基于Cascade R⁃CNN的铁路路基翻浆冒泥病害智能识别方法
2020-01-02徐昕军黄启迪
徐昕军,江 波,黄启迪
(中国铁道科学研究院集团有限公司基础设施检测研究所,北京 100081)
翻浆冒泥病害是铁路路基常见病害,如果不能及时发现并处理,会严重影响行车安全。目前,对铁路路基病害检测主要采用车载地质雷达法,检测数据量巨大。对路基病害的识别仍然以人工解译为主,对解译人员相关专业知识要求较高,数据分析的速度极低且无法避免人为误差。因此,如何提高铁路路基检测数据的病害识别效率以及时指导铁路路基的养护维修,是亟需解决的难题。
由于铁路路基地质雷达检测数据的解译主要采用经过处理的地质雷达剖面图,因此,铁路路基病害识别可以看作计算机视觉研究中的目标检测任务。目标检测包括2个子任务:①目标类别检测任务,需要区分目标和背景,并确定目标所属类别;②目标定位任务,需要用检测框框定出目标的所属范围。本文以目标检测方法中的Cascade R-CNN 模型为基础,提出一种针对铁路路基翻浆冒泥病害的智能识别方法,该方法以PyTorch[1]作为深度学习框架,通过在自制病害数据集上进行试验来验证本文方法的有效性。
1 国内外研究现状
1.1 铁路路基病害识别方法
针对铁路路基病害识别的相关研究主要集中在病害特征的设计与提取,以及支持向量机、浅层神经网络等传统机器学习方法在训练病害分类器上的应用。赵勐[2]设计了基于二维小波分析的探地雷达图像特征提取算法,并基于神经网络设计了路基病害自动识别算法,但识别算法中各参数需要人为设定,识别参数的选取直接决定了识别效果的好坏。廖立坚等[3]通过分析雷达图像的层面图,提取了翻浆冒泥的特征值,并采用神经网络技术实现了对翻浆冒泥病害的识别。邹华胜[4]提出了以瞬时频率和瞬时振幅为特征值,采用支持向量机技术对路基病害进行识别,但识别范围局限于训练样本的范围,超出范围则识别效果变差。侯哲哲[5]采用稀疏表示的方法对路基病害进行特征表示,并利用超球面支持向量机对病害进行识别。
1.2 目标检测的发展现状
由于深度学习方法避免了传统方法手工设计特征的弊端,在目标检测、语义分割等多个领域取得成功,其中目标检测发展迅速。目标检测框架主要包括2 类:①单阶段检测器,代表性架构是SSD(Single Shot Multibox Detector)[6],YOLO(You Only Look Once)[7],Focal Loss[8];②两阶段检测器,代表性架构是 Faster R-CNN[9],R-FCN(Region-Based Fully Convolutional Networks)[10],Mask R-CNN[11]和Libra R-CNN[12]。
近些年来,多阶段检测框架逐渐成为目标检测领域的一种风向标。Gidaris 等[13]提出了将检测框评分和定位精修交替进行的迭代定位机制。Gidaris 等[14]介绍了一种ARN(Attend Refine Network)网络结构,通过一个多阶段程序生成精确的候选框,并将其输入FastR-CNN 进行前向传播。Yang 等[15]将一个级联结构合并到RPN 和Fast R-CNN,以提高候选区域和检测结果的质量。Jiang 等[16]提出了优化的定位置信度方法,提高了检测框精修定位精度。级联结构大量被用于排除简单负样本。例如,Ouyang 等[17]在浅层排除掉简单的候选区域(Region of Interest,RoI)。Li 等[18]提出在多个分辨率上排除简单样本。Ouyang 等[19]在目标检测网络中嵌入了典型的级联架构。Dai 等[20]将一个检测和一个分割任务交替迭代用于实例分割。
在使用级联结构的模型中,Cascade R-CNN[21]效果显著。Cascade R-CNN 包含多个阶段,每一阶段的输出作为下一阶段的输入,以取得更高的精修质量,而且每一个阶段的训练数据是采用逐渐增加的交并比(Intersection over Union,IoU)阈值进行采样的,这种方式可以很好地应对不同的训练分布。
2 Cascade R⁃CNN简介
2.1 Cascade R⁃CNN
Cascade R-CNN 是一种多阶段目标检测模型,解决了在目标检测任务中训练出包含少量假阳性样本的高性能检测模型的问题。
传统两阶段目标检测架构[9,22-24]将目标检测归结为包含分类和检测框回归2个子任务的多任务学习问题,通过设定一个IoU 阈值来定义正样本和负样本,该阈值一般为0.5。但这是一个不够严格的判定标准,检测模型很难排除接近阈值的假阳性样本。提高IoU阈值可减少通过的假阳性样本数量,但会造成正样本数量呈指数级减少,导致检测器因为训练过拟合而性能下降。反之,降低IoU 阈值会导致训练的检测模型产生误检。
研究发现,以单一IoU 阈值训练的检测器对与该阈值接近的输入样本的定位和检测性能最好,所以单一IoU 阈值检测器通常对某类样本最优。因此,Cascade R-CNN 被设计成多阶段检测架构,每个阶段对应不同质量的输入样本。另外,回归器输出的IoU值总是优于输入的IoU值。因此,Cascade R-CNN 模型训练采用级联检测进行迭代式训练,将低IoU 阈值检测器的训练结果作为下一高IoU阈值检测器的输入。
2.2 级联检测
Cascade R-CNN 级联网络结构从初始样本分布开始,可通过重采样自动生成下一阶段需要的高IoU 阈值输入样本。这种结构有2 个优点:①不易发生过拟合,因为每个阶段都有足够的输入样本;②较深阶段的检测器被优化为适应更高的IoU 阈值。此外,由于每一检测阶段均可剔除离散值,在检测阶段采用级联结构,候选框质量随着检测阶段深入逐渐提高,进而增强了检测模型性能。
2.3 级联回归函数
由于单一回归函数很难适应不同IoU 阈值下的候选框,因此Cascade R-CNN 将回归任务分解为一系列更简单的步骤,此级联网络的回归函数如下:

