基于煤矿预警监测的数据挖掘算法应用研究
2019-12-27张丁
张 丁
(1.太原理工大学,山西 太原 030001;2.中国太原煤炭交易中心有限公司,山西 太原 030024)
0 引言
煤炭企业生产工作环境区域狭隘,照明情况差,存在易燃易爆气体等固有的特点决定了其高危行业的属性。随着技术的不断发展,大部分煤矿陆续部署实时监控的安全监控系统,但各系统之间缺乏对整体的有效管控,导致大量安全隐患数据激增,难以通过科学方法对安全生产环境进行预警监测。为了更好地进行生产过程监测与管理决策,对隐患数据的发掘提出了新的要求。数据挖掘技术通过对各类隐患数据的收集处理、预测分析,可以很好地跨越限制[1]。本文通过对煤矿生产过程中的隐患数据建立数据仓库,采用关联规则算法进行数据挖掘分析预测,实现对煤矿生产的安全预警,起到对生产安全事故的预防和指导作用。
煤矿生产是一个动态复杂的过程,涉及到隐患数据众多,预警监测数据挖掘模型分为数据采集与重构、关联算法挖掘及预测分析3大模块。
1 数据准备
1.1 数据采集与重构
数据准备工作是关系到数据挖掘成功与否的重要步骤,占据整个数据挖掘工作超过60%的工作量[2]。由于各监测系统的数据格式等无法满足需要,将所有与业务系统相关的原始数据进行收集,录入到满足数据挖掘要求的数据库中。
本文主要针对煤矿安全生产过程中的隐患数据进行挖掘。为提高开发效率,缩短开发周期,使用SQL Server 2008数据库管理工具,对不同数据源进行数据转换处理,导入生成隐患参数数据库,使用OLAP提供的应用接口进行数据统计和数据分析,提取关联规则,预测分析,为用户提供决策支持服务。使用的开发工具及其作用,见表1。
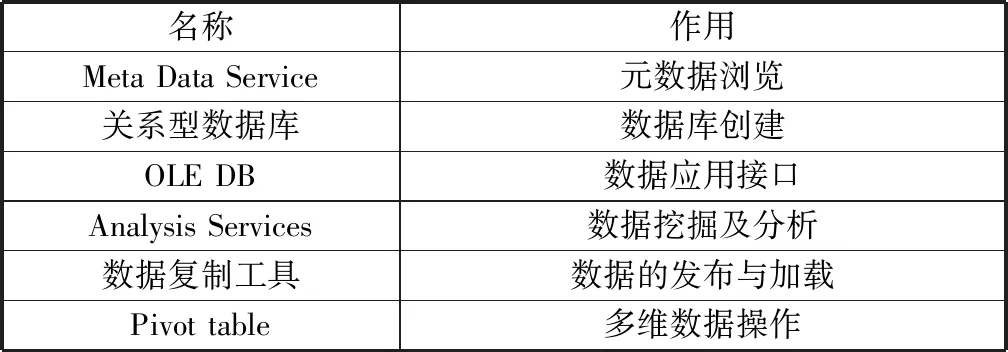
表1 数据库开发工具及作用
生成的隐患数据库包含:瓦斯浓度、瓦斯压力、温度、通风量、煤层厚度等。
1.2 数据预处理
经过重构的数据大多数存在噪声,包含空值及不一致数据,为保证数据挖掘算法效率,提高关联规则的有效性,需要对数据进行预处理。例如,清洗与挖掘关联规则无关的数据采集人等冗余属性,删除孤立数据,可以有效地降低数据复杂度。将数据关联规则挖掘作为预测分析结果,以瓦斯浓度数据为例,将瓦斯浓度、通风量、温度、煤层厚度等处理形成部分数据表,如表2。
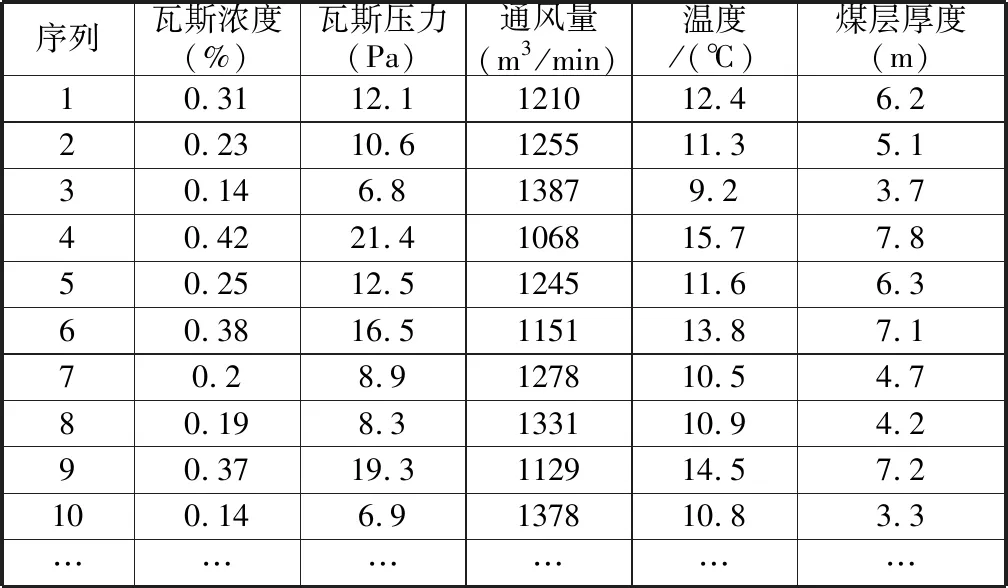
表2 隐患数据表
2 Apriori关联规则挖掘算法
