基于时序和距离的门控循环单元兴趣点推荐算法
2020-01-16夏永生王晓蕊李梦梦
夏永生,王晓蕊,白 鹏,李梦梦,夏 阳,张 凯
(1.中国矿业大学 计算机科学与技术学院,江苏 徐州 221116; 2.苏宁易购集团股份有限公司,南京 210042)
0 概述
智能手机、手环等多功能移动终端的广泛使用,使得用户的地理位置信息可以被轻易地获取到,因此,基于位置的移动社交网络(Location Based Social Network,LBSN)也逐渐发展起来[1-2]。在LBSN中,用户可以使用随身携带的智能设备进行签到,还可以对访问过的地点进行评分或评价,为要访问该地点的其他用户提供参考意见。这类地点可以是饭店、酒店、名胜古迹等,专指那些用户感兴趣的位置地点,即兴趣点(Point of Interest,POI)。
兴趣点推荐分析用户的签到信息,挖掘用户、兴趣点、兴趣点所在位置以及用户访问兴趣点的时间等模型,为用户推荐可能感兴趣的位置地点[3]。兴趣点推荐对于用户和兴趣点商家都有重要的现实意义。从用户角度,兴趣点推荐可以帮助用户有效地探索符合用户偏好的未访问过的地点,为人们的日常生活带来便利。从商家角度,兴趣点可以为企业吸引更多的潜在客户,为企业带来更多的商业利益。因此,兴趣点推荐算法研究具有一定的科研价值和实用价值。
相比于传统推荐算法,兴趣点推荐所包含的信息种类多种多样,如兴趣点的文本信息、兴趣点的地理坐标、用户的签到时间、用户的社会关系、兴趣点的流行度等,兴趣点的相关文本信息不同于传统推荐系统,其信息具有不完整性、模糊性[4]。利用LBSN中用户的多源异构签到数据,对用户进行兴趣点推荐成为当前的研究热点。
为捕捉地理因素影响,文献[5]将用户在某位置上签到的概率建模为一个多中心高斯模型(MGM),按照概率值为用户进行兴趣点的推荐。文献[6]从基于位置的社交网络抓取用户签到数据进行分析,发现用户会在不同的时间周期访问不同类型的兴趣点,并提出基于用户签到的时间分布来提取兴趣点特征的方法。基于兴趣点时间或距离的单维签到数据进行推荐,一定程度上提高了兴趣点推荐的准确性,但是没有考虑到两者之间的相关性,忽略了用户所处的地理位置往往随时间的变化而发生移动的特点。文献[7]使用隐含狄利克雷分布(Latent Dirichlet allocation,LDA) 模型,并基于用户的帖子或者兴趣点的标签来挖掘用户和兴趣点的主题属性,其中每个主题也是词的分布,然后利用主题属性和词分布来确定用户对于兴趣点的偏好分数。对于评分数据,一般采用协同过滤算法较多,文献[8-9]对评分数据的处理都运用了协同过滤推荐算法来进行兴趣点推荐。将用户对兴趣点的签到评分数据和评价文本融合到兴趣点推荐中,比仅利用用户个人信息进行的兴趣点推荐有更好的推荐性能,但是评分数据和评价文本大都非常稀疏,使得用户的真实偏好难以被充分挖掘出来,很难达到理想的推荐效果。此外,也有学者利用好友关系和兴趣点流行度进行兴趣点推荐。文献[10]提出基于朋友的协同过滤算法,其中用户间的相似度采用轨迹相似度,即将用户间的轨迹和距离作为幂函数计算,最后通过具有相似的签到偏好向用户进行位置的推荐。文献[11]提出融入时间信息的用户协同过滤兴趣点推荐算法,得到用户访问兴趣点的估算值;结合流行度和空间信息提出另一种估算方法,将2个估算值进行线性组合,作为用户访问兴趣点的估算值。
