基于缓存的位置隐私保护方法研究
2019-12-19冯亚平康海燕
冯亚平, 康海燕
(北京信息科技大学 信息管理学院 北京 100192)
0 引言
随着“互联网+”时代的发展,智能手机和其他电子移动设备已成为人们日常生活中不可或缺的一部分,基于位置的服务也得到了广泛的应用.用户在享受位置服务所带来便利的同时,也承担着位置隐私或轨迹隐私泄露的风险.例如,人们可以使用基于位置的服务搜索附近的商场、医院、银行、餐厅以及酒店等,攻击者有可能根据用户在服务请求中的地理位置和请求内容推断出用户的工作地址、生活习惯等.现有的隐私保护技术[1-4]主要依赖独立式结构、集中式可信第三方结构和分布式点对点结构.在基于可信第三方结构的位置隐私保护技术中,文献[5]首次引入匿名服务器,将数据库中k-匿名隐私保护模型应用到位置服务隐私保护中,但是要使个人用户保持匿名,位置匿名服务器必须在地理区域拥有足够多的用户,否则无法匿名.为了满足用户的不同隐私需求,文献[6]提出了一种私有k-匿名模型,该模型使每个用户可以设置自己的隐私需求匿名度,并且每个用户的隐私需求匿名度可以不同,通过形成匿名区来实现位置隐私保护,但是有时在某种程度上也会暴露该用户所在的区域.
文献[7-11]均采用第三方服务器进行匿名的TTP框架,负责对用户的查询进行泛化处理,形成包含k个用户的匿名区域,从而实现对用户位置的隐私保护.在这些基于TTP 框架的位置隐私研究方法中,一方面,不同的用户请求服务均需要在中心服务器中进行匿名,进而得到反馈结果,容易成为性能的瓶颈和集中攻击点;另一方面,用户每一次请求查询结束后往往将匿名候选结果集丢弃,当用户在连续的 LBS 范围请求查询时,相邻查询点的范围总存在一定的相交区域,如果这些相交区域在后续查询点又进行请求查询,这将会增加 LBS 服务器的开销,也会加大用户信息暴露给LBS服务器的风险,从而降低了对用户隐私的保护度.文献[12]提出了一种简单分布式的轨迹隐藏策略,该策略不依赖可信的第三方,采用虚拟路径规划方法,为了保证用户发送的连续位置服务请求包括足够多的真实可信的轨迹,还需要发送其他假的位置服务请求,从而使位置服务请求打破时间与空间的关联性,不足之处是发送大量假的服务请求增大了通信开销以及LBS服务器的计算开销.文献[13]为用户设计了一种基于假位置和用户协作的隐私保护方案,该方案采用熵来衡量匿名化程度,并且在选择假位置的时候考虑了攻击者可能利用的边信息,使所选择的假位置与用户的真实位置具有相近的历史查询概率,然而该方案的通信开销和存储开销均较高.文献[14]提出一种移动轨迹的位置隐私保护方法DUMMY-T, 旨在保护用户隐私免遭背景攻击, 首先通过DLG算法生成假位置, 然后通过DPC算法生成虚假路径, 保证了移动位置隐私安全,不足之处是假位置和虚拟路径的生成效率不高.文献[15]提出一种基于近似匹配的假位置k-匿名位置隐私保护方法DBAM,该方法采用独立式结构,保证了假位置之间物理分散性和语义多样化,虽然假位置的生成效率在一定程度上优于DUMMY-T方法,但效率还有待提高.文献[16]提出一种基于缓存的时空扰动位置隐私保护方法,该方法采用中心匿名服务器结构,不仅保护用户位置点的隐私,还保护其时间相关性的移动轨迹隐私,但该方法需要找到一种更优的数据匹配规则,否则会出现性能瓶颈问题.
