基于自然语言处理和深度学习的NL2SQL技术及其在BI增强分析中的应用
2019-12-11刘译璟徐林杰代其锋
刘译璟 徐林杰 代其锋
一、引言
1996年,Gartner提出BI的概念,随即成为了数据分析的重要技术。直到今天,BI也是企业首选的数据分析应用。但随着企业数据规模和复杂度日益增大,现在数据分析人员越来越难从海量的数据中找到有价值的结论。在这种背景下,Garnter于2017年提出了增强分析的概念:“增强分析是利用机器学习和 AI 等技术来帮助数据准备、洞察生成和洞察解释,以增强人们在分析和 BI平台中探索和分析数据。” 2018年,Gartner 在其发布的魔力象限报告中,明确指出增强型分析功能是 BI 产品发展的最重要、也是最显著的发展趋势之一,其原因并不难理解:“当前企业使用的数据的规模和复杂度已经逐渐超过人类可以处理的程度,静态报表、仪表板等传统工具已经不能满足需求,而通过机器学习、人工智能等技术增强分析,可以更好地处理这些数据。而如果利用自然语言处理、人工智能等技术的增强分析就可以自动、快速地对数据进行分析,辅助分析人员得到需要的数据洞察。”
实际上,百分点在自身的业务发展中也得出了与Garnter同样的观点。作为诸多企业第最重要的大数据应用,我们认为BI经历了三个阶段:
1990~2003年是第一阶段。这一阶段的特点是技术主导,数据建模特别是数据仓库建模的建设实施占据了BI项目的绝大多是时间和资源。而BI主要作为一种数据呈现的手段供极少数决策者使用。这时候的BI可以说是九成技术加一成业务;
2003年~2016年是第二阶段。这一阶段的特点是数据分析师主导,敏捷式BI开始流行。以Tableau为代表的BI工具逐步让数据分析不再是一个纯技术工作,而是技术+业务的混合工作。这时候可以说BI是五成技术加五成业务;
2017年开始是第三阶段,我们正在经历这个阶段。这个阶段的特点是数据分析平民化、普惠化,技术工作将主要集中在数据准备和数据治理方面,绝大多数数据分析工作都将由业务人员主导。未来的BI必定是一成技术加九成业务。相应的,BI的理论、技术和工具将有新一轮的升级改造。
正是看到了这些趋势,百分点在2017年开始自主研发增强分析BI工具CleverBI,我们期望通过引入自然语言处理、知识图谱、推荐算法和机器问答等人工智能技术,使得CleverBI可以理解用户的数据分析需求,并帮助其快速完成分析任务获得数据洞见。
智能问答功能是CleverBI中的一个重要功能,它允许用户以自然语言和语音的方式与系统进行交互式对话,系统分析对话内容提取出用户的数据分析意图,而后自动从数据库中提取数据、计算得到结果并进行可视化展现。譬如用户在系统中提问“2015年各地区的销售额”,系统自动就能展示如下图:
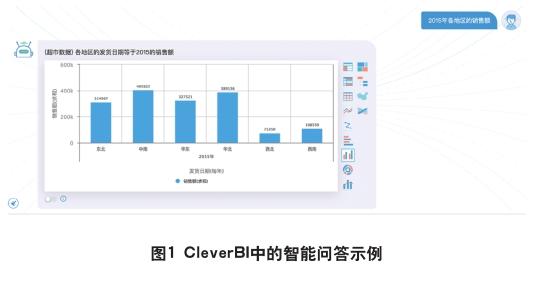
可以看出,智能问答实际上是一种特定的语义分析任务。在学术界,类似的任务最早可以追溯到1970年代提出的自然语言编程(Natural-language programming),是指将自然语言(研究比较多的是英语)翻译为特定的编程语言。在1980年代,人们又针对关系性数据库提出了自然语言数据库查询(Natural Language Database Query),也称为Text2SQL、NL2SQL等,现在这个领域变得越来越热门。目前,业内比较知名的是WikiSQL和Spider数据集及其相关研究成果。可惜的是,中文目前还没有统一的数据集,最近追一科技发布了一个10W级别的中文数据集用于其NL2SQL挑战赛,我们认为这个数据集有望成为中文数据集的标准。
