于草地的每一个像素点,从而完成更加精准的统计和计算。综上所述,与传统算法相比,基于语义分割的草坪区域获取方法具有更多优点,能够更好满足待测试场景的需求。
1.1 模型结构简介
本文实现的语义分割算法的基本网络架构如表1所示。整个网络包含4 个阶段,每一个阶段包含一些重复的子模块,重复的次数分别为1、1、4、3 次。在阶段1 中,子模块包含1 个分支;在阶段2 中,子模块包含2 个分支;在阶段3 中,子模块包含3 个分支;在阶段4 中,子模块包含4 个分支。每一个分支对应于一个不同的分辨率,它由4 个残差单元和一个多分辨率融合单元块构成。表中‘[]’表示相应的残差单元,其中第二个数字表示这个残差单元的重复次数,最后一个数字表示整个模块的重复次数,C 表示通道个数。本文使用的残差块与ResNet 网络中的残差块相同,它不仅可以在一定程度上抑制网络发生梯度消失,而且可以协助网络获得更鲁棒的特征表示。除此之外,为了保持特征映射的分辨率不变,本文采用了类似HRNet 网络的思路,在网络搭建过程中,从高分辨率到低分辨率的过程中并行连接多个子网路,从而保证了网络在加深的同时,特征映射的大小保持不变。为了使网络获取到更加鲁棒的特征表示,能够获取更加丰富的语义和细节信息,在搭建网络的过程中不断交换不同分辨率的设备。由于本文关注的分割对象是草地,而很多现实场景中拍摄的图片中,草地比较杂乱,呈现不均匀分布,而且会遇到大量的干扰物,为了更好地捕获到草地的细节信息,本文改变了阶段1 和阶段2 的网络架构,网络的运行速度并没有受到影响,但是网络层之间的变换更加多样,实验结果表明这种改变可以更好地获取到草地的一些纹理信息,可以在一定程度上改善语义分割算法的效果。
1.2 模型训练
通常训练语义分割模型的数据包含每个图像中的标注多边形及其所属的类别信息。由于标注质量会极大影响模型的最终效果,因而本文使用labelme 对图像进行了严格的标注,并将这些标签转换为不同的颜色映射,方便后续的可视化。本文所实现的语义分割模型在训练过程中包含很多超参,这些超参会对模型的精度产生较大的影响。表1展示了一些关键参数。
语义分割任务,可以被看作一个像素点分类问题,语义分割网络的输入是一个512×512×3 的彩色图像,网络通过一个特定大小的特征映射将其映射到特定的特征空间,最后再通过一个函数将其映射为一个概率值。我们通常使用softmax 损失函数来完成输出到概率值的映射,具体计算公式如式(1)所示。其中y 表示相应的标签,p 表示网络的预测输出,s 表示softmax loss。

表1:语义分割网络架构

大量实验结果表明,虽然softmax 可以完成模型训练的任务,但是在有些情况下使用该损失函数并不能获得好的训练结果。为了获得较高的精度,本文实现了多种损失函数,具体包括Weighted softmax loss、Dice loss、Lovasz hinge loss 等。Weighted softmax loss按照不同类别设置不同的权重,可以在一定情况下抑制类别不均衡的问题,本文动态设置不同类别的权重,即根据每个batch 中各个类别的数目动态调整类别权重。
针对草地分割问题,我们需要分割的类别包括草地和背景两类,而在大多数图片中都会出现类别分布不均匀的问题,即背景所占的区域一般远大于草地所占的区域。本文使用Dice loss 和Lovasz hinge loss 来解决这个问题。Dice loss 的定义如式(2)所示,其中Y 表示相应的标签,P 表示模型预测结果,||表示矩阵元素之和,|S|表示Y 和P 的共有元素数,d 表示Dice loss。

Lovasz loss 是基于子模损失的凸Lovasz 函数,该损失函数可以针对网络的mean IoU 损失进行优化。该损失函数的表达形式如式(3)所示:

通过大量实验,本文最终选择使用Lovasz hinge loss 和Dice loss 作为最终的损失函数,这两个函数分别包含一个超参
1.3 区域统计与状态分析
通过上面的方法我们可以获取到图像中草地所在的具体位置,在获取到图像中草地所属的像素之后,我们可以快速统计出图像中属于草地的像素点个数。具体计算公式如式(4)所示,其中n 表示图像中草地像素点的个数,img(i,j)表示图像中第i 行第j 列位置上的像素点,grassn表示最终的统计结果。

图1:数据样本

获取到图像中草地所占据的像素点后,我们就可以获取到草地在整个图像中所占据的比例值,再将计算获得的比例值和设置的阈值比较,如果该比例值大于该阈值,则表明这块草地的生长状态良好;如果该比例值小于该阈值,则表明这块草地的生长状态较差,应该对其加以保护。具体计算方法如式(5)所示,其中area(img)表示img 图片的面积,即整个图像总共包含多少个像素点,0.8 表示设置的阈值,good 表示当前草地的生长状态良好,不需要进行人为干预;bad 表示当前草地的生长状态较差,需要进行适当的人为保护。

2 实验分析
2.1 数据来源
本实验所使用的训练数据均来自项目组在拉萨、山南等地拍摄的真实图片。如图1所示,真实场景获取到的图像中的草地颜色杂乱、分布不均匀、周围会有很多干扰信息:图1(a)中的草地周围有一些干扰的干草和石块,草地的形状各式各样;图1(b)中的草地比较稀疏,不同草地之间没有连接,草的颜色各不相同;图1(c)中的草地包含大量的杂草和一些间隙和干扰物。通过上面的观察,我们可以发现输入数据具有较大挑战,对语义分割算法提出了很高的性能要求。为了提升算法的鲁棒性,我们在互联网中找了部分草地图片,具体效果如图1(d)所示,这些图片中的草地比较干净,仅存在一些其它的干扰,可以进一步提升语义分割算法的泛化能力。我们把真实拍照和网上获取一起组成的106 张图片构成了数据集,84张作为训练集实验数据、12 张作为验证集、12 张作为测试集。整个数据集采用Labelme 标注工具进行标注,并采用脚本将该数据集调整为Pascal VOC 数据集的格式。整个数据集中包含各种不同时间段、不同地方和不同角度拍摄的草地图片,图像中包含大量干扰信息,如干草、石块、垃圾、大理石等。
整个实验过程均在一台配有一块R7-4800H 显卡、一颗GTX2060 处理器、内存大小为16G 的Ubuntu 服务器上进行,使用百度开源的PaddlePaddle 深度学习训练框架完成网络的训练和网络的推理。