综上所述,现有方案的TTP框架存在局限性,服务质量较低,通信开销大.本文提出了一种不依赖可信第三方的基于缓存的中国剩余定理(caching-based Chinese remainder theorem,CCRT)位置隐私保护方法;在客户端加入了缓存机制,减少了用户与LBS服务器之间的交互;根据用户不同等级的隐私需求,采用中国剩余定理算法计算真实地理位置等价集,满足了用户的个性化隐私需求,同时也降低了用户信息暴露给LBS服务器的风险.
1 基于缓存的中国剩余定理算法
1.1 理论分析
在基于位置服务的隐私保护研究中,主要存在以下3个问题.
1) 在采用集中式结构的位置服务隐私保护方法中,每次的服务请求都需要通过一个位置匿名服务器转发后再送到LBS服务器,这种方法非常依赖于位置匿名服务器,一旦位置匿名服务器被攻击者入侵,所有用户的隐私安全将会受到威胁. 此外,所有用户的请求查询都要通过匿名服务器的转发,使得位置匿名服务器成为系统性能的瓶颈.例如,在基于k-匿名方案中,基本方法是将用户的真实位置数据隐藏在用户和至少k-1个其他邻居访问点组成的位置集合中,但这种传统的方法往往由于无法找到k-1个同时存在的邻居访问点而无法顺利获取位置服务,并且会在某种程度上暴露该用户所在区域,无法保证高级别的位置隐私保护请求,从而影响服务质量.
2) 在位置服务中,由于用户有不同级别的位置隐私保护请求,因此在提供服务时,要依据用户的不同隐私需求对位置进行隐私保护.
3) 许多移动用户向LBS服务器查询相似的服务请求,服务器重复地对相似的请求进行查询并返回结果,从而加大了整个系统的通信开销.从这个角度来说,对服务数据进行缓存是可行的.
本方案中的核心理论是中国剩余定理算法,利用该算法的等价集思想,将等价集的概念与地理坐标相结合获取虚拟点位置,得到用户真实位置等价集,并且获取的位置点之间的关联能够应对路径分析的攻击,从而对真实位置进行保护.利用该算法改变等价集中虚拟位置的个数,从而保证用户在顺利获取位置服务时能满足用户不同的隐私需求.
1.2 解决方案
本文提出了一种不依赖可信第三方的基于缓存的中国剩余定理位置隐私保护方法,其基本模型如图1所示.该模型不依赖可信的第三方服务器,模型架构主要包括移动客户端和LBS服务器两部分.客户端新增了后台处理模块,包括处理区、计算区和缓存区.处理区主要是对服务请求以及请求结果进行处理;计算区主要是计算真实位置的等价集;缓存区主要是存储用户一定时间内请求的服务数据.用户在使用基于位置的服务时,位置隐私保护工作(例如预处理、等价集的生成、筛选请求服务的返回结果等)都是由客户端独立完成的.

图1 基于缓存的中国剩余定理位置隐私保护模型Fig.1 Caching-based Chinese remainder theorem model for location privacy protection
整个服务的基本处理流程如下:若用户U1第一次在所在位置请求服务时,首先为了满足用户不同等级的隐私需求,用户自定义隐私需求并请求服务,后台处理模块中的计算区通过中国剩余定理算法对获取的真实位置的经纬度进行计算,得到一个关于经纬度的等价集,其中用户自定义的隐私需求包括等价集中虚拟位置点的个数以及以真实位置为圆心获取虚拟点的范围;而后客户端将包含真实位置与等价集的服务请求发送给LBS服务器进行查询,从而达到多个位置同时请求服务的效果;最后LBS服务器返回所有位置的请求结果,再经过客户端处理将真实位置的请求结果发送给用户并存储于缓存区.
