提高fuzzing 边覆盖率的改进方法
2019-12-03贾春福严盛博王志武辰璐黎航
贾春福,严盛博,王志,武辰璐,黎航
(1.南开大学网络空间安全学院,天津 300350;2.南开大学人工智能学院,天津 300350)
1 引言
fuzzing[1]是一种有效的漏洞挖掘技术,它通过生成大量的测试用例来对目标程序进行测试,同时监视目标程序的运行过程,发现程序暴露出的缺陷。传统的fuzzing 工具由于生成测试用例时过于随机,其测试存在盲目性,虽然测试速度很快,但效率很低。针对fuzzing 存在的问题,研究者提出了很多新的技术和方法,结合覆盖引导、静态分析、动态符号执行、语法表示、动态污点分析和机器学习等多种技术,大大提高了fuzzing 的效率,并且在现实的软件中发现了大量漏洞[2]。
覆盖引导的fuzzing 策略被广泛使用,并且已被证明是非常有效的。它尽可能地测试更多的代码分支,使程序的代码覆盖率实现最大化。目前,代码覆盖率有2种基本的测量方式。一种是计算基本块(BBL,basic block)覆盖数,Libfuzzer、honggfuzzy和VUzzer[3]都是通过程序插桩来跟踪BBL 的覆盖信息。另一种是计算边覆盖数,AFL(American fuzzy lop)是第一个将边覆盖引入fuzzing 的工具,其通过编译时静态插桩,当程序运行时可获取边覆盖信息,提供了比BBL 覆盖更加精确的信息。
最近几年发表了大量基于AFL 的研究。一类研究是定向fuzzing。例如,AFLGo[4]和Hawkeye[5]通过对程序的静态分析来调整种子排序和种子的测试次数,逐步引导程序到达目标点。另一类研究结合了符号执行技术。Driller[6]使用选择性的混合符号执行技术,当AFL 被“卡住”时,调用 Angr[7]来生成合法输入,从而有效地分析大规模程序。WildFire[8]先通过单独测试程序中的函数来发现漏洞,再使用KLEE[9]来校验这些漏洞的可行性。还有一类研究结合了人工智能技术。孙鸿宇等[10]分析了人工智能技术在安全漏洞领域的应用。Godefroid等[11]基于神经网络的统计机器学习,生成富含格式的文件作为AFL 的初始种子。Skyfire[12]从样本中学习一种概率上下文敏感语法(PCSG,probabilistic context sensitive grammar)来描述语法特征和语义规则,利用PCSG 生成具有不同语法结构的种子输入,从而为处理高度结构化输入的程序生成正确、多样和不常见的种子。
然而,AFL 本身也存在一些缺陷,通过对这些缺陷的修复,可以优化上述方法的效果。例如,CollAFL[13]针对AFL 边覆盖记录存在冲突的问题,通过静态分析生成新的hash 计算式,把冲突率降低到接近0,大大增加了覆盖信息的准确率,提升了AFL 的效果。
此外,本文研究团队也发掘出AFL 中隐藏的几个缺陷和可以进一步改进的地方,主要有以下几个方面。1)AFL 的种子选择算法存在缺陷。其进行选择时,实际隐含了一个固定顺序,使队列中排在越后面的种子被选中的概率越低。更严重的问题是,执行完一轮循环后,被选中的种子可能并没有覆盖到所有的边。2)AFL 对每个选中的种子执行的变异次数几乎一样,没有考虑到每条边的热度(即这条边被覆盖到的次数)。3)AFL 会记录哪些字节变化时会产生新的状态转移,但是这些记录信息未被有效利用,并且在从进程中无法使用这些记录信息。
