一种半监督多流形识别算法
2019-11-21高小方贾丽娜
高小方,贾丽娜
(山西大学 计算机与信息技术学院,山西 太原 030006)
0 引言
流形学习是机器学习与数据挖掘领域重要的研究课题,目的是找到高维空间中的低维映射,实现维数约简或者数据可视化。经典的流形学习算法都是假设高维数据存在于单一的流形结构上,例如ISOMAP[1]、LLE[2]、LE[3]、HLLE[4]以及LTSA[5]等,但是实际生活中的数据大部分存在于多流形上,比如人脸图像数据中,每个人脸存在于一个特定流形上;再比如手写体数据中,每个数字也存在于一个特定流形上。这些多流形数据中各子流形可能独立,也可能相交或重叠。
目前,对多流形数据结构的研究并不是很多。K-Manifolds[6]是最早研究多流形数据结构的算法,但是它只能分解相交的多流形数据结构;而DC-Isomap[7]正好相反,只能解决不相交多流形数据结构的分解;SMMC[8]是基于谱聚类的方法,它虽然能够很好地分解多流形数据结构,但其本身是一种谱聚类方法,没有充分考虑到流形自身的拓扑结构。这些多流形方法都是基于无监督学习的方法,没有充分利用宝贵的数据标签信息来指导分类器的训练。之后提出的监督学习方法,或者利用标签信息定义了一个新的距离度量标准来增加原始数据集中不同子流形间数据点的距离(SLLE[9]、S-Isomap[10]等),或者通过标签信息设置约束条件使多流形的目标函数最优化(M-Isomap[11]、MMD-Isomap[12]等)。这些方法虽然高效,但是标签数据的获取需要耗费大量的人力和成本。因此,将半监督学习的思想应用于多流形学习的方法在近几年得到人们越来越广泛的关注。
近几年,基于半监督流形学习的研究主要体现在三个方面,一是利用数据集中包含的标签信息构建新的半监督流形框架来实现多流形学习,如Wang等人提出的DAMR框架[13]先用无监督的思想对原始数据集做分类学习,然后再利用数据集中包含的标签信息优化分类器,实现多流形的识别。Sun等人则基于半监督认知模型和拉普拉斯矩阵设计了新的流形框架[14],解决了多流形数据维数约简过程中的流形密度不相同等问题;二是利用数据集中包含的标签信息设置一些约束条件来实现多流形学习,如Goldberg等人提出的MMSSL算法[15]和Xing等人提出的M2SGMM算法[16]都是先利用数据点构造图,然后通过带有相关约束条件的谱聚类方法实现多流形数据的聚类,Chang等人[17]则基于must-link和cannot-link约束条件有效地获得潜藏的多流形聚类结构,提高了多流形的识别精度;三是通过运用流形正则化的方法实现多流形学习,如Belkin等人[18]提出利用样本的空间分布信息给有监督模型加流形正则项,尽可能多的利用无监督数据,使得模型转化为半监督模型,Li等人提出的SCE算法[19]是一种用于多流形数据划分的结构化集成算法,主要是通过构造带有正则化后的目标函数来获取簇间的结构信息实现的,以及Luo等人提出的MRDA算法[20]通过采用流形正则化方法将源数据流形和目标数据流形约束在子空间中,提高了流形数据学习标签的性能。
在Goldberg等人提出的MMSSL方法中存在两点不足:一是MMSSL方法通过贪心算法从未标记数据集中选择出了一个子集,并规定这个子集中每个数据点的欧式邻域中的所有近邻点位于同一个子流形,但是在流形相交区域的数据不完全来源于相同的流形却有可能被划分到同一个邻域中,这样会给最终分类结果带来误差。本文利用MPPCA模型[21]将多流形数据集划分成m个“局部数据块”,再利用已有的标签信息进一步分解这些数据块,使每一个数据块中标签信息一致,这样可以尽可能地使相交部分的多流形结构分解开来;二是MMSSL方法用Hellinger距离的大小来判断两个数据点是否位于同一个子流形,这种方法对数据点的数量有一定的要求,如果较少,Hellinger距离就会相对较大,对实验结果会产生影响。本文利用数据点间的几何相似性来判断两个数据点是否位于同一个子流形,避免了因Hellinger距离对数据数量的特殊要求而对实验结果产生的不良影响。
