基于深度视觉语义嵌入的视频缩略图推荐
2020-01-02张梦琴孟权令张维刚
张梦琴,孟权令,张维刚
(哈尔滨工业大学(威海)计算机科学与技术学院,威海264209)
随着移动互联网的快速普及和智能电子设备的高速发展,人们获取信息的方式已不仅仅满足于图像,而直接选择使用信息更丰富、画面感更强的视频,因此也带动了很多视频分享网站和APP的快速崛起,比如YouTube、优酷,以及最近两年快速流行的抖音、快手等短视频分享APP。人们越来越热衷于将自己生活中发生的事情用短视频的形式记录下来,并且分享到主流的视频共享网站上。再加上一些新闻、体育、电视、电影等相关的视频,使得互联网上的网络视频每天爆炸式增长,充斥在网络生活中。
为了能在海量的视频资源中快速地提高某段视频的点击率,以及快速高效地为用户找到需要的视频资源,现在较大型的视频分享网站都会对每段视频添加一个视频缩略图,并配上合适的标注文本,以将视频的内容“直截了当”的呈现给用户。可见,对于一段视频,用户初步看到的是视频缩略图的内容及对应的标注文本,这也是决定其是否点击并观看该视频的关键要素之一。一个好的视频缩略图会让这段视频更有吸引力,所以研究一种能够自动提取有意义且有较好代表性的视频缩略图的方法就显得尤为重要。
对于标注文本,一般由视频上传者手动输入,也可通过视频字幕(video captioning)技术来自动生成。既然有了标注文本,缩略图自然要和文本内容相匹配,因此,如何根据已有标注文本为视频选择一个合适的视频缩略图就成为一个值得研究的问题。本文提出一种基于深度视觉语义嵌入的网络视频缩略图自动生成框架,主要针对给定的一段视频及描述视频内容的标注文本,从视频中选取出既与标注文本内容相符又满足用户浏览体验需求的视频帧作为该视频的缩略图。该方法首先使用卷积神经网络(CNN)来提取视频帧的视觉特征,并使用循环神经网络(RNN)来提取标注文本的语义特征;然后将视觉特征与语义特征嵌入到视觉语义潜在空间,视觉语义潜在空间是指视觉特征与语义特征具有相同维度与表示方式的空间,以便对视觉特征与语义特征进行相似度匹配;最后按照相似度得分对视频帧排序,选出分数最高的一个视频帧作为该视频的缩略图。同时,该方法还将选出多个与文本语义内容相关联的视频帧来作为推荐缩略图呈现给用户,以提高用户的可选择性。为了将选出的得分最高的缩略图与推荐的缩略图序列进行区分,本文将前者称为关键缩略图,后者称为推荐缩略图序列。
本文的贡献在于:①提出一个完整的视频缩略图推荐框架,该框架能够根据描述语句推荐相关联的视频缩略图序列;②提出一种深度视觉语义嵌入模型,模型将整个语句的语义特征与图像的视觉特征嵌入到共同的潜在空间中以获得两者的相关性;③在已有相关数据集的基础上,创建适用于本文任务的数据集,并取得较好的结果。
1 相关工作
