基于K-means的选择性任务调度算法研究
2019-11-23刘燕龙陶跃陈占芳周玉轩范威振
刘燕龙,陶跃,陈占芳,周玉轩,范威振
(1.长春理工大学 计算机科学技术学院,长春 130022;2.长春理工大学 电子信息工程学院,长春 130022)
云计算是分布式计算领域中一项正在加速发展的技术,任务调度问题[1]是云计算研究中的重要阶段,云计算平台上可以接收多样化的应用和请求,不同的应用有着各自不同的任务和不同的任务特性,对资源的需求也各有不同。寻找合适的方法对用户任务进行分类,使相似任务聚合,相异任务分离,缩小任务的特性维数是非常有必要的。聚类算法[2]是任务分类的有效手段。聚类分析的目的使聚类中的任务特性彼此高度相似,不同聚类中的特性有明显的差异。聚类内部的相似性和聚类之间的差异性越大,聚类结果越好。K-means算法[3]是聚类算法中的经典分类算法,具有出色的速度和良好的可扩展性,在实践中被广泛应用。在云计算环境中,云计算是通过互联网媒介按需付费的方式来使用计算资源,所以云资源具有差异性,与用户任务相似,对云资源进行聚类划分,面向具体类别的应用任务特性有针对性的调度到类别相似的云资源上,有效提高资源调度优化的效率,将会大大提高任务的执行效率和资源的利用率。
在任务调度时,对于资源和任务的分配,既要考虑任务的完成时长,也要考虑系统资源的利用,由于调度问题是一个NP难问题,许多学者对其做出研究,提出了大量的启发式调度算法,如Min-Min算法[4]、模拟退火算法(SA)[5]、遗传算法(GA)[6]、蚁群算法(ACO)[7-8]、人工神经网络(ANN)等[9-10]。而经典的Min-Min算法和Max-Min算法是启发式算法中具有代表性的算法,算法采用贪心策略,调度算法的总完成时间短、执行效率高,并且算法思路简单,结合Min-Min算法和Max-Min算法两者优点,通过启发式算法来寻求实现资源最优分配。
通过对云计算的任务调度和资源分配问题的分析,本文提出了一种基于K-means的启发式云资源调度方法,通过K-means算法对执行任务和云资源进行分类,将任务集合分配到合适的执行资源中,避免了造成任务与资源的不匹配,从而造成的资源浪费的问题,达到提高任务执行效率的效果。同时在K-means对任务划分的基础上,采用Min-Min算法和Max-Min算法相结合的选择性调度算法,根据任务的长度和预期完成时间,选择合适的调度算法,通过对任务长度和预期执行时间的计算,合理的分配任务与资源,快速的处理任务集群,达到缩短任务集群整体执行时间的效果。
1 基于K-means的任务聚类策略
聚类方法是对任务进行划分的过程,根据相似性或唯一性标准分组。聚类算法不仅仅是用于分类,也用于任务特性简化。用n个属性变量来表示m个任务对象,如任务需求的资源为处理器、内存、存储、带宽等属性。用户任务对资源的需求可以采用任务向量距离公式表示,本文采用欧几里得距离,它表示在m维空间中两个点之间的真实距离,如式(1)所示。其中,D(i,j)表示任务i与 j的数据的相似程度;k表示m个任务对资源需求的某一特性。