针对上述问题,本文着眼于AFL 算法的缺陷,同时对一些功能进行了改进,具体包括以下几个方面。
1)提出了完全覆盖种子选择算法。该算法随机打乱边的顺序,以打乱后的顺序进行种子选择,且只选择队列中位于当前位置之后的种子,最后对覆盖情况进行检查并修复覆盖不全的问题。本文所提算法避免了按固定顺序选择优先种子集,同时也避免了对边覆盖不完全的情况。
2)提出了基于边覆盖热度的能量调度算法。根据路径中边的覆盖热度,对每条路径进行评分,以此为依据动态调整每个种子文件的变异次数。
3)增加对有效字节的利用。在进行随机性变异时,更多地对有效字节部分进行变异。同时加快了有效字节的产生,并在主进程和从进程之间同步有效字节信息。
基于上述方法,本文在开源的AFL 工具上,设计和实现了新的fuzzing 工具—efuzz,并按照Klees等[14]提出的测试思想进行实验,实验结果表明efuzz的边覆盖和漏洞发现能力都超过了 AFL 和AFLFast。使用常用软件测试24 h 后,efuzz 的平均边覆盖数相比AFL 和AFLFast 分别提升了5%和9%,某些情况下甚至达到20%以上。使用LAVA-M[15]测试7天后,efuzz 发现的漏洞总数超过了AFL。在常用软件中,efuzz 发现了3个新的CVE漏洞,其中一个是 binutils 工具包中的漏洞CVE-2018-20671,该漏洞从2001年起就已存在。
2 相关知识和技术概述
2.1 AFL 概述
AFL 是一个覆盖率引导的灰盒测试工具。它基于遗传算法,采用编译时插桩的方式,通过获取被测试程序运行时的覆盖信息反馈,来判断是否触发了目标程序新的内部状态,从而发现感兴趣的测试用例,以此引导fuzzing 策略,这大大提高了测试工具的覆盖率。
图1展示了AFL 的简易流程,具体步骤如下。
步骤1提供一个初始输入集加入种子队列。
步骤2按照种子选择算法从种子队列中选择优先种子集。
步骤3按预设概率,顺序从种子队列中选择一个种子文件。
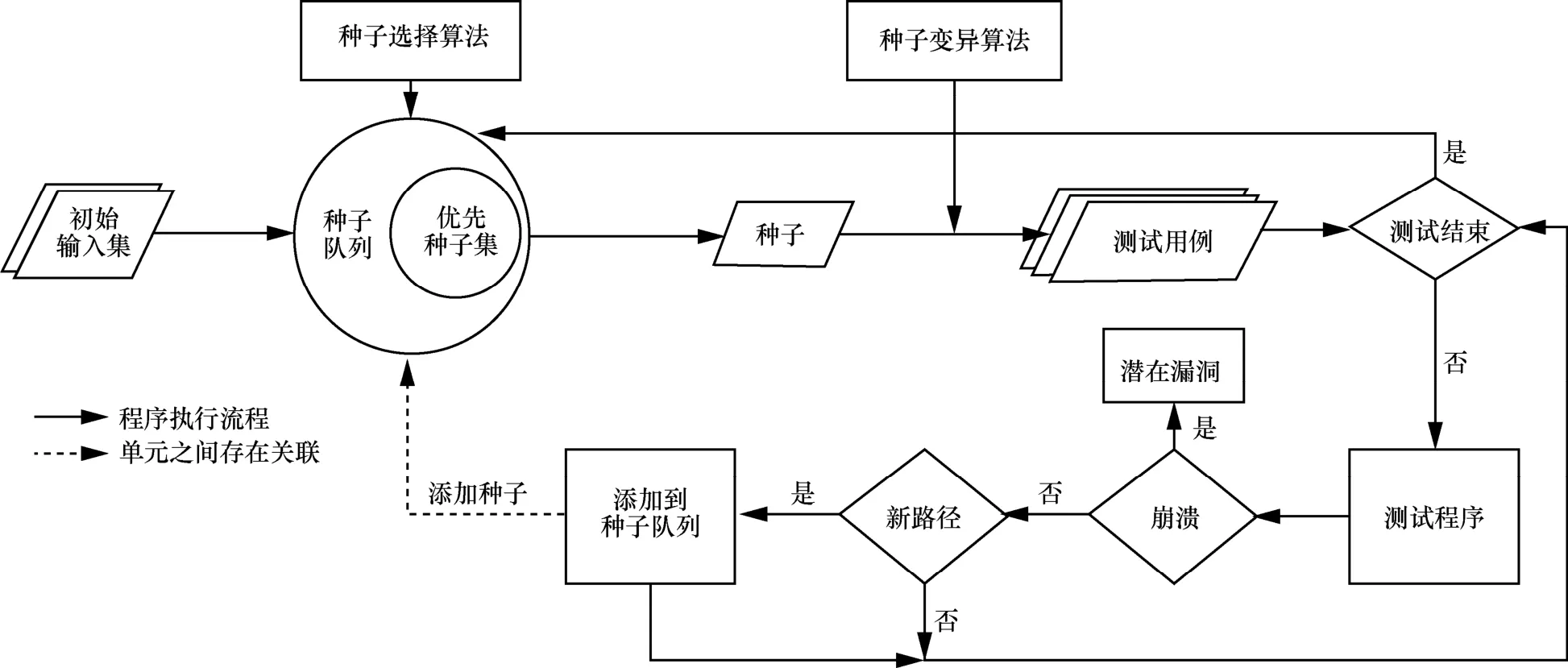
图1 AFL 简易流程
步骤4使用多种变异算法对种子文件进行变异,循环生成大量测试用例进行测试。
步骤5如果发现程序崩溃,那么这可能是一个潜在的漏洞。
步骤6如果发现了新的路径,那么把生成该路径的测试用例加到种子队列。
步骤7对该种子生成的所有测试用例,如果测试结束,回到步骤3。
整个测试是一个无限循环过程,直到人工终止。
2.2 边覆盖记录
AFL 记录的边覆盖信息包括边的hash 以及这个边被命中的次数。边覆盖信息使用规模为216的数组记录,边hash 作为数组的索引,数组中的值是边被覆盖的次数。为了加快处理速度,AFL 在每个BBL 中插入了一个0~65535的随机数,边hash 是由边的首尾2个BBL 中的随机数通过简单hash 算法生成的,记录覆盖信息的算法伪代码如下。
1)edge_hash=cur_bbl ^(last_bbl >>1)
2)shared_mem [ edge_ hash ]++
