基于改进BIRCH聚类算法的评价对象挖掘
2019-12-19王梦遥王晓晔洪睿琪
王梦遥 王晓晔 洪睿琪

摘 要: 本文对于意见挖掘领域中的评价对象的修剪和聚类问题,提出使用K-means聚类算法和BIRCH聚类算法相结合的方式来进行评价对象的修剪和聚类。利用BIRCH算法类别聚类的功能对评价对象进行聚类,并删除包含较少数据的簇来实现修剪评价对象;再通过对于剩下的簇使用K-means聚类算法来获得最优评价对象。这种修剪聚类方法与以往的基于PMI算法修剪然后基于K-means聚类算法相比,减少了评价对象修剪时对语料库的依赖,最终聚类的结果更加精准,而且BIRCH算法采用一次扫描数据库的策略,可以有效提高速度。
关键词: 名词词组模式;BIRCH聚类算法;K-means聚类算法;PMI算法
【Abstract】: For the pruning and clustering evaluation objects in opinion mining, this paper proposes a method that combines BIRCH clustering and K-means clustering algorithm to prune and cluster evaluation objects. Firstly, utilizing BIRCH algorithm of self-learning cluster category, after clustering by BIRCH algorithm, delete the clusters containing few data so that we can prune the evaluation objects. Then use K-means clustering algorithm to make global cluster for the remaining clusters. Compared with pruning using PMI algorithm and clustering using K-means clustering algorithm, our method eliminates the dependency on the corpus. And the cluster result is more accurate. Also BIRCH algorithm scans the database one time, so it can increase the speed greatly.
【Key words】: Noun phrase pattern; BIRCH clustering algorithm; K-means clustering algorithm; PMI algorithm
