基于时空多视图BP神经网络的城市空气质量数据补全方法研究
2019-12-19张贝娜冯震华张丰杜震洪刘仁义周芹
张贝娜 ,冯震华 ,张丰 ,杜震洪 *,刘仁义 ,周芹
(1.浙江大学浙江省资源与环境信息系统重点实验室,浙江杭州310028;2.浙江大学地理信息科学研究所浙江杭州310027;3.北京超图软件服务有限公司,北京100015)
由于城市化的飞速发展,伴随而来的城市空气质量问题已成为全球居民普遍关心的问题。城市物理空间中部署了大量的传感器,用以持续和连续地监测环境信息,生成了海量的带有地理位置信息的时间序列数据,帮助人类更好地理解周边环境[1]。在实际监测中,由于传感器故障、数据传输错误等,监测数据常会出现随机性甚至连续性缺失,严重影响实时监测数据的查看和后续数据挖掘训练集的组织。
经典数据补全方法包括数学统计、时间序列预测、空间插值等。RUBIN[2]提出用多重补全方法迭代进行数据补全;LI等[3]比较了周期性填补法、均值填补法和三次样条函数插值法3种方法对时间序列缺失数据的补全情况;TURRADO等[4]采用自适应的反距离加权方法对太阳辐射缺失数据进行补全。
上述方法仅考虑单视图,即仅使用一种维度信息来表示一个对象[5]。目前,也有考虑多视图信息的研究,例如CHEN等[6]采用时空k最近邻方法对推文标记数据进行补全,YI等[7]提出结合经验统计模型和数据驱动算法的线性回归方法进行时空数据补全。因当前该类方法普遍立足于线性关系,不利于多视图信息的关联挖掘。
随着机器学习的发展,出现了一些基于非线性关系的数据补全方法,例如XIA等[8]提出采用非负矩阵分解补全社交图像的缺失标记,魏晶茹等[9]采用支持向量机和粒子群优化方法补全污水处理厂的污染物测量数据。因当前该类方法普遍基于单视图信息,不利于连续缺失数据的补全。
在数据预测问题的解决中,由于未来条件的不可预知性,其他影响因素(例如气象条件)往往作为输入补充条件。而数据补全问题是基于历史和未来数据的,本身蕴含较为丰富的信息,因此,本文重点研究监测数据的缺失数据重建。
针对当前数据补全方法的优点和不足,以北京市一年的城市空气质量数据为研究对象,基于指数移动平均、普通克里金、非凸矩阵完备,提出了一种基于时空多视图BP神经网络的数据补全方法,用于补全随机缺失、时间连续缺失和空间连续缺失的数据,并用实验验证和分析该方法的有效性和优越性。
1 时空多视图