1 相关工作
1.1 MMSSL算法
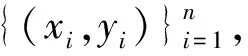
(1)
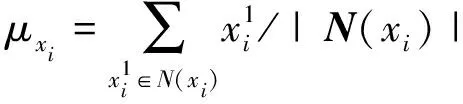

(2)
其中D为原始数据的高维维度。最后在图G上运行谱聚类算法将节点聚为K类,即将原始的多流形数据分解成为K个子流形。
1.2 MPPCA模型
在M2SMPPCA算法中,首先要通过混合概率主成分分析(MPPCA)模型将多流形数据分解成“局部数据块”,MPPCA模型由Tipping等人在1999年提出。
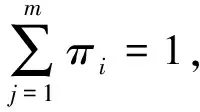
(3)
其中,I是d维的单位矩阵,μj是均值向量,Aj是一个d×kj的矩阵,Ynj是一个独立的具有kj维的隐藏向量,σj2是噪声方差。显而易见,这个MPPCA模型是由具有混合比例πj的m个PPCA子模型混合而成。在MPPCA模型中,令:
(4)
观测数据X的对数似然函数为:
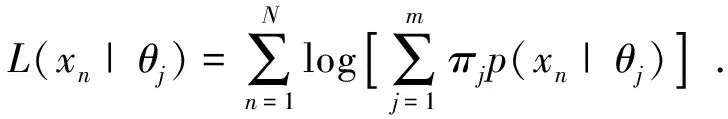
(5)
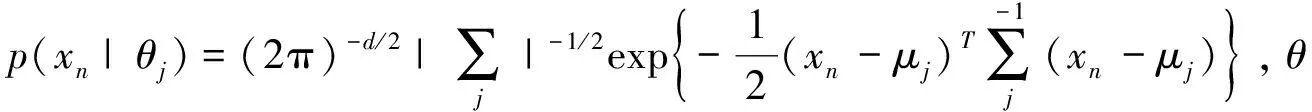
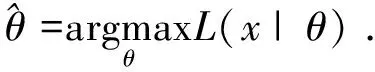
(6)
如果模型参数θ的概率p(θ)是可取的,则把(6)写为:
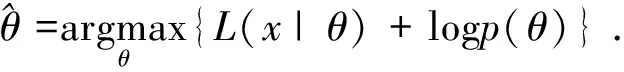
(7)
给出MPPCA模型的局部数据块个数m和子空间维度K=(k1,k2,…,km),模型参数θ可由EM算法得到,E步骤得到对数似然函数的期望值,M步骤使得θ最大化。
2 多流形半监督算法M2SMPPCA
在流形学习中,通常采用奇异值分解(SVD)的方法计算数据点的切空间,但是在多流形的相交区域,因为不同子流形上的点相互重叠,它们的近邻点相似,因此并不能直接通过切空间的计算分解开两个不同的子流形。而MPPCA算法本身具有“穿过”不同线性区域的能力,所以在M2SMPPCA算法中先通过MPPCA模型分解“局部数据块”,再依据标签信息提高局部数据块的“纯度”;然后,利用数据点的切空间偏差计算点对的局部几何相似性,并构造相应的局部几何相似图,接着运行谱聚类算法将其划分成K个聚类结果;最后,利用基于共协矩阵的集成算法[22]提高M2SMPPCA算法的鲁棒性。具体算法描述见算法1(M2SMPPCA算法)。
2.1 构造数据点邻域
在M2SMPPCA算法中采用K-NN算法或动态邻域算法[23]来构造数据点xi的邻域。K-NN算法比较简单,但是其全局参数可能不适用于整个的数据流形结构。如果采用动态邻域算法,充分考虑采样密度和流形曲率,会进一步提高实验结果的精度。
2.2 分解“局部数据块”
流形学习的基本原理就是“局部线性”,可以通过局部邻域近似成一个“线性流形”。虽然相交部分的不同子流形上的点构造的局部邻域或者切空间具有相似性,但不能分辨这些不同的子流形,而MPPCA算法能够成功地“穿”过不同的“线性流形”。因此本文通过MPPCA算法将原始数据集分解成了m个小的“局部数据块”,并将每个“局部数据块”中包含的数据点信息保存在变量P中。为了进一步提高“局部数据块”的“纯度”,本文遍历P中的所有数据块,利用原始数据集中包含的标签信息Xl={(x1,c1),(x2,c2),…,(xm,cm)}将“局部数据块”进一步分解,使每个数据块中的标签信息一致,得到最终的M个“局部数据块”。

算法1 M2SMPPCA算法
2.3 构建局部几何相似图
设原始数据集为X={xi∈RD,i=1,…,N},本文定义数据点xi和xj之间的几何相似性由切空间偏差来表示,即:
(8)
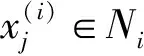
xboun={xj|xi∈Mi,xj∈N(xi),xj∉Mi} .
