近红外光谱技术法快速鉴别茶油掺伪
2019-12-14荣菡罗懿黄镘淳
荣菡 罗懿 黄镘淳

摘要 [目的]采用近红外光谱技术法,快速鉴别茶油掺伪。[方法]基于近红外光谱技术,比较马氏距离聚类分析法与反向传播神经网络,建立茶油与掺有菜籽油、棕榈油掺伪茶油的模式识别模型。[结果]采用马氏距离聚类分析法建模时,参数如下:光谱一阶导数处理后,结合SNV、Norris Derivative滤波方法,经主成分分析法,提取8个主成分,模型对预测集样本的准确率达100%;采用反向传播神经网络建模时,参数如下:输入向量为前8个主成分的33个吸收峰,隐含层神经元个数为15,训练学习速度为0.1,训练220步时,模型对预测集样品识别准确率亦为100%。[结论]反向传播神经网络方法更加具有较快的运算速度和较好的收敛性,可为茶油品质评价与检测提供一种新方法。
关键词 近红外光谱;模式识别;马氏距离;反向传播神经网络;茶油;掺伪油
中图分类号 TS227文献标识码 A
文章编号 0517-6611(2019)19-0204-03
Abstract [Objective]Using nearinfrared spectroscopy technology to quickly identify camellia oil adulteration.[Method]Based on near infrared spectroscopy, two pattern recognition models were developed for discriminating camellia oil and adulterated oil with rapeseed oil and palm oil, which were bulit by Mahalanobis distance discriminative model and BackPropagation (BP) network.[Result]When modeling with Mahalanos distance clustering, the parameters were as follows:first derivative spectrum combined with standard normal variate (SNV)and Norris Derivative, 8 principal components compressed from the original data processed by PCA, the models accuracy of discrimination in the prediction set was 100%. When modeling with BP neural networks, the parameters were as follows:33 absorption peaks data, 8 principal components processed by PCA were taken as inputs of the BP Network, the number of hidden neurons was 15, learning