大部分视频分享网站都用到了视频缩略图自动生成技术,但一些视频分享网站的视频缩略图通常是来自于视频的固定某个时序位置(第一帧、最后一帧或者中间帧),或者借助相关的图像捕获工具随机从视频中捕获一张图片作为视频缩略图。很显然,这种方法获取的视频缩略图不具有代表性并且选取的图片质量也得不到保证。
为了让自动生成的视频缩略图更具有代表性,Gao等[1]提出了一种反映视频内容主题的视频缩略图提取算法,他们注意到基于视频帧颜色和运动信息等底层特征的所选帧可能不具有语义代表性,所以使用主题标准对生成缩略图的关键帧进行排序。Lian和Zhang[2]提出使用包含正面人脸信息、侧面人脸信息的高级视频特征与包含灰度直方图、像素值标准方差等低级视觉信息特征进行融合来选择最后的缩略图的方法。Jiang和Zhang[3]提出一种矢量量化方法来生成视频缩略图,利用视频时间密度函数(VIDF)来研究视频数据的时间特性,使用独立分量分析(ICA)构建空间特征。Liu等[4]提出了一种查询敏感的动态网络视频缩略图生成方法,所选的缩略图不仅在视频内容上具有代表性还满足了用户的需求。而Zhang等[5]结合其之前在文献[6]中所提出的基于图像质量评估和视觉显著性分析的视频缩略图提取方法以及在文献[4]中发表的方法,提出一种综合考虑图像质量评估、图像的可访问性、图像的内容代表性以及缩略图与用户查询的关系等因素的方法,推荐出同时满足视频用户与浏览器需求的缩略图。Zhao等[7]在基于视觉美学的自动缩略图选择系统[8]的基础上提出一种利用视觉元数据和文本元数据来自动合成类似杂志封面形式的视频缩略图方法;所推荐的缩略图不是取自于原视频,而是通过自动合成来得到的。
上述的部分视频缩略图选择方法[2-3,6]都集中于单纯从视频内容来学习视觉代表性。文献[1,4-5]研究了如何将查询与视频内容相结合来为不同查询提供不同的缩略图,但是他们都是使用基于搜索的方法。而Liu等[9]首次引入基于学习的方法,将深度视觉语义嵌入模型应用到视频缩略图生成任务中,开发一种多任务深度视觉语义嵌入模型,将查询和视频缩略图映射到一个共同的潜在语义空间,直接计算查询与视频缩略图之间的相似度,使得应用可以根据视觉和边缘信息自动选择依赖于查询的缩略图,但该方法的局限在于所用查询是以Word Embedding(词嵌入向量,是指将一个单词转换成固定长度的向量表示形式)嵌入到潜在空间中,且一次只能获取单个单词的Word Embedding表示。对于查询语句或者多个查询关键词需要将查询以单词的向量形式依次与视频帧特征进行相似度匹配,这种匹配方式忽略了查询单词之间的关联信息。此外,文献[9]中的视频帧特征只使用简单几层的CNN进行提取,所提取的视频帧特征也不够丰富。本文提出的基于深度视觉语义嵌入的视频缩略图提取方法框架如图1所示。首先使用预训练的深度CNN有效地依次提取各关键帧的视觉特征,同时使用基于RNN的神经语言模型将整个语句的语义特征嵌入到一个固定的向量,使得语义特征不但包含了单词之间的关联信息,也更易与视觉特征进行相关性比较。

