基于SSD模型的道路交通标志识别方法研究
2019-12-24李泽滨裴崇利
李泽滨, 裴崇利
(中通客车控股股份有限公司, 山东 聊城 252000)
交通标志的识别是智能客车环境感知的主要组成部分,对于规范驾驶员驾驶行为,保障道路安全具有重要的意义[1]。为了提高车辆感知系统识别交通标志的速度和精度,本文提出一种采用SSD深度学习框架的交通标志识别方法。
1 交通标志识别研究现状
得益于机器视觉和图像处理技术的发展,工业相机作为一种高效、廉价的传感器被广泛地应用于客车安全辅助驾驶技术。在交通标志检测方面,视觉传感器与其他传感器相比具有更强的细节捕捉能力,在图像颜色、形状识别方面有着天然的优势。传统基于视觉的交通标志识别方法大多是基于先验知识进行特征提取,无法对每一类交通标志进行精确描述。而且依赖单一特征的传统算法,其识别的准确性和鲁棒性有待提高[2-3]。相比传统的交通标志识别算法,深度学习通过多层神经网络自动地学习和提取交通标志特征,对交通标志的识别和检测具有更好的准确性,但是实时性略显不足[4]。为了兼顾交通标志检测的准确性和实时性,本文提出一种采用SSD深度学习框架的交通标志识别方法,并对SSD模型进行了改进。SSD(Single Shot MultiBox Detector)是一种通用的深度学习目标检测模型,由LIU W等人2016年在ECCV上提出[5]。本文以SSD模型为基础,采用高效、轻便的MobileNet V3特征提取网络代替了原模型中庞大的VGG16网络。改进后的模型较好地兼顾了目标检测的实时性和准确性的要求,通过对标注的交通标志图进行有监督地学习,可以实现交通标志的识别和检测,基于SSD的交通标志识别方法的主要内容如图1所示。下面将其中几个重点进行详细介绍。
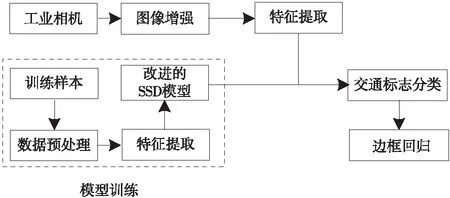
图1 基于SSD识别方法的主要内容
2 工业相机和镜头选型与匹配
为了保证相机能够清晰地捕获交通标志信息,同时满足采样频率对于实时性的要求,本文最终选择德国Basler公司生产的acA800-200gm工业相机。相机选好后,还要对镜头进行选型。
镜头选型主要考虑的是相机的有效工作距离和水平视角[6],这两项参数的确定主要与车辆的安全车距和驾驶员的安全视野有关。根据我国道路交通安全法的规定:机动车在高速公路上行驶,当车速超过100 km/h时,安全车距为100 m以上;车速低于100 km/h时,最小安全车距不得小于50 m[7]。根据大型客车高速行驶工况,确定相机的有效工作距离至少为100 m。实际上当相机有效工作距离满足高速环境的需求时,也必然满足城市道路的检测需求。考虑到驾驶员和车辆响应时间大约为1.2 s,最终确定相机的有效工作距离为130 m。
驾驶员的感受视野宽度跟车速呈反比,静止状态下人眼的感受视野大约为210°,车速在70 km/h和100 km/h时驾驶员的感受视野分别约为65°和40°[6]。