若用户U1在某位置点请求服务时,如果之前一段时间内,用户可能在该点或相近或等价的位置请求过相同或相似的服务,那么此服务已存储于缓存区,缓存区查询到此服务后会将结果直接反馈给用户,无须再进行等价集计算和请求LBS服务器,这样减少了用户与服务器之间的交互,破坏了用户U1在时间与空间上的相关性,从而对用户的轨迹隐私起到了一定的保护作用.中国剩余定理算法也具有一定的自我处理能力,一定时间后会自动删除缓存区中一些经常访问不到的服务请求数据,以存储更多的其他请求数据.
2 基于缓存的中国剩余定理位置隐私保护算法
2.1 相关定义
定义1服务请求的数据格式.用户提交服务请求的数据格式为Q={(x,y),t,r},客户端发送给LBS服务器的服务请求数据格式为Q′={(x,y),G,t,r},其中:(x,y)表示用户地理位置的经纬度;t表示请求服务的时间;r表示请求服务的内容;G表示地理位置的等价集.
定义2隐私级别.用户在提交服务请求时,可根据不同的需求对位置设置不同的隐私等级,从而满足用户的个性化隐私需求.隐私级别由 (n,f)共同决定,其中:n表示等价集中虚拟位置点的个数;f表示以真实位置为圆心获取虚拟点的范围.n、f越大,该位置的隐私级别越高.
定义3等价集.由真实地理位置产生的等价位置的集合,用符号G来表示.若等价集G中有3个位置,则G={G1,G2,G3}.
定义4中国剩余定理(CRT).中国剩余定理一般是指孙子定理,即求解一元线性同余方程组问题.其表示式为

(1)
利用中国剩余定理的原理将式(1)用于位置隐私保护,根据式(1)对真实地理位置进行计算,产生真实位置的等价集.客户端将服务请求Q′发送给LBS服务器请求服务,此时真实位置隐藏在等价集中,成功保护了用户的位置信息.假设n=3,其真实地理位置坐标(x,y)=(116.231 7°, 39.542 7°),(m1,m2,m3)=(13, 17, 113), (n1,n2,n3)=(13, 45, 92),具体计算过程如下.
(i) (x,y)=(116.231 7°, 39.542 7°),整数化为(X,Y)=(1 162 317°, 395 427°).
(ii) 中国剩余定理同余方程组为

求解得
由此,通过中国剩余定理能够得到互相不可区分的位置等价集.
定义5缓存命中率.缓存命中率表示由缓存机制为用户提供服务请求的概率.其表示式为
(2)
式中:QC表示缓存提供服务请求的次数;QS表示LBS服务器提供服务请求的次数.缓存命中率越高,用户与LBS服务器的交互次数越少,位置隐私保护效果越好.
2.2 处理流程
该算法的处理步骤主要集中在客户端的后台处理模块中,缓存区存储一定时间内的服务请求数据,与请求服务的时间无关,不受时间因素的影响.基于缓存的中国剩余定理算法的隐私保护流程如图2所示.

图2 基于缓存的中国剩余定理算法的隐私保护流程Fig.2 Privacy protection flowchart by caching-based Chinese remainder theorem
基于缓存的中国剩余定理位置隐私保护算法的具体步骤如下.
Step 1: 用户提交LBS服务请求Q,并自定义用户的隐私级别.
Step 2: 查询缓存区是否存在该服务请求Q,若存在,跳转Step 3;否则,跳转Step 4.
Step 3: 缓存区将查询结果直接反馈给用户,请求完成.
Step 4: 通过中国剩余定理对获取的真实位置的经纬度进行计算,得到一个关于真实位置经纬度的等价集G.
Step 5: 将包括真实位置及其等价集G的服务请求Q′发送给 LBS服务器进行查询.
Step 6: LBS服务器进行查询后返回请求结果给客户端.
Step 7: 客户端对返回的结果进行筛选并反馈给用户,同时更新缓存区的数据,请求完成.