图1 基于深度视觉语义嵌入模型的视频缩略图推荐框架Fig.1 Video thumbnail recommendation framework based on deep visual-semantic embedding model
2 深度视觉语义嵌入学习方法
基于深度视觉语义嵌入的缩略图推荐学习方法首先需要训练深度视觉语义嵌入模型,然后利用该模型实现缩略图推荐。因此本节首先介绍深度视觉语义嵌入模型,然后介绍整个视频缩略图推荐框架。
2.1 深度视觉语义嵌入模型
深度视觉语义嵌入模型[10],实现将从文本域中学习的语义信息和图像中的视觉信息共同嵌入到一个潜在的空间中,以便直接计算文本与图像之间的相关性。并且对于与图像内容无关的语义信息也能够根据与图像之间的相关性,返回相关性较高的图像[9]。而本文的任务就是从视频中选择与给定的语句语义相关的视频帧作为推荐的视频缩略图,因此可利用深度视觉语义嵌入模型来计算给定的语句信息与视频帧之间的相关性。所提出的深度视觉语义嵌入模型框架如图2所示。首先使用预训练的CNN依次提取视频关键帧序列的视觉特征,再使用基于RNN的神经语言模型来提取文本的语义特征,并将视觉特征与语义特征嵌入到视觉语义潜在空间。
近年来,RNN由于具有特定的记忆功能已经在处理序列问题和自然语言处理等领域取得了很大的成功,所以本文使用RNN的变式即擅长解决中长文本序列间依赖问题的门控循环单元(GRU)[11]来提取单词之间的依赖信息。对于给定的描述语句,本文方法不再是简单的提取一个单词的Word Embedding来作为其特征向量,而是将一句话中的所有单词都用Word Embedding表示,然后将整句话作为序列输入GRU单元,最终输出一个表达这句话语义特征的向量,这也是典型的多对一关联模型,其主要结构如图3所示,本文方法使用GRU的最后一层隐层状态hn,作为语义特征Vs:
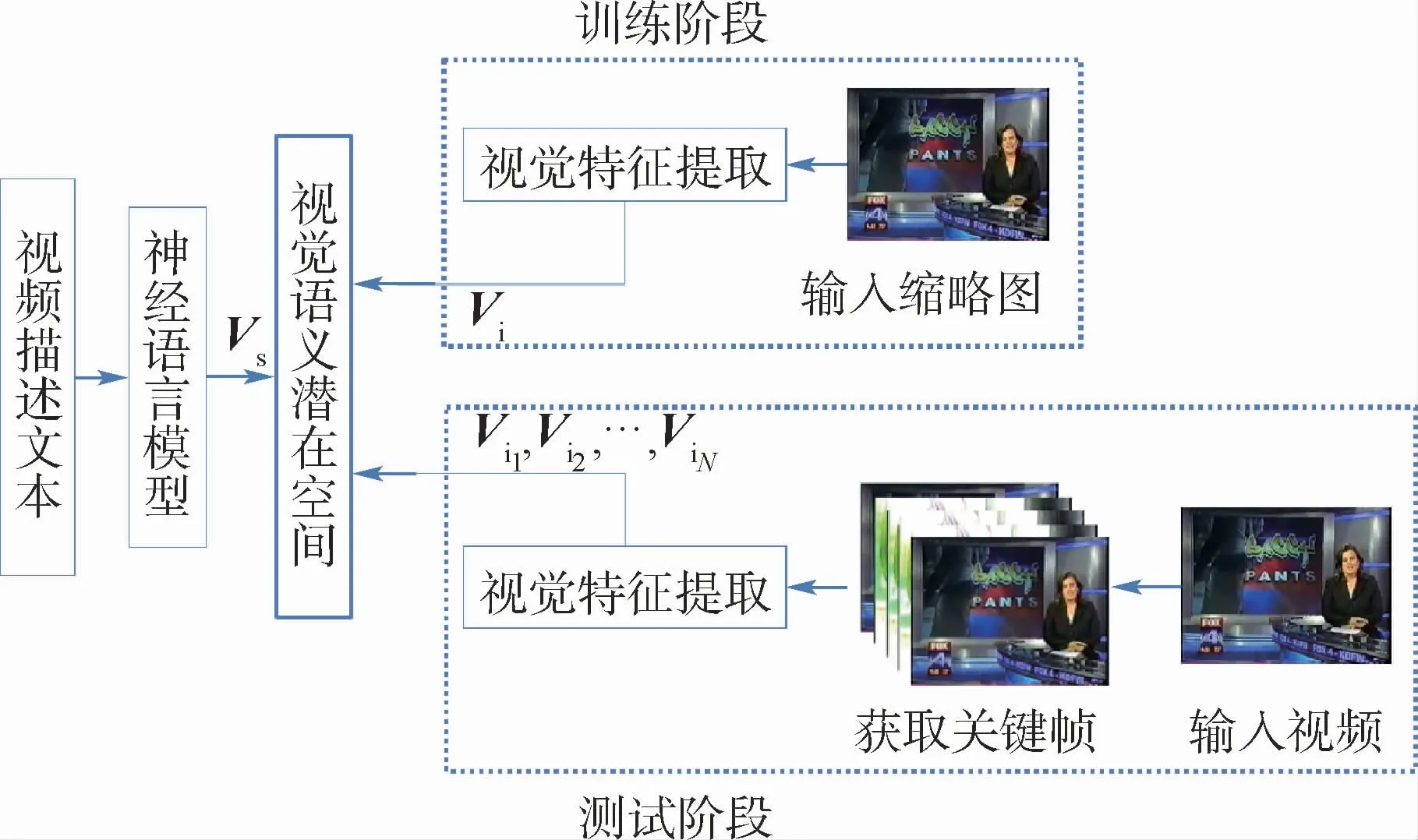
图2 深度视觉语义嵌入模型示意图Fig.2 Schematic diagram of deep visual-semantic embedding model

式中:w1,w2,…,wn为单词序列x1,x2,…,xn的Word Embedding形式;n为输入的单词个数。
本文方法使用预训练好的 ResNet152模型[12]来提取视频帧的视觉特征,由于所提方法旨在将视觉特征嵌入到固定的潜在空间,因此需去除ResNet网络的最后一层全连接层,并提取最后一个卷积层的特征得到视觉特征Vi。