rate was 0.1, training steps were 220, the BP model was built for identification of camellia oil and adulterated oil, and the models recognition correct rate was 100%. [Conclusion]The BP network has rapider operation speed, better convergence,which provides a new method for the quality evaluation and determination of camellia oil.
Key words Near infrared spectroscopy;Pattern recognition;Mahalanobis distance;Backpropagation network;Camellia oil;Adulterated oil
茶油是維持人体新陈代谢和生命活动不可缺少的供能营养物质,为人体提供必需脂肪酸和脂溶性维生素,因其丰富的单不饱和脂肪酸,在清理血栓、调节血脂、促进神经细胞发育、抗炎性等方面的重要功效更加突出。不同的食用植物油因脂肪酸组成不同,营养价值存在较大的差异,市场售价也存在较大的差别。一些商家为谋取利润,会在茶油中掺入玉米油、大豆油、菜籽油、棕榈油等较低价位的植物油,降低茶油营养价值,影响消费者的健康。
目前,在茶油品质检测技术中,主要是通过检测其质量特征指标,比如酸价、过氧化值、脂肪酸组成等,理化检测法和感官评价法适用于食用油品质的初步判断;气相色谱法和气质联用法等仪器分析法则需要对样品进行甲酯化预处理且分析时间较长,对于脂肪酸组成和含量与茶油接近的植物油,很难通过脂肪酸的指标加以鉴别[1];近红外光谱技术基于近红外光谱信号量丰富、测量形式多样化的特点,能够对检测物进行快速、无损的定性和定量检测。在茶油品质检测中,最常见的是化学计量学中的偏最小二乘法(PLS)、线性判别分析(LDA)、簇类独立模式法(SIMCA)用于掺伪油的分类与掺伪量的定量检测,这些是基于因子分析的线性体系的多元校正方法,面对掺伪量含量较低的茶油掺伪体系时,仍具有一定的局限性[2-5]。鉴于茶油组成成分的官能团与近红外光谱信息的有效性较为复杂,由大量的基本神经元相互联接而成的人工神经网络在茶油掺伪这类非线性动态体系中,在信息处理、运算速度、模式识别等方面优点突出,可作为解决非线性校正问题最优方法之一[6-10]。
近红外光谱技术具有绿色环保、无损、信号量丰富的特点,相比传统的理化检测费时且检测条件受限等问题,该试验采用近红外光谱技术与化学计量学结合,通过试验比较基于线性系统下的马氏距离聚类分析法,以及基于非线性系统的反向传播神经网络,建立茶油与掺有菜籽油、棕榈油掺伪茶油的模式识别模型,以期为茶油掺伪快速检测甚至大批量在线检测与评价茶油品质提供新思路。
1 材料与方法
1.1 仪器与试剂
仪器:傅里叶变换拓展近红外光谱仪及近红外光纤探头(美国,Thermo Nicole公司)。软件:OMNIC7.0、TQ7.0、Matlab2017a。