本文借鉴门控循环单元对序列数据建模的有效性,对用户访问兴趣点中的时序信息进行建模,利用用户访问兴趣点之间的连续时间和连续地理位置信息,提出基于时序和距离的门控循环单元兴趣点推荐方法TD-GRU。
1 相关研究
综合兴趣点推荐算法的相关文献可以发现,与传统推荐算法相比,兴趣点推荐算法容易受地理位置、时间等因素的影响[12]。本节从地理位置因素和时间因素两方面介绍相关研究,同时介绍门控循环单元模型。
1.1 基于地理位置因素的推荐算法
在兴趣点推荐中,地理位置因素发挥着非常重要的影响。文献[13]研究发现用户的签到位置与距离呈反比,即距离当前位置越近的兴趣点,越容易被用户签到。因此,在位置推荐算法中设定了距离的阈值,过滤掉签到位置距离超过阈值的兴趣点,以此提高推荐性能。文献[14]将地理位置近邻引入偏向矩阵分解算法以提高兴趣点推荐的准确性。针对空间聚类现象,文献[15]利用用户的活动区域向量和影响POI的区域向量来增加用户和POI在矩阵分解模型中的潜在因素。文献[16]将用户签到位置之间的距离视为高斯分布模型,其中主要将用户签到位置划分为在家周围和工作地点周围2个状态,采用二维的时间独立的高斯模型,将地理因素和时间的阶段性有效结合。除高斯分布模型外,对于地理位置因素,最常用的是幂律分布。文献[17]假设用户签到位置之间相互独立,将用户签到下一位置的意向转换为距离的幂函数,以此进行位置的推荐。在此基础上,研究人员从一维的距离函数转向为二维的核密度估计,利用位置的经纬度坐标,进行非参数估计,避免了提前设定函数的局限性,更能体现用户签到的个性化和推荐的个性化特征[18]。
1.2 基于时间因素的推荐算法
在用户的签到信息中,时间因素往往起到非常重要的作用,用户在不同时间点会在不同的兴趣点签到[19]。文献[20]将用户签到矩阵划分为各个时间下的子矩阵,并利用非负矩阵分解将各个子矩阵分解成相应时间状态下的用户签到偏好矩阵和位置特征矩阵,再集成各个时间下的用户签到偏好,最终得到用户对兴趣点的签到偏好。另外,还包括将用户历史评分数据的时间和预测目标兴趣点签到时间之间的时间间隔作为一个衰减因子[21]来衡量评分数据。文献[22]提出基于马尔可夫链模型的序列预测算法FPMC,在MC的基础上将所有用户的转换矩阵的张量因式分解,并通过基于马尔可夫链假设计算转换概率来预测下一个位置。2013年,一种新的矩阵分解方法被提出,即FPMC-LR[23],该方法嵌入了个性化马尔可夫链和局部区域,不仅在签到序列中利用个性化马尔可夫链,而且还考虑到用户的移动约束,即在局部区域周围移动。文献[24]采用周期时间模式,将一天的时间按照一定的单位划分为若干个相等的时间槽,根据时间槽对用户签到位置历史进行划分和研究,提出基于用户签到的时间分布来提取兴趣点特征的方法。
