难以决定的重启操作
2019-12-16四川赖文书
四川 赖文书
笔者单位应用组的同事反馈公司应用后台的文件服务器异常,引发用户上传文件报错,影响公司业务正常办理运作。
公司应用系统部署6台虚拟机构成的Weblogic 服务器集群,由单独一台虚拟机通过NFS 服务提供共享文件服务。
NFS 服务器是以iSCSI 挂载H3C 的ONEStor 分布式存储的块存储,虚拟化平台与存储融合部署于CVK 宿主机拓扑如图1所示,分布式存储的LUN1 和LUN2 挂载到物理机用于存放虚拟机磁盘文件,LUN3 挂载到NFS 服务器虚机用于存放应用系统的非结构化数据文件。
初步诊断
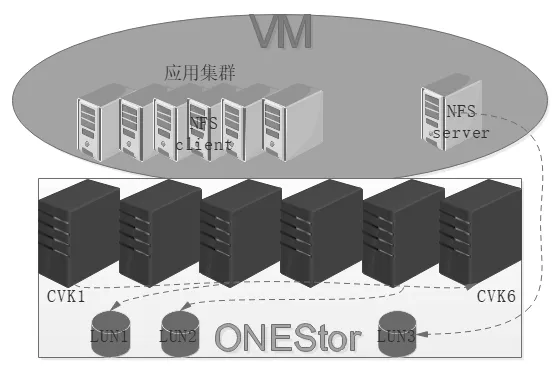
图1 虚拟化及分布式存储融合架构
由于问题的影响面比较大,运维组老D 接到反馈后第一时间对应用集群服务器和NFS 服务器进行了检查。
测试挂载到集群服务器上的目录,执行touch 命令新建文件发现无法写入,报错提示“Read-only file system”,检查目录的权限是777 即(rwxrwxrwx),也没有异常。
同时测试集群中其他服务器所挂载的目录均无法写入,在集群中的一台服务器执 行“mount -o rw,remount/nasapp”重新挂载,仍然无法写入。
推测是NFS 服务器有问题,登入NFS 服务器上执行命 令“service nfs restart”重启NFS 服务,在群集服务器上测试仍然无济于事。
忙活了这么久竟忘了该对iSCSI 挂载的块存储进行测试,touch 命令依然是无法新建文件。
排查故障原因从mount挂载方面,转到NFS 服务是否异常,最后检测确认到iSCSI挂载的块存储异常。由于NFS 服务器所共享的磁盘是基于Ceph 的块存储,前期部署由公司集成部配合厂商完成,具体技术细节运维组了解甚少,所以得请求他们紧急支援解决问题。
运维组通过邮件具体描述了故障现象以及排查过程,发给项目组领导A 请求集成部领导B 沟通协助排查。同时运维组询问厂商,请求远程对ONEStor 分布式存储进行排查。
由于事关重大,集成部的技术大牛胖U 第一时间响应了运维组的请求,当他了解到NFS 服务器所在的iSCSI磁盘也无法写时,立即判断是分布式存储方面的问题,并让运维组联系厂商解决。厂商售后工程师通过远程检查了ONEStor 存储运行状态,没有发现任何异常初步判断是虚拟机系统层面或者是软件配置的问题。
而近几天又没有进行系统或软件层面的配置修改,就今天早上突然出现了故障,目前应用仍然无法正常运行直接影响公司业务,项目组领导A 强烈要求厂商和集成的同事到现场协助解决。
深入排查
厂商一线工程师Y 赶到现场,运维组老D 给他演示了故障现象,并解释了远程检查的结果,即ONEStor 存储没有问题,还是让我们从软件配置方面检查,是不是哪里对磁盘容量有限制的策略。
该建议对于运维组来说没有可操作性,毕竟系统部署是厂商完成的,还个方向的检查还得请厂商工程师完成。工程师Y 在虚拟平台的管理页面没发现任何可疑项。为了推动问题的解决,运维组同事建议先从NFS 服务器的系统日志进行排查。在系统日志文件message 里凌晨5点26 分发现数十条的I/O 报错:


大概意思是文件系统由于I/O 错误无法写入逻辑磁盘块,自动以只读模式重新挂载。
根据此日志,工程师Y解释文件系统变为只读,原因为文件系统遭到破坏,与ONEStor 块存储是否故障无直接关系,更坚决认定故障原因在虚机服务器操作系统层面,用手机对错误日志拍了两张照片报告其公司的二线工程师。