将语义特征和视觉特征分别嵌入到一个N维的潜在空间得到潜在语义特征V′s和潜在视觉特征V′i。为使语义特征向量尽可能地拟合提取到的视觉特征,本文采用均方误差损失函数:

式中:MSE函数用于计算两个向量之间的均方误差;N为潜在空间的维度(本文中是2 048维)。
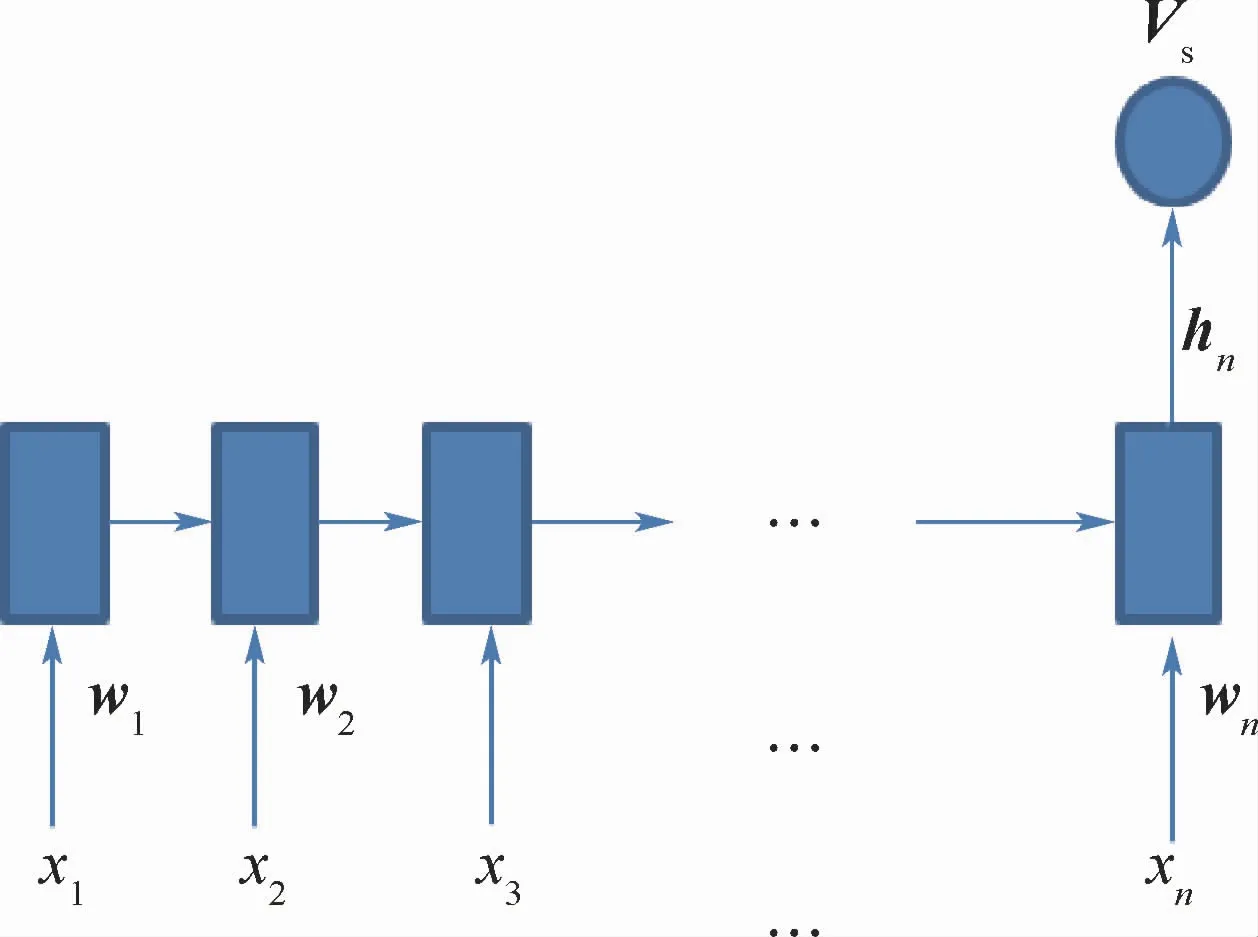
图3 神经语言模型Fig.3 Neural language model
2.2 基于深度视觉语义嵌入模型的缩略图推荐
本节将介绍如何利用上述深度视觉语义嵌入模型来为一段视频选择缩略图。本过程分为2个阶段,分别是关键帧提取和缩略图推荐。
2.2.1 关键帧提取
本文方法使用基于顺序聚类与K-means聚类相结合的关键帧提取算法对视频进行镜头分割。参考文献[13]中的视频镜头分割算法,对视频进行初步聚类。首先将视频帧映射到HSV(Hue,Saturation,Value)颜色空间,将3个颜色空间分别分成12、5和5三个量级,生成对应的归一化颜色直方图。将3个颜色空间的直方图结果组合到一起为每个视频帧生成一个22维的颜色空间向量。再用顺序聚类方法对转换过的视频帧进行镜头分割[13]。对顺序聚类后的每个类的视频帧依次进行清晰度、亮度、色偏检测,并将最后检测的得分进行加权融合,得出图像质量评价得分Df,检测方法如下:
清晰度检测:使用Tenengrad梯度函数来计算每个视频帧的清晰度得分fd,得分越高,图像越清晰[14]。
色偏检测:将RGB图像转变到CIE L*a*b*空间(L*表示明暗度,a*表示红-绿轴,b*表示黄-蓝轴),通常存在色偏的图像,在a*分量和b*分量上的均值会偏离原点很远,方差也会偏小;计算衡量图像色偏程度的K因子得到色偏检测得分fc,分数越高,图像色偏越严重[15]。
亮度检测:与色偏检测相似,计算图片在灰度图上的均值和方差,当存在亮度异常时,均值会偏离开均值点(假设为128);同样根据计算衡量图像亮度程度的K因子得到亮度检测得分fb,分数越高,图像亮度异常越严重。
最后的图像质量评价得分为3种评价属性的得分的加权融合。本文设置清晰度检测的权重为0.5,亮度检测的权重为0.3,色偏检测的权重为0.2,由于图像质量与亮度检测得分fc以及色偏检测得分fb成反比,所以最后的得分Df为
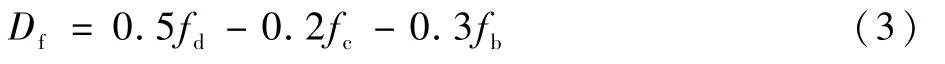
得到每个视频帧的图像质量得分Df后,通过分数排序将每个聚类中分数较低的一半视频帧过滤掉(对只包含一个视频帧的聚类不进行过滤)。获得过滤后的视频帧和聚类数K0。接下来对过滤后的视频帧再进行K-means聚类,K值设置为K0,得到最后的镜头分割结果。
如图4所示,将视频帧进行镜头分割后,需要从每个镜头中提取能够充分代表视频镜头的视频帧添加到关键帧序列以及为每个视频镜头挑选候选缩略图序列。