很显然步骤1)中的hash 算法会存在冲突问题,但这不是本文的研究重点。本文把一个hash 记录直接对应为一条边覆盖记录。
2.3 种子选择算法
fuzzing 中如何从种子队列中选择种子是一个非常关键的问题。之前的工作已经证明,良好的种子选择策略可以显著提高模糊效率,更快地发现更多的bug[16]。
为了理解AFL 的种子选择算法,首先介绍以下2个概念。
优先种子。覆盖到某一条边的最好种子称为该边的优先种子。最好种子就是所有能够覆盖到该边的种子中,对其进行一次完整测试所消耗时间最短的种子。
优先种子集。可以覆盖当前已经发现的所有边的优先种子集合,即优先种子集的覆盖面等价于当前所有种子的覆盖面。
AFL 调用种子选择算法从整个种子队列中选出优先种子集,随后按概率优先选择其中的种子来进行测试。该算法本质上是一个贪婪算法,如算法1所示。
算法1AFL 的种子选择算法
输入每条边对应的优先种子T[65536]、种子队列Q
输出选择结果S

算法1按照边的hash 值,在0~65535范围内按从小到大的顺序选择该边的优先种子,直到覆盖所有已发现的边。由于被测试程序编译生成后,所有边的hash 值就已经确定了,因此这实际上是一个固定的选择顺序。
2.4 能量调度
Böhme 等[17]提出了能量的概念,能量指一个种子被选中后的测试次数。能量调度即按照一定算法对能量进行控制。AFL 给每个种子分配相同的能量,这忽略了对路径稀有度的考量,可能将过多的能量分配给高密度区域[18]。AFLFast 使用马尔可夫模型,给低频路径分配了更多的能量。但是,AFLFast 总是朝着低频路径,可能会错失对一些边的探索,导致代码覆盖率不高。Klees 等[14]也指出了AFLFast 的这个问题。
2.5 有效字节信息
如果对种子文件中某个字节进行翻转后产生了与原种子对应路径不同的新路径,那么这个字节就是有效字节。下面具体解释相关概念。
确定性阶段和随机性阶段。AFL 分为确定性测试和随机性测试两大类。确定性测试阶段对种子的变异方式是高度确定的,且每个种子只会经历一次确定性测试,而随机性阶段会调用一些随机算法对种子进行变异。
主进程和从进程。AFL 可以有多个进程并行工作,主进程对每个选中的种子先进行确定性测试,再进行随机性测试;从进程只进行随机性测试。同时,主进程和从进程之间定期进行种子同步。
AFL 使用如下方法来记录有效字节信息。当一个种子经过确定性阶段的字节翻转子阶段时,观察种子文件中某个字节的翻转对执行路径是否有影响。如果对这个字节翻转后,产生了与种子对应路径不同的新路径,则使用 eff_map(effector maps)来记录这个字节,在确定性测试的剩余子阶段中只对eff_map 中记录的字节进行变异。这样一般可以将测试的执行次数减少10%~40%左右,而不会显著降低覆盖率。在极端情况下,例如块对齐的tar 文件,执行次数可能减少高达90%。
3 fuzzing 改进方法
3.1 完全覆盖种子选择算法
AFL 的种子算法本身基于如下完全覆盖性约束:选出的优先种子集必须能完全覆盖所有已经发现的边。通过2.3节的介绍以及实验测试,发现算法1存在以下缺点。