虽然初步检查到了基本的故障原因,但是问题并没有解决。经工程师Y 与二线工程师讨论决定,需要对NFS 服务器系统进行重启以测试确认故障点,为防止所挂载的iSCSI 磁盘的文件系统发生异常,导致所存放的文件有问题,重启前建议对iSCSI 磁盘进行备份。
运维组和负责NBU 备份的同事联系确认,还有大概7TB 的可用空间,再经咨询NBU 售后工程师确认,其备份需要在NFS 服务器上安装NBU 客户端并新建备份任务,4TB 的数据文件从目前16 点开始备份大概要到第二天上午才能完成。
同时集成部大牛胖U 还担心NBU 的恢复验证问题,推荐直接COPY 方式复制到空闲的SAN 存储,由于是巨量的小文件也会非常耗时。
经过讨论,针对眼前紧急状况,这些备份措施均无法满足要求。厂商工程师Y 就一直等着运维组拿出备份解决方案,进展也卡在这里1个多小时。
在这期间,运维组技术骨干建议将iSCSI 块存储LUN3重新挂载到其它虚拟服务器,以确认其文件系统是否正常,还是被工程师Y 否定,称在没有备份前对其操作存在很大风险,可能导致部分数据损坏或丢失。
厂商工程师的意见把大家都震住了,备份不能很快完成,不备份直接重启带来的风险责任谁也无法承担,真不知如何是好啊。
专家会诊
时间一分一秒不停地在流逝,可处理故障的进展陷入了停止状态。
公司应用系统虽然还在运行,但是部分功能确实无法使用,给业务带来的影响非常大。集成部领导B 也打来电话关心处理进度,并指责运维组为什么之前没有备份,还强硬地要求派人去IDC 数据中心拿移动硬盘拷贝完成备份。
大家对于领导B 面对故障的心情是可以理解的,只是他的指挥意见在此时此刻没有操作可行性。项目组领导A 沉着冷静地在一边思考,然后电话与厂商的商务负责人沟通故障排查情况及影响程度,因为公司的应用是部署在厂商的虚拟化和分布式存储之上的,出现的存储问题需要厂商大力配合尽快处理,要求工程师Y 联系他们二线工程师进一步分析故障及有效的解决方案。
在商务负责人的推动下,厂商很快建立了专项故障诊断微信群,使用向日葵远程控制软件分享远程桌面。
二线工程师X 主导诊断分析,工程师Y 按指导意见进行操作。
首先针对我们需要备份的问题,工程师X 查看ONEStor 分布式存储磁盘使用率才40%多,决定再划分5TB 块存储以iSCSI 挂载到NFS 服务器上进行备份。
这样即解决了备份空间的问题,又避免了通过其他网络备份的性能瓶颈问题,此操作果然高明,真是行家一出手便知有没有啊。
工程师Y 操作过程中,在NFS 服务器上以“fdisk”命令对新的5TB 块存储进行磁盘分区,操作了多遍都只能分区到2TB 的空间,百思不得其解。后来猛然间才发现fdisk只能创建2TB 的分区,改用“parted”命令并以GPT(GUID分区表)完成磁盘分区操作。
经过格式化后,工程师Y编写了个shell 脚本对NFS原块存储的文件进行备份,运行时发现很多报错,大概意思是无法复制文件夹。

图2 查看系统日志sysIog
为了验证是否是脚本问题,手动执行脚本里的复制命令仍然报错,再以cat 命令输出NASAPP 目录下的几个文件竟然无法读取,这样就确认到此时原来iSCSI 块存储不仅无法写也不能读了,备份工作就无法正常进行。
在这种情况下,二线工程师X 远程详细检查NFS 服务器虚机所在宿主机CVK5,查看系统日志syslog。如图2所示。
查看kernel日志文件kern.log 发现内核报检测到通讯错误,拒绝I/O 到离线的设备。