传统数据采用单视图组织形式。随着大数据时代数据获取和存储能力的显著提高,同一对象的数据表达形式日益丰富,例如一幅图像可被形状、纹理和颜色共同表示[10]。多角度的数据组织形式能够描述同一对象的不同方面,能够刻画同一目标的不同特性,对信息的描述具有补充价值,被称为多视图数据[11]。
理论上,多视图只是一个泛指,它可以是不同特征,也可以是不同的模型架构和不同的数据集。本文重点关注多视图特征,从局部时间信息、局部空间信息和全局时空信息3个角度入手,构建3时空多视图特征,提取不同角度的数据内容,挖掘数据本身的潜在信息。
1.1 基于指数移动平均的时间视图
采用指数移动平均(exponential moving average,EMA)模型表征时间视图。该模型最早由BROWN[12]提出,对过去的时间序列数据进行加权平均,时间间隔越近的数据权重越大,可用递推公式表示:

其中,St是t时刻的平滑值,vt是t时刻的实际值,α是平滑常数,满足0<α<1。
数据补全时应同时考虑包含过去和未来的双向数据,为充分利用数据,采用拓展为双向的指数移动平均方法。此外,考虑到过于久远的数据对当前数据影响较小,故只将最近一定时间范围内的数据作为输入进行计算,公式为

其中,是t时刻的平滑值,vt是t时刻的实际观察值,threshold是时 间 窗 口,将 [t-threshold,t+threshold]范围内除t外的数据作为t时刻数据的计算输入,α是平滑常数,满足0<α<1。
1.2 基于普通克里金的空间视图
采用普通克里金(ordinary Kriging,OK)模型表征空间视图。该模型的雏形来自南非矿业工程师KRIGE[13],法国地质数学家MATHERON[14]对其进行了整理归纳。方法的依据是地理学第一定律[15],即已知空间上的地理属性具有空间相关性,且越相近的事物越相似,其基本公式为

克里金插值采用统计规律信息计^算权重系数,目标是得到满足点(xs,ys)处的估计值与真实值vs的差最小的一套最优系数,即满足最优系数条件:

同时满足无偏估计条件:
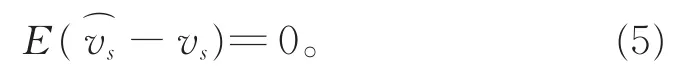
克里金具有不同变种,主要区别在于假设条件的不同。本文采用的普通克里金插值方法的假设条件为:空间属性v是均一的;对于空间任意一点(x,y),都有同样的期望与方差。
基于上述3项条件,经过公式推导,可得到权重系数λi的求解等价式:
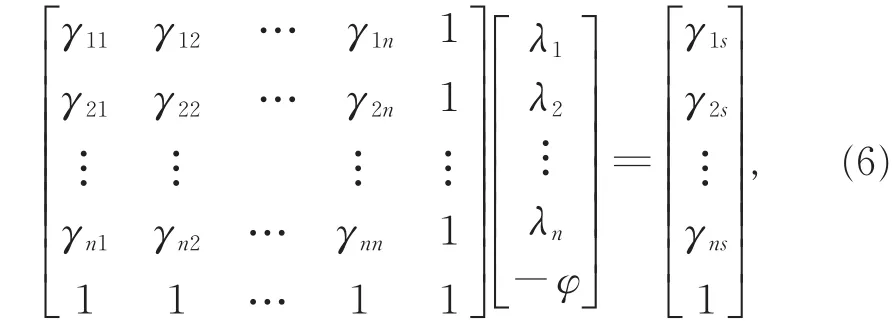
其中,γij是半方差函数值,φ是拉格朗日乘数。
普通克里金的求解过程最终转换为半方差函数的求解问题,其定义为