关键帧序列是从每个视频镜头中挑选出最具代表性的一个视频帧组成的序列,其将作为视觉语义嵌入模型的输入以获得关键帧的视觉特征序列。模型输出关键帧的视觉特征序列中与输入的文本语义特征相关性最高的视觉特征所对应的关键帧作为关键缩略图。
候选缩略图序列是对关键帧序列的扩充,从每个视频镜头中挑选最具代表性的某几个视频帧,组成该视频镜头的候选缩略图序列。每个视频镜头都有一个候选缩略图序列,它们之间是独立的。如果关键缩略图属于这个视频镜头,那么这个镜头的候选缩略图序列就会成为最后的推荐缩略图序列。

图4 基于已训练模型的视频缩略图推荐框架Fig.4 Video thumbnail recommendation framework based on trained model
为了从每个镜头中提取合适的视频关键帧,本文使用熵值来作为视频信息量的度量,熵值越大,表明图像的信息越丰富,越具有代表性,在本文中,分别计算HSV三个颜色空间的熵值,其计算式为

式中:Pk为每个视频帧生成归一化颜色直方图的值。然后分别计算出H 分量的熵值E(fh),m=12;S分量的熵值E(fs),m=5;以及V分量的熵值E(fv),m=5。由于人眼对Hue的敏感性比对Saturation和Value高[11],所以本文中对H、S、V三个分量的熵值分别赋0.5、0.3、0.2的权重,最终的熵值E(f)为
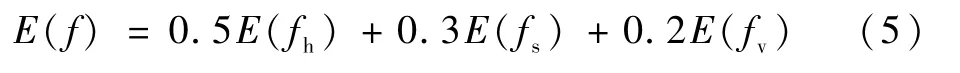
得到视频镜头中每个视频帧的熵值E(f)后,本文提取每个镜头中熵值最大的视频帧作为该镜头的关键帧添加到关键帧序列。提取熵值最大的前5个视频帧(不足5帧的镜头取全部视频帧)作为该镜头的候选缩略图序列。所以每个镜头的关键帧也包含在该镜头的候选缩略图序列中。由于聚类数是由顺序聚类结果而定,所以聚类数(视频镜头数)是不固定的,取得的关键帧序列的数量也是不固定的。
2.2.2 缩略图推荐
缩略图推荐,如图4所示,获取关键帧序列之后需要对所有的关键帧进行视觉特征提取得到视觉特征序列Vi1,Vi2…,ViN,并将这些视觉特征都映射到视觉语义潜在空间中。对于输入文本,使用2.1节中训练好的神经语言模型提取语义特征Vs,并将其也映射到视觉语义潜在空间中。分别计算潜在语义特征V′s与潜在视觉特征序列,…,V′iN之间的余弦相似度,相似度最大的视觉特征所对应的关键帧将作为关键缩略图。为了增加推荐缩略图的多样性与可选择性,如果某个关键帧被选取作为关键缩略图,由于与关键缩略图在同一个视频镜头中的视频帧可能具有相同的视觉特征,因此将关键缩略图所在镜头的候选缩略图序列作为最后的推荐缩略图序列。显然,推荐的缩略图序列,必然包含关键缩略图,推荐的缩略图序列最少包含1帧,最多包含5帧。