(9)
定义一个稀疏的加权图G=(V,E),其中V={xi∈X,i=1,2,…,N}表示图G的节点集合;E={eij}表示图G中节点(xi,xj)之间的边的集合。边的权重矩阵W是一个N×N的实对称矩阵,wij=wji,用来衡量图G中节点之间的几何相似性,即节点(xi,xj)之间的几何特性越相似,wij=wji的值越大。其构造方式为:
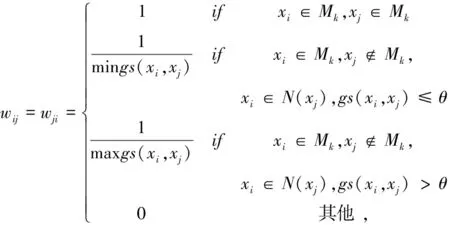
(10)
其中Mk为第K个“局部数据块”,gs(xi,xj)中xi为数据块Mk的边界点而xj为xi的近邻点(见公式8)。当gs(xi,xj)小于或等于切空间偏差阈值θ时,则认为数据点xi和xj之间具有相似的几何特性,反之,数据点xi和xj之间具有不同的几何特性。具体算法描述见算法2(Construct graph算法)。
2.4 聚类子流形

算法2 Construct graph算法
2.5 生成最终子流形
因为MPPCA的算法每次生成的“局部数据块”不稳定,导致整个算法的结果也不稳定。为了提高算法整体的鲁棒性,M2SMPPCA算法构造了H个子流形的基结果,设为Π={π1,π2,…,πH},其中πi={sXi1,sXi2,…,sXis}表示第i次构造的子流形结果,通过共协矩阵集成这H个子流形结果,生成最终的子流形分解结构{sX1,sX2,…,sXs}.
2.6 算法时间复杂度分析
设原始数据集中含有N个样本点,其维度为D,计算本文提出M2SMPPCA方法的时间复杂度需要分为以下五步:第一步,通过半监督MPPCA模型将原始数据集分解成M个局部数据块,其中需要E-M算法初始化该模型参数以及遍历由MPPCA初始分解的m个数据块,其时间复杂度为O(NDm(t1+dt2)),其中t1,t2分别是遍历数据块与E-M算法收敛前所需的时间,d为原始样本数据集映射到低维空间的维度;第二步,需要计算出每个数据点的近邻,其时间复杂度为O(Nlog(N));第三步,计算两个局部数据块的边界点的几何相似性,其时间复杂度为O(N2Dd2);第四步,先利用数据集中的数据点构造图G,再利用谱聚类算法将图G分解成K个聚类,其时间复杂度为O(N3);第五步,将得到的H个子流形分解结构作为输入利用基于共协矩阵的集成算法,得到最终的子流形分解结构,其时间复杂度为O(N2H)。综上所述M2SMPPCA算法整体的时间复杂度为O(NDm(t1+dt2)+Nlog(N)+N2Dd2+N3+N2H),由于d≪D,m≪N,H通常是一个常数,t1、t2的迭代次数往往也很小,故算法复杂度主要受N,D影响。
3 实验结果及分析
本节进行了四组实验:第一组实验比较了本文提出的M2SMPPCA算法与Isomap[1]、K-Manifolds[6]、MMSSL[15]、Spectral Clustering[25]四个算法识别合成数据的可视化结果;第二组和第三组实验分别比较了M2SMPPCA算法与Isomap、K-Manifolds、Spectral Clustering、MMSSL算法在合成数据和实际数据上的精度与时间;第四组实验分析了两个可变参数m、θ对M2SMPPCA算法精度的影响。
3.1 合成数据上的实验