1.3 门控循环单元模型
用户访问兴趣点的时间信息反映了用户行为的时间序列模式,引入时间信息有利于提升兴趣点推荐系统的性能。循环神经网络模型(Recurrent Neural Network,RNN)的提出正是被用于建模序列数据,因此很快被引入到用户行为序列模式建模的研究中[25]。本文利用循环神经网络对用户访问兴趣点的时间信息进行处理获得用户偏好的隐表示,用作下一步对用户兴趣点的推荐。
循环神经网络是一类专门用于处理时序数据样本的神经网络,具体的表现形式为:网络对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点是有连接的,并且隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出。文献[26]采用循环神经网络建模用户偏好和项目特征的演化,提出了一种循环推荐网(Recurrent Recommender Network,RRN)来预测用户未来的行为轨迹。理论上,RNN可以对任意长度的时间序列进行记忆,但是随着时间跨度的不断增大,RNN会丧失对远处单元的记忆能力。这样会导致提取到的用户兴趣点偏好更多地依赖用户近期访问的兴趣点,不能全面刻画用户兴趣点偏好。长短期记忆网络(Long Short Term Memory,LSTM)和门控循环单元(Gated Recurrent Unit,GRU)作为RNN的变种,通过使用门结构来改善RNN短期记忆的缺点,在保留长期序列信息下减少梯度消失问题。文献[27]提出一种深度递归神经网络的文本推荐方法,利用GRU 学习文本内容的向量表示,对改善数据稀疏性和冷启动问题很有帮助。文献[28-29]对比了 LSTM 和 GRU 以及传统的 RNN 的异同,探讨了上述结构的优点,另外通过实验证明了在个数参数相同的情况下,GRU 优于 LSTM。因此,本文利用GRU来处理用户访问兴趣点的时间信息,GRU模型的基本结构如图1所示。
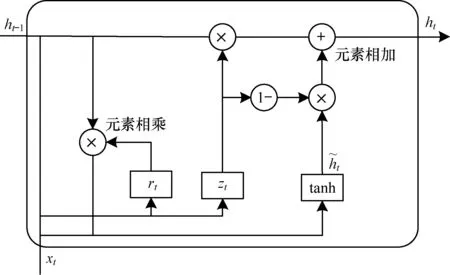
图1 GRU模型基本结构
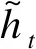
rt=σ(xtWxr+ht-1Whr+br)
(1)
zt=σ(xtWxz+ht-1Whz+bz)
(2)
(3)
(4)
其中,Wxr和Whr是重置门的权重参数,Wxz和Whz是更新门的权重参数,Wxh和Whh是候选隐藏状态的权重参数,br、bz、bh是偏置参数,⊙是元素乘法符。将用户访问兴趣点的时间序列作为GRU的输入,提取用户的兴趣点偏好特征,并以此进行兴趣点推荐。
2 TD-GRU推荐模型