0 引言
随着电子商务行业的发展,网购在人们生活中起到越来越重要的作用,用户通过查看购物网站的评论信息来对商品有更加全面的了解。但同一产品在网络中的评论可能会达到成千上万条,给用户全部逐条查看带来了极大的麻烦,这基本是不可能实现的。而且评价信息数据量虽然极大,但信息量稀疏,也就是说不是所有的句子都是有用的,这又使得用户评论的参考价值大大降低。因此,挖掘用户评论提取出有用信息供給用户查看就显得十分必要了。
评论信息的意见挖掘是从评论信息中提取主题词的过程,主题词包括评价对象,然后对评价对象进行处理分析。目前对评价对象处理的方法有很多,比如,张俊飞[1]等人,通过改进PMI算法实现特征值提取,利用TF-IDF函数实现特征值权重计算,实现基于PMI特征值TF-IDF加权朴素贝叶斯算法;陈海红等人[2],利用信息增益法进行文本特征选取,运用TF-IDF进行特征权重设置,对支持向量机使用不同核函数,通过网格与交叉验证组合法优化参数选择,比较支持向量机在不同核函数下文本分类性能;为了减少数据集和训练方法对词向量质量的影响,王子牛、吴建华、高建瓴等人[3]提出了深度神经网络结合LSTM模型来实现情感分析;林钦、刘钢[4]等人采用关联算法挖掘商品特征的算法实现领域词典的半自动更新;孟鑫[5]等人在通用领域词典的基础上,增添领域情感词及其情感强度值,通过计算词语相似度,构建专用领域情感词典;李春婷[6]等人将模糊认知图理论应用于词语聚类,实际上属于基于神经网络的聚类方法。
在前人研究的基础上,本文采用名词词组模式来提取主题词,然后使用BIRCH算法[7]与K-means聚类算法[8]相结合的方法对评价对象进行修剪和聚类[9]。
1 主题词的抽取
主题词抽取首先对评论信息进行预先处理。处理工作主要分两个部分:评论中经常会包含明显的无效信息,比如,QQ号、电话号码或网址的句子有做广告的嫌疑,重复出现的句子没有意义,首先将这类评论删除。之后是对句子进行分词和词性标注,由于我们主要依靠形容词判断句子情感,所以删除不含有形容词的评论。分词采用中科院的分词工具ICTCLAS2015[10]。
抽取主题词[11]的关键在于评价词和评价对象的抽取。对于评价对象的抽取,总结为对名词、动名词、名词短语的抽取,本文通过分析句式,构建了以下四种名词词组形式:n和n和n、n和n、n的n、nn或n,进而对句子进行匹配并抽取主题词。具体抽取步骤如下:
(1)使用上面几种名词词组对于评论中的分句进行匹配,根据此来确定评价对象,并同时匹配形容词或其他词性来抽取评论信息;
(2)若分句中只有评价词而没有评价对象,则将其前面分句中的评价对象作为该分句的评价对象;若前面分句也没有评价对象,则该分句中的评价对象为隐式的,此时通过创建评价词和评价对象的语义集的方法来确定隐式评价对象。