已知点间的半方差函数值γij可通过实测值求得;而已知点和未知点间的半方差函数值γis通过统计信息和空间相似性的关系求得。
克里金插值假设观测点i和j的半方差函数γij与两点间的距离dij存在函数关系。首先,绘制两两已知点间“距离-半方差函数值”的散点图,然后寻找一条最优的拟合曲线(常用半方差模型,有球面、圆、指数、对数等模型)拟合d和γ的关系,得到半方差函数。对于任意两点(xi,yi)和(xj,yj),先计算其距离dij,然后根据函数关系求得这两点间的半方差γij,最终求得权重系数和待插值点的估计值。
1.3 基于非凸矩阵完备的时空关联视图
采用非凸矩阵完备(non-convex matrix completion)模型表征时空关联视图。矩阵完备是在一个矩阵有元素缺失的情况下,通过对缺失值之外的有效元素位置进行采样,进行一定的计算和分析,最后补全整个矩阵的一种算法[16]。从数学角度而言,绝大多数矩阵补全问题是通过寻找低秩条件下原始矩阵的近似矩阵解决的,矩阵完备问题可形式化表示为
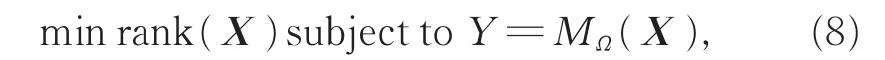
其中,X是目标完整矩阵,Ω是对应矩阵中所有能观测到的坐标位置集合,MΩ是选取X在Ω位置的掩膜操作,Y是实测样本。求解式(8)是NP难问题,可将其转换为具有高概率恢复矩阵能力的凸松弛问题:

其中,‖‖X*是核范数,被定义为奇异值之和。
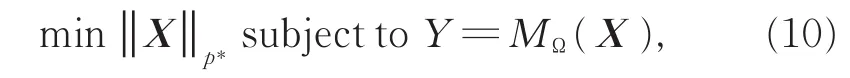
其中,‖X‖p*是矩阵奇异值的lp范数。
稍微放宽式(10)中的限制条件,目标问题便转变为
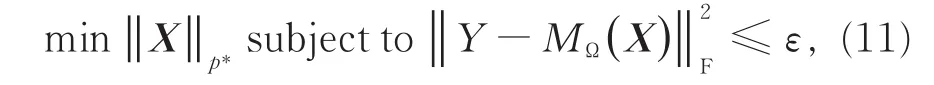
其中,‖·‖F是弗罗贝尼乌斯范数(Frobenius norm),ε为误差值。
将非凸矩阵完备进一步转换,可数值计算量化的目标问题:
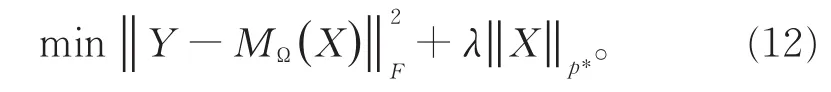
最终可通过转换优化和冷却算法进行迭代,得到补全的目标矩阵。
2 时空多视图BP神经网络模型
时空多视图BP神经网络数据补全模型(spatiotemporal multi-view-BP,STMV-BP)框架见图1,包括时空多视图和BP神经网络2个重点内容。时空多视图从时间、空间和时空3个互为补充的视角切入,综合抽取不同角度的时空数据信息;BP神经网络融合时空多视图特征,映射时空多视图和目标补全数据之间的非线性关系,构成面向城市空气质量数据补全的方法架构。
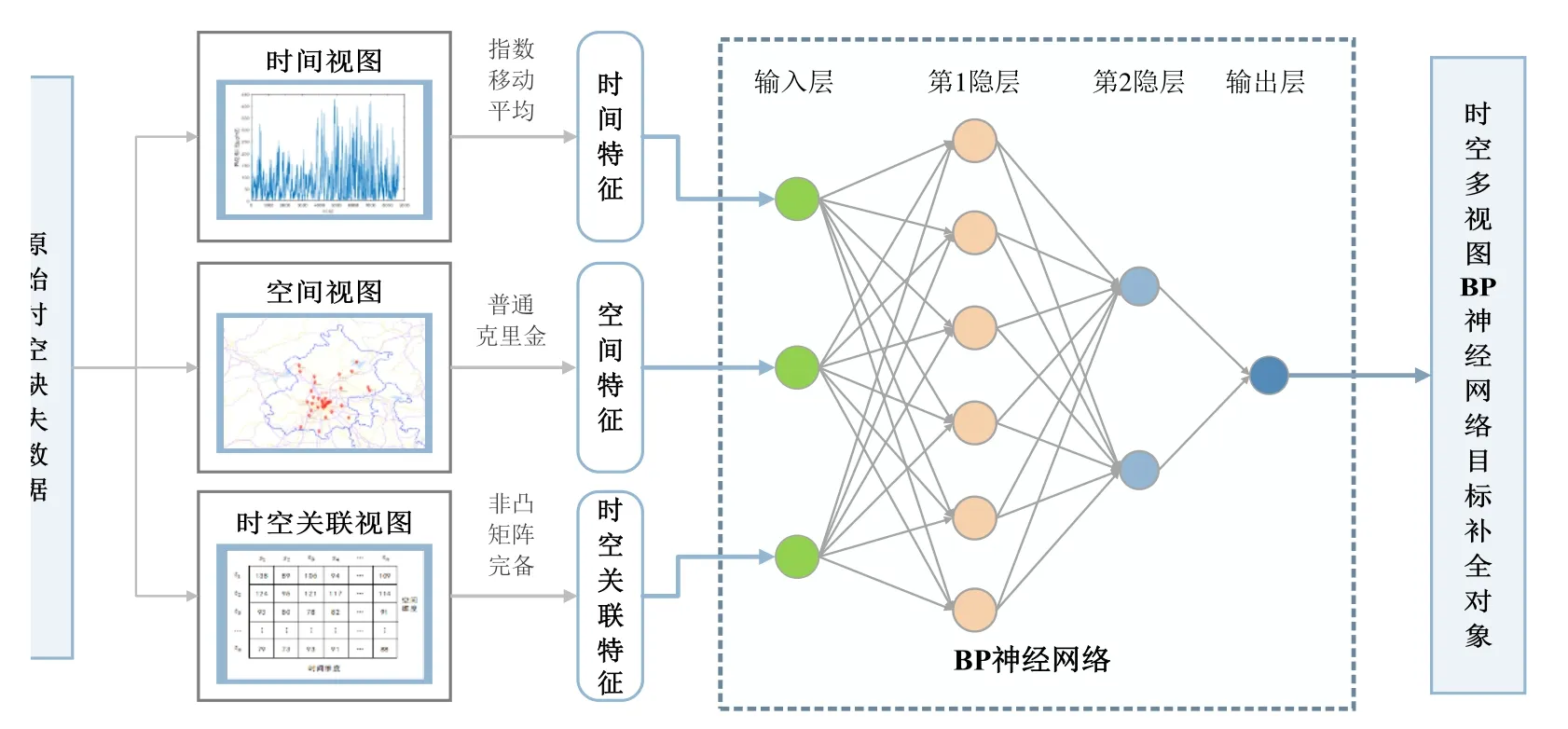