在兴趣点推荐算法中,基于连续时间因素的研究较少。在兴趣点推荐中,所有的POI都具有位置属性,而且用户行为具有时序性,将时序信息和距离信息融入兴趣点推荐算法,有利于提高推荐的准确性。针对循环神经网络可以建模序列数据的优势,将门控循环神经网络引入兴趣点推荐算法,提出基于时序和距离的门控循环单元兴趣点推荐算法,以提高兴趣点推荐的准确性。
2.1 TD-GRU模型描述
用户访问兴趣点之间的连续地理位置距离和时间间隔对于推荐用户将要去的兴趣点是十分重要的,如用户在昨天去了电影院,那么很有可能需要去电影院附近的餐厅就餐;用户连续几个周日去了教堂,那么下周日可能还会去教堂。因此,将用户访问兴趣点序列中的时间和地理位置加入兴趣点推荐算法是十分必要的。通过对用户访问兴趣点时间序列中的局部时间间隔和兴趣点之间的距离进行建模,可以得到用户在局部时间的兴趣偏好和连续时间中用户的周期性偏好行为,进而进行兴趣点推荐。
由于GRU是RNN的一种,不可将连续的时间间隔加入到模型中,因此需要对时间序列进行一些处理,本文将时间离散化,用时间间隔ω作为时间因子,代入GRU模型,提出TD-GRU兴趣点模型,如图2所示。

图2 TD-GRU模型
在图2中,C表示兴趣点集合,U表示用户集合,ult表示用户u在t时刻访问兴趣点l的嵌入表示,用户访问过的兴趣点历史Ul={ul1,ul2,…},S和T分别表示特定距离转换矩阵和特定时间转换矩阵。
根据GRU的基本结构,在t时刻,新的候选状态为:
(5)
其中,Wc1、Wc2为模型参数,Ult为在lt位置点的嵌入表示,ft是重置门开关,ht-1为上一个输出的嵌入表示,bc为偏置向量。由于GRU不能很好地处理连续时间内用户的访问历史,因此需要对时间序列进行巧妙处理,将时间划分为时间间隔,此时用户访问的兴趣点历史被划分为时间跨度相同的若干个兴趣点集合Ul={{ul1,ul2,ulω},{…},{ult-ω,…,ult}},引入特定时间转换矩阵,则有:
(6)
其中,ω为时间窗口长度,窗口内的每一个元素在模型内建模,Tt-ti则为当前时间t之前的时间间隔为t-ti的特定时间转换矩阵。矩阵Tt-ti捕捉了用户访问兴趣点历史中最新元素的影响,也将连续的时间间隔考虑入内。同时,考虑到距离因素对于兴趣点推荐的影响,对用户访问兴趣点的连续距离进行建模,将特定距离转换矩阵引入TD-GRU算法。特定距离转换矩阵用以衡量不同地点位置之间的地理距离,用来捕捉用户行为轨迹的地理属性,t时刻的候选隐藏状态表示为:
(7)
其中,SUlt-Ulti是根据坐标下2个地理距离Ul-Uli的特定距离转换矩阵,Ult表示在时间t下用户u正在访问位置的坐标,地理距离用欧几里得距离公式:
(8)
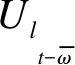
(9)
其中,h0表示初始状态,所有用户的初始状态相同,且在该状态下不存在任何用于个性化预测的行为数据。
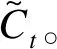
(10)
其中,it表示更新门开关,*代表分素乘积。更新门和重置门开关计算公式如下:
it=σ(Wi1Ult+Wi2ht-1+bi)
