基于SSD 的实时车辆检测算法研究∗
2019-11-29明德烈
谭 威 周 斌 张 辉 明德烈
(1.华中科技大学自动化学院多谱信息处理技术国家级重点实验室 武汉 430070)(2.宇航智能控制技术国家级重点实验室 北京 100854)(3.北京航天自动控制研究所 北京 100854)
1 引言
随着生活水平的不断提高,汽车逐步成为了人们出行的代步工具,然而日益增长的车辆对已有的车辆监管系统提出了巨大的挑战。传统通过人工判读的方法在处理海量的交通视频信息已显得越来越乏力,搭建智能检测识别系统以自动处理各种交通视频信息已成为主流趋势。车辆检测作为车辆监管系统中一项最基础的关键技术,长期以来就是国内外广大学者的重点研究对象。
近几年来,随着机器学习的逐步深入研究,车辆检测算法大致可分为两类:基于车辆特征信息的检测和基于机器学习方法的检测算法。基于车辆特征信息的检测算法主要根据图像中的边缘信息[1~2]、纹理[3~4]、角点[5~6]、颜色[7]、形态学等特征信息来检测定位车辆。文献[8]改进了混合高斯背景模型,结合帧差法和背景差分法的高效性,克服了对光照变化敏感的问题。文献[9]根据车辆阴影划分感兴趣区域,再运用车辆自身的纹理特征对该假设进行验证,取得了不错的效果。文献[10]通过Sobel 算子检测出图像中所有垂直边缘图像信息,并运用垂直积分投影特性获得感兴趣区域。文献[11]通过分析车辆的边缘信息等,运用Gabor 滤波器提取相应特征,并使用SVM 分类器取得了不错的效果。文献[12]将易错分类但分辨率高的浅层特征与分辨率低但抽象化的高层特征融合起来,得到了更好的候选区域,进一步提高了检测的准确率。文献[13]利用Faster R-CNN 网络提取车辆的深度卷积特征,不仅克服了一直以来对手工特征的依赖问题,而且大幅度地提高了目标的检测效率。然而,这两种深度学习方法并没有达到实时性的要求。
2016年,Wei Liu提出来SSD检测算法[14]。SSD是一种新颖的端到端(End-to-End)的检测算法。SSD也属于CNN,但SSD不仅保留了之前CNN的检测高效性,同时也保证了检测的实时性。
我们用以VGG 为基础网络的SSD 算法检测视频中的车辆。通过实验,可以发现SSD算法不仅能够保证准确率,也能达到实时性的要求。
2 SSD算法
CNN 网络检测车辆时,主要分为以下几个步骤:首先在图像中生成候选框,然后对候选框进行特征提取,最后根据训练好的分类器对该特征进行候选验证。这样虽然能够保证检测的准确率,却达不到实时性的要求。SSD 算法由此应运而生,它兼具了实时性与准确性,是目标检测历史上的重大突破。为了进一步提高准确率,我们对基础网络提取的特征做了多层次的级联。
2.1 SSD介绍