(3)若分句中只有评价对象没有评价词,则保存,如果后续没有评价对象,则将其作为此分句中评价词的评价对象;
(4)本文采取建立语义相关集的方法来抽取隐式评价对象,如下:
1)统计已抽取出的评价词和评价对象在评论中出现的次数,选取出现次数最高的90个评价词和45个评价对象;
2)统计每一对评价词和评价对象共同出现的次数;
3)对于每一个评价对象,选择其对应的出现次数最高的45个评价词,以它们的组合词对组成语义相关集,对应的评价对象通过使用已抽取出的评价词搜索语义相关集来确定。
2 主题词的修剪及聚类
有些抽取出的评价对象与商品无关,需要去掉。比如“淘宝网很棒”这句话,虽然评价词“棒”被抽取出来,“淘宝网”也被作为评价对象提取,但这一分句并未对商品的属性做出评价。所以需要去掉这些冗余数据后,再对剩下的数据聚类以得到最终评价对象。
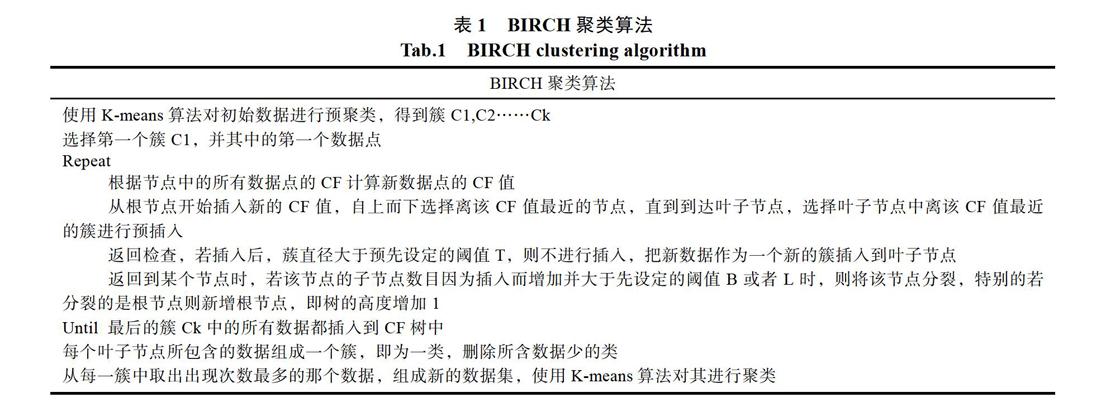
2.1 BIRCH算法的预聚类
BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies)利用层次方法的平衡迭代规约和聚类。它使用聚类特征(Clustering Feature, CF)和聚类特征树(CF Tree)两个概念,用于概述聚类。聚类特征树概括了聚类的使用信息,并且占用空间较原来数据集小得多,可以存储在内存中,从而可以提高算法在大型数据集上的速度及伸缩性。关于BIRCH聚类算法,数据的插入顺序对聚类特征树的构建影响很大,所以本文通过对初始数据集进行预聚类的方法,首先已知数据集合插入顺序,再将数据按照顺序插入来构造聚类特征树。在预聚类阶段采用的算法是K-means算法,因为该算法效率高、实规定现简单、复杂度较低,不会在初始阶段增加BIRCH算法的复杂度。
为了将语言数学化,首先将所有评价对象转化为词向量,具体步骤如下:选取提取到的最高频次的15个评价词,该评价对象与这15个评价词在评论中出现的次数即可用向量中的元素值来表示。比如,本文针对“手机”评论挑选的评价词包括:“流畅”、“使用稳定”、“操作方便”、“美观”、“速度快”等共15个评价词,而“摄像头”这个评价对象表示成向量為[443, 227, 201, 145, 88, 129, 49, 55, 60, 41, 38, 42, 53, 44, 95],向量中的元素代表“摄像头”与评论中15个评价词共同出现的次数。
对于K-means聚类算法的初始质心如何选择的问题,采用最大距离法[12],保证各质心不属于同一类并且之间的距离尽量大。在计算各数据点之间的距离时,采用欧几里得距离的方法。算法的具体细节见文献[13]。
2.2 BIRCH聚类算法
关于BIRCH聚类算法中的几个阈值[14,15],直径阈值T的确定如下:从数据集里选取N个数据,分别计算每两个数据之间的距离,计算这些距离的方差值DX和期望值EX,则阈值T = EX + 0.25 × DX。对于确定叶子节点的子节点个数L以及非叶子结点的子节点个数B,通过抽取部分数据作为测试集,反复实验,得到实验结果最好时的L和B值。