(11)
ft=σ(Wf1Ult+Wf2ht-1+bf)
(12)
其中,Wi1、Wi2、Wf1、Wf2分别为更新门和重置门参数,bi、bf表示更新门和重置门的偏置向量。t时刻的输出表示为:
ht=tanh(Ct)
(13)
ht捕捉了用户u在特定时间特定空间下动态的兴趣点变化,至此,本文使用TD-GRU模型提取出用户访问兴趣点的局部偏好和连续时间序列中的周期性变化特征。
2.2 基于TD-GRU的推荐算法
在提取到用户访问兴趣点的特征偏好后,对于一个给定的兴趣点l,使用TD-GRU模型的输出值ht来计算用户访问该兴趣点的预测值:
(14)
其中,l是兴趣点的潜在向量表示,对于兴趣点集合L中的兴趣点进行访问预测值的计算,选取预测值高的兴趣点推荐给用户构成推荐结果集,由于在ht的计算过程中,引入了局部时间内用户访问兴趣点的特定时间转换矩阵和特定距离转换矩阵,因此其推荐的兴趣点符合用户的兴趣点偏好,且兴趣点集中在一定范围内。
算法1TD-GRU算法
输入记录用户信息的数据集M
输出推荐结果集R′
1.For each u∈U do//对某一个用户
2.For each ti∈(t-ω,t) do//设定时间窗口长度阈值
3.Strai=SUlt-Ulti//特定距离转换矩阵
4.Ttrai=Tt-ti//特定时间转换矩阵
5.A=A+StraiTtraiWc1Ult
6.End For
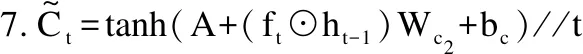
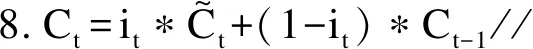
9.ht=tanh(Ct) //t时刻的输出
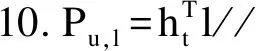
11.ltopN→R′//选取预测值高的兴趣点加入推荐集
12.End For
3 实验结果与分析
3.1 数据集
本文选取了2个LBSN数据集来验证算法的有效性,分别是最常用的Foursquare数据集和通过爬虫软件抓取的美团网数据集。首先对数据集进行预处理,将少于5条签到记录的用户和兴趣点剔除,Foursquare数据集和美团网数据集的具体统计信息如表1所示。
表1 Foursquare数据集和美团网数据集的统计信息
Table 1 Statistics information of Foursquare dataset and Meituan datasets
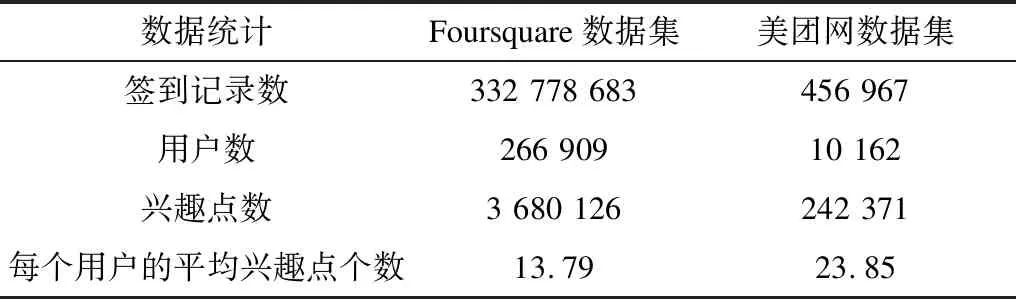
数据统计Foursquare数据集美团网数据集签到记录数332 778 683456 967用户数266 90910 162兴趣点数3 680 126242 371每个用户的平均兴趣点个数13.7923.85
在2个数据集中随机选择70%作为训练集,20%用于测试集,10%留作验证数据。为便于实验,将数据集进行预处理,整理用户集为U,兴趣点集为PPOI,时间集为T,位置坐标集为L。为便于计算兴趣点之间的距离,将其坐标化,每个地点l包含其坐标{xl,yl}。符号表示如表2所示。