1)按照边的hash 值以0~65535的固定顺序选择,导致种子被选中的概率相差太多,hash 较小的边对应的优先种子总是被先选择。举个极端的例子:按照算法1,假设hash 值为0的优先种子T[0]被选中,而T[0]对应的种子为s0,如果s0生成的路径刚好覆盖了所有已发现的边,那么每次都只会选择s0这一个种子,其他种子永远无法被选到优先集合。在实验中记录每次选出的优先种子集也发现,每次选择出的优先种子集变化极小。如果采用随机的顺序进行种子选择,可以缓解这个问题。
2)AFL 每测试一个种子后,如果种子队列发生了变化,就会调用一次算法1,这可能导致执行一轮循环后,有的边没有被覆盖,这种情况违背了完全覆盖性约束。出现这个问题的根本原因在于选择了队列中位于当前位置之前的种子,具体以代码1为例进行说明。
代码1AFL 种子选择算法缺陷示例代码

代码1编译后对应的控制流程如图2所示。
图2中每条边上的数字代表该边的编号,以ei表示边i,只有顺序通过边e2、e6、e14的路径才会触发bug。
以qj表示第j条路径,假设初始发现的6条路径如表1所示。
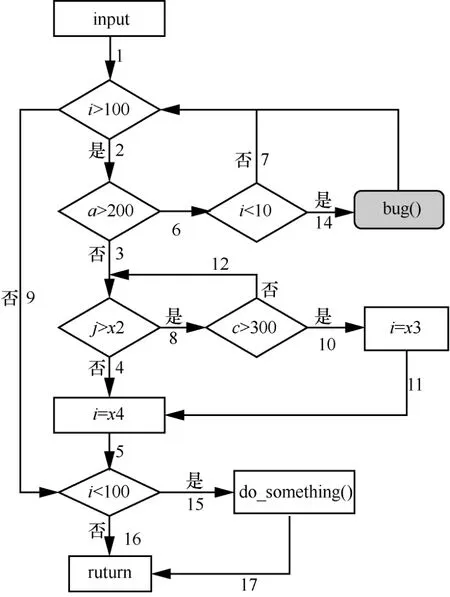
图2 AFL 种子选择算法缺陷示例

表1 路径说明
假设这些边经过hash 运算后的值,从小到大的顺序为(e9,e8,e17,e6,…),且测试按照以下步骤进行。
步骤1测试q1,发现新路径{q2,q3,q4},这时覆盖的所有边集合为{e1,e2,e3,e4,e5,e6,e7,e9,e15,e16,e17}。调用算法1选择优先种子集,按照边hash顺序(e9,e17,e6),先选择e9对应的优先种子q4,再选e17对应的优先种子q3,这时已经覆盖了所有边,选择结束,优先种子集的结果为{q3,q4}。
步骤2q2不在优先种子集中,被跳过。
步骤3测试q3,发现新路径{q5,q6},这时覆盖的所有边集合为{e1,e2,e3,e4,e5,e6,e7,e8,e9,e12,e15,e16,e17}。再次调用算法1,按边hash 顺序(e9,e8,e17,e6),先选择e9对应的优先种子q5,再选择e8对应的优先种子q6,由于e17已经被q6覆盖,对其跳过处理,最后选e6对应的优先种子q2,选择结束,结果为{p5,q6,q2}。
步骤4q4不在优先种子集中,被跳过。
步骤5测试q5。
步骤6测试q6。
整个测试过程中,按照种子队列从前向后的顺序判断是否选择该种子,没有对可到达e6的q2和q4进行测试。虽然AFL 存在随机性变异,也有可能通过其他种子变异出到达e6的测试用例,但是随机性变异过于盲目,概率过低,导致很难到达e14,从而无法触发bug。
上述例子说明了AFL 在一轮循环中,虽然每次选择的优先种子集能覆盖所有已发现的边,但是真正测试的种子却可能会漏掉某些边。上述情况看似概率很小,但是本文通过实验发现这种情况大量存在。
针对上述2个问题,本文提出了完全覆盖种子选择算法,如算法2所示。
算法2完全覆盖种子选择算法
输入每条边对应的最好种子T[65536]、种子队列Q、当前位置queue_cur
输出选择结果S

算法2共分为4个步骤,具体如下。
步骤1把本次循环中已经测试过的种子文件直接加入S并更新C。
步骤2生成0~65535的乱序排列。
步骤3按照步骤2生成的序列从T中挑选种子加入S,并更新C。只有当前位置之后的种子才会被加入S。