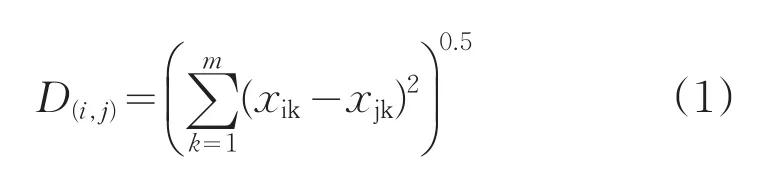
K-means算法是通过划分将m个任务对象划分为k类,首先确定所要的聚类的类簇k,k值的选定关乎着算法结果,因为任务所需求的资源属性值包括计算能力、宽带能力和存储能力,k值可以预先选定为3,用户任务聚类并不完全是是非此即彼的类别划分,聚类结果的每一个类簇都会有一部分的边缘任务数据,称为边缘域[11],边缘域一定程度的影响了聚类结果的准确率,为了提高用户任务分类的准确率,确定合适的聚类数目是重中之重。为了确定聚类数目,本文将任务分类k值在一个区域内(其中Tk值小于任务总量),对区域内的k值,进行依次的迭代聚类,对所有的聚类结果进行分析。对于这些聚类结果,计算其聚类的评估函数(Clustering Performance Index)CPI,聚类评估函数结合了聚类内部的相似性和聚类之间的差异性这两个因素,一般说来,通过类簇中数据和类簇中心的内聚程度来衡量聚类内部的相似性,用类簇之间的分离程度来衡量聚类之间的差异性。本文从内部的相似性和聚类之间的差异性出发,定义新的评估函数,并设计了新的有效性指数CPI。选择聚类评估函数CPI最小的聚类为最优聚类结果,该最优聚类结果代表了最符合任务需求资源特性的分类结果。
K-means的任务聚类策略算法流程图如图1所示。
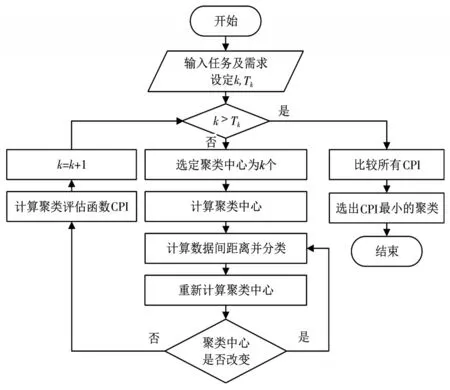
图1 K-means的任务聚类策略流程图
图1中K-means的任务聚类策略具体步骤如下所示:
输入:用户提交的n个任务的资源需求特征D={p1,p2,⋅⋅⋅,pn},其中 pi={计算需求,宽带需求,存储需求},Tk=8。
输出:任务聚类结果。
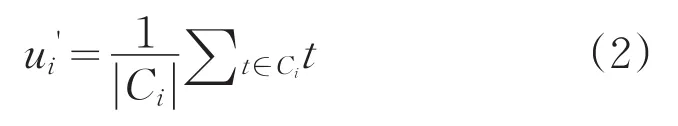
(7)如果当前聚类中心不再改变,确定所有的聚类中心:C={C1,C2,⋅⋅⋅,Ck}。
(8)计算聚类结果评估函数,根据类内紧凑性和类间分离性因素考虑,首先计算每类类内样本间的平均距离(如式(3)所示)和不同的类的类间距离(如式(4)所示)。

计算聚类评估函数,如式(5)所示:
(2)将任务按长度进行排序,令排序的任务以k倍划分,选择每组中位数为聚类中心,共k个聚类中心:C={u1,u2,⋅⋅⋅,uk}。
(3)对于其他任务,根据欧式距离,计算所用的任务数据与类簇中心的距离。
(4)根据欧氏距离,选择与聚类中心距离最小的类簇,将tj分到相应的类簇中。
(5)根据式(2),重新计算每个类簇的中心点,确定新的聚类中心。

(9)根据 k=3,4,⋅⋅⋅,Tk,重复步骤(1)-(8),计算所有的聚类,比较每一个聚类评估函数CPI,CPI值越小说明得到的聚类效果越好,确定聚类的中心值k和任务聚类结果。
2 云计算资源的聚类