食用油:市面购得茶油、菜籽油、棕榈油3类油品,每种油至少采购4个不同品牌作为建模样品,经纯度鉴定均为100%纯正油品。
1.2 掺伪油配制
掺有菜籽油、棕榈油的掺伪油,掺伪油含量浓度为10%~40%的梯度进行配制,共100个掺伪油样品。
1.3 采集谱图
茶油与掺伪油全部样品共180个,分为训练校正集样品150个、预测集样品30个。样品充分混合均匀,放置于专业近红外光谱测试室的适宜条件下,进行光谱采集。
石英杯装约占容积1/4的样品,保证样品液面高于5 cm,将近红外光谱光纤插入样品中,每个样品采集6次谱图,取其平均光谱参与建模,扫描条件:PbS检测器,白光光源,增益为1.0,动镜速度为0.632 9,扫描范围4 200~10 000 cm-1,扫描次数为72次,分辨率为8 cm-1。
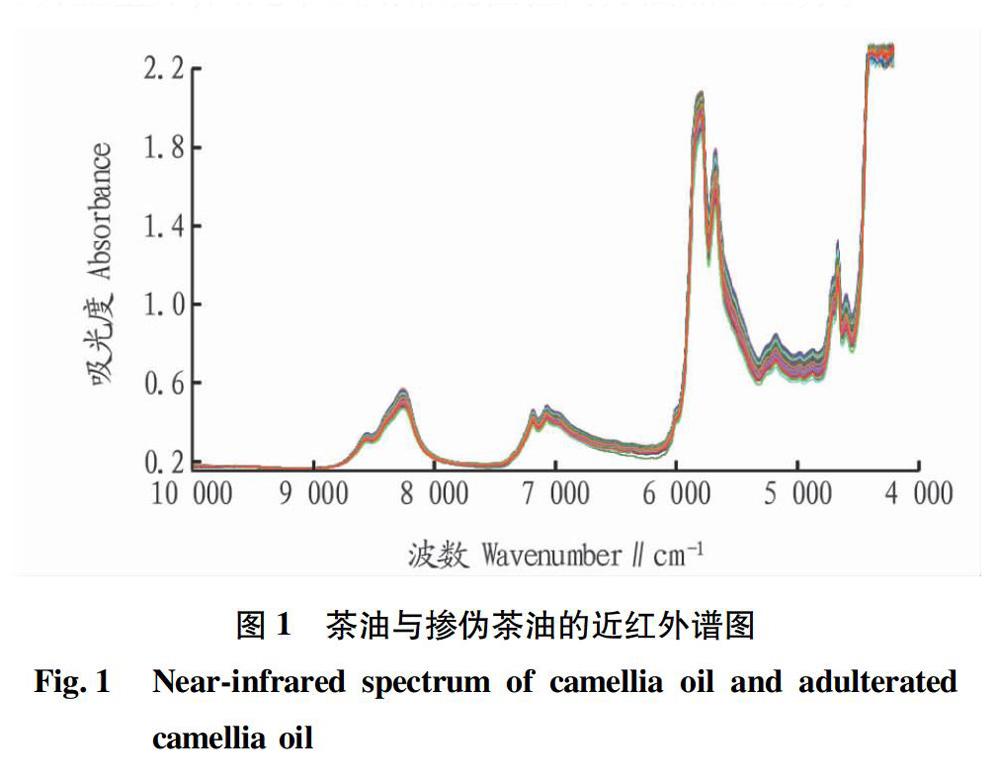
样品谱图如图1所示。从谱图可知,茶油与掺伪油谱图无明显差异,因此难以用常规检验的方法加以区分。
1.4 主成分分析-马氏距离法构建茶油与掺伪油的定性判别模型
样品光谱矩阵通过主成分分析进行降维处理,用各光谱的主成分得分计算马氏距离。根据主成分得分向量描述的2个样本i,j 间的马氏距离计算公式如下:
它是一种基于类模型基础上有监督的模式识别方法,该法依据如下:同一類样本因具有相似的特征,在一定的特征空间内,属于同一类的样本会聚集在某一特定的空间区域内;而对于不同类的样本,则分布在不同的区域[11-12]。因此在训练中要建立每一类不同油品的类模型。验证集和预测集样本,通过计算到各类模型的马氏距离值,判别该样本的种类归属。
1.5 反向传播神经网络构建茶油与掺伪油的定性识别模型
反向传播算法(back-propagation,BP)神经网络,一般具有输入层、中间层(隐含层)和输出层3层网络结构,通常采用误差逆传播算法。常用BP网络的传递函数主要有Sigmoid型的对数、正切函数或线性函数等。使用Matlab2017a软件,网络传递函数确定为‘tansig和‘purelin,训练函数为‘trainscg,予以建模。由于误差逆传播算法在网络训练中可自行调整权重,网络模型能够提高输入模式响应的准确率,因此BP网络面对复杂的非线性系统时,亦能具备出色的建模能力。
2 结果与分析
2.1 主成分分析法提取主成分
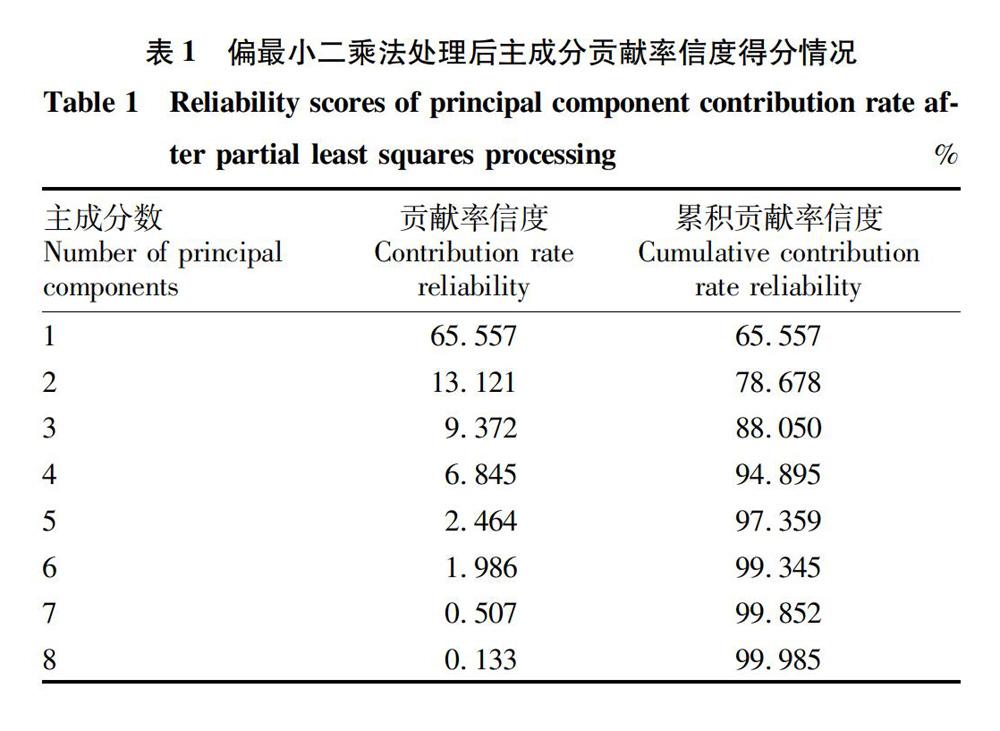
采用主成分分析(PCA)法对样品原始光谱数据进行压缩处理后,能够在最大程度代表样品信息的基础上,将光谱数据降维,有效降低网络输入向量的规模并剔除噪音。样品光谱数据经PCA处理后主成分得分如表1所示。由表1可知,当提取8个主成分时,累积贡献率信度得分达99.985%,几乎可涵盖样品所有信息。
2.2 光谱数据预处理
光谱数据的数学预处理能够使基线漂移、光程的变化对光谱响应所产生的影响降到最低。常用到的数学预处理方法一般有一阶微分、二阶微分、Savitzky-Golay滤波平滑、Norris Derivative滤波平滑、多元散射校正(MSC)以及矢量归一化(SNV)等。
