分布式NameNode在云存储平台中的应用
2019-12-10丘刚玮黄欣
丘刚玮 黄欣

摘要:为了解决HDFS单一NameNode处理大批量并发访问的瓶颈问题,论文提出了一种基于MongoDB数据库的分布式NameNode节点架构,增强节点的处理能力,进一步提高了HDFS集群的性能。实验结果表明:基于MongoDB数据库的分布式NameNode节点架构方案不仅有效扩展了HDFS的命名空间,同时提高了HDFS集群的并发读写能力。
关键词:MongoDB;分布式存储;单一NameNode节点;HDFS
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2019)28-0040-03
Abstract: Aiming at the bottleneck of concurrent access of HDFS single NameNode, a distributed NameNode architecture based on MongoDB database is proposed. It improves the processing capacity of nodes and the performance of HDFS cluster. The experimental results show that the approach of MongoDB and distributed NameNode not only extends the namespace of HDFS effectively, but also improves the concurrent reading and writing ability of HDFS cluster.
Key words: MongoDB; distributed storage; single NameNode; HDF
HDFS(Hadoop Distributed File System)是Google GFS开源的Hadoop分布式文件系统,可存储海量大数据,由于其具有高可靠性、高可用性、高伸缩性等特性,目前已经成功应用于航空安全QAR(Quick access recorder)数据分析[1]、医学影像存储[2]、预测模型[3]、云储存系统平台实现[4]等多个领域。由于单一NameNode限制导致的性能问题,HDFS在实际应用过程中渐渐暴露不足之处。众多学者针对此问题进行多方面的改进,文献[5]的改进方法是在DataNode 节点中存储小文件的元数据信息;文献[6]采用元数据压缩打包方式来减少元数据的大小;文献[7]在另一台服务器存放元数据块到Datanode的映射信息,以降低NameNode的压力。这些改进有效地减少了NameNode节点的读写请求,在一定程度上减缓了单一NameNode性能问题。但是这些改进方法的本质不变,还是由一个主节点NameNode控制访问交互[8]。随着文件数量级增长,大批量并发访问,单一NameNode节点的连接数和处理能力将受到极大的挑战,导致整个HDFS集群性能瓶颈。为了从本质上解决单一NameNode限制问题,基于MongoDB数据库对其架构进行优化,以便能够支持多NameNode节点。
1 单一NameNode的HDFS分析