云计算中的资源是使用虚拟化将计算资源(如网络、服务器、存储、应用和服务等)进行封装共享,不同的资源提供的性能不同。
资源模型表示为式(6)所示:
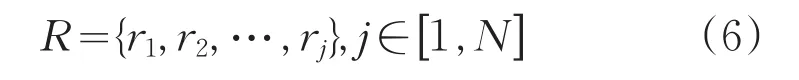
式中,rj表示第 j个资源节点;资源节点数为N。
资源节点 j的资源特性可以用一维向量表示:rj={rid,rcpu,rmips,rbw,rstor},其中,rid为资源编号,rcpu为资源的CPU数目,rmips表示每秒执行的百万条指令数目,rbw、rstor代表资源的通信能力、存储能力[12]。其中,资源的计算能力可以通过rcpu和rmips的乘积表示。该乘积越大代表该资源的计算能力越强。
任务调度结果同时受资源计算、带宽和内存的影响,因此将资源以计算型资源、带宽型资源和存储型资源为基础属性进行K-means分类,与第二节中任务聚类的原理一样,在聚类开始,将聚类数目k值设定在一个区域内(其中Tk值小于任务总量),对区域内的k值,进行依次的迭代聚类,对所有的聚类结果进行分析。然后对于这些聚类结果,计算其聚类评估函数CPI,选择聚类评估函数CPI最小的聚类结果为资源的最优分类。
3 资源与任务的映射匹配
通过前两节对任务和资源的聚类划分后,得到相应的分类的类簇,同一类簇中的任务对资源的需求具有相似性,通过将聚类结果进行权值化,进行调度时偏向选取与任务权值相近的资源,将资源与用户任务之间形成相应的映射关系,通过映射匹配将任务集分配到合适的执行资源类中,对任务进行合理调度,达到提高任务调度的执行效率的效果。
(1)通过计算(c)、内存(r)、宽带(b)三种属性对任务和资源分别建立对比矩阵,这里以资源为例,如式(7)所示。其中vmij表示要素i相对于要素 j的重要程度。
(2)进行对比矩阵的一致性检验,如式(8)所示。
(3)如果矩阵的一致性满足要求,则可以根据矩阵的最大特征值进一步计算得到对应的特征向量,并通过对特征向量进行标准化将其转化为权向量[13]。如式(9)和式(10)所示,其中的各分量反映了各要素的影响权重。
(4)通过对比矩阵求出权向量,利用如下式(11)和式(12)计算任务集需求度和资源综合能力:
(5)按式(13),通过任务集需求度和资源综合能力之间的最短距离da,对任务和资源进行映射匹配,将任务集分配到合适的执行资源中。
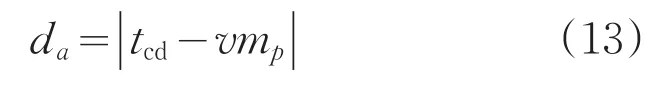
4 任务调度阶段
经过K-means算法对任务和资源的分类,使任务和资源形成映射关系,再将任务分配到合适的资源之后,对于同一资源中的任务,采用选择性启发调度算法,启发式(heuristic)任务调度算法是解决云计算任务调度中简单有效的方法,其中的Min-Min算法和Max-Min算法[14]是经典的调度算法,开销小,且执行速度快。选择性调度算法是采用Min-Min算法和Max-Min算法相结合的算法,根据任务的长度和预期完成时间合理选择与任务集群最相配的调度算法。