在 WikiSQL 数据集上,Leaderboard 中的方法都是把NL2SQL任务转化为槽值填充,然后利用深度学习的方法训练多个不同的子模型对每个槽位进行填充,比如作为SOTA模型的X-SQL,而追一数据集上的 SOTA 模型M-SQL 采用的是和 X-SQL 类似的结构,但是为了提高过滤条件值的提取和匹配准确度,对模型结构进行了修改。虽然在WikiSQL 数据集和追一科技的数据集上,机器学习模型的效果已经超越了人类,但这两个数据集过于简单,很难覆盖真实应用场景。比如WikiSQL只支持1个查询目标(select)、1个聚合函数、最多4个过滤条件,且不支持分组。但是在实际使用中,有多个查询目标以及包含分组字段的问题比比皆是,比如“各省份的人口”,“每年的人口”,所以只采用 X-SQL 的方法是无法满足工业的需要。
Spider 数据集中支持对分组进行提问,而且支持跨表join,但是 SOTA 模型的测试准确率只有55%,还无法满足产品化的效果。
同时需要注意的是,在实际应用中,时间是一个很特殊并且重要的提问维度,比如用户可能会问“近七天的总销售额”,“2019/2018年的销售额”,“今年前三个季度的总销售额”等等,但关于时间的问题在上述数据集中都没有覆盖。
综上所述,考虑到已有数据集的局限性以及其上SOTA模型的能力。我们要想在CleverBI中实现比较好的智能问答功能,就必须针对CleverBI的场景定制新的技术和算法。这就需要我们的模型既能准确的提取问题中的槽位信息,又需要无监督的语义分析方法。所以我们综合了X-SQL和依存句法两种技术,首先采用X-SQL槽位匹配的方法提取出问题中的select、where 内容,然后利用这些信息辅助依存句法樹的解析,最终得到完整的select、where、group、order 等内容。而针对提问中的时间维度,我们采用定制模板的方法来处理,准确度和扩展性都能很好的保障。
下面的内容中,我们首先在第二节简介CleverBI智能问答的整体架构,在第三节介绍语义解析模块的流程,在第四节介绍最核心的问题解析模块的算法和流程,在第五节介绍我们的方法的实验效果,最后在第六届进行展望和进一步研究讨论。
二、CleverBI智能问答架构
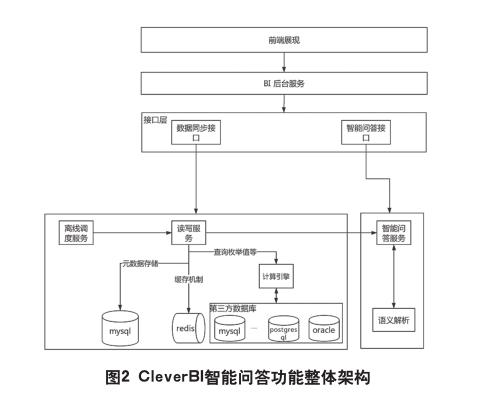
上图展示了CleverBI智能问答功能的整体架构,它主要包括三大部分:
(一)智能问答服务
用于接收来自BI后台的请求,并且返回解析完成的结果。
(二)数据库读写服务、离线调度服务、计算引擎等
后台在元数据发生变更时,会调用读写服务。读写服务的目的是在本地MySQL 数据库中的元数据发生变动时对缓存进行更新。并且利用计算引擎重新计算枚举值和数据样例,将最新结果存入本地 MySQL数据库中。
在智能问答中,需要利用第三方数据的枚举值和数据样例信息,辅助进行语义解析。所以当表的元数据发生变更时,需要重新进行计算。同时,为了保证枚举值的时效性,还需要一个离线调度服务定期自动计算枚举值,并且将结果存入 MySQL数据库。计算枚举值时采用如下公式:
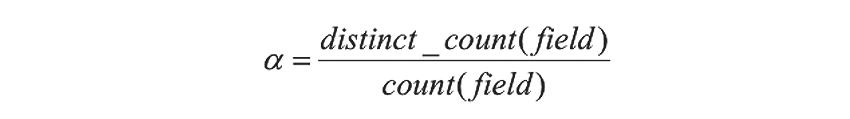
就是某个字段的不重复率,如果 ,则表示该字段是一个枚举值字段,该字段的不重复值就是所谓的枚举值。
计算引擎是一个统一的生成数据库查询语句并且提交数据库执行的程序,它提供统一的对外接口,但是支持在 MySQL、PostgreSQL、Oracle、Sql Server、MongoDB、Vertica、ClickHouse 数据库中进行查询。
(三)语义解析服务
这是智能问答服务的核心部分,它会把BI后台的参数,以及从数据服务中得到的数据整理成语义解析需要的结构,然后利用语义解析的流程解析得到最终的结果。下一节将介绍它是如何工作的。
三、语义解析流程
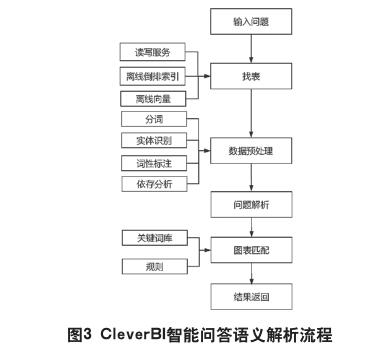
上图是智能问答功能中语义解析服务的工作流程,可以看出,当接受到一个用户提问时,系统会经过如下处理:
(一)找表
由于智能问答支持用户不指定具体的数据表就进行提问,所以语义解析的第一步就是要定位到哪个(些)数据表是适合用户的问题的,只有确定了表,后续的解析工作才能开展。为了能够准确快速地从所有数据表中匹配出需要的表,需要结合精确匹配策略和模糊匹配策略:
1. 首先执行精确匹配
精确匹配时,在离线任务中需要把表的字段名、枚举值、实体标签按字级别构建成倒排索引。倒排索引的内容如下:
键:字段名、枚举值的字,或者 ${PER}、${ORG}等标签;
值:(包含键的表id,该字出现位置列表)的集合,该字所在位置列表是指将字段名,枚举值按字典序排序之后,该字出现的所有位置所组成的列表。
实体标签包括人名、地名、组织名、电话、邮箱和时间。通过对数据样例进行命名实体识别或者正则表达式匹配求得,我们采用的是 pyltp 库判断数据样例的实体标签(人名、地名、组织名标签),通过正则表达式判断电话、邮箱和时间标签。由于一条样例数据可能是短文本,命名实体识别效果不佳,所以采用下面的公式判断:

其中 question 为问题中的字和实体标签的集合,table 为表的字段名、枚举值中的字和实体标签的集合,invert_index 为倒排索引,注意在对其取交集时只以表id为依据。
上述方式没有考虑字的位置,在某些情况下会出错。比如问题是“总销售金额”,其中一张表中包含“销售额”字段,另一个表中有“销售人”、“保证金”、“总额”。合理的方式是匹配到第一张表,但是上述方式会匹配到第二张表。把字位置的因素考虑進来,得到改进后的相似度计算公式:

其中 position_diff 的计算方式为,将问题中匹配出来的字按顺序排列,计算在倒排索引中记录的距离的差分序列之和。
通过这种方式,最后进行倒序排序就能够得到精确匹配下的最佳匹配表了。
但是在问题非常灵活的情况下,经常出现所有表的similarity都为零的情况,在这种情况下,就需要采用模糊匹配得到最优的表。
2. 精确匹配无法找到数据表时,利用模糊匹配寻找最优表
此时首先对问题进行分词,然后在问题上使用长度为3的滑动窗口从左向右滑动,每滑动一次,计算窗口内的词的向量和预先算好的表向量之间的相似度。在上面的过程中,都是通过word2vec 对词进行向量化。当窗口滑动完毕,每个窗口相似度的最大值就是表的分数,最后得分最大的表就是所要匹配的表。
经过精确匹配和模糊匹配的结合,我们会确定在哪张数据表上来回答用户的提问。