步骤4检查每条边是否被覆盖,如果没有覆盖,从当前位置向后找到一个可以覆盖该边的种子文件,添加到S并更新C。
下面使用数学归纳法对上述算法的覆盖完整性进行证明。
1)测试开始时第一次选择的优先种子集显然可以覆盖到所有已经发现的边。
2)假设第n次选择的优先种子集Qn能够覆盖到所有已经发现的边。当第n+1次选择时,当前位置把Qn切分为两部分,一部分是在当前位置之前(不包含当前位置)的集合Q1,另一部分是当前位置之后(包含当前位置)的集合Q2。如果出现了新的边,这些边对应的种子文件会被增加到队列尾部,这些新种子文件的集合记为Q3。根据假设,可推导出Q1∪Q2∪Q3能够完全覆盖当前所有的边。按照算法2,在步骤1中Q1全部被选中,而步骤4是检查步骤,当发现某条边e尚未被覆盖时,则e∉Q1,那么必然有e∈Q2∪Q3,这说明从当前位置向后查找,一定可以找到一个种子文件对应的路径包含e。因此,步骤4完成后可保证对边的完全覆盖。
上述证明说明算法2满足完全覆盖性约束,同时算法2采用乱序选择,且从当前位置开始选择新的优先种子,可以有效避免出现算法1的2个缺点。
3.2 基于边覆盖热度的能量调度算法
王志等[19]分析僵尸网络控制命令时,提出了BBL 覆盖率的概念,用来描述一个BBL 被执行路径覆盖的频繁程度。受此思想启发,本文用边的热度来描述一条边被所有路径覆盖的次数,结合2.4节的分析,提出了一个新的能量调度算法。
用N(e)表示边e的热度,计算式为
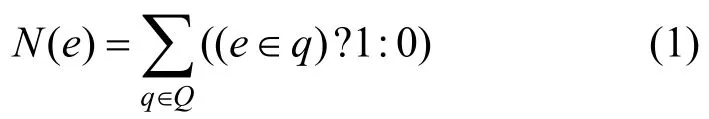
边的评分与该边的热度成反比,即这条边被覆盖的次数越多,评分越低。每个种子文件对应一条执行路径,一条执行路径由多条边组成。路径评分为该路径中边的评分之和,p(q)为路径q的评分,定义为
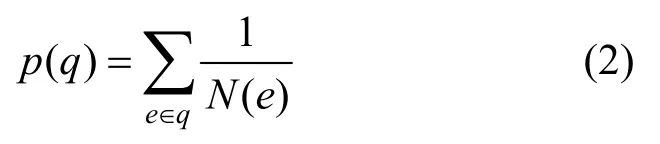
将上述评分进行归一化,得到路径q的调整系数,定义为
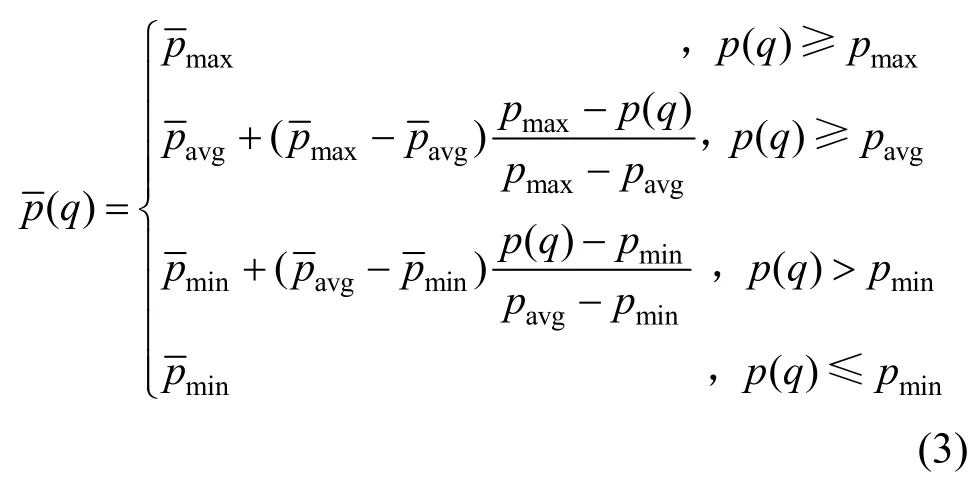
其中,pavg为所有种子对应路径评分的均值,pmin为最小值,pmax为最大值。分别为预定义的调整系数。
1)热度越低的边,被给予越高的权重,有可能得到越多的执行机会。
2)fuzzing 往往难以到达很深的代码块,该算法对边评分采用加法,较长路径的评分会有更多的优势,有利于覆盖更深的边。但这也可能导致路径探索被局限在某一些分支上,针对这个问题,在具体实现中可通过对系数的调整来达到一定的平衡。
AFLFast 通过路径覆盖频率来选择种子,而本文方法则是通过边覆盖热度来选择种子,通过实验分析,本文方法在边覆盖上比AFLFast 更优。
3.3 有效字节信息的进一步利用
2.5节中提到的有效字节机制非常可靠,并且很容易实现,但是也存在如下问题。
1)只有确定性阶段使用了有效字节信息,随机性阶段并没有使用,未能充分发挥其效果。
2)有效字节信息由主进程产生,但主进程速度很慢。在实验中发现,有时主进程用一周时间都无法执行完一次循环,这会导致可利用信息非常少。
本文提出了3种进一步利用有效字节信息的方法。
1)在随机性阶段使用有效字节信息引导变异。在应用随机性算法时,按一定概率只对有效字节进行变异。
2)在从进程中也使用有效字节信息。保存主进程中记录的信息,供从进程使用。