SSD 网络基于前馈卷积网路,其根据裁剪或扩张产生固定大小的边界框,并通过打分系统得到框中对象类别的分数,最后运用非极大值抑制算法消除冗余的重复框得到最后的检测框。在本实验中,我们以VGG-16 网络[15]作为基础网络,通过该特征提取网络对输入图像进行特征提取。与常见的CNN 网络不同,我们并没有采用全连接层,而是设计了一种新的辅助结构,由此得到了具有以下两种特征的检测器。
1)多尺度特征图检测器:在基础网络的末尾依次添加若干卷积特征层,这些层的尺寸逐渐减小,形成了一个类似于金字塔的结构,增强了网络对车辆大小的鲁棒性。而且,每个特征层上检测得到的卷积模型各不相同。
2)检测的卷积预测器:我们设计了一组卷积滤波器用于新增加的特征层,这样就可以得到固定的预测集合。对于具有c 个通道、大小为m×n 的特征层,我们利用大小为3×3×c 的卷积核,得到类别的分数或者相对于默认框的坐标偏移。在特征图中,通过大小为m×n 的卷积核作用,在相应位置得到一个输出结果,见图1。

图1 SSD网络结构
2.2 网络训练
与其他分类器不同,在训练SSD 网络模型时,我们需要将车辆的真实标签信息指定到检测器输出集合的某一特定输出中。一旦指定对应关系确定,我们就可以采用端对端方式应用损失函数和反向传播。
在训练阶段,我们首先建立了车辆的真实标签与训练集中默认框之间的对应关系。对每个标签框,我们都从确定好的默认框中进行选择。在训练开始时,我们匹配每个真实标签框与默认框最好的杰卡德(Jaccard)重叠。通过添加这样的匹配,可以大大地简化学习问题。这样,我们也可以从多个重叠默认框中取得较高的置信度。
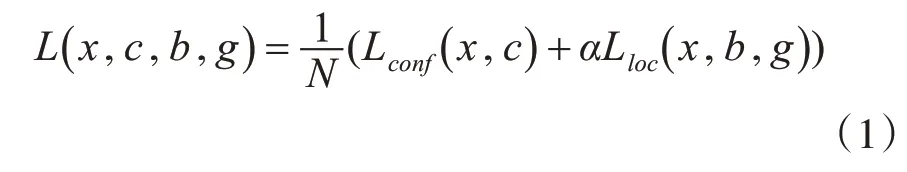
其中N 是匹配默认框总数,当N=0 时,我们认为损失为0。
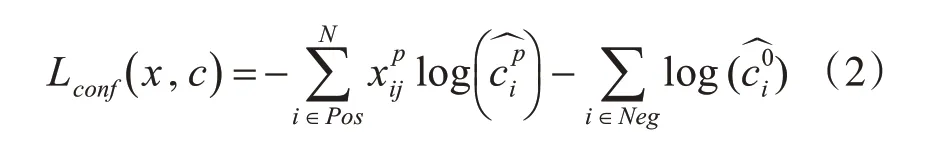
其中

位置损失是预测框与真实标签值框参数之间的平滑损失。
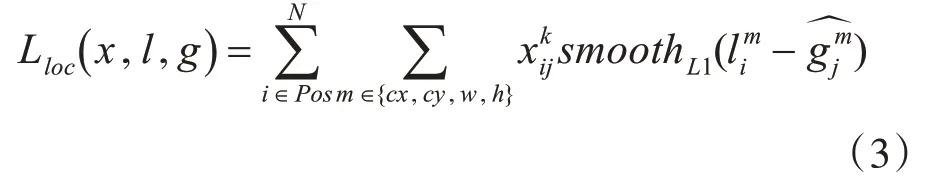
其中
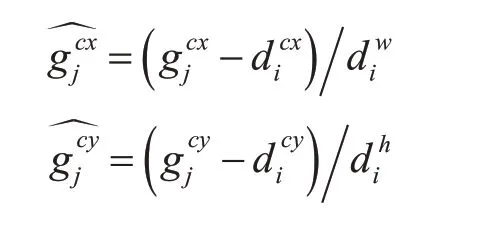
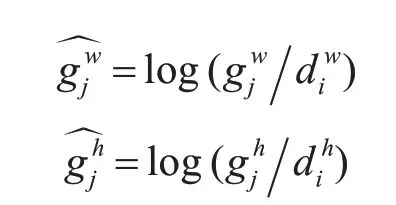
随着网络层数的增加,在池化过程中,所得到的特征图不断减小,这样不仅降低了计算量,节省了内存,更在一定程度上保证了特征的平移和尺度不变性。为了使算法对尺寸有良好的鲁棒性,Sermanet 等将不同大小的图像作为训练集,得到了不错的效果。然而,我们可以结合基础层中不同层次提取的特征图的预测结果来达到类似的结果。通过Hariharan 等的实验结果可以知道,较低层可以捕获到输入对象的更加精细的细节,因此较低层的特征图可以提高语义分割结果。类似地,高层特征图中采样得到的全局文本也可以提高平滑分割的结果。在SSD框架内,设定的默认框不需要一一对应于每层的实际感受视野。我们通过特征图所在位置的不同尺寸大小的组合以及不同宽高比的默认框的预测结果可以得到包含了输入对象不同尺寸和形状的预测集合。例如图2中,车4×4 特征图的默认框相匹配,但不与8×8 特征图默认框相匹配。这是因为默认框都具有不同的尺寸大小,但并不能匹配车的框,因此在训练期间被认为是负样本了。