(二)数据预处理
在这一步,我们对问题进行分词、词性标注、实体识别和依存句法分析,提取出一系列的问题要素送到后续问题解析模块。
(三)问题解析
这是语义解析的核心,它负责将预处理得到的问题要素翻译为如下面例子的数据结构:

这个数据结构中包含了需要查询的字段、查询结果数量、排序和分组要求,并且说明了必要的指标和维度,信息非常丰富。不难看出这个数据结构是非常容易转化为SQL语句的我们会在下一节详细介绍问题解析模块是如何获得这个数据结构的。
(四)图表匹配
图表匹配是指问题解析得到上面的数据结构后,找到最适合用户提问的图表类型,以便最后进行数据展示。图表类型包括表格、柱状图、散点图、折线图、饼图、桑基图等。由于每种图表都有相应的维度、指标个数要求,为此我们设定了一个规则集来描述这些要求。规则集中每条规则都是以维度和指标为条件,图表类型为结果的。例如“如果维度个数>=0并且指标个数>=0,那么用表格”。规则的顺序需要按照图表的使用频率人为确定,在下面的规则匹配时这个顺序是很重要的,因为系统会从第一条规则开始逐个匹配,直到碰到满足条件的图表类型。
在图表匹配模块,我们采用的是“先关键词后规则”匹配过程:首先进行关键词匹配。关键词匹配是指根据提问中的关键词找到对应的图表类型。这需要预制关键词库,词库的格式为“词:对应的图表类型”,比如“占比:饼图”,“趋势:折线图”,“比例:饼图”。通过关键词库在问题上进行匹配,如果匹配成功,就得到了候选图表类型。如果该候选图表类型满足对应的图表类型规则,那么候选图表类型就是所需要的结果。否则系统直接使用规则的方式得到需要的图表类型。
四、基于X-SQL和依存句法树的问题解析
本节介绍语义解析中最重要的问题解析模块的实现技术。
问题解析是一个典型的NL2SQL任务。将自然语言转化成 SQL 本身可以认为是一个 Seq2Seq 的任务,所以在 WikiSQL 中很多早期模型也确实是这么做的,比如Corse2fine[ ],它会对问题和字段名进行编码,然后利用中间的预解码层将向量解码为 SQL 的框架,这个过程就能相当于自动生成了槽位模板,最后再把槽位模板也进行编码,结合原始的向量,最后能够解码出最终的 SQL。但是这样生成的结果不一定符合 SQL 的语法规则,所以后面改进的生成方法都是事先写好SQL 的模板槽,然后再用多个模型逐个预测槽位,X-SQL[ ] 就是其中效果最好的一种。
X-SQL 的大体流程如下图所示,通过 MT-DNN 对原始问题以及字段名称进行编码,但是在问题前面人为添加一个 [CXT] 用于提取全局信息。中间的 Context Reinforcing Laryer 层是这个模型的核心部分,它的目的是把 MT-DNN 得到的预训练编码在 NL2SQL 任务上进行增强和重组。这个层包括体现上下文信息的 h[CXT],以及通过 Attention机制对字段名称的编码进行强化(紫色部分)。这一层输出的结果包括问题的编码,以及强化后的字段编码,后面的输出层都在这个基础上进行。 输出层包括了6个子模型:S-COL和S-AGG 用于预测 select的字段,只依赖于强化后的字段名称编码,通过 softmax对每个字段打分就行了。W-NUM 只依赖全局信息h[CXT],用于预测 where 条件个数。W-COL、W-OP和W-VAL 用于预测过滤条件的具体内容,通过组合字段编码,当前的 where 条件编号以及问题编码,通过softmax评分就能得到需要的结果。