现有HDFS使用的是主/从架构,一个HDFS集群包括了单一NameNode节点及大量DataNode节点。NameNode节点管理和维护所有的命名空间和元数据信息。当Client访问HDFS集群时,由NameNode控制访问交互,再执行实际数据操作,可以说整个HDFS集群仅仅一个入口点。所以,NameNode节点相当于是整个集群的核心和关键。此外,DataNode节点还可以与Client及另外的DataNode节点进行交互。为了避免单一NameNode节点限制问题,HDFS尽可能减少了Client对NameNode节点的操作。Client在读写数据时,首先向NameNode節点获知元数据信息,然后根据这些信息直接与DataNode节点交互,进行读写数据。虽然尽可能使NameNode轻量级,但元数据信息仍然占文件系统超过一半以上。随着HDFS运行的任务数量的增加,NameNode的负荷变得越来越重,必定影响文件系统整体性能。Client对HDFS的操作都必须先向NameNode节点请求,虽然客户端只需获知较少的元数据信息,但如果同一时间有非常多的请求,NameNode的负荷非常重,有些Client的操作就无法及时响应,这就是HDFS关于单一NameNode的性能问题核心所在。
2 可扩展的多NameNode节点优化原理
2.1 优化难点分析
在现有的HDFS架构中单一NameNode节点是HDFS的主要服务器,负责管理管理和维护整个文件系统的命名空间和元数据信息,分工明确。Client对HDFS集群发送请求时都必须先和NameNode交互才能与相应的DataNode节点进行实际的数据操作。即把单一NaneNode架构优化为多NameNode节点的架构关键之处主要有以下三点:如何命名分布式NameNode,当单一NameNode节点变为到多NameNode节点时,多NameNode节点该如何命名以及分布;如何定位有关文件元数据信息的位置,当Client发起读某一文件请求时,如何快速定位NameNode节点并获取其元数据信息,进一步获取DataNode节点信息读取相关文件;数据一致性问题,当Client与某一个NameNode节点的对其元数据信息进行更改操作,其他的NameNode节点如何实时获取同样的更改并作出一样的更改操作。
2.2 基于MongoDB的解决方案
Mongodb是一种分布式NoSQL数据库,基于C++语言,可支持关系型数据库的绝大多数操作,可存储多种格式的数据类型[9]。MongoDB数据库兼具存储性能高、易部署、易于使用、功能丰富、支持索引等优点。非关系型数据库可在HDFS上部署,相对于传统关系型数据库,NoSQL数据库部署在分布式集群上,增加了可存储的数据量,可以维护更多的DataNode,扩展性更强,并减少了对单个节点的通信压力。
引入MongoDB的优化方案,把整个文件系统的命名空间以及元数据信息的控制由NameNode转化为MongoDB数据库中,采用星型状将多个NameNode节点与MongoDB连接,每个NameNode节点相当于只是负责整个文件系统一部分命名空间,所有NameNode的元数据信息的集合才是整个文件系统的命名空间和元数据信息。当启动HDFS集群时,将重构有关数据块和DataNode节点间的映射信息,并将其记录到MongoD数据库。规定某个指定的Client只能和某个指定的NameNode进行交互,各个NameNode间没有交互,保证文件系统的一致性。其架构如图1所示:
当Client发起请求时,先与其中一个NameNode节点连接,根据命名空间查看是否存在所需的元数据信息,如果无,则对MongoDB数据库进行查询,获取相应文件名的元数据信息(文件名和数据块间映射,数据块和DataNode节点间映射),将其加载到NameNode节点内存中。当Client下次访问该文件的时,可直接在NameNode节点获取相关的元数据信息,就不用再对MongoDB进行访问,即“一次加载,多次读取”,相当于原始的单一NameNode节点同Client和DataNode节点进行交互。
在写数据时,实时更新当前NameNode的元数据信息,利用延迟写的策略将系统更改后的元数据信息写入MongoDB数据库中,以便有效减少地写数据库造成的延时。
3 MongoDB和分布式NameNode节点优化
设计每一个NameNode的元数据信息一开始都是空的,实际整个文件的命名看空间和元数据信息都在MongoDB数据库中,每个NameNode在首次使用时先在MongoDB数据库中加载所需信息,在元数据发生变化时,该数据实时更新到数据库中,并通知其他NameNode节点。