3 算法实现
3.1 数据集
本文的关键是训练深度视觉语义嵌入模型,在训练阶段需要采用深度学习中的有监督学习方法,所以首先要解决的就是数据集问题。已存在的缩略图生成方法都是在图像质量评价或建立关联模型等图像处理的层面来获取对应的缩略图,并且都是依赖于选择算法的缩略图生成方法。所以目前还没有专门针对缩略图推荐任务的数据集可供训练,本文只能自行收集或者对已有的相关数据集进行改动使其满足对本任务的训练。
首先考虑的是微软的MS COCO 2014[16]数据集,该数据集中包含8万多张训练图片,4万多张测试图片,由于该数据集是做图像字幕(image captioning)任务常用的数据集,所以每张图片都有5个左右的人工标注文本语句来对图像内容进行描述。图像字幕任务是输入一张图片得到一个描述该图像内容的句子,本文提出的基于深度视觉语义嵌入的视频缩略图推荐任务,虽然是基于视频的任务,但实质上是根据输入一句视频描述文本,从视频中获取与文本内容相关联的一张图像。相比于图像字幕任务,本文的任务是从文本到图像的一个相反的过程,所以可以将MS COCO 2014数据集中的标注语句作为模型的训练数据,将图片作为目标值来进行模型的训练,获得用于训练的{语句,缩略图}对。
另一个数据集是微软的MSR-VTT(MSR Video-to-Text)[17],该数据集是用来做视频相关任务,比如视频字幕。数据集中每段视频大约有20条描述性语句,每段视频时长在20 s以内。由于本文的训练目标是获得图像,所以需要对此数据集进行重新标注,生成适合本任务的数据集。本文根据MSR-VTT数据集提供的描述性语句从对应的视频中选出与语句内容最相关并且视觉效果较好的视频帧,组成训练需要的{语句,缩略图}对。由于该数据集中有很多存在偏义以及无法从视频中获得相关视频帧的描述语句,所以本文对原数据集提供的描述语句进行了筛选,每段视频只留取10句左右的描述语句。之所以要在MS COCO 2014数据集训练后还用这个视频数据集来训练是因为MS COCO 2014数据集图片之间的差异较大,图片之间以及标注文本之间的关联性较小,不利于细节处的学习。而从MSR-VTT数据集中选出的句子有些来源于同一段视频,所以语句之间的关联性较大,而对应的图片之间也会存在一定的联系,更有利于模型的学习。最后从MSR-VTT数据集的前400段视频中收集了4 000多个描述语句以及对应的800多个视频帧,其中不同的标注文本可能会对应同一个视频帧,最后得到包含4 000多个{语句,缩略图}对的数据集。
3.2 模型的训练
3.2.1 文本预处理