CF树建完以后,每个叶节点包含的数据点就是一个簇,删除所含节点数很少的簇,因为这些数据很可能是抽取出来的与商品无关的特征。由于BIRCH算法中阈值的限制,CF树每个节点只能包含一定数量的子节点,最后得出来的簇可能和真实结果差别很大,所以需要对BIRCH聚类算法得出的聚类的结果进行全局聚类。本文采用K-means聚类算法进行全局聚类。
BIRCH算法步骤如表1所示。
3 实验分析
3.1 BIRCH算法与PMI算法修剪评价对象实验对比分析
本文使用的实验数据是京东商城上手机的评论信息,共计1万条数据。
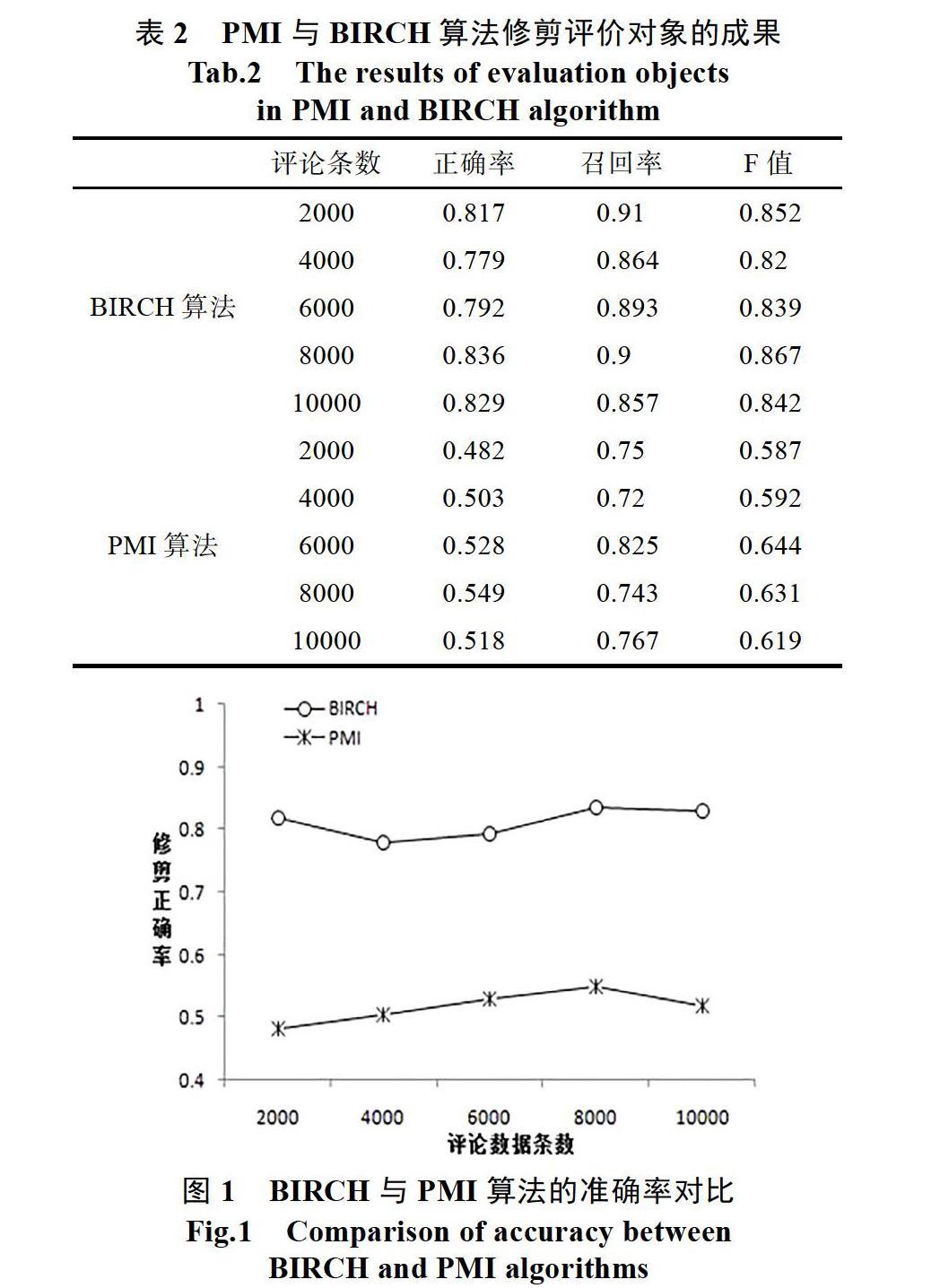
为了验证BIRCH算法修整评价对象的效果,本文用它和常用的PMI算法修剪评价对象的结果进行对比,通过分析两种方法的准确率、F值和召回率,进而判定本文方法的效果。正确率就是对于操作出来的数据中正确操作的数据所占的比例,召回率是对于总样本数据中正确操作的数据所占的比例,F值是二者的综合指标。
实验中BIRCH聚类算法中不是叶子结点的子结点个数B为10,簇的直径阈值T为3.9,叶子节点的子结点个数设定为15,将PMI算法中的修剪阈值设为0.3。将1万条数据分为五个数据部分:2000条、4000条、6000条、8000条、10000条,上述两种方法在不同数据段上的实验结果如表2和图所示,使用BIRCH算法的修剪准确率明显高于PMI算法,因为PMI算法对阈值和语料库有非常大的依赖,需要综合的语料库作支撑,本实验选取的是微软开发的必应搜索引擎的语料库,但如果同时增大语料库,时间复杂度将会增加。
3.2 BIRCH聚类算法实验分析
以往对评价对象进行聚类采用的方法主要是两种:一种是通过创建商品属性集合以及属性常用的表达方式来组成映射集,然后对每个评价对象确定最终评价对象时,搜寻映射集来确定;另一种方法也是使用聚类算法,比如K均值聚类算法。本文为了验证将BIRCH聚类算法应用于评价对象聚类方面的有效性,将其与上述两种方法的正确率进行实验对比分析。
首先是映射集方法,实验建立的映射集部分如表2。
使用K-means算法进行属性统一时,将评价对象聚为13类,然后选择相对较集中的簇并且簇中数量较多的作为最终评价对象,结果为“手机”、“性价比”、“快递速度”、“使用感受”、“散热”、“声音”、“外观”、“服务”。
在对上节的BIRCH算法得出的每一簇,选择出现频率最高的数据来组成数据集,使用K-means算法进行聚类,即完成了本文中方法的实验。最后,对这三种方法的结果进行对比,图1展示了三种方法在评论数据集分别在2000、4000、6000、8000和10000条时的正确率。