2.3 安全性分析
本方案中攻击者主要依靠2种途径窃取用户的位置信息:一是攻击者通过窃听或监控客户端与服务器之间的通信获取位置信息;二是攻击者通过入侵LBS服务器从而监控整个系统,侵犯用户的隐私.本文所提出的基于缓存的中国剩余定理算法,在缓存机制下,使得用户每一次发出的服务请求并非与LBS服务器都产生交互,当用户的服务请求无法在本地得到满足时,就会向LBS服务器发送请求来得到服务数据.由于等价集中真实位置与虚拟位置的识别度较低,即使攻击者窃听到某条记录,也很难从位置等价集中分析出用户的真实位置.LBS服务器虽然收集了一定量的用户服务数据,但位置数据在空间和时间上并不是连续的,在最坏情况下,LBS服务器也只能等概率地猜测其中某个位置为用户的真实位置,很难推测出位置轨迹.攻击者的目标是获得用户的位置信息,从而得到用户的其他敏感信息.本方案中由于缓存机制在用户的客户端中,故假定由缓存机制提供位置服务的过程是安全的.
针对不可信位置服务提供商,从概率分布攻击、同源攻击和位置相似性攻击这3种主要攻击方式进行安全性分析.
1) 针对概率分布攻击,用户利用中国剩余定理算法产生虚拟位置,将位置等价集G={G1,G2, …,Gn}作为匿名位置集合,并向服务提供商发送服务查询请求.在这个过程中,不可信的位置服务提供商根据背景信息从匿名位置集合中获得各位置单元的查询概率,由于用户每次的隐私需求不同,位置集合中位置个数不同,虚拟位置的产生范围不同,位置服务提供商很难推断出用户真实位置的概率.
2) 针对同源攻击,本方案利用缓存机制,用户每次请求服务均将位置等价集中的n个应答结果存储在缓存中.当用户在同一位置且较短时间内连续发送多个位置查询请求时,由于缓存区已存储该服务数据,在一定的时间间隔内,任意查询请求均可由缓存中的记录作为应答结果,有效减少用户与不可信的LBS服务器的交互次数,降低了隐私泄露风险.
3) 针对位置相似性攻击,本方案在隐私级别中利用f表示以真实位置为圆心获取虚拟点的范围,通过用户自定义f,可使用户的真实位置与产生的虚假位置有一定的差距,从而保证虚假位置集合所形成的匿名区域中包含多种语义信息,即使不可信服务提供商根据查询请求获取到等价集中所有位置的相关信息,也无法根据语义特征推断出用户的轨迹信息.
因此,本文方案能够有效地抵御拥有背景信息的攻击者的概率分布攻击、同源攻击和位置相似性攻击.
2.4 算法复杂度分析
时间复杂度方面: 基于缓存的中国剩余定理算法在用户提出请求服务后,均需要先在缓存区进行查找,并需要对缓存中位置集合的查询概率进行计算并排序.位置集合的大小为s,若在位置集合中查找到用户请求服务的地理位置,则位置集合的查询概率计算和排序的时间复杂度为O(1);若没有查找到,则还需要根据用户的隐私级别(n,f)计算真实位置的等价集,计算等价集的时间复杂度为O(1).随着请求次数的增多,缓存区存储的数据会越多,位置集合的查询概率计算和排序的复杂度将会增加O(s),则总的算法时间复杂度为O(s).
空间复杂度方面:算法在处理过程中只是需要存储临时的变量,所需的内存空间极少,总的算法空间复杂度为O(1).
3 实验与分析
3.1 实验数据和环境
收集了同一城市的100个用户在3个月内的请求服务数据,主要包含用户的服务提交时间、经纬度、请求内容等信息.实验采用处理之后的数据,用户的请求服务用Q={(x,y),t,r}来表示.本实验硬件环境为Intel(R) Core(TM)i5-5200U CPU,内存4 GB,操作系统为Windows 10(×64),实验开发环境为 Eclipse(Java)+MySQL.