图2 SSD示意图
在匹配步骤之后,以真实标签为中心的大多数默认框都是负样本,这将导致在训练过程中正负样本比例的严重失调,由此降低检测的准确率。因此,我们将每个默认框的最高置信度排序,通过选择排序在前的框,保证正负样本比例最多为3∶1,以此替代使用所有的负样本。
在训练过程中,为了使模型对输入图像的大小和形状更具鲁棒性,通过对训练图像做随机的采样方式来做数据增广。如果真实标签的框中心在采样片段内,则保留重叠的部分。同时为了保持网络的统一性,我们将每个采样片大小设为固定值,并以0.5的概率进行水平翻转。
3 实验结果与讨论
3.1 数据集
本文中,数据集来自于城市的交通监控视频,总共截取10000张分辨率为1280×720 的图片。其中7000 张图片为训练集,3000 张图片为测试集。在训练集中,我们把目标分别分为A,B,C 三类。其中A 是机动车,B 是非机动车,C 是行人,如图3所示。

图3 样本类别示例
3.2 实验平台
实验主要在PC 端完成的。PC 主要配置为i7处理器、GPU(GTX-1080ti)和32G 内存。SSD 和YOLO[16]使用了TensorFlow 框架,使用的编程语言为Python。
3.3 实验结果
使用VGG16 作为基础网络,我们采用SSD 可以得到如图4所示的检测结果。
通过测试结果,得到SSD,YOLO和背景相减法(BGS)的查准率、查全率以及识别帧率(f/s),结果如表1所示。
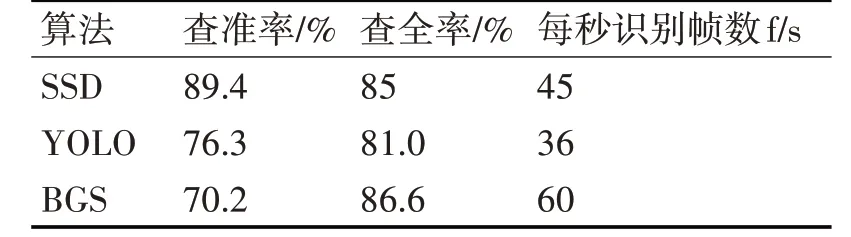
表1 实验结果对比
3.4 结果分析
表1 中,SSD、YOLO 和BGS 算法的识别帧率均满足实时性的要求。虽然3 种方法的实时性相差不大,但SSD 的查全率与查准率明显高于YOLO。其原因是SSD网络通过逐级网络衰减,能提取到比YOLO 更加有效的特征。而相比于BGS,虽然SSD的查全率略低,但其查准率明显高于BGS。这是由于BGS 是通过当前帧与背景之间的差值得到的结果,略微的变化都会被检查到。
通过实验可以发现,虽然SSD 模型检测较远处的车辆略显不足,但在近处时,其较高的查全率、查准率以及识别帧率,基本可以满足车辆监督的准确性和实时性的要求。
4 结语
本文采用SSD 检测算法实现车辆检测,取得了中高的检测准确率和检测速度,基本满足了对视频种车辆检测的要求。而本文提出对于较远处车辆,由于目标尺度过小,检测准确率还需要后期的进一步提高。