式中:T是Cascade 网络检测阶段的总数;fi(i=1,2,…,T)是Cascade 网络对应阶段的回归器;x是输入回归器的图片;b是输入图片对应的检测框。
级联回归函数中的每一个回归函数不是采用同样的初始分布,而是在相应阶段的样本分布下达到的最优化。因此该网络可以逐渐优化候选框。
2.4 实现细节
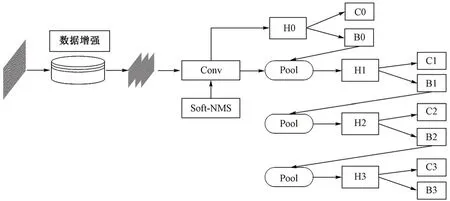
图1 Cascade R-CNN 级联模型结构
Cascade R-CNN(图1)扩展了Faster RCNN 的两阶段检测架构,构建了1 个由多阶段子网络构成的级联回归模型。Cascade R-CNN 由4 个阶段组成:1 个用于生成候选区的RPN(Region Proposal Network)阶段和3 个检测阶段,IoU 阈值分别设为 0.5,0.6 和 0.7。首先,由产生候选区域的子网络“H0”输入整张图片并产生初步的目标检测区域;然后,利用RoI候选区域检测子网络“H1”对第1阶段的初步候选区进行处理;最后,将每个候选区送到分类评分模块“C”和检测框模块“B”。
3 基于Cascade R⁃CNN的路基病害识别方法
3.1 病害识别流程
因为路基病害地质雷达检测数据内部结构复杂,目标与背景结构差异小,且彼此交融,导致边界模糊不清。因此,本文针对翻浆冒泥目标检测任务的特点,对原始Faster R-CNN 进行了改进,基于Cascade R-CNN的病害识别流程如图2所示。
在传统非球面光学元件抛光过程中,主要通过技术人员手工修磨,因此存在加工效率低,精度稳定性差的缺点,且产品加工质量十分依赖技术人员的经验和技巧,很难达到技术要求。计算机控制小磨头抛光技术的提出有效解决了这些难题。计算机控制小磨头抛光技术也被称为计算机控制光学表面成形技术(computer controlled optical saurface, CCOS),是发展于20世纪70年代的光学加工技术,该技术在大口径光学非球面元件加工领域扮演着重要角色。近年来发展的磁流变抛光、气囊抛光、离子束抛光和大气等离子体抛光等技术,全是基于这一原理的抛光技术[2-5]。