3.2 实验过程与结果分析
3.2.1虚拟位置点测试 随机选取了较活跃的3个用户在某一天5时—21时的轨迹进行测试,默认用户对请求位置的隐私级别均相等,其中n=3,f=20 km,即产生3个虚拟位置点且产生虚拟位置点的取值范围半径为20 km.随着时间的变化,LBS服务器得到的用户请求位置中,虚拟位置与真实位置的距离偏差如图3所示.可以看出,虚拟位置点对应的时间就是不同用户请求服务的时间, 当用户在不同或相同的时间点请求服务时,都会产生3个不同的虚拟位置点;各个虚拟位置点与真实位置点的距离偏差均为0~20 km,这主要是由于实验假设每个用户的隐私级别都相等.图3中显示的虚拟位置也正是LBS服务器中接收到的所有位置中的一部分.因为用户并非仅仅在图中所标识的时间点上发出服务请求,用户的请求一旦在缓存区有记录,缓存区会直接反馈给用户,并不需要再产生虚拟位置坐标,这样就扰乱了LBS服务器接收到的请求在时间和空间上的连贯性.因此,攻击者无法区别用户的真实位置和分析用户的轨迹,从而保护了用户轨迹数据.
3.2.2虚拟位置点的生成效率 测试了不同隐私等级下虚拟位置点的生成效率.图4 为本文方法(CCRT)与DUMMY-T方法[14]、DBAM方法[15]虚拟位置平均生成时间的对比.可以看出,随着隐私等级的增加,DUMMY-T方法、DBAM方法和本文方法的虚拟位置平均生成时间都在增加,DUMMY-T方法与DBAM方法的增加幅度明显较大,其中DUMMY-T方法花费的时间最多.而本文方法的增加幅度较小,花费的时间相比其他两种方法也较少.因此,本文方法具有明显的时间效率优势.
3.2.3缓存平均命中率测试 抽样选取了20个用户240 h内的轨迹进行测试,缓存平均命中率随时间的变化结果如图5所示.可以看出,随着时间的增加,缓存平均命中率增大.这主要是由于随着时间的增加,用户请求服务不断增多,缓存区中存储的请求结果数据也逐渐增多,故缓存平均命中率逐渐增大.240 h内缓存平均命中率最高接近0.5,相比无缓存机制的框架,大大减少了用户与LBS服务器的交互,从而使攻击者难以从LBS服务器接收到的服务请求中推断出用户的轨迹.
3.2.4通信开销测试 本文方法主要分析客户端与LBS服务器之间的通信开销.通信开销主要是由客户端向LBS服务器请求查询的服务数据大小和次数决定的,假设查询的服务数据大小相同,则通信开销主要由移动客户端向LBS服务器发送请求的次数决定.随着时间的增加,移动客户端向LBS服务器发送请求的次数随时间的变化结果如图6所示.可以看出,随着时间的增加,请求次数逐渐减小.这主要是由于随着时间的增加,缓存中存储的服务数据会越多,当用户发出服务请求时,缓存中的数据提供服务的概率增大,故发送给LBS服务器的请求次数逐渐减小,降低了通信开销.
