基于Elasticsearch的时空大数据存储与分析方法
2020-01-16俞志宏栗国保李少白
文/俞志宏 栗国保 李少白
1 引言
地理信息技术的快速发展,使其信息化水平越来越高,随之而来的是数据的爆炸式增长,使得海量空间数据的存储与查询时效性面临巨大挑战。由于空间数据的特殊性,在存储和管理方面也存在诸多的限制,而分布式技术的迅速发展,无疑为空间数据的存储与管理提供了解决方法。ElasticSearch 作为一个分布式可扩展的实时搜索和分析引擎,在海量数据的存储与搜索方面得到广泛应用。由于ElasticSearch面向文档的特性,使得它在海量空间数据的存储方面也有很好的表现,但如何实现空间数据的高效查询是业界研究的一个热点问题。传统的关系型数据库大多建立树的索引实现空间查询,在面临大数据量的查询时其性能很难满足实际需求,而传统的空间索引很难应用于非关系型数据库中,所以需要对空间数据进行转换,将转换后的数据作为索引字段以用于查询。因此,本文依据ElasticSearch 的存储特性,结合四叉树网格编码算法,将矢量数据进行转换,并构建空间索引,以提升空间数据的查询效率。在此基础上,设计并实现了基于Spark 的空间数据分析的优化方案,为海量空间数据的存储与查询分析提供了一种快速有效的解决方案。
2 四叉树网格编码算法

图1:四叉树网格编码原理图
由于四叉树编码算法原理较简单且容易实现,已被广泛应用于地理信息系统的业务处理中。该算法的基本思想是将一个已知范围的空间划分成四个相等的子空间,并按照此方式递归执行,直到树的层次达到指定的深度或满足某种终止条件时则停止划分。本文依据四叉树编码算法的思想,实现了利用平面直角坐标系所划分的四个象限作为编号的四叉树编码算法。该算法以全球矩形范围(-180,90,180,-90)为基准网格(可根据具体应用场景调整矩形范围),逐级四分,通过单个要素的最小外接矩形,计算落在各级网格的象限编号,将各级的象限编号按顺序组合形成网格编码,其编码原理如图1所示。
从图1中可以看出该算法基于各级象限进行编码,计算出来的编码值能够表达图形在每一级的格网位置。四叉树编码算法的处理流程可描述为:首先,算法根据输入的几何对象计算该对象的最小外接矩形;其次,根据最小外接矩形的顶点坐标信息对其进行递归编码;最后,输出几何对象的编码集合。在使用该算法对要素类进行递归编码的过程中,会存在一些线状要素或面状要素所跨范围较大的情况,针对该情况算法会根据要素投射在当前级别四叉树格网中的位置,产生相应的多个编码值。当网格划分到一定的级别后,单个面状要素和线状要素生成的编码个数也会增加,编码数的增多会导致存储的冗余数据增多。因此,所采用的格网编码的长度应根据实际数据的特点进行权衡,其遵循的原则是确保大部分图形拥有一个编码,允许少量的图形拥有多个编码。
3 空间数据存储
Elasticsearch 是一个分布式、可扩展、实时的搜索与数据分析引擎,能够为海量数据提供分布式存储、搜索和快速分析的服务。因其强大的搜索与分析能力,已被成功用于很多海量数据的处理中,如新浪过亿条的日志数据的实时分析。Elasticsearch 除能够提供传统数据库很难实现的全文搜索功能外,还具备结构化搜索、数据分析及复杂的语言处理等功能。
鉴于此,本文使用Elasticsearch 存储空间数据,以充分利用Elasticsearch 强大的索引搜索功能,达到快速查询指定数据的效果。虽然Elasticsearch 提供的搜索功能,能够满足空间数据基本属性的快速查询,但由于图形数据是一组坐标点的集合,直接对该字段进行索引,并不能满足图形数据的查询需求。因此,本文结合空间数据的特点及Elasticsearch 索引机制,提出基于四叉树的网格编码算法,根据图形数据计算其网格编码值,使用网格编码值对图形数据进行索引。基于以上设计思想,空间数据在Elasticsearch 中的存储形式如表1所示。表1表示的是一条空间数据在Elasticsearch 中的表示形式,在保留了空间数据原有属性字段的基础上添加了codes 字段,用于存储图形数据转化成的编码值集合,并指定该字段为索引字段。
4 基于Spark的空间数据分析方法
针对海量空间数据存储问题,上文中提出基于四叉树网格编码算法,并结合Elasticsearch 强大的搜索能力,解决了多应用场景下空间数据的查询性能问题。但空间数据在执行空间分析操作时,计算耗时较长,尤其是参与计算的空间数据量较大时,空间分析操作需等待的时间更久,已不能满足实际的生产需要。因此,本节在基于上文中提出的基于四叉树网格编码索引方案的基础上,探讨利用基于内存的分布式计算引擎Spark 解决传统模式下计算能力不足的问题,并以空间分析中的空间裁切操作为例,验证基于Spark 的分布式空间分析的处理性能。
4.1 建立外部空间数据连接
上文中根据实际应用需求提出基于四叉树网格编码的索引方案,用以提升多场景下的空间数据查询效率。同样的,也可以使用该索引方案提升空间数据分布式处理的效率,即从底图数据检索和外部空间数据预加载两个方面着手,来减少参与计算的数据量,从而提升分布式处理的效率。在底图数据检索方面,对外部空间数据使用四叉树编码算法计算其编码值,并根据编码值从Elasticsearch 中检索出与codes 字段前缀相同的数据,从而减少Spark分发数据时的数据量;在外部空间数据预加载方面,对外部空间数据进行编码,并建立编码与外部要素的对应关系集合,以便在Spark 开始分布式计算时,能够根据读取的底图要素的编码值直接找到与其空间上相关的外部要素,减少程序遍历计算的次数,从而提升空间数据分布式计算的性能。