图2 基于Cascade R-CNN 的病害识别流程
首先,基于PyTorch 搭建深度学习开发环境,整理病害图片进行病害标注,并转换成COCO(Common Objects in Context)[25]格式数据集;然后,以深度学习工具箱mmdetection 提供的Cascade R-CNN 代码为基础,并使用Soft-NMS 和数据增强方法对Cascade R-CNN 进行改进;最后,采用预训练模型进行模式参数初始化,训练和测试模型,使用自制数据集对模型调优,采用COCO检测评价矩阵评价模型性能。
3.2 Soft⁃NMS
非极大值抑制(NMS)用于剔除重叠度高的候选框,但传统NMS 会将部分正确的目标检测框剔除掉。翻浆冒泥病害在总体趋势上是连续的,但也会由于涵洞、桥梁等结构物而出现间断的情况。因此,如果在翻浆冒泥病害识别任务中仍采用传统NMS,会导致距离较近的正确病害候选框被抑制掉,降低识别准确率。因此,本文采用了一种改进的NMS方法——Soft-NMS[26]。
Soft-NMS 对重叠度大于阈值的候选框不是采用直接抑制的方式,而是降低该候选框的检测评分。与最高分候选框重叠度大的候选框评分下降较大,而重叠度小的候选框评分受影响较小,可以减少假阳性结果,增强模型性能。其中,Soft-NMS 利用衰减函数对评分进行控制,包括线性加权和高斯加权2种形式,分别见式(2)和式(3)。试验表明,在翻浆冒泥识别任务上高斯加权效果更好,因此本文采用高斯加权Soft-NMS。

式中:M是具有最高检测评分的候选框;bi是候选检测框;iou(M,bi)是M和bi的重叠度;si是bi对应的检测评分;D是预留的候选框集合;σ为高斯函数的方差;Nt为NMS的阈值。
3.3 数据增强
在深度学习中,有时会出现训练集样本不够或某一类样本较少的情况。为了防止过拟合,加强模型鲁棒性,可以采用数据增强的改进方法。数据增强通过几何变换的方式改变像素所在位置,而不改变像素值,让模型学到更多图像不变特性。
在翻浆冒泥病害识别任务中,由于能收集到的样本数量比一般的目标检测任务要少,因此本文综合使用多种数据增强方法扩充病害样本集,提高模型性能。具体改进方法为:①翻转与反射变换,沿着水平或垂直方向翻转图像;②对比度和亮度变换,对图像HSV(Hue,Saturation,Value)颜色空间中每个像素的饱和度和亮度分量进行指数运算,以增加光照变化;③缩放变换,按照一定的比例缩小图像;④随机裁剪,采用随机图像差值裁剪图像。
4 试验与结果分析
4.1 数据集准备
利用中国铁道科学研究院集团有限公司基础设施检测研究所桥隧部多年铁路路基检测工作积累的数据自制路基病害数据集。数据集中的图片为地质雷达后处理软件生成的病害雷达剖面图,且部分病害已经过现场开挖验证。
目前制作目标检测数据集常用的数据格式包括VOC 和COCO 2 种格式,本文采用COCO 数据集格式制作数据集。COCO 是微软团队提供的一个进行图像识别的数据集。数据集包括1 030 张标注好的翻浆冒泥病害图片,并按照8∶1∶1 比例划分为训练集、测试集和验证集。图片首先由路基检测专家使用LabelImg[27]图片标注工具进行标注,再使用数据格式转换工具[28]将得到的 xml 标注文件转化为 COCO 的json format格式。
4.2 环境配置
本次试验以PyTorch 为深度学习框架搭建开发环境,版本为 Stable(1.2),使用 Linux(Ubuntu14.04)系统、Python3.6版本和CUDA 版本10.0,Cascade R-CNN的实现代码采用商汤科技和香港中文大学开源的深度学习目标检测工具箱mmdetection,开发环境配置如表1所示。模型训练和测试以PyTorch 版本的Cascade R-CNN为基础。