表2:不同语义分割算法客观指标展示

表3:不同损失函数效果展示

图2:算法效果展示
2.2 性能分析指标
为了对本文实现的针对草地的语义分割算法进行性能评估,实验中使用了多种常用性能分析指标,具体包括MPA、MIoU 和Kappa。MPA,即所谓的平均像素精度,它是对像素精度指标的一种提升,用来计算每一个类内被正确分类的像素数的比例,最后将所有类的平均值作为最终结果,具体计算公式如式(6)所示。MIoU 即平均交并比,它是在IoU 的基础上提出的一种评价指标,计算两个集合的交集和并集之比,即计算算法预测结果和标签之间的比值,首先计算出每一个类的IoU,然后对所有类的结果进行平均即可,具体计算公式如式(7)所示。Kappa 系数是一个用于一致性校验的指标,该系数的计算是基于混淆矩阵的,取值范围为[-1,1],该值越大表示语义分割的效果越好,具体计算公式如式(8)所示。
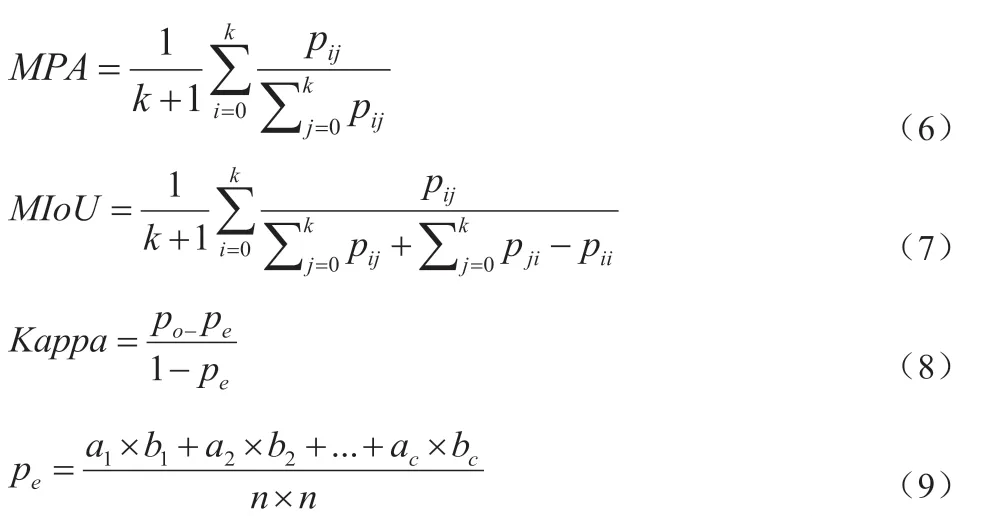
其中k 表示k 个类别,1 表示背景类,pij表示本来是i 类被预测为j 类的像素数量;pji表示本来是j 类被预测为i 类的像素数量;pii表示本来i 类被预测为i 类的像素数量。po表示每一类正确分类的样本数量之和除以总样本数,pe的计算公式如式2-4 所示。a1,a2,a3表示每一类的标签样本个数,b1,b2,b3表示每一类的预测样本个数,n 表示总体样本个数。
2.3 实验结果分析
本文实现的语义分割算法进行性能评估,经过大量实验,具体包括该语义分割算法和其它性能优异的语义分割算法的性能比较、不同损失函数的分割效果。具体评估方法包括主观指标评价和客观指标评价,我们不仅将不同语义分割算法在同样的测试图片上面的效果进行展示和分析,而且计算出不同模型的MPA、MIoU 和Kappa 数值。
表2展示了语义分割算法使用不同语义分割模型在测试图片上的效果,所有分割算法均采用相同的超参,batch_size=4,epoch=30。表中红色、绿色和蓝色结果分别表示第一名、第二名和第三名。通过观察我们可以发现,与其它state-of-the-art 算法相比,本文实现的语义分割算法能够在草地数据集上获得最好的分割结果,在MPA、MIoU 和Kappa 等多项指标中均获得了最佳的效果。
表3展示了语义分割算法使用不同损失函数训练之后的效果,在训练过程中除了更换不同的损失函数之外,所有的模型均保持相同的超参,batch_size=4,epoch=30。表中红色、绿色和蓝色结果分别表示第一名、第二名和第三名。通过观察我们可以发现,使用Weighted lovase 损失函数可以有效提升分割算法的精度,在MAP、MIoU 和Kappa 等指标中都取得了最好的结果。
图2是实现的草地语图像义分割算法和其它5 个语义分割算法在测试图片上的测试效果。通过观察我们可以发现,本文实现的草地图像语义分割算法可以在同样的训练参数下获得更高的分割精度,更鲁棒的分割性能。该算法分割出的结果更加接近真实标签文件,含有更少量的空洞区域,能够更好地区分一些干扰目标,达到了本文预期的要求。
3 结语
为了对高原地区草地生长状态进行评估,针对传统图像处理算法存在的精度低、鲁棒性差、抗干扰能力弱等缺点,本文尝试使用语义分割算法来解决整个草地图像分割问题和草地生长状态评估问题。首先使用一个改进网络架构和损失函数的语义分割算法获得草地图像分割结果;然后在该结果基础上对草地区域进行统计并计算草地的面积比;最后通过阈值比较确定这块草地当前的生长状态。该方法具有精度高、泛化能力强、抗干扰能力好等优点,可以广泛应用到草地生长状态分析的相关任务中。