3)当存在从进程时,主进程去掉随机性阶段,只处理确定性阶段,可加快有效字节信息的产生。
针对以上方法,需要在确定性阶段把eff_map信息记录到文件,当从进程对这个种子进行测试时,直接加载这个文件。
AFL 中共有16种变异方法,如表2所示。这些方法中,变异位置都是随机选择的。efuzz 中对此进行了改进,按一定概率只选择eff_map 中记录的位置进行变异,不再是完全随机选择变异位置。

表2 随机性阶段的变异方法
随机性阶段会对文件进行多次变异。除了12、13、16这3种方法可能改变种子文件长度外,其他方法不会改变种子文件的长度。一旦变异过程中文件长度发生变化,eff_map 记录信息将不再准确。因此,efuzz 把随机性阶段又分成了2个子阶段:第一个子阶段不采用12、13、16这3种方法;第二个子阶段采用所有16种方法,一旦文件长度发生了变化,就立即恢复到AFL 原有的方式。
4 系统设计和实现
AFL 的最新开源版本是2.52b,efuzz 扩展了这个版本,共添加了不到1000行的C 代码,实现了第3节中描述的技术。
在算法2中对每个种子进行顺序编号,相比原来的算法,仅增加了种子选取顺序的随机化处理和最后的检查,因此整体增加的CPU 消耗几乎可以忽略不计。
在能量调度算法中,对路径的评分实际上是很难准确定义的,本文采用了比较保守的策略,设置3个调整系统的值分别为0.2、0.8、4,且只有在发现的总路径数超过200时,才启用这一策略。因为该算法中都是浮点计算,为降低计算量,每增加20条以上的新路径才重新计算一次评分。其次,该算法中所有种子对应的覆盖信息都要记录下来,每个种子需要占用8 KB 的内存空间。在本文的实验中,总路径很少有超过12000的,因此,总计算次数不会超过600,单个进程的内存增长数不会超过100 MB,对计算机资源的整体消耗非常小。
在确定性阶段测试过的种子,需要把它的有效字节信息记录到一个对应的以.eff 为后缀的文件。eff 文件中每一位表示该种子的1 B 是否是有效,因此eff 文件大小只有种子文件的,对存储资源的消耗也非常小。
5 实验与分析
Klees 等[14]指出了当前fuzzing 实验中普遍存在的一些问题,并给出建议的测试方法,希望能建立统一的测试标准。本文中的实验按照他们提出的测试思想,以如下方式进行测试。
1)共选择了5个常用的目标程序,分别是binutils 程序集中的objdump、nm、readelf,以及libtiff和tcpdump。
2)对每个测试程序选择了5个有代表性的初始输入,输入分别来源于空种子、随机种子、公开的测试样本、漏洞的POC(proof of concept),表3是实验中具体使用的输入文件。由于有些程序使用空种子和随机种子无法测试,因此本文使用其他种子代替这2个种子的实验。
3)涉及对边覆盖数进行比较的实验,每个实验都测试30次,每次测试时间为25 h。由于实验数据并不是实时更新的,选取第24 h 这个时间点的数据来进行评估。最终结果取30次的平均值。
4)每次实验使用一个主进程和一个从进程共同测试,更加接近真实使用环境。
5)以AFL 和AFLFast 作为比较对象。AFLFast和efuzz 一样,也是针对AFL 本身算法的改进,且是开源软件,方便进行实验。