表1:空间数据存储结构

表2:两种方案处理空间裁切任务耗时情况表
4.2 空间数据分布式计算流程
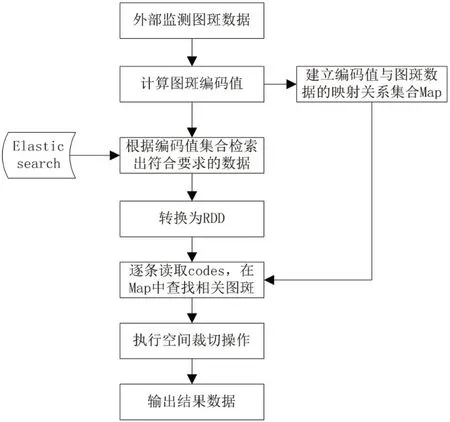
图2:基于Spark 空间数据裁切处理流程图
本节以空间裁切的应用场景为例,使用基于四叉树网格编码的索引方案,设计出基于Spark 的分布式空间数据处理方案。其处理流程为:
(1)程序读取Kafka 队列中监测图斑数据,并调用网格编码算法计算出矢量数据中的网格编码值,建立网格编码值与外部图斑数据的映射关系,存储于Map 集合中;
(2)Elasticsearch 根据监测图斑编码值集合,检索出符合要求的底图数据,并转换成RDD,Spark 逐条读取RDD 中的codes 字段的值,而后根据该编码值从Map 集合中查找到与其有关联的监测图斑,分别执行空间裁切操作;
(3)输出空间裁切后的相关数据。基于Spark 空间数据裁切处理流程图如图2所示。
5 实验与分析
5.1 实验环境
本小节通过实验来测试本文提出的基于四叉树网格编码算法的空间数据存储与分析方案在执行效率上是否优于传统的空间数据存储与分析方案。基于Hadoop 2.7.3 搭建一个主节点,两个数据节点的Hadoop 集群环境,并在该集群中部署Spark、Elasticsearch 环境,其中Spark 版本为2.3.0,Elasticsearch 版本为6.4.0。每个数据节点的配置信息为:1 颗8 核主频1.70GHz 的CPU、125G 内存、操作系统为CentOS7.3。测试数据使用了一个市的地类图斑数据集作为底图数据,其数据量为10 万条记录,并按照本文提出的存储方案,存储于Elasticsearch 中。
5.2 实验结果与分析
为验证本文提出的空间数据处理方案的计算性能,所以本小节中设计了基于网格编码索引的分布式处理方案与传统的基于随机散列的分布式处理方案的对比试验。为保证试验结果的可比性,底图数据固定为一个市的地类图斑数据,使用不同数据量的监测图斑对两种方案进行测试。两种方案处理空间裁切任务的耗时情况如表2所示,其中基于随机散列的分布式处理方案记作R-INDEX,基于网格编码索引的分布式处理方案记作G-INDEX,花费时间单位为毫秒。
从表中耗时情况可分析出当选取的监测图斑逐渐增加时,两套方案的处理时间都有所增加,但本文提出的G-INDEX 方案,在做空间数据裁切操作时所花费的时间明显低于R-INDEX 方案所花费的时间,这表明本文提出基于四叉树网格编码空间索引方案要优于传统的基于随机散列的处理方案。这是因为基于网格编码的空间索引方案,在获取到监测图斑后能够根据生成的编码值,从Elasticsearch 中快速检索出与监测图斑数据相关的记录,减少空间裁切操作时所处理的数据量,从而提升空间裁切处理效率。
6 结束语
本文在研究了Elasticsearch 基础上,根据矢量数据的空间特性,提出基于四叉树网格编码索引方案;而后依据Spark 的分布式处理原理,设计出基于Spark 的空间数据处理优化方案,并选取空间裁切作为应用场景,验证了该优化方案的有效性。