图1显示了M2SMPPCA算法与Isomap、K-manifolds、Spectral Clustering、MMSSL四个算法在$、Three linear planes、Two spirals数据集上的多流形识别结果。$数据是由一个S Curve曲面流形随机选取1 000个样本点和一个平面流形随机选取500个样本点相交而成的相交多流形数据集;Three-Linear-Planes数据是由三个两两相交的平面流形各随机选取400个样本而形成的相交多流形数据集;Two-Spirals数据是由两个相互交叉的二维螺旋流形,并各自从中随机选取500个样本形成的相交多流形数据集。

Fig.1 Decomposition results comparison of Isomap、K-manifolds, Spectral Clustering, MMSSL,and M2SMPPCA algorithms on $data, Three_Linear_Planes, and Two_Spirals intersection manifold data,respectively图1 Isomap、K-manifolds、Spectral Clustering、MMSSL和M2SMPPCA算法分别对$data、Three_Linear_Planes和Two_Spirals相交多流形数据的分解结果比较
实验结果表明:(1)本文所提出的M2SMPPCA算法相比其他算法可以更准确地识别和分解相交的多流形数据;(2)Isomap和K-manifolds算法都是通过计算点对之间的测地距离对多流形数据聚类,在相交区域会产生误差;(3)K-manifolds算法与Spectral Clustering算法虽然一定程度上考虑了数据本身的流形结构,但依旧没有脱离聚类的思想,不仅需要设定分类参数,而且无法很好的分解相交流形;(4)MMSSL算法由于先使用欧氏邻域划分原始数据集以及使用Hellinger距离的大小来判断数据是否位于相同的流形结构上,造成在流形相交部分也有较大误差。
3.2 合成数据上实验的精度与时间比较
表1展示了本文提出的M2SMPPCA算法与以上四种算法在上述三个数据集上识别多流形数据的精度和运行时间。每种算法分别在相应数据集上运行10次,其平均结果作为分解精度和运行时间,在“±”号后跟随的是标准差。
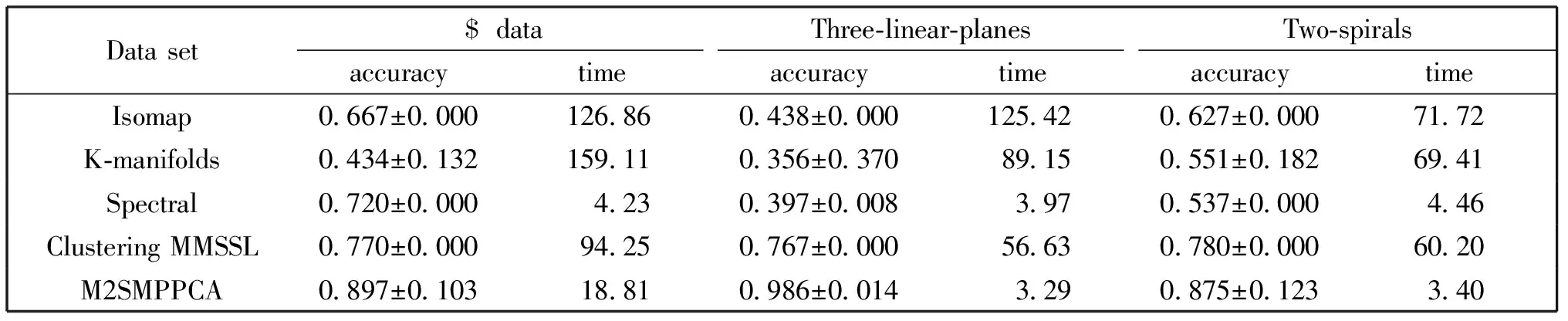
表1 比较图2中三组相交多流形数据的分解精度(均值±标准差)和平均运算时间(秒)
实验结果表明:(1)M2SMPPCA算法的精度明显优于其他算法,时间上仅次于Spectral Clustering;(2)Isomap算法时间复杂度较高且分类精度较差;(3)K-manifolds算法利用EM算法迭代计算数据点的分类概率,运行时间较长,分类精度并不高;(4)Spectral Clustering算法虽然运行速度快,但是分解精度也不高;(5)MMSSL算法需要使用贪婪算法获得未标记数据集的子集,需要EM算法优化参数,因此运行时间也相对较长,分类精度并不够理想。
3.3 实际数据的精度和时间比较