所使用的语料库来源于MS COCO 2014数据集中的标注文本。首先将所有标注语句中的单词都转化为小写形式,然后使用NLTK工具包中的word_tokenize函数对句子进行分词处理,并将标点符号都移除。对每个单词出现的次数进行统计,将出现频率小于3次的单词移除。再加上<pad><unk>这2个补齐和补缺的标注符,一共得到8 576个单词的语料库。对于输入的文本语句,需要将语句中单词映射成词汇表中对应的单词序列号,并且将每条语句的长度都设置为30,语句长度不够就用<pad>对应的序列号补齐,在语料库中找不到对应单词则用<unk>对应的序列号代替。
3.2.2 图像预处理
训练阶段的缩略图图像以及测试阶段的视频关键帧在进行视觉特征提取之前,需要将图像缩放到224×224大小。然后使用预训练的Res-Net152网络模型对图像进行特征提取,并将最后一个卷积层的特征保存下来,得到一个2 048维的特征向量。
3.2.3 参数设置
训练模型阶段:数据集形式为{语句,缩略图}对,潜在语义空间的维度是2 048维。训练神经语言模型时,设置Word Embedding维度为512,输出的语义特征维度为2 048。由于2个数据集的规格不同,需要对其进行分开训练,先在MS COCO 2014数据集上进行训练,设置BatchSize为128,学习率为0.001,学习了2个epoch。然后在MS COCO 2014训练的基础上再在处理过的MSR-VTT数据集上进行训练,设置BatchSize为16,学习率为0.001,学习了100个epoch。所有的参数都使用Adam优化器进行优化。
在生成缩略图阶段:首先对视频每6帧提取一帧作为视频的输入,在进行顺序聚类时,经过多次实验将阈值设置为0.85。顺序聚类所得的聚类数作为K-means聚类的K值。
4 实验结果
为了有效地对本文提出的框架进行评估,本文分别从YouTube和优酷网站下载了不同类别的视频来测试该框架推荐的视频缩略图的效果。用于测试的视频类别主要有:教育、娱乐、电影、游戏与卡通、新闻与政治、生活、体育等。使用击中率HIT@l[9]作为评价指标,即推荐的缩略图序列中如果有与描述语句的语义内容相匹配的缩略图则为击中,反之如果推荐的缩略图序列中的所有缩略图与语句描述之间都不相关的话则为不击中。本文为了合理地显示实验结果,共设置了3个等级:A表示推荐的缩略图序列中有与语义内容完全相关的缩略图,称为完全击中;B表示推荐的缩略图序列中有与语义内容部分相关的缩略图,称为一般击中;C表示推荐的缩略图序列与所给出的语义内容完全不相关,称为完全不击中。
本文为每个类别各选取2~4段视频,每个视频时长在3 min左右,且都包含了多个场景的切换。针对每段视频,结合所给的5个描述文本语句,分别进行缩略图推荐。根据每个描述文本语句从对应的视频中挑选出关键缩略图作为默认缩略图,同时返回1~5个视频帧作为推荐的缩略图序列供用户选择。