基于对缩短整体任务的执行时间的考虑,根据任务长度和预期完成时间,选择合适的调度算法对任务进行处理。选定参数α值,当长任务的数量要小于短任务的数量的α倍,则采用Max-Min算法,否则,采用Min-Min算法。本章用相互映射匹配的一对类簇中的任务和资源进行选择性调度,选择性任务调度过程图如图2所示。
图2中选择性任务调度的流程如下所示:
输入:同一资源中相互映射匹配的任务和资源集合。
输出:任务调度的结果。
步骤1:当资源都处于负载为零时,对于任务集t中的每一个任务ti,计算任务ti在资源vmj上的执行时间ETC(ti,vmj)。
步骤2:对于任务集t中的每一个任务ti,计算ti在资源vmj上的执行完成时间MCT(ti,vmj)(已知:rj是资源vmj准备就绪去处理任务ti的准备时间),如式(14)所示。
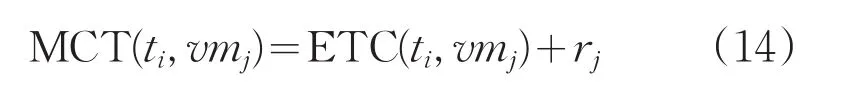
步骤3:通过MCT对任务进行排序,并计算任务集群的标准偏差sdij,如式(15)所示。
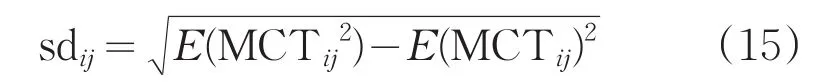
式中,E(MCTij)表示MCTij的平均值;T表示任务ti在资源vmj上运行的最大时间。
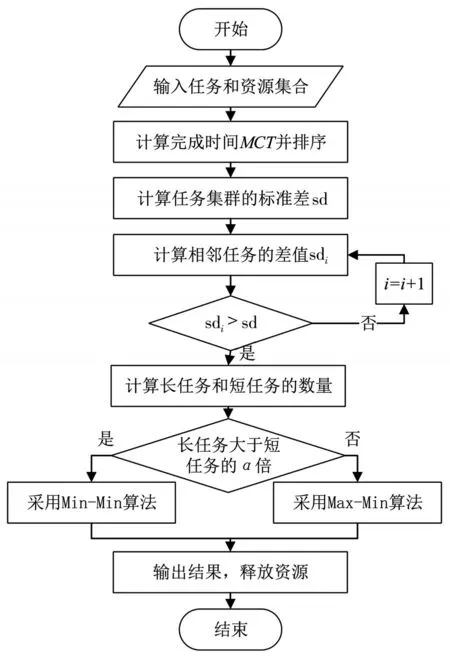
图2 选择性任务调度流程图
步骤4:在己经排好序的任务序列中找到两个连续值的差值大sd的位置,即任务长度变化明显的位置,用于区分长任务和短任务。
步骤5:设定参数α值,当长任务的数量要大于短任务的数量的α倍,选择Min-Min调度算法,优先处理任务长度小、预期完成时间短的任务,否则,选择Max-Min调度算法,优先处理任务长度大、预期完成时间长的任务。
步骤6:每分配一个任务,更新任务集合的期望完成时间,如此重复步骤1-5,分配所用的任务集合。
步骤7:通过评价指标评估分配策略,以任务的最后完成时间和系统资源利用率为标准。
其中时间指标函数为式(16):
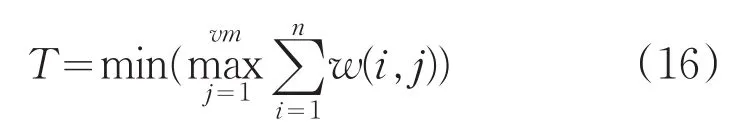
式中,vm为云资源集合总量;n为资源j上总分配的任务总数;w(i,j)表示第i个任务在第j个资源上的执行时间。
资源利用率评估指标为式(17):
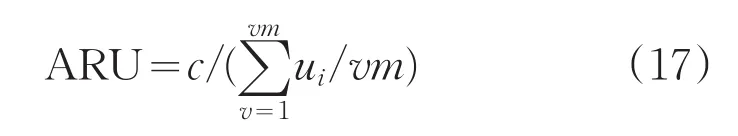
式中,vm为资源总数;ui表示第i个资源的综合利用率。
5 结果分析
CloudSim[15]是由澳大利亚墨尔本大学网格实验室和Gridbus项目推出的用于云计算仿真的软件[16],支持大型云计算基础设施的建模与仿真。CloudSim可以提供模拟的数据中心,通过对资源、任务、调度机制、资源分配进行仿真实现,通过网络资源的建立,可以实现对云计算资源控制及任务调度的有效实验和改进。为验证本文提出的算法的有效性,通过扩展CloudSim仿真平台,自定义DatacenterBroker类中的方法实现任务调度算法,通过重新编译、打包实现了算法仿真。