对于整个系统的元数据信息存储在MongoDB数据库,分析MongoDB和分布式NameNode节点优化方案的读写过程。
3.1 读文件操作
基于MongoDB数据库和HDFS优化方案有关读文件操作过程如下:
(1) Client发送读请求,通过open()函数打开文件,并创建Distributed File System对象。
(2) Client创建读取相应文件数据信息的FSData Input Stream对象,利用read()函数来向FSData Input Stream对象传递用户的请求信息。
(3) HDFS的FSData Input Stream对象接收用户请求后与NameNode节点交互,获取该用户的数据块地址信息。
(4) NameNode根据FSData Input Stream对象传送过来的请求信息判断该用户的数据块的信息是否存在,如果存在,则向Client端的FSData Input Stream對象返回该用户的数据块的信息;如果不存在,NameNode节点就去Mongo DB数据库中读取所需的数据块信息,并将此信息保存在NameNode中,然后再向Client端的FSData Input Stream对象返回该用户的信息。
(5) FSData Input Stream对象接收返回的数据块文件的地址信息后向该用户的DataNode节点发出read()请求,读取用户所需要的元数据信息,并呈现给用户,此时利用close()函数关闭读取数据流,HDFS读操作完成。
3.2 写文件操作
基于MongoDB数据库和HDFS优化方案有关写文件操作过程如下:
(1) Client发起写请求,利用open()函数来打开文件,并建立Distributed File System对象。
(2) 利用create()方法创建文件上传的FSData Output Stream数据流对象。
(3) 向特定的NameNode发送新建文件目录的请求,该文件条目下是空的。优化后的方案存在多个NameNode,必须事先指定不同的NameNode。
(4) NameNode节点接收请求信息后根据Client身份判断是否有操作权限,再判断所需文件条目是否存在,若有则不创建;若无则创建。
(5) 把用户数据与DataNode数据节点对应,并依次写入相应的数据块文件。
(6) 当DataNode节点存储完成后向FSData Output Stream对象返回确认。
(7) Client的FSData Output Stream对象将文件名和数据块间映射,数据块和DataNode节点间映射等元数据信息存入相应的NameNode节点,NameNode节点再将该元数据信息持久化到MongoDB数据库中。
(8) 待需要上传的文件完成后,Client会执行close()函数关闭写操作流,HDFS写操作完成。
4 实验结果与分析
4.1 实验环境配置
在单一NameNode节点限制优化测试方案中,选用两台物理机上架构HDFS系统,即NameNode的配置为Inter(R) Xeon(R) CPU E5-1620 v3 @3.5 GHz,内存为512M,分别命名为NameNode1和NameNode2,MongDB所在服务器的配置为Inter(R) Xeon(R) CPU E5-1620 v3 @3.5 GHz,MEM为2.0GB。
4.2 实验参数设置
针对并发访问处理的实验设计,对于改进前的方案,模拟12个Client进程,对HDFS并发读写操作;对于改进后的方案,模拟6个Client进程访问NameNode1,6个Client进程访问NameNode2。设定文件读写规模为1000、3000、5000、10000、15000,每个Client进程分别对改进前后的系统并发读写,并分别其记录写入时间。
