基于微博热点发现的改进SSDKmeans算法
2020-01-16陈来
文/陈来
在当前的微博平台上,部分人认为该平台上的数据繁多,并且存在大量杂乱无章的内容,通过对其中的关键资料进行整理分析,可以有效提取其中的热点话题数据,保证了信息数据的利用率。
1 对改进SSDKmeans算法的分析
1.1 对Kmeans算法的认识
Kmeans 算法又被称为K-均值算法,是目前信息数据处理过程中一种最为常见的划分聚类算法,在该方法中,需要给定一个K 值作为基础数据,在随机从数据集中提取K 个点作为算法执行的初始中心后,再计算其他数据点与这个K 初始中心的相似度,并将其归纳到相似度最大的类簇中,并在此计算中心点。在整个数据处理环节,工作人员通过持续的迭代上述计算过程,最终会获得一个新的聚类中心点,该聚类中心点不会变化。在这个过程中,Kmeans 算法的计算过程为:
(1)输入若干个数据对象,将其定义为K 值。
(2)输出K 个聚类结果;
(3)算法的步骤为:
①从若干个数据中随机选K 个初始类簇中心点;
②对数据的归纳处理;
④再重新计算每个类的质心,计算公式为:
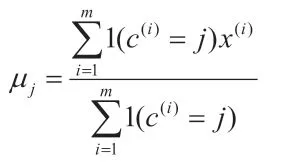
⑤聚类中心不再变化。
在上述计算公式中,K 代表事先给定的聚类数量;c(i)代表与数据点i 之间距离最近的类,取值范围为:1-K;μj代表质心,属于类簇的中心。
在整个数据处理过程中,Kmeans 算法获得的聚类结果手初始值的影响,若在数据处理过程中没有选择到理想的初始值,或者初始值的选择与原始聚类之间的分布存在较大的差异,这种情况将会造成算法迭代的次数快速增多,造成算法所能获得的聚类结果存在差异,甚至出现局部最优的情况,无法满足当前海量数据下的数据抓取要求。
1.2 改进SSDKmeans算法的技术分析
通过上述分析可以发现,在传统Kmeans算法中的时间复杂程度不高,对于大部分的数据集合处理而言都具有良好的适应性,但是在微博热点话题等相对复杂的数据抓取处理环节,该方法还存在一定的不足,主要表现为:
(1)在数据处理环节需要优先确定K 值。该方法在执行过程中需要先随机选择K 个点作为聚类划分的标准,因此在很多的数据处理过程中可以快速的确定K 值,但是针对无法精准获得原始簇数量的聚类问题,所选择的K值会直接影响数据的聚类结果,甚至少部分不合理的选值会影响整个数据处理过程。
(2)在传统的数据处理算法中,终止条件的目标函数一般为类簇中心的误差平方和,在数据处理过程中若发现原始的数据对象之间存在明显的区别,并且各类数据点的分布相对密集,则在数据过程中通过误差平方就可以获得相对满意的聚类结果。但是在实际上类簇之间存在差异,尤其是在计算误差平方和期间,为了能够将误差控制在最小,往往需要对大聚类进行分隔,并随机选择质心。在这种数据处理过程中,若选择的目标函数局部极值小,那么聚类结果有可能不是全部最优解。
针对传统数据处理方法中存在的问题,本文认为数据流在实际上属于一种基于时间排序的特殊序列,目前淘宝、京东知名平台在数据处理过程中都采用了数据流技术。而在这个技术下会出现一个特殊情况,即数据处理过程的频繁项,这是指在数据集合中项的出现的次数达到特定指标的一个阈值,假设在一个数据集中存在N 个数据项,并且将支持度设定在S∈{0,1}的集合见,则这些数据项频数达到SN 的情况下就可以归结为频繁项。在当前数据抓取技术中,频繁项技术已经得到了充分的应用,尤其是结合频繁项挖掘的SS算法,所以本文就基于这一要求提出了改进SSDKmeans 算法,该算法中通过SS 算法来完成数据流计算过程,其中的核心表达含义为:在N 个数据中若添加一个新的数据项在N 中,则对应的计数为1;若不在则可以判断空间已经满了,若满了则可以替换计数最小值,否则可以将数据直接添加到数据集合D 中。