5.1 实验参数配置
(1)实验环境配置:
硬件环境:第7代英特尔®酷睿™ i7处理器,16 GB DDR4-2666 SDRAM(2×8GB)内存,传输速率2 400 MT/秒。
软件环境:IntelliJ IDEA 2017开发环境,Apache Ant 1.7,CloudSim4.0,JDK1.8.0。
(2)数据中心配置参数:
任务参数:任务长度(单位:MIP)的设置[500,3 000],期望宽带(单位:MB/s)的设置[1 000,2 000],期望存储(单位:MB)的设置[512,2 048],期望计算能力(单位:MIPS)的设置[500,3 000]。
资源参数:CPU的设置[1,4],宽带(单位:MB/s)的设置[1 000,3 000],存储(单位:MB)的设置[1 024,4 096],计算能力(单位:MIPS)的设置[500,2 000]。
5.2 仿真过程
任务调度在CloudSim仿真系统中的一般流程如下:
(1)通过init方法,初始化CloudSim库。
(2)通过createDatacenter方法,创建数据中心,其中dataName是数据中心的命名。
(3)通过createBroker方法,创建数据中心代理broker。
(4)通过定义VM对象,创建虚拟机列表;通过submitVmList方法,将虚拟机注册到代理broker上。
(5)通过定义Cloudlet对象,创建任务列表;通过submitCloudletList方法,将任务注册到broker上。
(6)通过自定义bindCloudletsToVmsKCMM方法,进行任务调度算法的实现。
(7)通过startSimulation方法,启动仿真。
5.3 实验结果分析
(1)在实验中,为了有效的验证算法,首先需要确定参数α的最优值。在实验仿真中选取在不同α下完成时间波动比较大的任务数量进行试验,因此,设置任务数量为n={900,1 200,1 800,2 400},通过改进的调度算法,对不同的α值,计算任务的平均完成时间,依据实验数据对比,确定最优的α值,不同α值下调度算法的完成时间如表1所示。
由表1不同α值下调度策略的完成时间可以看出,当α=0.8时,任务的综合平均完成时间最小,在α小于0.8时,长任务和短任务的划分界限偏小,在选择性调度时,偏向于选择Max-Min算法,优先处理长任务,使得短任务处于长时间的等待,增加了任务的最终完成时间;当α大于0.8时,长任务和短任务的划分界限偏大,在选择性调度时,偏向于选择Min-Min算法,优先处理短任务,造成少量的长任务占用大量的执行时间,使得选择性调度失去意义。因此,将选择界限参数α的值定为0.8。