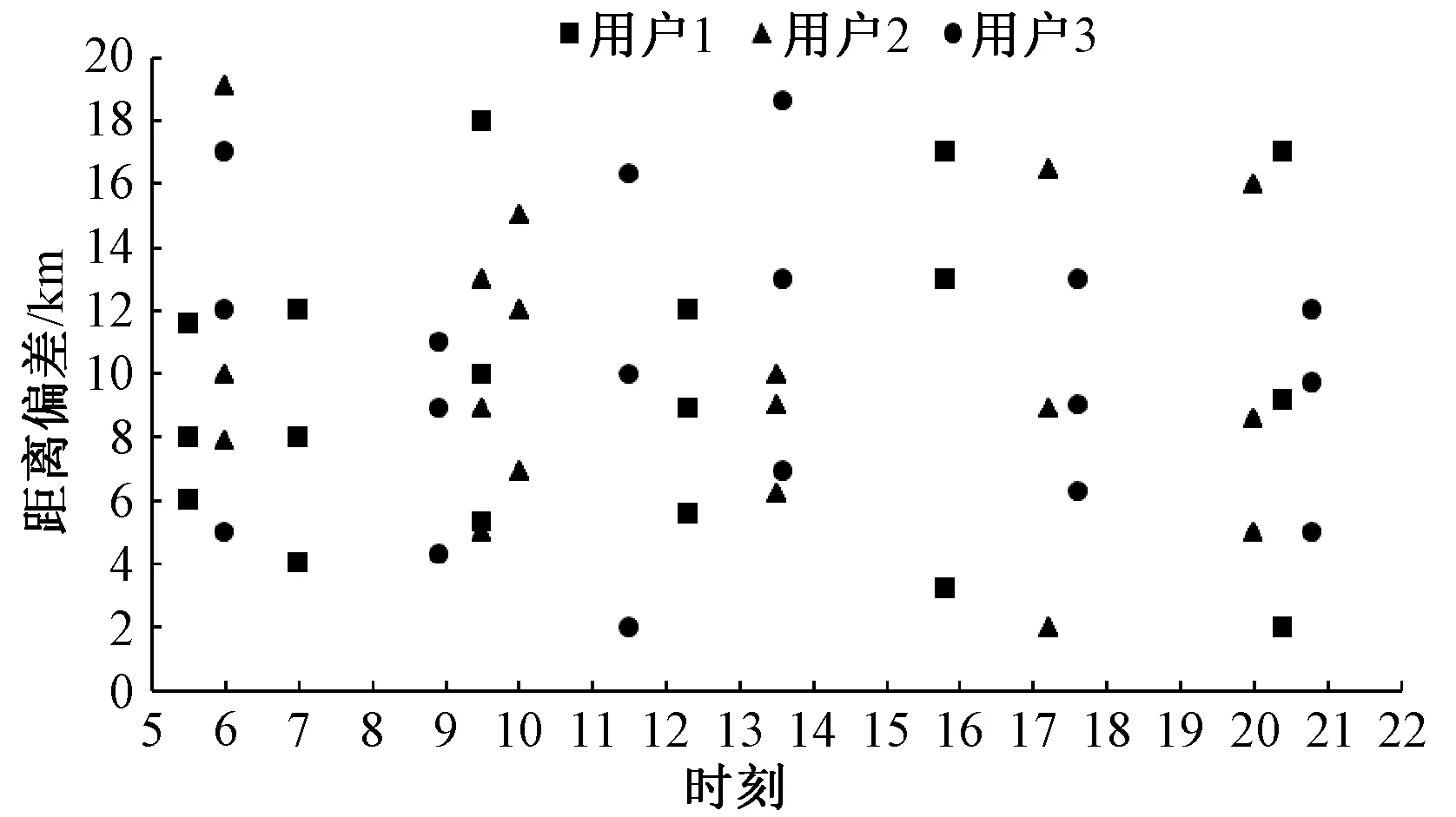
图3 虚拟位置与真实位置的距离偏差Fig.3 Distance deviation between virtual location and real location

图4 虚拟位置平均生成时间的对比Fig.4 Comparison on average generation time of virtual location

图5 缓存平均命中率随时间的变化Fig.5 Average hit ratio of cache changing with time