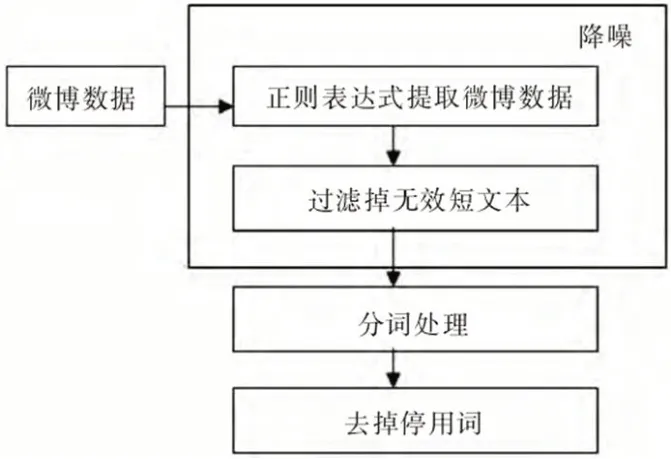
图1:微博数据处理思路
通过上述介绍,可以判断改进SSDKmeans算法的数据描述过程为:
(1)将数据集D 中的N 条微博记录词条进行采集,每个词条的技术为ci,并输入微博词条。
(2)判断替换的最小计数值e 是否在D中,若在则将f=f1+ci作为e 的统计频数;若不在,则判断D 空间是否已经满了;若发现D空间没有满,则将<e 且大于ci的数据加入到D 中;或者查找D 中计数值f 是否满足最小数据项em,并将其替换掉。
(3)对上一步骤中的数据集做建模,形成VSM 模型。
(4)针对最大最小距离初始m 的中心点数量,此时记录每一条微博的内容,并将其与m 个聚类中心距离进行比较,形成基于余弦距离的(i,m)。
(5)再次识别每一条微博内容,计算获得聚类的中心数据,保证(i)=m。
(6)评判每一条微博,若发现所有的微博文本集属于最近的near(i)类别则终止运算,若不属于则继续执行。
(7)强near(i)中的i 归纳到m 中,重新计算各个中心的平均值。
2 基于改进SSDKmeans算法的微博热点发现要求
2.1 文本聚类
在微博热点的文本信息分析中,可以通过文本聚类的方法,将不同组别中的文档类型进行判断,在了解文档类型的划分后,选择其中具有较高相似度的内容将其归结到一起,这是文本聚类的主要依据。在这个过程中,文本聚类具有良好的可伸缩性,在改进SSDKmeans算法中,可以通过文本聚类的方法来保证文本信息识别的拓展性,并且这个聚类过程不需要人工干预,保证了数据处理能力。
在这种情况下,通过改进SSDKmeans 算法能够对采集到的微博数据进行预处理,通常做法是讲数学矩阵技术纳入到文本中并进行整合,通过数字化的改进方法来获得目标微博文本信息的特征项表征。在此基础上,利用文本信息构建的VSM 模型(向量空间模型)能够更好的识微博中各种词条的空间向量特征,其中的表达方式为:
在上述公式中,f 代表了微博文本,t 代表特征词条,w 为特征词条的权重值。在这个过程中,结合微博本身的信息文本特征进行判断,大部分微博中所包含的文本内容不多,所以在这种情况下可以判断单个词条会出现多次的0 或1,这样可以有效的筛选出频繁出现的词条,达到了识别微博热点的目的。
2.2 计算简化思路
在改进SSDKmeans 算法中,为了可以更好的识别微博热点,整个聚类所得到的关键词还是基于微博本身的,因此在该方法在应用过程中可以结合不同的文本数据识别进行调整。而根据微博本身的热点特征进行判断后,发现热点话题本身的微博转发、评论量很多,并且发布微博用户本身的影响力也会对最终结果产生影响。在这个过程中可以发现,影响微博热点的影响因素主要包括:
(1)拥有大量关注者意见领袖的参与。活跃的微博用户所发布的微博更容易被热门发现,而拥有大量粉丝的意见领袖所发布的内容容易被大量粉丝阅读,因此成为微博热点的概率更大。但是此时需要注意的是,并不是所有的意见领袖所发布的微博可以得到粉丝的认可,也不是所有的粉丝都可以即时看到微博。
(2)微博的点赞数与转发数等。一条备受关注的微博,其转发量、点赞量必然很大,当用户对某条微博产生强烈的认同感时,会采用“转发+评论”的方法,而随着微博转发数量越来越高,微博成为热点的概率越高。