2.1 数据挖掘的相关概念
关联规则算法是从事务数据库的大量随机、模糊的数据中,通过数据提取挖掘出数据之间的关联性及依赖性,发现对分析结果有价值的知识,可描述如下:
设I={i1,i2,…,im}是由m个不同的数据项组成的集合。设D是在I上的事务集合,它由各个事务所组成,记为D={t1,t2,...,tn},其中ti(i=1,2,...,n)是单个事务,ti都对应I上的一个集合Iti,它是I的一个子集,即Iti⊂I,有一个唯一的标识符TID。若项集X⊂I且X⊂T,则事务T包含项集X[2]。
关联规则就是形如:X⟹Y[support=s%,confidence=c%]的规则[3],其中X和Y都是项的集合且X⊆I,Y⊆I,X∩Y=φ。support=s%表示规则的支持度为s%,即事务数据库D中有s%的事物包含X和Y;confidence=c%则表示规则的置信度为c%,即事务数据库D中包含X的事务中有c%的事务也包含了Y。
频繁数据项集:假设用户设定最小支持度为min_support,称min_support为支持度阈值,其中对于支持度大于支持度阈值的项集,我们称之为频繁项集,也叫大项目集。
强关联规则:对于事务集合D,强关联规则是指满足不小于最小支持度min_support,且不小于最小置信度min_confidence的频繁数据项集。此时,关联规则X⟹Y被称为强关联规则。
2.2 关联规则算法挖掘步骤
对数据进行关联规则挖掘的首要任务是给出最小支持度和最小置信度阈值。主要分为两个步骤:1) 依据最小支持度,产生频繁项集;2) 由步骤1) 频繁项集和最小置信度确定生成强关联规则。示意图如图1。
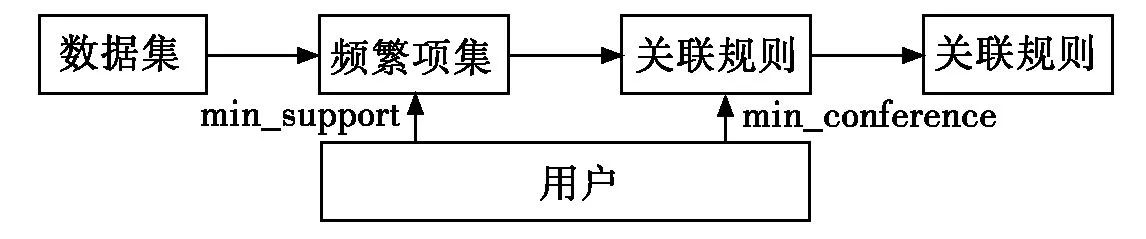
图1 关联规则挖掘算法模型
关联规则挖掘的一种经典算法为R.AGRAWAL等人提出的Apriori算法,其核心思想为:递归扫描事务数据库D,直至生成全部频繁项集,找到满足设定条件的关联规则。步骤如下:
1) 扫描事务数据库全部数据,得到1-项集合C1;
2) 依据给定支持度阈值min_support,由1-项集合C1得出频繁1-项集合K1;
3)i>1时,重复步骤4-6;
4) 对得到的Ki集合进行连接剪枝,得到(i+1)-项集合Ci+1;
5) 依据给定支持度阈值min_support,由(i+1)-项集合Ci+1得出频繁(i+1)-项集合Ki+1;
6) 如果集合K≠Ø,i=i+1,转到步骤4,如果K=Ø,则转到步骤7;