图1 时空多视图BP神经网络模型框架Fig.1 Framework of spatio-temporal multi-view-BP model
本文设计了3个独立的时间、空间和时空视图,将其作为特征,没将所有数据作为神经网络输入的原因如下:
(1)从特征空间的角度看,时间和空间视图使用的基础数据无重叠,提供了不同视角的信息;
(2)从模型的角度看,3个视图分别模拟局部和全局信息,表征局部信息的时间视图和空间视图从本质上说是回归问题,表征全局信息的时空关联视图则是非线性插值问题,需采用不同的模型处理;
(3)从网络训练的角度看,将所有数据作为特征模型参数易导致效率降低,基于有限训练数据的时空特征提取,有利于提升参数训练效率,提高模型准确度。
本文采用BP神经网络而非线性回归或其他复杂神经网络进行特征融合,主要出于以下两点考虑:
(1)BP神经网络能够映射输入数据和目标数据间的线性关系,弥补了线性回归仅能进行线性关系映射的不足,能够更深入地挖掘时空多视图信息;
(2)BP神经网络较其他复杂神经网络建模简单,更重要的是,对数据补全方法的时空多视图特征,最终凝练出的3个视图已能有效映射此类简单维度的关系。
3 实验与分析
硬件环境:处理器Intel(R)Core(TM)i7-4770 CPU@3.40 Hz,内存8.00 GB。
软件环境:操作系统Microsoft Windows7(64bit),Matlab版本 2017b。
数据来源于“城市计算”(urban computing)项目公开数据集[1,19],采用2014年5月1日至2015年4月30日北京市36个站点的空气污染物小时浓度数据,站点分布见图2,污染物包括 PM2.5、PM10、NO2、CO、O3和SO26种。

图2 北京市空气质量监测站点分布Fig.2 Distribution of air quality monitoring stations in Beijing
对278 023条原始空气质量记录数据进行预处理。首先,分站点规整化数据,将各站点数据处理为按照时间序列排列的固定1 h间隔的规整数据,并将缺失数据用NaN值进行填充。然后,根据污染物类别划分数据,以顺序时刻为行,以站点为列,将数据划分为对应污染物的6个数据矩阵,每个矩阵大小为8 760×36。其中,矩阵行大小代表365 d×24 h·d-1共8 760 h,矩阵列大小代表36个站点。
各空气污染物数据存在随机缺失、时间连续缺失和空间连续缺失3种缺失模式,3种缺失模式可能存在交叉,缺失统计情况如表1所示。