表2 符号描述
3.2 对比算法
为验证本文提出的兴趣点推荐算法的有效性,选取如下的兴趣点推荐算法作为对比算法,以比较算法的性能。
1)TOP算法:是较早的基于位置推荐算法,直接为每个用户选择训练集中最受欢迎的位置作为预测。
2)MF算法:由MNIH和 SALAKHUTDINOV提出的基于用户位置矩阵协同过滤推荐算法,是传统的协同过滤方法之一。
3)FPMC算法:RENDLE等人提出的基于马尔可夫链模型的矩阵分解(Factorized Personalized MC,FPMC)算法。在基于马尔可夫链模型(Markov Chains,MC)推荐算法的基础上,将所有用户的转换矩阵的张量因式分解,并通过基于马尔可夫链假设计算转换概率来预测下一个位置,这也是目前最先进的推荐算法之一。
4)PRME算法:FENG等人考虑到学习嵌入需要将目标位置和最近的远程位置之间的距离纳入考量,提出个性化排名度量嵌入(Personalized Ranking Metric Embedding,PRME)方法。
3.3 评价指标
采用兴趣点推荐常用的准确率和召回率作为评价指标,然而,由于准确率和召回率往往相互制约,本文为评测算法的稳定性,采用了F1指标。F1指标是一种综合指标,为Precision和Recall的加权调和平均数,计算公式如下:
(15)
(16)
(17)
其中,R(u)表示对用户u进行推荐的兴趣点集合,T(u)表示用户u在测试集上实际的签到集合,N表示推荐列表的大小。
3.4 实验结果
本文在Foursquare数据集和美团网数据集进行了对比实验。对比算法包括TOP算法、MF算法、FPMC算法和PRME算法。评价指标为准确率Precision@N、召回率Recall@N和F1值,N取值为1、5、10、20。
图3和图4表示Foursquare数据集上TD-GRU算法、TOP算法、MF算法、FPMC算法、PRME算法之间不同推荐列表长度的准确率和召回率。在Foursquare数据集上,当推荐列表长度N取10时,TD-GRU算法准确率为8.7%,召回率为12.1%,而经典的矩阵分解MF算法的准确率为2.3%,召回率为5.1%,FPMC算法的准确率为5.3%,召回率为9.2%,PRME算法的准确率为5.9%,召回率为10.3%。相比之下,TD-GRU算法的准确率约是MC算法的3倍多,比FPMC算法、PRME算法分别高3.4%和2.8%。而TD-GRU算法的召回率是MC算法的2.3倍,比FPMC算法和PRME算法分别高2.9%和1.8%。

图3 Foursquare数据集上不同算法推荐列表长度的准确率
Fig.3Precision rates of different algorithms and recommended list lengths on Foursquare dataset

图4 Foursquare数据集上不同算法推荐列表长度的召回率