6)Stephens 等[6]指出使用唯一状态转换的数量作为边覆盖的度量是合理的,本文实验也使用状态转换的数量作为边覆盖的度量。

表3 实验使用测试程序和种子文件
实验共使用了3台服务器,都是64位Ubuntu 16.04 LTS系统,CPU为Intel(R)Xeon(R)E5-2620 v4@2.10 GHz,内存64 GB,硬盘12 TB。
5.1 边覆盖的完整性测试
为了对AFL 和efuzz 的种子选择算法进行测试,在它们的算法中添加了检查代码,每次算法执行完时,都对优先种子集的边覆盖情况进行校验,检查本轮循环中已测试过的优先种子和当前位置之后还未测试的优先种子是否覆盖了所有已经发现的边,如果出现覆盖不全的情况,则进行日志记录,并记下每次选择最多有多少边未被覆盖。
实验用表3中各测试程序对应的5个文件共同作为该程序的初始化种子,只运行1 h。由于efuzz采用了新的种子选择算法,保证了覆盖的完整性,结果中并未出现覆盖不全的情况。而AFL 中出现了大量覆盖不全的情况,如表4所示。
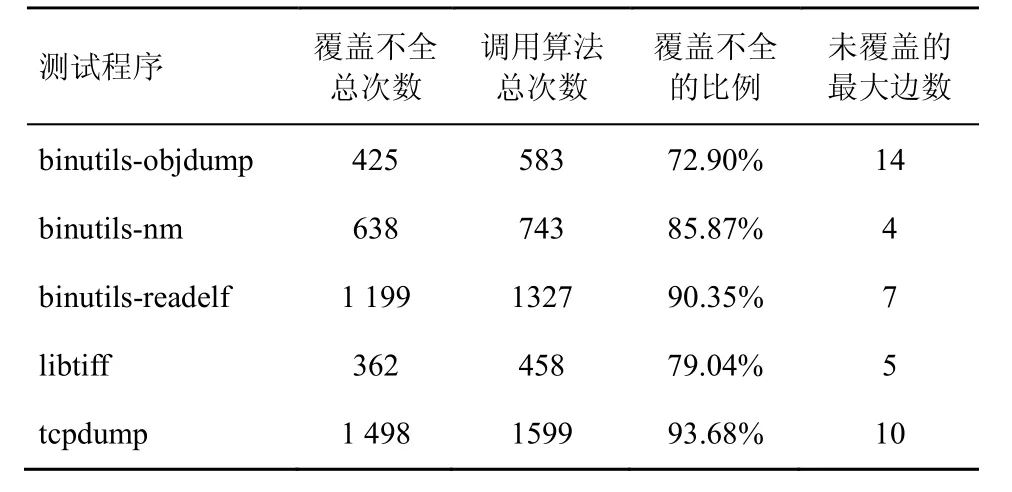
表4 AFL 边覆盖不全的记录
由表4可知,AFL 覆盖不全的比例非常大,虽然每次未覆盖的边数非常少,但依然说明了AFL 的种子选择算法在一轮循环中并未满足完全覆盖性约束。
5.2 能量调度算法和有效字节信息改进的效果验证
实验中开发了仅启用能量调度算法的程序efuzz-Enery 和仅启用有效字节信息改进的程序efuzz-Bytes,用于单独测试这2个改进的有效性。每个改进的测试选择了5个实验,每个实验进行30次,结果如表5所示。
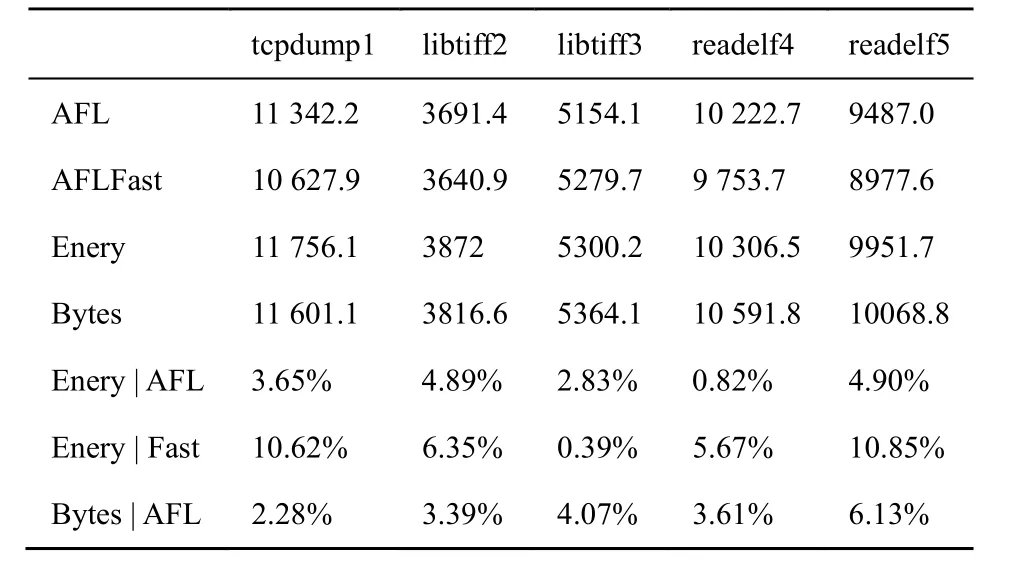
表5 单独测量的边覆盖数
从比较结果来看,efuzz-Enery 相对AFLFast 有比较大的提高,同时比AFL 也有一定提高,证明了本文的能量调度算法比AFLFast 在边覆盖率上更有优势。
通过比较efuzz-Bytes 与AFL 可以看到,efuzz-Bytes 相对AFL 也有少量的提高,说明有效字节信息的合理利用可以在一定程度上提升AFL 的效果。
5.3 efuzz 与其他工具的比较
实验对比efuzz、AFL 和AFLFast,使用5个程序,并把每个程序对应的5个种子文件分别作为初始输入,共25组实验。进行该测试的资源要求非常高,总开销为25×30×25×2×3=112500核·小时=4687.5核·天。表6是24 h 的平均边覆盖数结果,从整体来看,efuzz 在覆盖数上优于AFL 和AFLFast。同时也发现,AFLFast 在平均覆盖数上要略差于AFL。
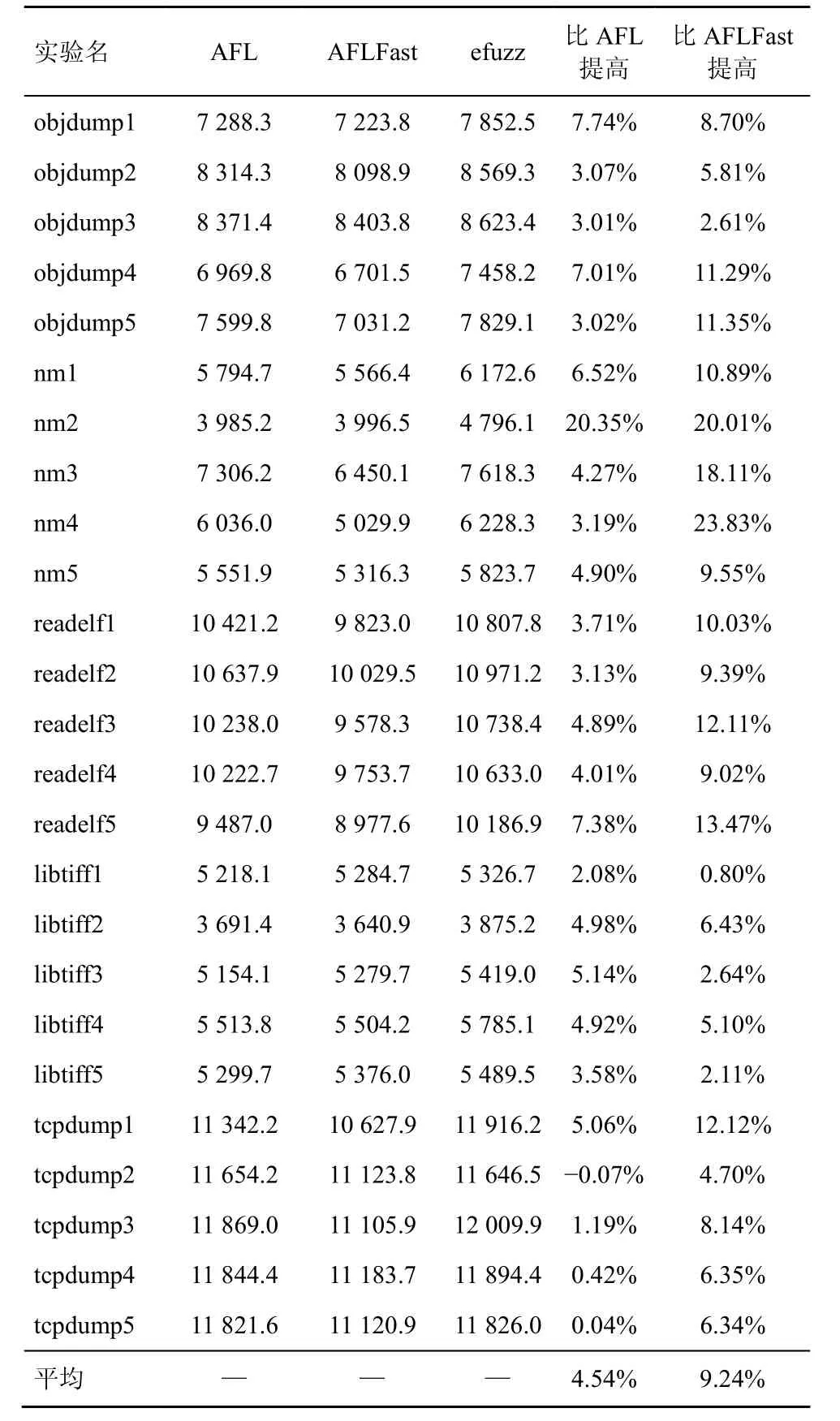
表6 25组实验的平均边覆盖数
单独分析每一组实验,efuzz 几乎在所有情况下都优于AFL 和AFLFast。在nm2中,efuzz 的边覆盖数甚至提高超过20%,但在tcpdump 实验中,efuzz 表现一般,仅仅略好于AFL,tcpdump2中甚至比AFL 低0.07%。这说明本文的改进方法在绝大多数情况下提高了边覆盖率,但是在极少数情况下也引入了一些限制。这也进一步说明了Klees 等[14]提出的评估方法的合理性,只有通过大量不同条件下的实验,才能比较全面地评估fuzzing 工具的有效性。