基于上述分析,为了可以更好的发现微博热点,在改进SSDKmeans 算法中可以根据不同影响因子对话题热度的影响进行判断,在了解微博单位时间内的评论量、点赞量以及意见领袖的参与情况后,对微博本身的数据信息进行判断,这样可以进一步提高数据处理质量。
3 改进SSDKmeans算法的实验验证
3.1 实验环境
本次实验中利用JAVA 语言编写,实验环境为:
操作系统为Windows7 系统,64 位;处理器Intel(R)i5;安装内存4.00GB。
3.2 实验数据与处理

表2:本文研究结果与新浪微博热门话题的实时对比表
考虑到微博平台中包含大量且广泛的数据,无法像传统的文本处理那样形成大量有权威的数据库,因此在本次研究中将以微博平台的具体内容用户内容,采用数据采集器直接从微博上抓取本次实验中的44182 条微博数据。
在这个数据处理过程中发现,由于在微博平台上每一个用户都具有发布信息的能力,其中一些微博内容只是用户对日常琐事的记录,也有一些微博文本内容是单纯的抒情,这些数据对形成热点没有任何帮助,因此数据处理的一部就是通过手工处理的方法对文本进行初步筛选,过滤掉不满足本次研究条件的微博文本;之后再对微博文本做进一步的处理,去除其中链接地址、特殊符号等微博,并通过系统排序,剔除意见领袖以及平常用户中一些评论、转发量较低的微博数据后,最终获得了涉及影视剧集、娱乐圈事件、民生资料等多个类型的微博数据。最后对上述文本做最终处理(见图1)。
在获得文本词集合后,采用Gibbs 抽样方法对VSM 模型的LDA 模型参数进行估计,并将处理后的文本词进行建模。在改进SSDKmeans 算法中,VSM 模型的参数与说明的详细资料如表1所示。
在参数设定结束后,通过运行程序获得“文档-主题”的矩阵文件,此时矩阵中的每个元素代表了某个文本中形成的主题概率。
3.3 实验方法
针对微博短文本聚类相似结果采用精准率与召回率判断,其中召回率代表改进SSDKmeans 算法中找到频繁项与微博文本中实际存在的频繁项之间的比例,常见的计算方法:文本中的主题概率÷微博文本中实际频繁项=召回率。精准率指改进SSDKmeans 算法中样本采集频繁项与找到的频繁项之间的比值。
3.4 实验结果与分析
按照上述方法对本文所提取的微博样本进行处理后,依照改进SSDKmeans 算法中所得到的数据集初始类簇,计算类簇中心点为聚类算法的初始中心点,在通过改进SSDKmeans算法中对聚类效果进行多次修正,在经过上述处理后,获得的微博热点与新浪微博实时热点话题对比结果如表2所示。
根据表2的相关资料,本文通过改进SSDKmeans 算法所提取到的热门话题特征词与新浪微博当时实际的特征话题之间存在一定的差异,特征词没有完全体现热点话题内容,但是特征词却没有偏离实时热点话题的范畴,进而证明本文所介绍的方法具有科学性。而造成两者之间出现的差异原因可能为:在本文所提取的数据中,只能根据微博所提供的数据资料进行分析,本身存在一定的滞后性,并且在相关话题阅读量问题的识别过程中,无法实时监测转发数、评论数的变化;再加之本次研究中所构建的VSM 模型无法像新浪微博官方那样讲词条内容具体化,只能提供一个大题的话题词条范围,因此这种问题在一定程度上造成本次热门话题词汇与具体热点出现差异,但是这种差异也是可以解决的。
4 结束语
基于改进SSDKmeans 算法满足微博热点发现的要求,本文所介绍的实践经验证明该方法具有明显的先进性,值得推广。