(2)通过确定参数α=0.8的最优解,为了验证算法的有效性,算法对任务数量在n={300,600,900,1 200,1 500,1 800,2 100,2 400,2 700}的范围中的数据进行实验,通过进行100次迭代实验,对实验结果进行比较验证。并对Min-Min算法(Min-Min)、基于K-means对任务和资源进行分类映射的Min-Min算法(K-MM)和本文提出的基于K-means的启发式选择调度算法(K-C-MM)通过任务的最后完成时间和资源的利用率进行比较,如图3算法任务完成时间对比图,图4算法资源利用率对比图所示。
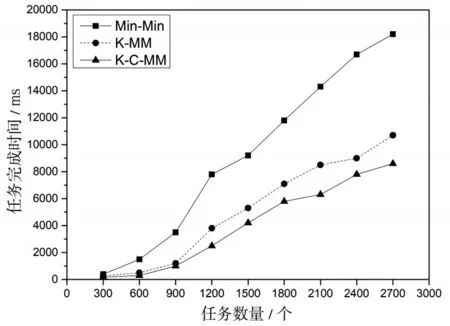
图3 三种算法任务完成时间对比图
由图3任务完成时间对比可以看出,在云任务数较小的情况下,三种算法的执行效率均较高,完成时间较快,且差异不明显。随着任务数量的增加,K-C-MM算法和K-MM算法的完成时间明显低于Min-Min算法,相对于Min-Min算法,K-C-MM算法在完成时间上缩短了50%以上,K-MM算法在完成时间上缩短了接近40%,由此可以看出通过K-means的任务和资源的分类与映射匹配,将任务调度到合适的资源上运行,提高了任务的执行效率,大幅度降低了任务的完成时间。而相对于K-MM算法,K-C-MM算法在完成时间上更具有一定的优势,降低了20%的平均完成时间,因此采用Min-Min算法和Max-Min算法相结合的选择调度算法,合理分配长任务和短任务的执行顺序,在任务执行效率方面具有一定优势。
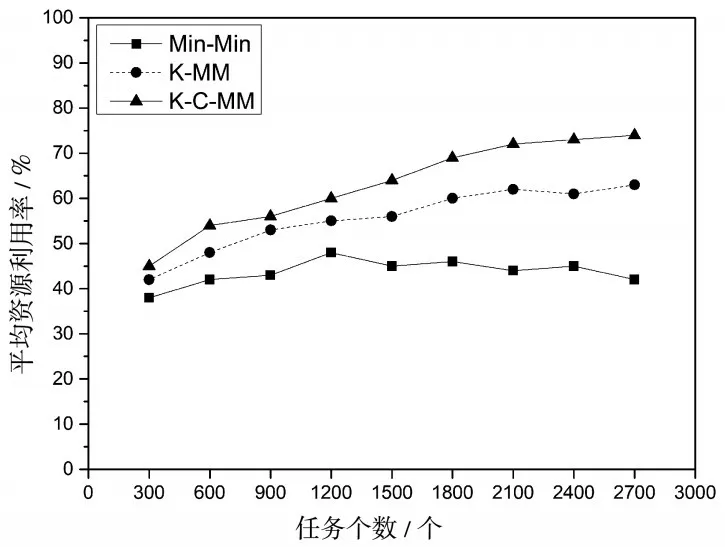
图4 三种算法资源利用率对比图
由图4资源利用率对比可以看出,Min-Min算法的系统资源利用率的平均值只有44%,而随着任务数量的增加,资源的利用率呈现下降趋势;对于K-MM算法随着任务数量的增加,资源利用率可以达到60%以上,因为K-MM是通过K-means算法对任务调度的改进,将任务和资源相互匹配,使得物尽其用,极大的提高了资源的利用率;但是由于Min-Min算法的负载不均衡问题,资源利用率在一定程度上还可以提高,所以本文采用选择性调度算法K-C-MM,使得资源的利用率达到70%以上,比Min-Min算法的资源利用率提高了60%,比K-MM算法的资源利用率提高了20%左右。
综合以上分析可知,在云计算环境中,基于K-means的选择调度算法不仅提高了任务的执行效率,降低了任务的最后完成时间,同时保证了较高的系统资源利用率。
6 结论
本文针对云环境下的任务调度进行了研究,提出了一种基于K-means的启发式选择调度算法,该算法首先通过K-means算法对任务和资源进行聚类划分,依照任务与资源的匹配映射关系,使任务集群分发到相应的资源上,避免了造成任务与资源的不匹配和资源的浪费,然后本文采用选择性调度算法,选择调度算法是采用Min-Min算法和Max-Min算法相结合的算法,通过对任务长度和预期执行时间的计算,合理的分配任务与资源,缩短任务的执行时间。实验结果表明,本文算法能够降低资源选择的开销,提高系统资源的利用率,缩短任务的执行时间。与其他方法相比,具有较好的执行效率,较强的应用前景。