5.4 LAVA-M 测试
对LAVA-M 中的4个程序,使用其提供的默认种子文件进行测试,每个程序各运行7天。表7中数据显示,AFL 在base64和uniq 中发现的漏洞数超过了efuzz,但efuzz 在who 中发现的漏洞数远超AFL,且在4个程序中发现的漏洞总数也超过了AFL。
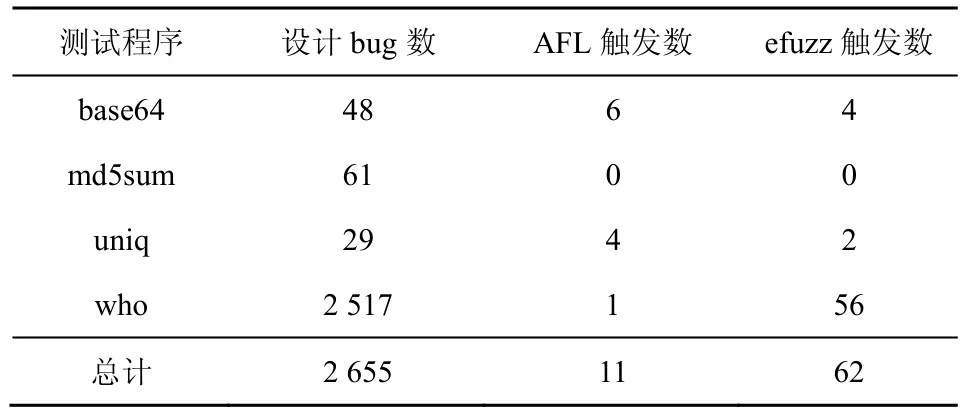
表7 LAVA-M 测试发现漏洞数
LAVA-M 在测试程序中插入了许多字符串比较和整数校验代码来阻碍fuzzing 工具,而AFL 的变异算法很难产生适当的输入绕过这些代码,导致无法到达新的代码块,因此AFL 和efuzz 在LAVA-M上的效果都很差。虽然efuzz 在who 上的表现超过了AFL,但发现的漏洞数也仅占总漏洞数的2%。efuzz 在base64和uniq 上差于AFL,再次说明了efuzz 的改进方法在有些情况下反而效果更差,且同样对校验性的代码无法达到很好的绕过效果。
5.5 新的CVE 漏洞
表8是使用efuzz 发现的3个新的CVE 漏洞,CVE-2018-20671是binutils 中的一个整型溢出漏洞,最终会触发堆溢出。CVE-2018-20467是ImageMagick 中的一个拒绝服务漏洞,会造成CPU和内存资源的耗尽。CVE-2019-6988是openjpeg 中的一个拒绝服务漏洞,由于其逻辑问题,会长时间占用大量CPU 资源。本文研究团队向相关厂商反馈了这些问题,现在这3个漏洞都已经得到修复。

表8 efuzz 发现的漏洞
表8中CVE-2018-20671最早存在于binutils 2.11中的objdump 程序,该版本的发布时间是2001年。从那时起,绝大多数的版本都存在这个漏洞。objdump 是一个广泛使用的二进制工具,也是很多相关论文中的测试目标程序,大量的研究者对其进行fuzzing,都没有发现这个漏洞。本文使用收集整理的种子文件,用一个进程进行30次测试,efuzz平均只需要519 s 就能发现这个漏洞,而AFL 和AFLFast 在相同时间内都无法发现这个漏洞。这进一步证明了efuzz 的有效性。
6 结束语
目前,fuzzing 是软件漏洞挖掘领域最有效的方式之一,覆盖率的提高一直是研究的重要方向。本文首先基于fuzzing 中边的完全覆盖性约束,设计了完全覆盖种子选择算法,并基于边覆盖热度提出了新的能量调度算法,最后进一步利用了AFL 中的有效字节信息。上述改进方法也可推广到其他fuzzing 工具中。从实验结果来看,本文实现的efuzz 相对AFL 和AFLFast 在边覆盖率和漏洞发现能力上都有提高,并在常用软件中发现了新的漏洞。但efuzz 依然存在很多改进空间,比如在tcpdump 上的效果并不明显,在tcpdump-2、base64、uniq 上的实验结果还要略差于AFL。同时在不知道被测程序结构的情况下进行fuzzing 依然存在盲目性,如何结合程序分析来获取更多被测程序信息,以及结合其他方法进一步提高边覆盖率,还需要在接下来的工作中进行更深入的研究。