实验采用均方根误差(root mean squared error,RMSE)、平均绝对误差(mean absolute error,MAE)和平均相对误差(mean relative error,MRE)3种误差作为评价指标。
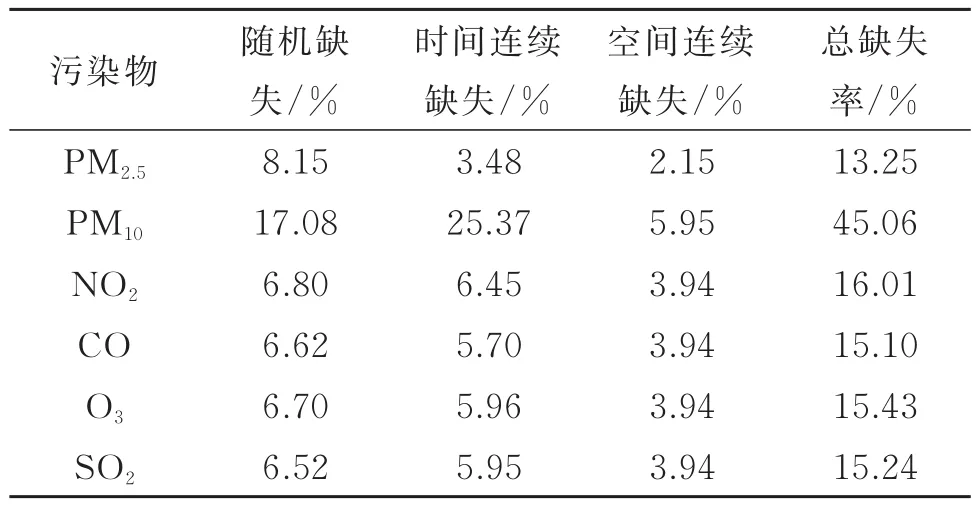
表1 各空气污染物缺失统计Table1 Statistics on the missing of air pollutants
3.1 不同缺失率下的数据补全
为探究不同缺失率下的表现,采用5%,10%,15%,20%,25%,30%6种缺失率进行3种缺失模式的随机挖空,训练集和测试集的比例为8:2。其中,时间连续缺失,定义为某一站点11个时刻连续缺失,为时间视图范围大小;空间连续缺失,定义为36个站点连续缺失,为所有空间站点数量。
考虑数据选取的随机性会导致补全难度不一,本实验中,每一高缺失率挖空点位集合包含了前一低缺失率挖空点位集合。
由表2可知,本文方法对PM2.5时空数据3种缺失模式的数据补全是有效且实用的。对应PM2.5数值在 1.000~1 000.000 μg·m-3时,RMSE<25,MAE<14,MRE<0.17。时间或空间连续缺失的各项误差指标值明显较大,说明连续缺失模式的补全难度更大。

表2 不同缺失率下3种缺失模式数据补全结果(PM2.5)Table2 Data completion results for different missing modes under different missing rates(PM2.5)
3.2 不同视图的数据补全
为探究不同视图的数据补全效果,在15%缺失率下,分别进行时间视图(EMA)、空间视图(OK)和时空关联视图(Non-convex)的单视图数据补全效果实验,并与本文的时空多视图方法进行对比。
由表3知,本文方法的各项指标均优于单视图数据补全。此外,单视图补全方法在极端情况下无法补全数据。如:时间视图基于时间序列数据,在时间连续缺失情况下无法进行补全;空间视图基于空间数据,在空间连续缺失情况下无法进行补全;时空视图无法基于全空行或全空列求取相似低秩矩阵,在全空行和全空列下无法进行补全。

表3 不同视图数据补全结果(PM2.5)Table3 Data completion results for different views(PM2.5)
由图3可知,时空多视图方法最优;3个单视图中,空间视图最差,时间视图最优,时空视图介于中间,说明各视图对方法贡献度由高到低依次为时间视图、时空视图和空间视图。