从不同的光谱预处理方法建模时模型对校正集、预测集样品的判别准确率(表2)可以看出,光谱经一阶导数处理结合SNV、Norris Derivative滤波平滑方法时,模型对校正集和预测集的判别准确率均为100%,可将茶油与掺伪油完全鉴别开来。
2.3 马氏距离法构建不同种类掺伪油的判别模型
在全波段范围内,经过一阶导数处理结合SNV和Norris Derivative滤波,采用马氏距离聚类分析建立不同掺伪茶油的判别模型,如图2所示。从图中可以看出,3种不同的油品明显聚集在3个区域,模型对校正集判别准确率为100%,其中图中坐标Distance 1、2、3分别表示到纯正茶油、掺有菜籽油的掺伪油、掺有棕榈油的掺伪油的马氏距离。
2.4 BP神经网络参数的选择
BP神经网络包括3层网络结构,即输入层、隐含层和输出层。网络的优劣除了与网络结构有关,还与传递函数有密切关系。根据网络的样本容量与识别需要,试验中采用双曲正切函数(hyperbolic tangent function,HTF)和对数函数(logarithmic function,LF)作为隐含层传递函数。
隐含层神经元数的选取是影响网络模型容错性和学习训练的重要因素。隐含层神经元数目太多会导致学习时间过长,误差较大;隐含层节神经元数太少则网络训练效果不好,或者无法识别样本信息。面对复杂的样品体系,往往没有确定的定律来确定隐含层神经元的个数,更多时候,网络隐含层神经单元数的选取需要根据设计者的经验和多次试验来确定最佳隐含层神经元数。设计循环隐含层数目在5~20,以试验预测误差和预测来判断BP网络模型的优劣性。试验证明,当隐含层神经元个数为15的时候,网络的预测误差最小。
此外,训练次数亦是构建BP神经网络的重要参数之一,训练次数过多会造成网络的过拟合,导致预测结果偏差较大;训练次数过少则使网络难以收敛,达不到训练要求。该试验中,样本经PCA法压缩主成分后,在最大程度代表样品信息的基础上,光谱矩阵数据量较少,可有效减少网络训练的负荷。在网络学习前设置最大训练步数1 000,试验证明,网络训练220步左右即可达到预先设定的学习误差0.000 1(图3)。
2.5 构建BP神经网络模型识别不同种类的掺伪油
采用PCA法提取的前8个主成分、33个吸收峰数据作为BP网络的输入向量,以曲正切函数和对数函数作为隐含层传递函数,隐含层神经元个数为15,训练目标设定为0.000 1,训练学习速度为0.1,训练220步时,构建的BP神经网络可将掺有菜籽油、棕榈油的掺伪茶油和纯正茶油同时识别出来。模型对预测集识别结果如表3所示,以1.000代表掺有菜籽油的掺伪油样本的网络输出;2.000代表掺有棕榈油的掺伪油样本的网络输出;3.000代表纯正茶油样本的网络输出,可以看出BP模型对预测集样品的识别准确率误差较小,模型的预测能力良好。
3 结论与讨论
基于近红外光谱技术,经PCA法压缩并提取主成分,分别采用马氏距离聚类分析和BP神经网络建立了掺有菜籽油、棕榈油的掺伪油与纯正茶油的判别分析模型。从模型结果来看,2种不同的模型面对掺伪油含量较低的浓度下,对预测集样品的判别准确率均为100%,结果令人满意。