表2显示了M2SMPPCA算法与Isomap、K-manifolds、Spectral Clustering、MMSSL算法在实际人脸数据集UMist-Cropped与图像集COIL-Cropped上的分解精度及运行时间。UMist-Cropped与COIL-Cropped分别是从人脸集UMist与图像集COIL-20上剪裁来的,由于实验环境的限制,从UMist中选出8组不同人脸照片共241张,每张图片像素为112×92,另外从COIL-20数据集上选取五个不同物品的图片,每个物品有72张图片共360张,每张图片的像素为64×64。如图2所示。
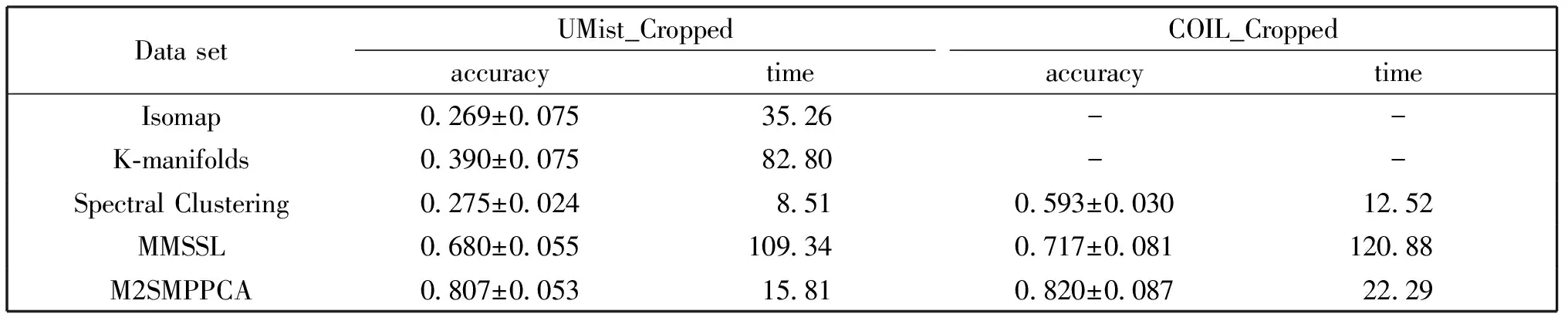
表2 在实际人脸数据集UMist-Cropped与图像集COIL-Cropped上分别比较几种算法分解相交多流形数据的分解精度(均值±标准差)和平均运算时间(秒)

Fig.2 UMist set typical image of the concentrated face and COIL-20 images of the concentrated image图2 UMist人脸集中的典型图像与COIL-20图像集中的物品图像
在两个数据集上运行M2SMPPCA过程中,随机抽取15%的数据点作为具有标签信息的数据子集,85%的数据点为未标记的数据子集。分别运行20次,计算运行的平均精度和平均时间复杂度。
实验结果表明:(1)Isomap和K-manifolds算法不能应用于分离较远的多流形数据结构,即使邻域参数设置较大也不能构建全局的测地距离矩阵;(2)Spectral Clustering算法对高维数据的分类结果并不理想;(3)MMSSL算法结果虽然优于其他三种算法,但是比本文提出的M2SMPPCA算法要差。因此,本实验进一步验证了M2SMPPCA算法的有效性。
3.4 参数对M2SMPPCA算法精度的影响
能对本文提出的M2SMPPCA算法分解相交多流形数据结构的精度产生影响的主要有2个可变参数,即MPPCA算法分解的数据块个数m和切空间偏差阈值θ。图3中的数据来自在$数据集上运行M2SMPPCA算法,每次只令其中一个参数发生变化,每种情况均运行多次,然后得到在该种情况下的平均分解精度的变化情况。
结果显示:(1)M2SMPPCA算法的精度随数据块个数m的增大逐渐增大,在达到一个较优值(m=80)时,精度变化幅度不大。因为m值影响到算法的时间复杂度,因此通常m值取该较优值(见图3a);(2)M2SMPPCA算法的精度会随切空间偏差阈值θ的增大逐渐增大,但是超过一个峰值后,由于阈值过大导致子流形不能分解,反而导致算法精度下降(见图3b)。

Fig.3 Influence of each parameter on the decomposition accuracy of$data intersecting manifold in M2SMPPCA algorithm图3 M2SMPPCA算法中各个参数对$数据相交多流形的分解精度的影响
4 结论
本文提出的半监督多流形识别算法M2SMPPCA是基于对MMSSL算法的改进,用于分解相交或是重叠的多流形数据。首先用半监督MPPCA算法将原始数据集划分为“局部数据块”,确保每个数据块中数据的标签一致;然后利用数据点间的局部几何特性构造相似图并用谱聚类算法对其进行聚类,构造子流形;最后,因为MPPCA的算法每次生成的“局部数据块”不稳定,用基于共协矩阵的集成思想提高了算法整体的鲁棒性。实验结果表明了M2SMPPCA算法的高效性。