本文采用主观评价的方式来测定方法的有效性,邀请10位了解过视频缩略图任务的用户对本文方法的推荐结果进行了主观打分评价。即针对每段视频的每条描述文本语句所推荐的缩略图序列,结合上述给出的3个评价等级来对推荐的结果进行评价,在实验测试集上获得的评价结果如表1所示。从击中率可以看出,所提方法对生活、电影与娱乐类视频所推荐的视频缩略图有较好的效果,而对游戏与动画、教育类的视频效果不是很理想。
图5给出了部分推荐缩略图示例,每个示例的第一个视频帧即是选出的关键缩略图,剩余为推荐的缩略图序列。其中图5(a)显示的是完全击中的视频缩略图(生活类视频的推荐结果),图5(b)显示的是完全没有击中的视频缩略图(体育类视频的推荐结果)。从图5(a)中可以看出,针对每个描述文本语句,可得到1~5幅推荐缩略图,推荐的缩略图与给出的语句内容完全相符,而且缩略图序列具有一定的丰富性,增加了用户的可选择性;但从图5(b)中看出,该方法针对体育类的视频效果并不是很好,一方面是因为体育类的视频包含较多的大幅度运动,不能很好地提取和表征其视觉特征;另一方面是所采用的描述文本语句,如果其本身较复杂不易被理解,则会影响所提取的语义特征表达,最终使得本文所描述的视觉语义嵌入模型不能很好的拟合。

表1 不同类别网络视频的击中率Table 1 Hit r ates of web videos in different categories

图5 本文方法所获得的推荐缩略图序列示例Fig.5 Examples of recommended thumbnail sequence obtained by proposed method
此外,由于不是在专门的缩略图推荐评测视频集上测试,且训练集中所使用的{语句,缩略图}对中缩略图特征表达受限,所以本文方法目前对于通俗简单易懂的描述文本语句有较好的效果,而对描述复杂理解偏难的语句,并不能较好地推荐出合适的缩略图序列,因此还具有很大的改进空间。
5 结 论
1)本文针对网络视频缩略图的自动推荐问题,提出一种深度视觉语义嵌入模型和缩略图推荐框架,实现了将图片的视觉信息与语句的语义信息嵌入到共同的潜在空间。
2)本文提出的框架能有效地根据给定的描述语句为用户推荐内容相关且具有视觉代表性的视频缩略图序列。20段3 min左右的视频,100条描述语句,推荐的缩略图序列完全击中率为35.0%,完全击中与一般击中的总比率为68.3%。
3)本文提出的框架能够为用户推荐细节多样化的缩略图,推荐的缩略图语义场景相同但具体细节不同,增加了用户的可选择性。
4)对视频表观内容有较好描述的文本语句,能够获得更好的缩略图推荐结果;但对视频中的运动信息表征识别能力偏弱,导致缩略图推荐结果受影响。
由于没有专门针对本文任务的数据集,所训练模型的准确度还有待改进。今后也需要在关键帧提取以及语料库上进行算法调整,以便进一步提高模型的准确度。