3.3 与其他方法的比较
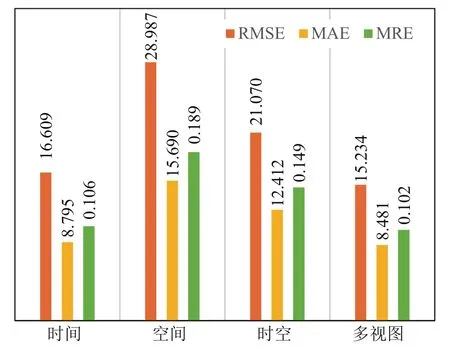
图3 在随机缺失模式下不同视图的数据补全结果(PM2.5)Fig.3 Data completion results for different views in random missing mode(PM2.5)
将STMV-BP和以下5种典型数据补全方法的表现效果进行了比较,结果见表4。5种典型数据补全方法为:(1)ARIMA,基于过去短期数据预测缺失数据,不断迭代预测缺失数据;(2)STKNN,基于k个最邻近的时间和空间数据,取其平均进行缺失数据的填补;(3)NonCVX,基于EMA和OK进行局部初始化,采用非凸矩阵完备算法进行缺失数据填补;(4)EMA+OK,基于EMA和OK计算时间视图和空间视图,取其平均进行缺失数据的填补;(5)STMV-R,采用本文提出的时空多视图作为特征,采用线性回归融合时空多视图特征。
由表4知,在各种缺失场景下,STMV-BP的补全效果明显优于各对比方法;考虑时间和空间的多角度方法,明显优于仅考虑单视图的方法;仅考虑时间线性关系的ARIMA补全效果最差,且在时间连续缺失场景下无法有效进行数据补全。
考虑时空多视图和对多视图特征进行融合,可明显提高数据的补全效果;BP神经网络3种缺失模式下的补全效果均明显优于线性回归。
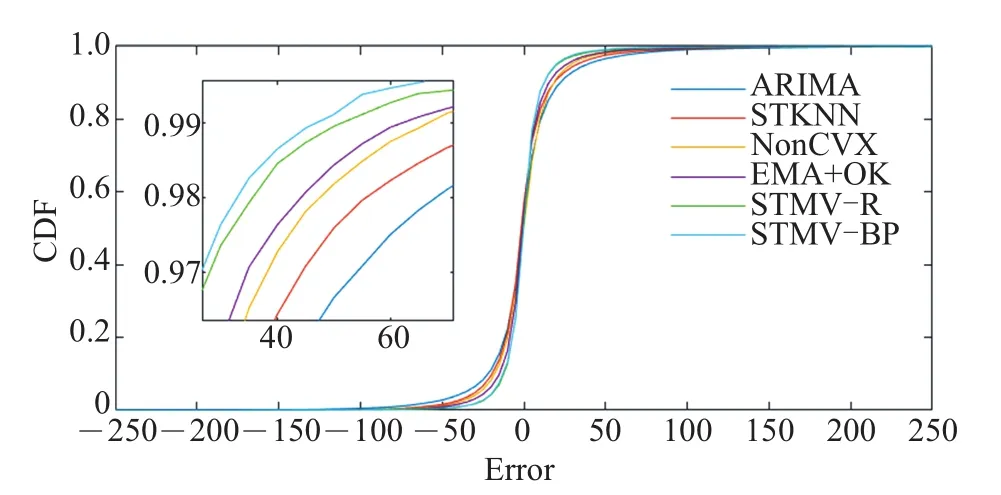
图4 不同方法数据补全误差的累积分布函数(PM2.5)Fig.4 Cumulative distribution function of data completion error for different methods(PM2.5)
各方法数据补全误差的累积分布函数(cumulative distribution function,CDF)见图4,从图4中可发现,STMV-BP在误差为0处导数最大且最先趋近于1,进一步说明本文方法整体表现更优。

表4 不同方法数据补全结果(PM2.5)Table4 Data completion results for different methods(PM2.5)
3.4 各空气污染物的数据补全
在15%缺失率下,各污染物数据补全效果见表5。各污染物的误差项均在合理范围内,以随机缺失为例,MRE普遍在0.16以下,说明本文提出的STMV-BP方法在空气污染物数据补全上具有适用性。