7) 依据给定的置信度阈值min_confidence,得到满足条件的频繁集则为关联规则,算法结束。
3 挖掘结果预测分析
本文采用Apriori算法挖掘数据关联规则,例如针对瓦斯浓度数据表中的所有的相关属性进行关联规则挖掘,而不仅仅局限于某一个特定属性。而Apriori算法需要处理量化后的离散值,所以需要首先对数据离散化,得到不同的分布区间。设定瓦斯浓度的类型标号为Q、瓦斯压力为R、通风量为S、温度为T及煤层厚度为U。我们依据数据表中属性值的情况得到:瓦斯浓度的分布区间为Q1:[0-0.16],Q2:(0.16-0.30],Q3:(0.30-~];瓦斯压力的分布区间为R1:[0-7],R2:(8-16],R3:(16-~];通风量的分布区间为S1:[0-1200],S2:(1200-1300],S3:(1300-~];温度的分布区间为T1:[~-11],T2:(11-15],T3:(15-~];煤层厚度的分布区间为U1:[0-4],U2:(4-7],U3:(7-~]。离散化的数据表分布如表3。
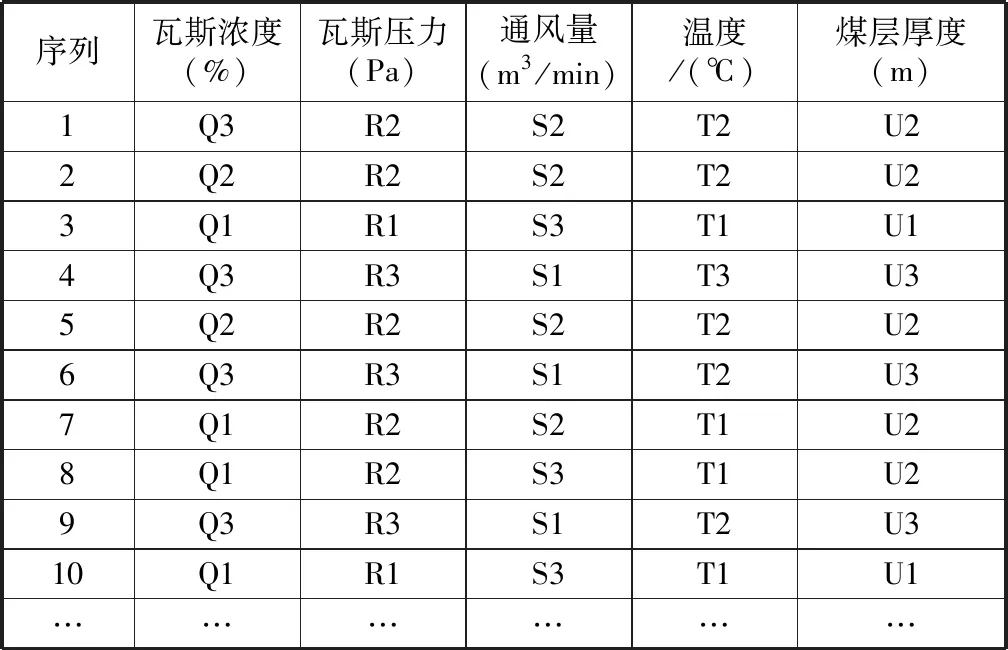
表3 离散化隐患数据表
我们设定最小支持度阈值min_support=0.45,最小置信度阈值min_confidence=0.75,使用Apriori算法对数据进行关联规则挖掘,得到部分关联规则如下:
(1)S1⟹Q3;(2)Q3⟹R3;(3)T1⟹R1;
将对应的区间类型标号对应数据区间,则关联规则(1)的实际含义为:煤矿中通风量等级越低,则矿道内瓦斯浓度等级越高;关联规则(2)的实际含义为:矿道中瓦斯浓度等级越高,则瓦斯压力等级也越高;关联规则(3)的实际含义为:矿道中温度等级越低,则瓦斯压力等级也越低。
根据得到的部分关联规则,发现煤矿生产过程的隐患数据之间的数据关联与实际生产的客观事实相吻合。所以,我们利用得到的关联规则,可以很好地对生产过程进行防范,从而降低生产事故的发生几率。
4 结束语
本文以煤矿生产过程隐患数据的监测预警为背景,针对数据种类繁多、复杂,数据量大的特点,构建数据仓库,提出了采用Apriori数据挖掘算法进行数据之间关联规则挖掘,得到的关联规则为实际生产提供了较好的参考意义,有效地降低了煤矿安全事故的发生几率。采用传统的Apriori算法复杂度较高,存在较大的优化空间,如何降低算法复杂度,取得更好地关联规则挖掘效率是在此基础上,下一步研究的方向。