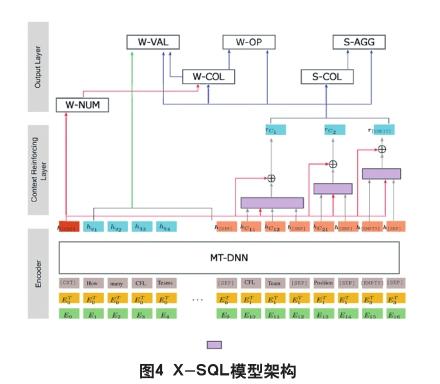
这个架构已经十分完善了,但是由于数据的局限,模型无法预测多个 select 以及 group 的内容。而且模型完全依赖字段名称去提取过滤条件和select的内容,在中文字段名称特征不够明显或者领域数据和训练数据偏差较大时,容易出错。
另外,传统的语法分析一般依赖于依存句法分析的结果,能够把问题的语法依赖关系体现出来,在此基础上结合 POS,NER 的結果,可以使依存语法树上的每个节点都具有词性、实体标签等属性。然后通过后序遍历,每次遍历到父节点的时候,都将孩子节点的以及当前父节点的内容通过规则进行整理合并,最终遍历到根节点的时候,就得到了select、group 等要素。这种方法的好处是它完全依赖于问题的语法规则,不需要训练数据,并且对于领域不敏感,迁移性强。它的缺点是只能处理相对规范的问题,对非常灵活的问题效果不佳。
那么,如果我们能结合上述两种方法的话,就能把语法和语义结合起来,得到能力更为强大的分析模型。也就是说 X-SQL 从深层语义的角度提取要素,而语法分析从问题的语法组成结构上进行提取。
我们的问题解析模块就是采用了上述思路,它的实现原理如下:首先用 X-SQL 得到解析结果,然后在依存句法树中将 X-SQL 的结果标记在依存语法树的节点上,作为它的属性之一,然后进行上述的遍历过程。对于非常灵活的问题,一般该方法得到的结果就是 X-SQL 的结果,对于相对规范的问题,语义解析方法能够对 X-SQL的结果进行补充和纠正,从而得到功能更加强大,效果更好的结果。
我们用两个小例子来看一下具体的算法流程。
例子一:“各地区的总新增订单量”
步骤1:分词后的结果(需要考虑字段名,X-SQL 的结果): 各 / 地区 / 的 / 总 / 新增订单量
步骤2:得到的聚合了所有信息的树:
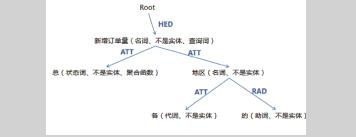
其中 HED、ATT 等表示依存关系,HED 表示核心关系,ATT 表示定中关系,RAD 表示附加关系。
步骤3:通过词库以及后序遍历解析依存树:
1.首先遍历到“总”。由X-SQL得知这是聚合函数;
2.遍历到“各”。得到这个是一个分组描述符;
3.遍历到“的”。得到這是一个无意义的词;
4.遍历到“地区”。从表中匹配得知这是一个字段名称,从孩子节点处得到的信息以及 ATT 的关系,得知这是一个分组字段;
5.遍历到“新增订单量”。由 X-SQL 得知这是查询词,并且结合孩子节点得知聚合函数是“总”,分组词是“地区”;
6.遍历到root,得到最终结果:select内容为总新增订单量,分组字段为地区。
步骤4:得到解析结果并输出。
例子二:“销售额最高的3个地区”
步骤1:分词后的结果(需要考虑字段名,X-SQL 的结果): 销售额 / 最高 / 的 / 3个 / 地区
步骤2:得到的聚合了所有信息的树:
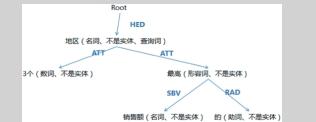
其中 SBV 表示主谓关系。
步骤3:
1.遍历到“3个”。由词性及规则得知这个是 limit。(不是 where 中的内容,否则会被 X-SQL 标记出来);