综合考虑有效工作距离和水平视角与相机硬件之间的约束关系,最终确定镜头的水平视角为70°。通过相机选型助手软件计算获得相机和镜头的参数见表1。
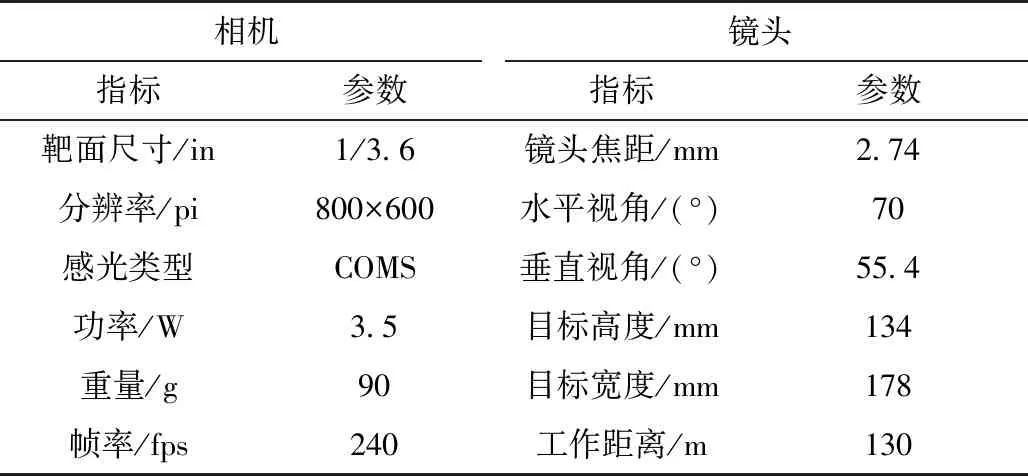
表1 相机和镜头参数
3 深度学习框架SSD模型
从2012年起,深度学习在图像领域的识别能力已经逐渐赶超了人类[8]。自此以后深度学习算法在图像识别和检测领域占据了绝对的优势,以卷积神经网络为基础的深度学习算法也层出不穷。根据算法的工作流程可以分为两类,一种是双步法,另一种是单步法,比较经典的框架有YOLO[9-10]和SSD。随着深度学习技术的发展,单步法识别的准确率,尤其是速度远超双步法,同时SSD模型在小目标的检测上比YOLO算法更具优势,这对交通标志的识别是极其重要的。因此本文最终选择SSD作为交通标志识别的基本框架模型,并对模型进行了改进,其基本算法流程如图2所示。
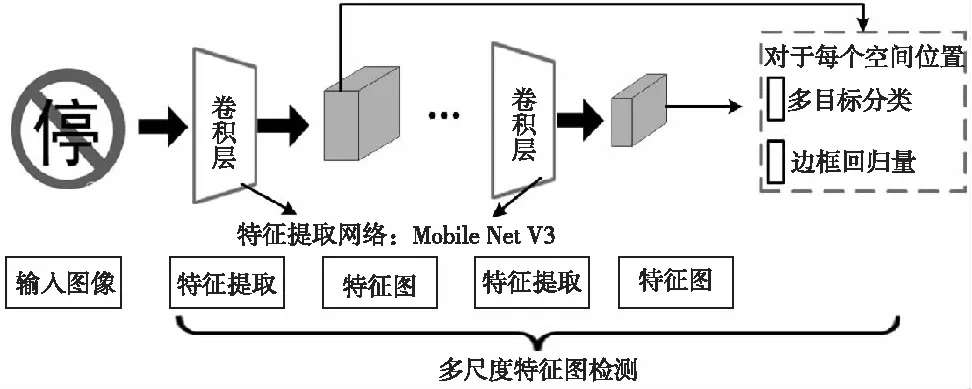
图2 改进的SSD交通标志检测流程
SSD算法的特征提取层的主网络结构是VGG16。但是VGG16是一个庞大的网络,整个网络包含有大约1.38亿个参数,这对硬件计算能力有着很高的要求,同时也不利于交通标志检测实时性的提高。为了进一步对模型进行优化,本文将VGG16主干网络采用轻量、高效的MobileNet V3进行替代和改进,并采用迁移学习的方法对模型中的基本网络参数和权重进行了继承。将最后2个全连接层改成卷积层,并随后增加了4个卷积层来构造网络结构。对其中5种不同卷积层的输出(Feature map)分别用2个不同的 3×3的卷积核进行卷积,一个是输出分类用的Confidence,每个Default box 生成21个类别的Confidence;另一个输出是回归用的 Localization,即每个边界框的位置信息,其中每个default box包含4个坐标值(x,y,w,h),用于描述回归边框的位置。为了衡量深度学习网络对交通标志分类和定位的准确性,采用损失函数对每一类指标的训练结果进行优化和微调,其中损失函数的定义如下:
L(x,c,l,g)=[Lconf(x,c)+αLloc(x,l,g)]/N
损失函数由两部分组成,一部分用来衡量分类误差,另外一部分用来衡量定位误差,其中Lconf代表置信损失,就是分类误差,Lloc代表边框定位误差。网络通过不断地训练迭代,直到各个指标的损失函数值达到期望误差值就结束网络训练。损失函数值越小,准确性越高。
4 模型构建与网络训练
4.1 数据采集与预处理
目前中国没有规模化的交通标志数据集,因此本文采用公开的交通标志数据集GTSRB进行网络训练。GTSRB是通过大量实车试验,在不同场景的道路上收集的交通标志数据库,共包含了43类交通信号,其中训练图像39 209幅,测试图像12 630幅[11]。本文根据我国交通标志的差异对GTSRB数据集的图像进行了筛选和合并,首先剔除我国交通标志法中没有的标志符号,另外对43类交通标志中常见的13种交通标志进行分类合并,共计图像10 287幅,筛选后的训练样本统计结果见表2。