Fig.4 Recall rates of different algorithms and recommended list lengths on Foursquare dataset
图5、图6表示美团网数据集上TD-GRU算法与TOP算法、MF算法、FPMC算法、PRME算法之间不同推荐列表长度的准确率和召回率。在美团网数据集上,当推荐列表长度N取5时,TD-GRU算法准确率为5.2%,召回率为5.9%,而经典的矩阵分解MC算法的准确率为2.9%,召回率为2.9%,FPMC算法的准确率为3.7%,召回率为3.1%。PRME算法的准确率为4.3%,召回率为3.5%。相比之下,TD-GRU算法的准确率约是MC算法的2倍,比FPMC算法高1.5%,比PRME算法高0.9%。而TD-GRU算法的召回率是MC算法的2倍,比FPMC算法和PRME算法分别高2.8%和2.4%。

图5 美团网数据集上不同算法推荐列表长度的准确率
Fig.5Precision rates of different algorithms and recommended list lengths on the Meituan dataset
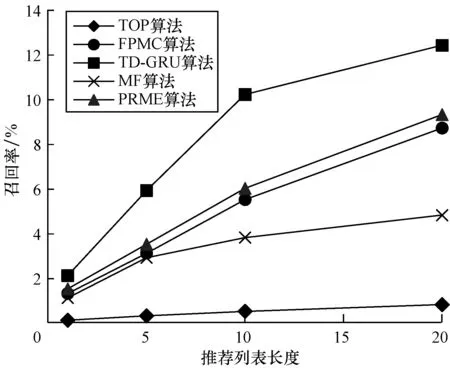
图6 美团网数据集上不同算法推荐列表长度的召回率
Fig.6 Recall rates of different algorithms and recommended list lengths on the Meituan dataset
从图3~图6可以看出,无论在Foursquare数据集上还是在美团网数据集上,TD-GRU算法的准确率和召回率都是5个算法中最高的。由此可见,相比于TOP算法、MF算法、FPMC算法、PRME算法,TD-GRU算法性能明显优于其他算法,说明该算法相比其他算法有效性更好,推荐更准确。整体上而言,无论在Foursquare数据集上还是在美团网数据集上,兴趣点推荐算法的准确率随着推荐列表长度N的不断增大而减小,而召回率则表现为随着N的不断增大而增大。为更直观地观察TD-GRU算法的整体性,本文还采用了F1指标,结果如图7和图8所示。从图7、图8可以看出,TD-GRU算法的F1指标随着推荐列表长度N的增大,均高于其他算法,说明其在整体性上明显优于其他算法。另外,在Foursquare数据集上,F1指标在N=10时出现最大值,表明为Foursquare网站的用户最好推荐10个兴趣点。而在美团网数据集上,F1指标在N=5时出现最大值,表明给美团网站用户推荐的兴趣点个数最好为5个。
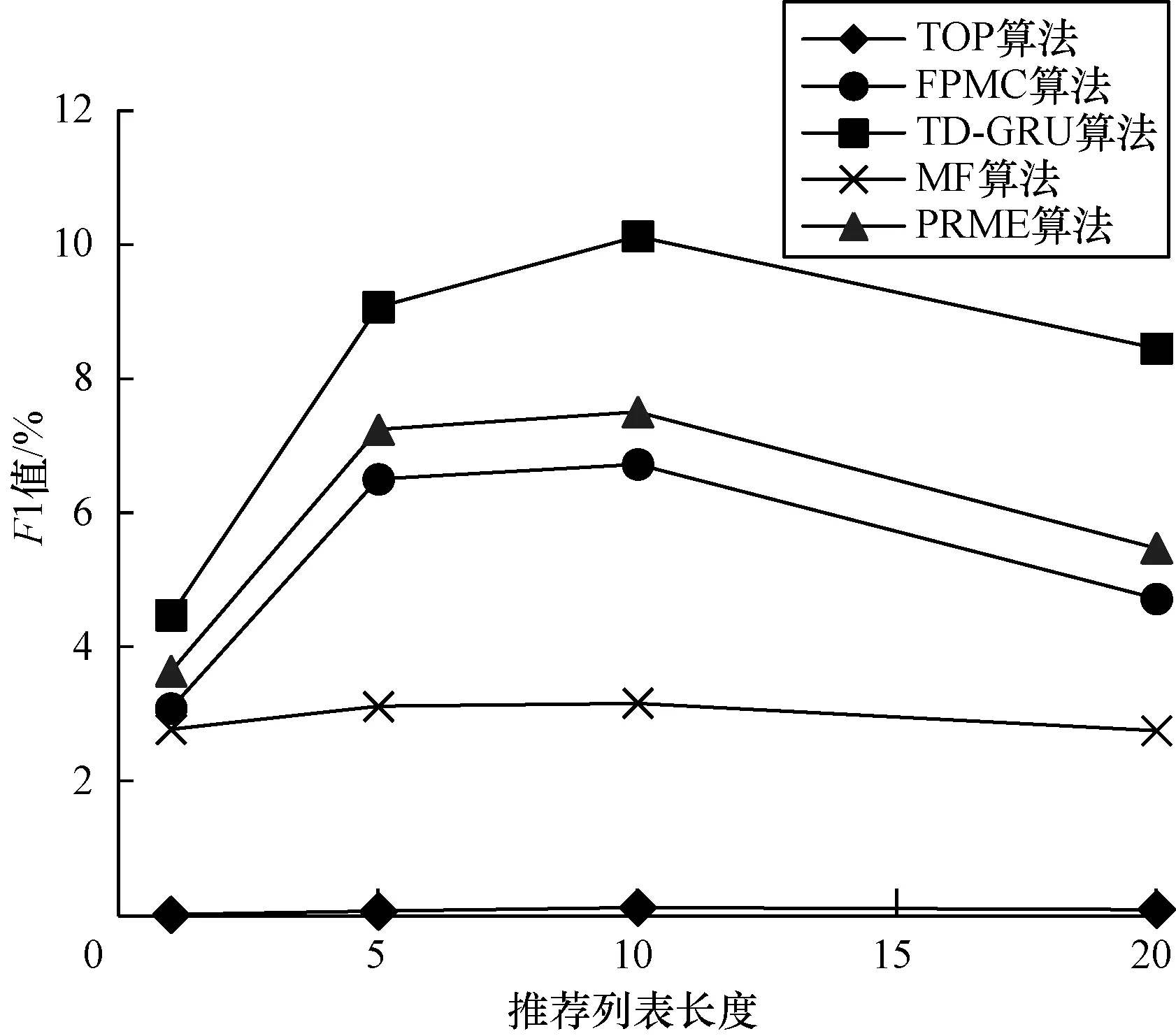
图7 Foursquare数据集上不同算法推荐列表长度的F1值
Fig.7F1 indicator with different algorithms and recommended list lengths on Foursquare dataset