2.遍历到“销售额”。得知这是一个字段名;
3.遍历到“的”。得到这是一个无意义的词;
4.遍历到“最高”。由依存关系,以及孩子回溯上来的信息,得知这个是一个降序排序信息;
5.遍历到“地区”。由 X-SQL 得知这是查询词。并且整合孩子节点的所有信息,得知limit 3, 按销售额降序排序;
6.遍历到root,得到最终结果:select内容为地区,limit 3, 按销售额降序排序。
步骤4:得到解析结果并输出。
特别需要注意的是,在具体应用的过程中,经常会出现比较复杂的时间问法。比如“上个月”、“近7天”、“一二季度“、“2018/2019年”等。对于这些问法相对固定,但是解析时需要利用大量知识的内容,我们采用了模板的方法进行处理。一个模板包括问法模板和解析结果两部分。
问法模板定义了问法的句式,由槽位、普通字符和正则语法构成,其中槽位暂时只用 ${num} 就够用了。例如“${num1}${num2}季[度]”,“${num1}/${num2}年”。
解析结果是问法模板对应的解析结果。由“value”,“start”,“end”三个字段构成。“value”是列表,每个值定义了某个具体时间,存在多个时相互间取并集。“start”和“end”表示一个时间段的开始时间和结束时间,只有当 “value”不存在时才会有“start”和“end”。在解析结果中需要 NOW_YEAR、NOW_ MONTH、NOW_DAY 常量表示当前的年、月、日。
下面是一个具体的模板实例:

其中 template表示问法模板,result 表示解析结果。这个模板可以匹配类似“近7天”模式的时间表达。
有了模板之后,只需要解析模板就行了。只需要将template 转化成对应的正则表达式,然后把问题中的词替换成对应的槽位,就能进行匹配了。匹配完成之后,将得到的槽位信息对应填入 result 中就得到了最终的解析结果。
五、智能问答的实验效果
在学术界一般都会以WikiSQL和Spider作为训练集和测试集,都是英文数据集。X-SQL采用通过对WikiSQL翻译得到的5w条有标注数据进行训练,取其中 5000条作为测试数据,准确率达到了80% 以上。但由于WikiSQL 不支持复杂时间以及分组,不具备可比较性,而在Spider上目前最优效果为测试准确率 55%。实际测试环境中,由于中文NL2SQL领域还没有统一的数据集,所以我们通过收集用户实际在平台上的使用数据,最终得到了 266条中文测试数据(问题中可能包含了分组、过滤条件、复杂的时间表达、查询内容、排序等),在这个基础上进行测试,得到的结果如下:
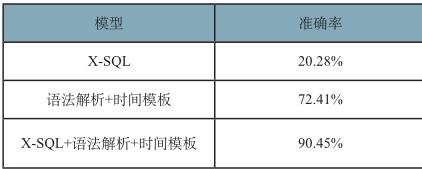
可以看出,本文提出NL2SQL实现方法更加具备实用性。
六、展望和进一步研究计划
CleverBI智能问答已经具备商用的条件,我们计划在实际应用中大量收集数据,形成类似甚至超越Spider的中文NL2SQL标准数据集,这对该领域来说至关重要。
同时,虽然智能问答中最核心的问题解析模块已经取得了不错的准确度和扩展性,但除此之外的找表、预处理和图表匹配步骤还需要大量的人工规则,在扩展性方面并不理想。在后续的研发计划中,一方面我们需要进一步提升问题解析的效果;另一方,我们计划利用半监督和无监督算法替换现有的算法,让整个过程更加灵活。
作者单位:北京百分点信息科技有限公司