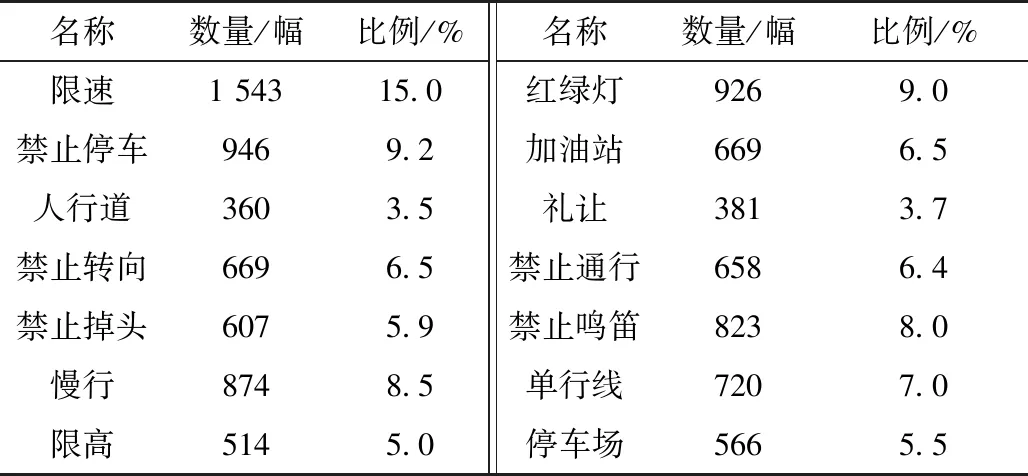
表2 筛选后的交通标志训练样本分布
由表2可知,各类型交通标志的样本数量不均衡,这不利于将来的网络训练和收敛,为了维持样本数量上的均衡,需要对数量比较少的样本进行补充,样本补充有两种方法,一种是针对数量较少的样本单独进行采集;另外可以通过图像处理的方法进行补充,比如调整对比度、翻转、镜像、裁剪等。补充后的数据集共计训练样本图像22 100幅。收集的部分训练样本如图3所示。

图3 部分训练样本
在网络训练之前还要对训练样本进行归一化、灰度化和去均值处理。归一化是将不同大小的图片像素都统一修改成45×45,归一化后的图片满足网络输入对于尺寸的要求。灰度化是一进步对图片进行压缩,去除色彩信息。去均值是用训练样本的平均值减去每个图像并除以其标准差来确定训练样本的分布中心。这些样本预处理的操作有助于提高模型在处理图像时的一致性,加速网络的收敛,提高训练的准确率。
4.2 网络训练与测试
本文的深度学习SSD模型是基于Matlab搭建的,Matlab集成了大量的深度学习图像处理函数,比如卷积,池化、随机梯度下降算法等。模型训练的迭代周期为1 400个,模型训练过程采用随机梯度下降算法进行寻优和误差的反向传播,学习率采用梯度渐变的方式,0~2 000步的学习率为0.001,2 000~4 000 步的学习率为0.000 1,4 000~6 000步的学习率为0.000 01,前期训练采用大学习率有利于加速网络收敛,后期采用小学习率对结果进行细致寻优增加网络训练的准确性。其训练过程和结果如图4所示。
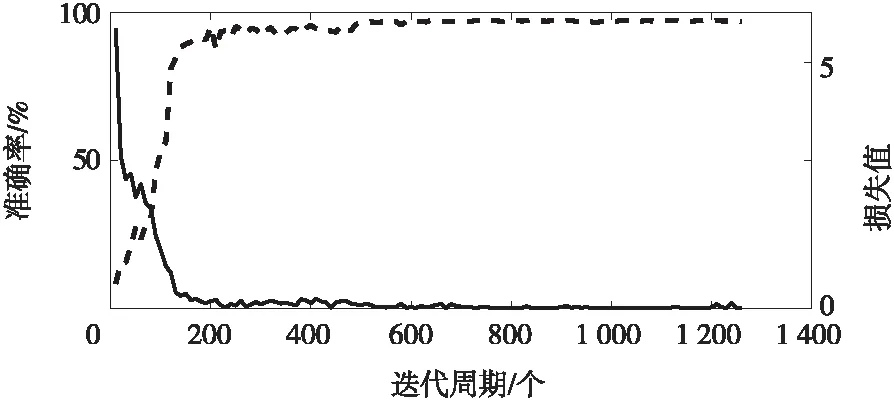
图4 网络训练过程与结果
由图4可知,在经过大约1 400个迭代周期之后网络逐渐趋于稳定和收敛,损失函数的值也逐渐趋近于0。将训练好的模型对摄像机捕获的图像进行识别测试,测试图像共计500幅,包含交通标志783个,其中成功检测交通标志753个,平均识别准确率为96.2%,单帧图像的处理速度约为50 ms。交通标志识别及其结果案例分别如图5和图6所示。
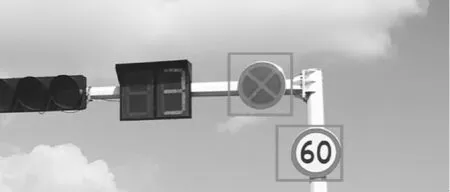
图5 交通标志识别
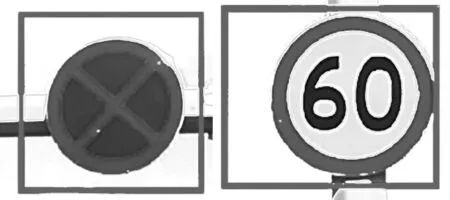
图6 部分交通标志识别结果
图5中的交通环境共有2类交通标志,分别是禁止停车和限速;由图6可知,本文的模型对这2类交通标志都能很好地完成识别。
5 结束语
交通标志的识别是客车ADAS技术的重要研究领域。如何高效、准确地实现交通标志的识别对于规范驾驶员行为,减少交通事故具有重要意义。本文提出了一种改进的SSD交通标志识别方法,试验表明该方法对交通标志识别的准确率为96.2%,单帧图像的处理时间约为50 ms,满足客车对于实时性和准确性的要求。