表1 开发环境配置
4.3 模型训练与关键参数设置
mmdetection 将目标检测架构拆解为不同的模块进行封装,通过这些通用模块可构建出自己的检测模型。本文模型的网络模块配置如表2所示,网络模型选用Resnet101。

表2 网络模块配置
经过大量试验与模型调试,对翻浆冒泥病害识别模型训练过程中的关键参数设置总结如下:参数imgs_per_gpu 设为 1,即每个 gpu 计算 1 张图片;参数workers_per_gpu 设为 1,即每个 gpu 分配 1 个线程;参数num_classes设为2,即分为翻浆冒泥和背景类;求解器优化方法采用随机梯度下降法,全局学习率lr 设为0.002 5,初始学习率设为1/3,初始学习率增加策略设为线性增加,动量因子momentum 设为0.9,权重衰减因子weight_decay设置为0.001。
模型训练采用GPU 加速模式,训练周期epochs 设为12,即数据集共训练12 次。在前500 次迭代过程中学习率逐渐增加,并在第8 个和第11 个epoch 降低学习率。训练时采用Resnet 预训练模型初始化参数,并在此基础上使用自制数据集进行调优,用少量训练样本取得较高的模型识别精度。
4.4 试验结果与评估
本文采用COCO 检测评价矩阵评估模型性能。COCO评价矩阵包括12个评价指标,用来评价COCO数据集上的目标检测器的性能。检测指标包括4大类:
第1 类为平均精度(Average Precision,AP),表示所有类别目标的平均精度,包括AP,AP50和AP753 个指标。AP 是COCO 格式数据集上评价模型性能最重要的指标,是多个IoU 值的平均值,以0.05 位间隔,对0.50~0.95 的 10 个 IoU 阈值进行计算,以提高检测器的精度;AP50对应传统的IoU阈值为0.50的计算方法,与PASCAL VOC 矩阵的评价方法相同;AP75对应更加严格的IoU阈值为0.75的计算方法。
第2 类为跨尺度平均精度(AP Across Scales),用于衡量不同尺度目标的平均精度,包括APS,APM和APL3 个指标。APS表示小目标的平均检测精度,目标区域像素点个数小于322;APM表示中等目标的平均检测精度,目标区域像素点个数大于322,小于962;APL表示大目标的平均检测精度,即目标区域像素点个数大于962。
第3 类为平均召回率(Average Recall,AR),是在每张图片固定检测目标数量的情况下计算出的最大召回率,且该指标是在不同类别和IoU 阈值上取平均之后的结果,包括 ARMAX=1,ARMAX=10和 ARMAX=1003 个指标,MAX为固定的检测数量。
第4 类为跨尺度平均召回率(AR Across Scales),与 AP Across Scales 类似,包括 ARS,ARM和 ARL3 个指标,表示在不同大小检测区域下的平均召回率。
本文基于Cascade R-CNN 的翻浆冒泥检测模型的COCO评价指标见表3。

表3 基于Cascade R⁃CNN病害检测评价指标
翻浆冒泥病害识别结果见图3。可知,模型检测出的翻浆冒泥病害具有较高的置信度,框选区域与病害所在区域基本一致,并且多目标区域可准确进行分割。

图3 翻浆冒泥病害识别结果
4.5 对比试验与分析
为进一步检验本文模型性能,进行了多组对比试验,见表4。

表4 模型性能对比试验
由表4可知,Cascade R-CNN 在病害数据集上比Faster R-CNN 取得了更高的识别精度。经过改进后的Cascade R-CNN 模型在检测精度上均有不同程度的提升,其中数据增强改进方法的提升效果最显著,性能提升率为1.7%,综合2 种改进方法的模型,性能提升率为3.5%。
5 结论
本文提出了一种基于新型目标检测架构Cascade R-CNN 的铁路翻浆冒泥病害识别方法,并根据目标的特点采用Soft-NMS 和数据增强方法对Cascade R-CNN进行改进。试验结果表明,改进后的Cascade R-CNN检测架构在自制病害数据集上取得了43.7%的平均精度,可有效识别翻浆冒泥病害。