马氏距离聚类分析作为类模型基础上的模式识别方法,一般需要借助化学计量学的手段,经过光谱数据预处理后,方可建立判别模型。这是因为采用PCA法可从自变量矩阵和因变量矩阵中提取主成分,能够有效降维,明显地改善了数据结果的可靠性和准确度。然而,掺伪油体系中各组分的含量和光谱吸光度之间存在着非线性关系,采用BP神经网络建模时,能够凸显预测模型数据矩阵响应快速、运算便捷、预测准确的优势。特别是经PCA处理后,得到样品光谱吸光度、组分含量的主成分、权重值,能够为网络建模时、确定隐含层神经元数量此类重要参数时,提供重要的参考依据。同时,网络训练时,可减少迭代次数,跳出局部最少的弊端。
2种模型在训练中发现,BP网络模式识别结果比马氏距离聚类分析更迅速。说明BP网络作为一种无教师学习的神经网络,面对更加复杂多元的掺伪体系,突出了自学习、自组织、自适应和容错能力的优势,且运算快速,模型精度较高。
参考文献
[1] 张东生,金青哲,王兴国,等.基于脂肪酸组成甄别油茶籽油掺伪的研究[J].中国粮油学报,2015,30(1):124-128.
[2] 苏东林,张菊华,李高阳,等.近红外光谱结合化学计量学在茶籽调和油品质检测中的应用研究进展[J].中国食品学报,2018,18(7):332-338.
[3] 张菊华,朱向荣,尚雪波,等.近红外光谱结合偏最小二乘法用于纯茶油中掺杂菜籽油和大豆油的定量分析[J].食品工业科技,2012,33(3):334-336.
[4] 孙通,吴宜青,李晓珍,等.基于近红外光谱和子窗口重排分析的山茶油掺假检测[J].光学学报,2015,35(6):350-357.
[5] YUAN J J,WANG C Z,CHEN H X,et al.Identification and detection of adulterated Camellia oleifera Abel.oils by near infrared transmittance spectroscopy[J].International journal of food properties,2016,19(2):300-313.
[6] LI S F,ZHU X R,ZHANG J H,et al.Authentication of pure camellia oil by using near infrared spectroscopy and pattern recognition techniques[J].Journal of food science,2012,77(4):374-380.
[7] 郑艳艳,吴雪辉.掺伪茶油的化学模式识别方法研究[J].食品工业科技,2014,35(7):115-118.
[8] 李宗朋,王健,张晓磊,等.基于近红外光谱技术的沙棘籽油鉴伪方法研究[J].中国油脂,2014,39(2):57-62.
[9] 蔡立晶,蔡立娟,李文勇,等.基于近红外透射光谱及神经网络的大豆油质量分析[J].湖北农业科学,2015,54(1):175-177.
[10] 苗静,曹玉珍,杨仁杰,等.基于二维相关近红外谱参数化及BP神经网络的掺杂牛奶鉴别[J].光谱学与光谱分析,2013,33(11):3032-3035.
[11] 荣菡.基于近红外光谱的模式识别技术用于鲜乳掺假检测的研究[D].南昌:南昌大学,2008.
[12] 刘波平.近红外光谱技术在多組分检测及模式识别中的应用研究[D].南京:南京理工大学,2011.