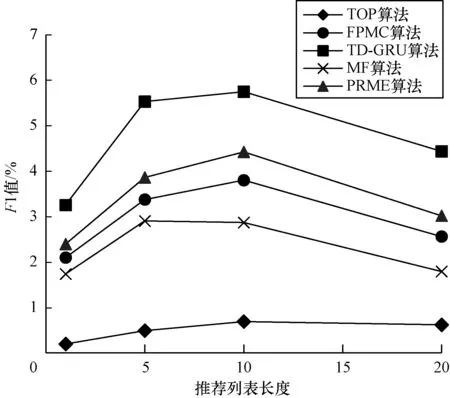
图8 美团数据集上不同算法推荐列表长度的F1值
Fig.8F1 indicator with different algorithms and recommended list lengths on the Meituan dataset
上述实验结果验证了TD-GRU算法的推荐性能最优。本文针对不同的时间窗口ω值以及不同的列表长度N,以召回率Recall值为参考进行实验,实验结果如表3、表4所示。
表3 Foursquare数据集上不同推荐列表长度时间窗口值的召回率
Table 3 Recall of different recommendation list lengths and time window values on the Foursquare dataset
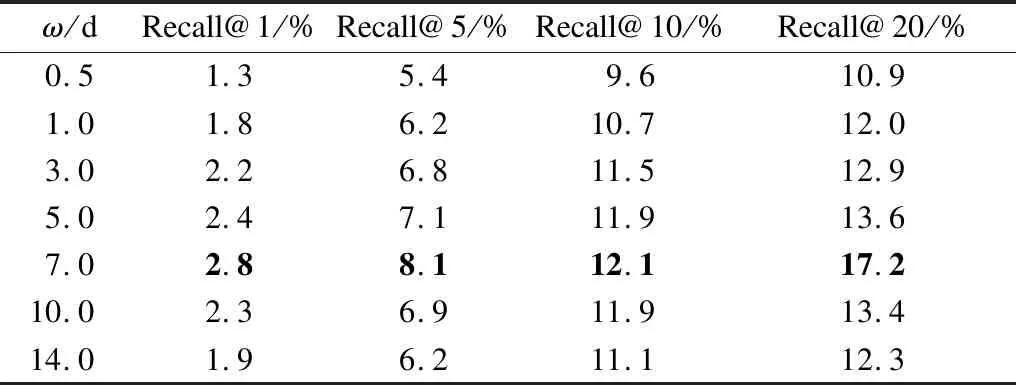
ω/d Recall@1/%Recall@5/%Recall@10/%Recall@20/%0.51.35.49.610.91.01.86.210.712.03.02.26.811.512.95.02.47.111.913.67.02.88.112.117.210.02.36.911.913.414.01.96.211.112.3
表4 美团网数据集上不同推荐列表长度时间窗口值的召回率
Table 4 Recall rate of different recommendation list lengths and time window values on the Meituan dataset

ω/dRecall@1/%Recall@5/%Recall@10/%Recall@20/%0.51.12.35.38.31.01.43.47.09.73.01.74.78.510.95.02.15.49.311.67.01.95.910.212.410.01.55.79.811.814.00.94.27.210.6
由表3、表4可知,当ω值取7 d时(见粗体),TD-GRU算法无论在Foursquare数据集上还是在美团网数据集上,召回率都是最高的,这就意味着将用户访问兴趣点的时间序列划分成7 d的时间间隔,推荐效果最优,较好地覆盖了用户访问兴趣点的长序列,推荐结果具有更高的可信度和参考价值。
4 结束语
为便于对时序信息建模,本文将深度学习领域的门控循环神经网络引入兴趣点推荐算法,对连续的时间因素离散化处理,给出特定时间转换矩阵,而对于距离信息采用了特定距离转换矩阵,提出基于时序和距离的门控循环单元兴趣点推荐算法(TD-GRU)。实验结果表明,与传统的兴趣点推荐算法相比,该算法推荐结果具有较高的可靠性。在实际中,影响兴趣点推荐的因素较多,本文只考虑了时间和地理位置,下一步将结合影响兴趣点推荐的兴趣点流行度、用户好友关系等因素,进一步完善本文推荐算法。