各空气污染物平均相对误差和缺失率对照见图5。通过比较发现,除SO2外,其他污染物的平均相对误差与缺失率普遍呈对应关系,即缺失率越高,数据补全的效果越差,缺失率越低,数据补全的效果相应较好。而SO2数据缺失率的平均相对误差明显偏高,可能原因为SO2数据的时空变换规律较其他污染物更难捕捉。
3.5 模型参数
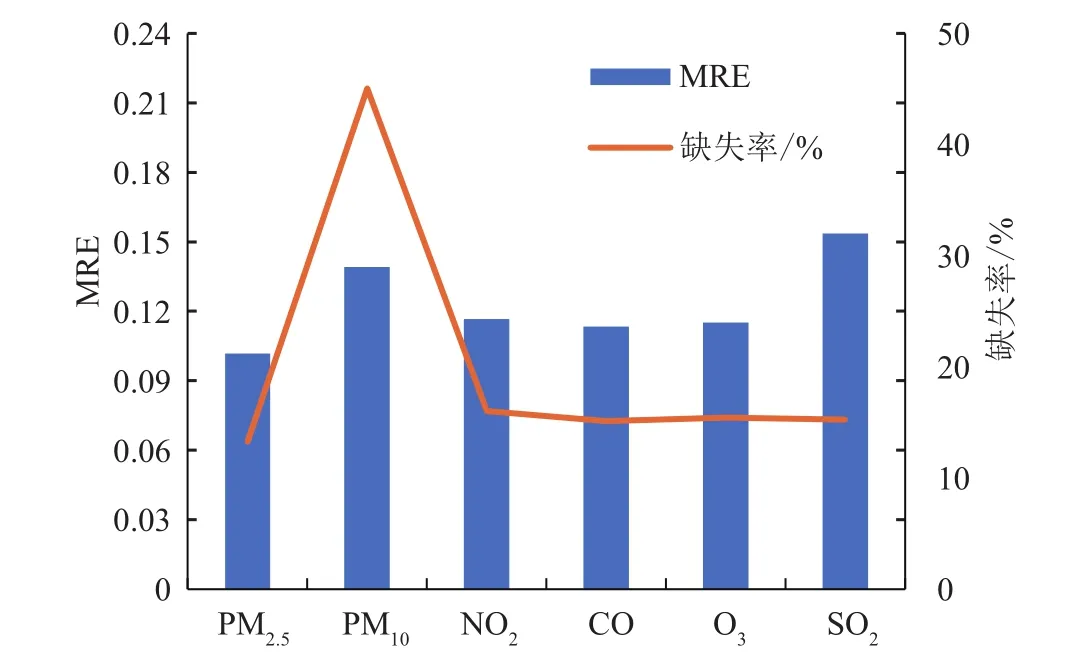
图5 各空气污染物平均相对误差和缺失率对照Fig.5 Comparison of mean relative error and missing rate for different air pollutants
本文在BP神经网络的具体构建中,采用4层网络结构,其中第1层为包含3个神经元的输入层,第2层为包含6个神经元的第1隐含层,第3层为包含2个神经元的第2隐含层,第4层为包含1个神经元的输出层;将Sigmoid函数作为激活函数,均方误差(mean square error,MSE)作为损失,Levenberg-Marquardt算法作为优化方法,对数据集预先进行归一化处理。
时空多视图BP神经网络模型受不同参数的影响。在时空多视图构建中,指数移动平均方法的threshold和α,非凸矩阵完备方法的p取不同值时的补全效果见图6。
本文最终选择参数threshold=5,此时补全效果已较优,当参数取更大值时,所需数据量更大且会影响数据处理效率;α=0.85,此时补全效果最优;p=0.5,此时补全效果达到最优。
4 结 论

图6 时空多视图参数影响Fig.6 Impact of parameters for spatio-temporal multi-view
基于指数移动平均、普通克里金和非凸矩阵完备,提出了面向城市空气质量数据补全的时空多视图BP神经网络模型。由于集合了从不同视角出发具有互补性的不同视图,本方法可在数据随机缺失、时间连续缺失和空间连续缺失3种模式下有效补全数据,与单视图补全方法相比,不仅提升了随机补全的效果,而且能够在极端缺失情况下补全数据。由于采用BP神经网络映射非线性关系,本方法能够更好地拟合时空多视图关系,各误差指标明显较线性方法低。实验证明,该方法能够有效补全各空气污染物数据。本文研究成果可为城市空气质量数据补全工作提供方法支持,研究思路可供时空数据挖掘参考。下一步将重点研究本方法对其他类型时空缺失数据的补全效果。

表5 各空气污染物数据补全结果Table5 Data completion results for different air pollutants