4.3 结果分析
4.3.1 并发读写文件速度对比
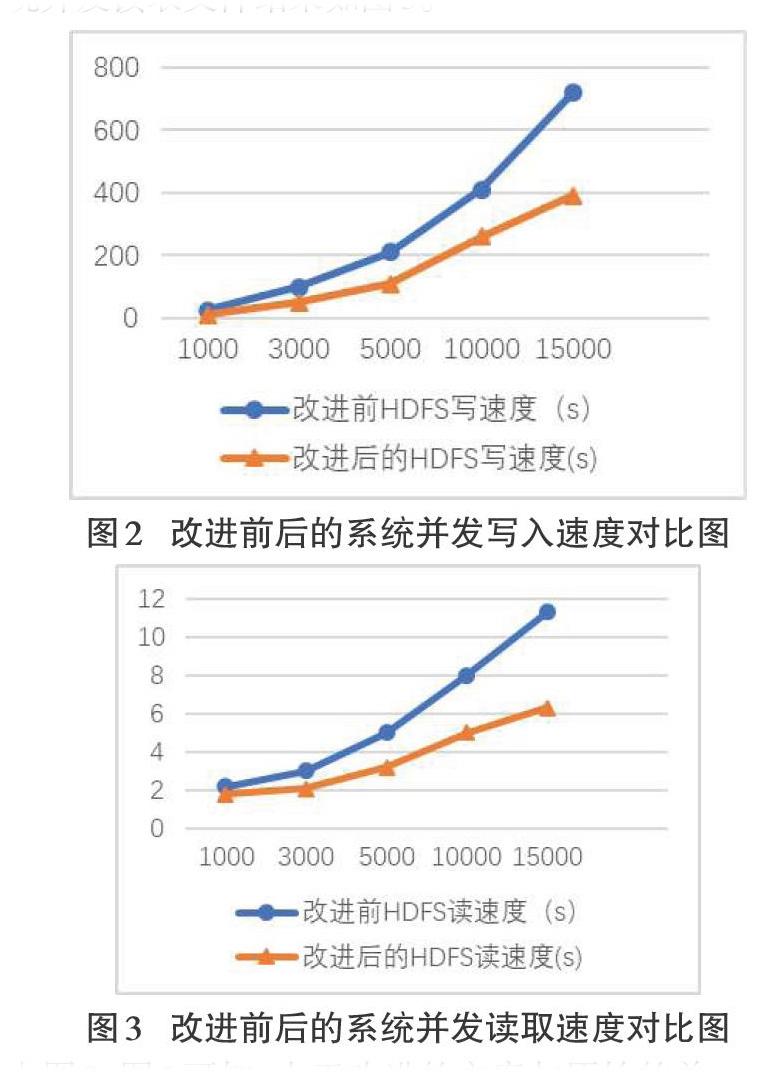
改进前后的系统并发写入文件结果如图2所示,改进前后的系统并发读取文件结果如图3。
由图2、图3可知,由于改进的方案与原始的单一NameNode方案不同,采用了基于MongDB数据库的NameNode1和NameNode2多个NameNode,使得系统能够在处理进行并发读写请求,尤其是文件数据量比较多的情况下,分布式NameNode节点的处理能力优势比较明显。
4.3.2 首次响应和元数据加载为实体响应
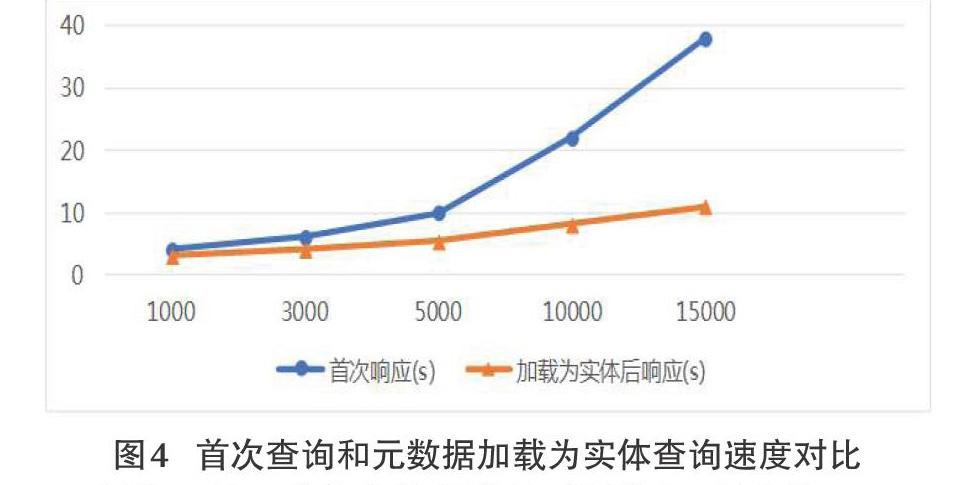
上述实验是基于所有的元数据都存在NameNode中的并发读时间,由于NameNode进行首次查询元数据的时候,先查询MongDB数据库的信息。所以,需要测试首次响应和元数据加载为实体后响应延迟时间,文件规模同上。实验结果如图4。
由图4可知,随着文件规模的不断增大,首次从MongoDB里加载元数据信息延迟比较严重。但是,由于元数据信息在首次加载后,之后的操作就不必去查询数据库,所以,即可以“一次加载,多次读取”,在实际应用中这些延迟基本是可以忽略不计的。
综上,在大规模文件数据下,分布式存储的优势比较明显,分布式NameNode+MongoDB方式响应时间最快,并使得HDFS的命名空间得到扩展。
5 结束语
HDFS分布式文件存储由单一NameNode节点控制多个DataNode节点的存储方式容易在单一NameNode节点出现瓶颈问题。分布式NameNode+MongoDB方案的核心思想将HDFS集群中由原来的一个NameNode节点控制的架构优化成多个NameNode控制。该方式既保证了整个集群数据信息的完整性又有效地减轻了单一NameNode节点的负荷,进一步扩展了HDFS的命名空间,同时提高了HDFS集群的并发读写能力。
在以后的工作中,将对改进HDFS进行更深入的研究,如解决分布式NameNode负载均衡的问题。
参考文献:
[1] 冯兴杰, 吴稀钰. HDFS可视化及其在QAR数据中的应用研究[J]. 中国民航大学学报,2017,35(01):56-59.
[2] 方胜吉, 李忆昕, 周姗姗. 探析HDFS在区域医学影像存储上的应用[J]. 电脑编程技巧与维护, 2017(22):89-90.
[3] 于磊春, 陈健美, 刘响, 等. 基于预测模型的HDFS集群负载均衡优化与研究[J]. 计算机应用与软件, 2018 (05):155-162.
[4] 陈虎. 基于HDFS的云存储平台的优化与实现[D]. 华南理工大学, 2012.
[5] Jiang L , Li B , Song M . THE optimization of HDFS based on small files[C]// IEEE International Conference on Broadband Network & Multimedia Technology. IEEE, 2011.
[6] Mackey G , Sehrish S , Wang J . Improving metadata management for small files in HDFS[C]// IEEE International Conference on Cluster Computing & Workshops. IEEE, 2009.
[7] 欒亚建. 分布式文件系统元数据管理研究与优化[D]. 华南理工大学, 2010.
[8] 高考数据分布式存储优化的设计与实现[D]. 山东师范大学, 2017.
[9] 曾强, 缪力, 秦拯, 等. 面向大数据处理的Hadoop与MongoDB整合技术研究[J]. 计算机应用与软件, 2016(2): 21-24.
【通联编辑:代影】