在路径/var/log/libvirt/qemu/的对应NFS 服务器虚机日志,发现了50条如下错误日志,持续时间2 秒钟:


最后尝试命令“umount”卸载nasapp 目录,但仍然报错,使用“lsof/nasapp/”和“fuser/nasapp/”命令查看占用情况,并使用“fuser -k/nasapp”杀掉占用该文件夹的进程,再umount 正常卸载,编辑/etc/fstab 注释掉nasapp 防止系统启动时自动挂载,避免ext4 文件系统自检导致异常。
现场工程师Y 再次电话沟通,确认重启系统是否对iSCSI 磁盘数据有影响,二线工程师X 根据检查情况和经验确认不会影响,reboot 重启NFS 服务器。重启后取消fstab 文件刚才的注释项,使用“mount -a”命令将/etc/fstab 的所有内容重新加载,进入/nasapp 目录创建文件正常确认可读写,同时检查了各节点访问nfs 共享目录读写也都正常。
接下来由应用同事检查nasapp 非结构化文件的完整性,确认系统访问情况正常,整个紧急处理过程算是告一段落。
项目经理A 再次向厂商工程师了解故障的根本原因,二线工程师根据检查结果初步判断为网络波动所致。但是从网络监测和日志中并未发现这种问题,况且分布式存储的LUN1 和LUN2 运行正常,运维部门对此故障原因深表怀疑。
为了更进一步排查深层故障原因,最后厂商工程师全面收集了虚拟化平台和ONEStor 分布式存储的日志,故障虚拟机及所在宿主机的日志,待厂商的研发部门深入分析根本原因。
最后收到的故障分析报告,还是证实了集成部技术大牛最初的判断,问题确实出在存储方面。
ONEStor 高可用工作节点CVK2 的tgt(iscsi Target存储服务端)进程由于已知Bug 引发自动终止,导致主机检测到iscsi 连接异常,随后存储的保护机制高可用(keepalive)检查到该故障,触发工作节点切换到CVK4 节点,此时存储高可用切换完成,大致耗时15s。
随后主机在05:26:41 完成在CVK4 节点建立iscsi 连接,此时主机IO 完全恢复正常,存储高可用业务切换加主机重新建立iscsi 连接共计耗时约24s。
而在虚拟化集群系统中,为了保证多路径可以及时切换,所以把CVK 设置iscsid session 恢复时限为20s,导致存储在高可用切换过程中,主机认为20s 超时将块存储置于离线,并且返回业务上层IO error,触发ext4文件系统错误处理机制导致Remounting filesystem read-only。
最终建议对ONEStor 版本进行升级修复此类故障。
总结
虽然最终是小小的重启排除了故障,使公司的应用系统恢复了正常运行,但其过程是相当艰难和漫长的,耗时近10个小时。
造成如此局面大概有两方面的因素:
首先技术方面在初步诊断时仅从Linux 系统服务的表面去检查,未能第一时间从内核和系统日志去检查;运维组、集成部和一线工程师均无法确认重启是否影响存储上的数据。

其次是工作边界引起的操作责任方面的问题,集成部直接判定为存储问题,而厂商工程师一直认为是软件或者系统层面的原因,重启操作前需要备份又将责任转移到运维组。有效推动此次故障解决的,除了项目经理A 正确把握故障处理方向和高效沟通协调外,二线工程师X 深厚技术功底和经验起了决定性作用。
通过这次故障经历认识到,只有技术过硬才能在紧急处理中有担当,如果我们都能拥有像厂商二线工程师X 的技术实力,也就能在最短时间内解决问题,避免跨部门及厂商协作中的责任划分带来的效率问题。