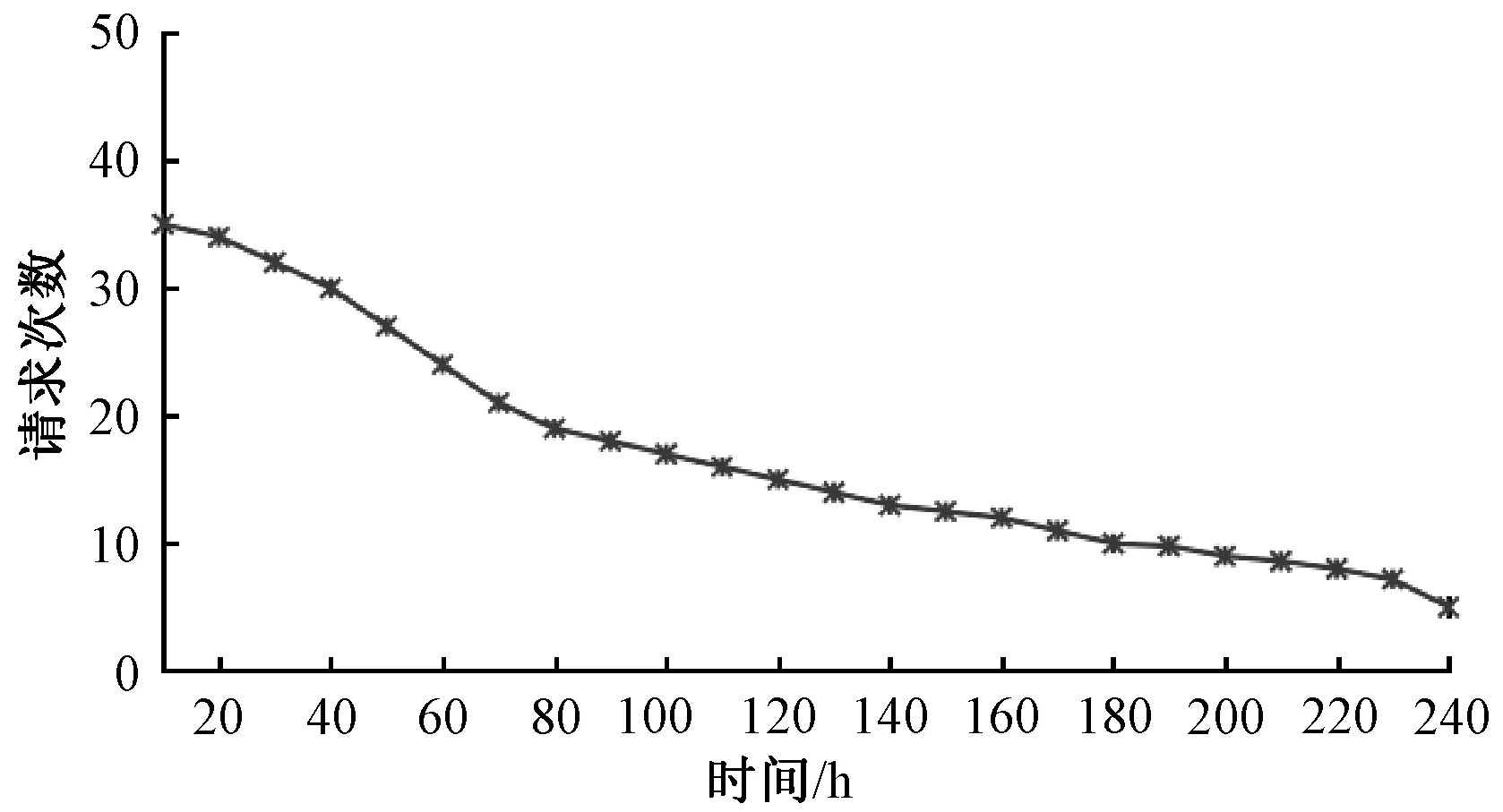
图6 请求次数随时间的变化Fig.6 The number of requests changing with time
4 结束语
本文提出了一种采用缓存区机制与中国剩余定理算法相结合来实现位置隐私保护的方案,该方案对数据的处理主要由客户端完成,不依赖可信的第三方服务器,减少了用户与 LBS服务器之间的交互,保证了用户的不同隐私保护需求,从而保护用户的位置隐私不被泄露.通过虚拟位置点的生成效率、缓存平均命中率以及通信开销的实验,证明了该方案的可行性和高效性.
