多维数据分析处理技术
2019-11-15蓝善根
文/蓝善根
1 绪论
1.1 研究背景和意义
近年来大数据飞速发展,数据的采集技术趋于成熟,海量的数据为科技生活提供了便利,但同时数据量的庞大与繁杂为数据的计算处理与分析带来了极大的困难,在实际生产以及生活当中,需要投入更多的研究来加强多维数据的分析与处理,使人们生产数据、处理数据、分析数据,改变科技生活,受惠于科技发展和大数据相关技术。
在数据处理当中,大部分只能分析具有某特征值的数据,当数据变成多维数据,混合属性的时候,技术上很难分析和处理,如何高效聚类数据成为了研究的热点。
1.2 研究现状
目前对于大数据当中的数据采集技术已经有了飞速的发展和突破。数据分析方法也多种多样,但是目前仍然存在很多问题:业务数据的采集、存储结构多样,形势混乱,数量庞杂并且存在随意乱填现象无效数据较多;数据分析技术不够普及,大多数信息服务行业人员对数据的处理技术不甚了解;数据庞杂的情况下,数据分析处理的速度有限;多维数据的分析以及展示不够智能等。
关于多维数据分析处理技术,目前有部分专家发布了较为优秀的研究成果,如文献[1-5]提出的各种算法以及开发出的比较先进的软件系统。
1.3 本文主要内容
企业或者机构日常经营积累的额海量数据以及随着大数据的普及,信息科技的共享展示,通过特定的手段获取有效的信息并利用算法等科学技术挖掘数据隐含价值,指导人们在生产经营中的分析以及决策。本文主要针对多维数据分析处理技术进行了介绍以及算法仿真实验,验证了多维数据分析计算算法的可行性以及对计算性能的提高。
2 多维数据分析处理技术
2.1 多维数据高效聚类原理
获取大量的多维数据信息后,采用交叉信息链模型来进行计算,计算结果可以获取数据集合的离散样本,将该样本利用粒子群聚方法进行动态分配得到多维数据的信息素浓度,完成聚类,该过程详细求解如下:
将海量的多维离散数据存储在系统中,设数据为:
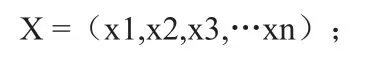
采用交叉信息链模型获取数据集合中的N个样本并将其切割得到聚类样本Xi(i=1,2,3,…n),矢量表示方式为:
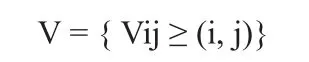
以上i取值范围为i=1,2,3,…C,表示第i个聚类中心,Vi含义为数据结构中心的第i个矢量聚类中心,C为常数; j的取值范围为j=1,2,3…s,表示迭代次数,s含义为带宽频间时间。多维离散数据Vmi的聚类划分矩阵如下所示:

以上i取值范围为i=1,2,3,…C,表示第i个聚类中心,k=1,2,3…n,表示n个样本。在多维离散数据的基础上实现模糊C均值聚类算法,采用群聚类算法对样本进行动态分配来获取信息素弄不,则表达式如下:

以上公式中,m代表权重,(dik)2含义为xk与Vi多维离散数据结构中心矢量,C代表计算机系统的惯性权值,代表聚类中心的非劣解,(U,V)表示非劣解的距离,采用欧式距离表达方式如下:

根据以上公式得到聚类中心最优解如下:

结合约束条件,采用李雅普诺夫极限定理,得到聚类的中心极值为:

求解以上公式获取聚类中心,利用以下公式进行数据聚类:
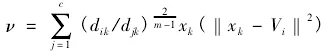
以上就是多维离散数据的高效聚类原理,通过该过程完成数据的聚类。
2.2 多维离散数据高效聚类方法
在2.1的基础原理上,利用离散性时间序列分析方法构建目标函数,得到最优聚类中心,采用优化算法对最优聚类中心进行优化,就是本文要实现的高效聚类方法。
首先,构建多维离散数据信息流模型,提取其时延尺度特征值,以此构建多维离散数据目标函数,求解该函数得到最优聚类中心,操作过程如下所示:
构造多维离散数据变量时间序列{Xn},样本长度取值为n,设样本数据流分类特征属性为X、Y,最小嵌入为数为m,最优延迟为τ,当数据特征的平均速度得到满足时,信息流模型为:
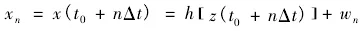
以上公式中,n为样本长度,t0为聚类中心检索,△t为单位时间变化,h为数据时间序列中每个样本独立的相似性特征量,为时延尺度。根据计算多维离散数据关联度来表示数据离散性时间序列的特征,并进行空间重构,得到时间序列分布轨迹如下:

表1:不同聚类方法用时对比
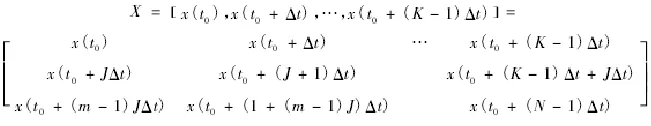
以上x(t)为采集样本的时间,J为多维离散数据相关系数,△t表示抽样时间间隔,m表示嵌入维数,可以用K=N-(m-1)*J来表达时间序列分类的最大属性,得到向量模型以及特征空间数据矢量如下所示:
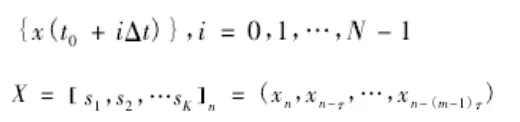
以上公式构造了海量数据流提取特征值属性,根据以上成果构建目标函数,数据的分布模型如下所示:

以上公式中,a0为数据采样初始值,xn-1代表数值相同的时间序列,bi为最佳分类属性,设多维离散数据时间标函数为x(t)(t=0,1,2…n-1),采用2.1提到的模糊均值聚类算法搜索有限的数据集向量如下:
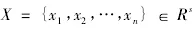
将数据集向量按照属性分类,得到n个数据样本数量,用xi(i=1,2,3…n)表示多维离散数据信息增益矢量如下:

在以上多维离散数据信息增益矢量的数据集中选K个实例,则其目标函数最优聚类中心得以求解,用公式表示为:

得到多维离散数据的最优聚类中心以后,其次要利用优化算法对最优聚类结果进行优化从而实现高效聚类。具体优化过程如下所示:
第一步,用α和β编码每个聚类中心,要求α和β满足 |α|2+|β|2=1,观测并生成二进制的普通种群,假设量子种群为 pop,数据集类别为 K,数据维数为 D,每一个维数用b位二进制来表示,则每一个量子染色体的长度 L= K×D×b。则种群 Q(t) = {qt1,qt2,…,qtpop}中第 i 个个体的编码形式为:
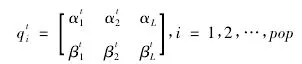
代入t=0来对量子集合进行初始化并观测结果,获取普通的种群如下:
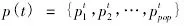
估计普通种群p(t)并计算出每个个体的适应度,提取适应度最大的个体:
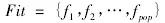
修正Q(t)形成新生集合:

利用以上公式扰动抑制聚类中心从而实现对多维离散数据的优化:
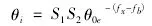
2.3 仿真实验以及结果分析
2.1以及2.2介绍了该算法的原理以及计算方法,本小节将对其进行仿真实验,文献[6]以及文献[7]分别介绍了另外两种不同的处理方法,下面我们将仿真实验结果与另外两种算法实验结果进行对比。对比结果中,Q值的结果如下图1所示。
图1为文献[6]的聚类方法结果与本文提到的聚类方法对比,不端的加大聚类参数个数,Q值随之不同幅度增大,通过图1中对比可知,本文方法在效率和性能方面优于之前的算法。
单一的对比具有局限性,为了更好的对比不同的算法,本文又采取了让文献[7]的方法进行计算,将本文、文献[6]、文献[7]的三种方法计算时间的结果进行对比,对比结果如表1所示。
由表1结果对比可知,随着需要计算的数据点个数不断加大,计算时间不同的同时,计算时间变化有不同程度的增幅。本文提到的算法明显优于其他两种早期提出的算法,有效的提高了计算效率。
3 结论
本文研究了早期的一些聚类方法,发现其计算效率较差。因而提出了另一种优化算法,提高当前大数据前提下多维离散数据的计算方法,实验结果证明该方法可行并且优于早期的一些计算方法。该方法虽然有效提高了数据计算的效率,但是仍存在一些不足,希望更多的研究者们提出更优化、更效率的多维离散数据计算方法。大数据正在普及,数据的存储计算以及展示优化在未来一定迎来更广阔的发展。
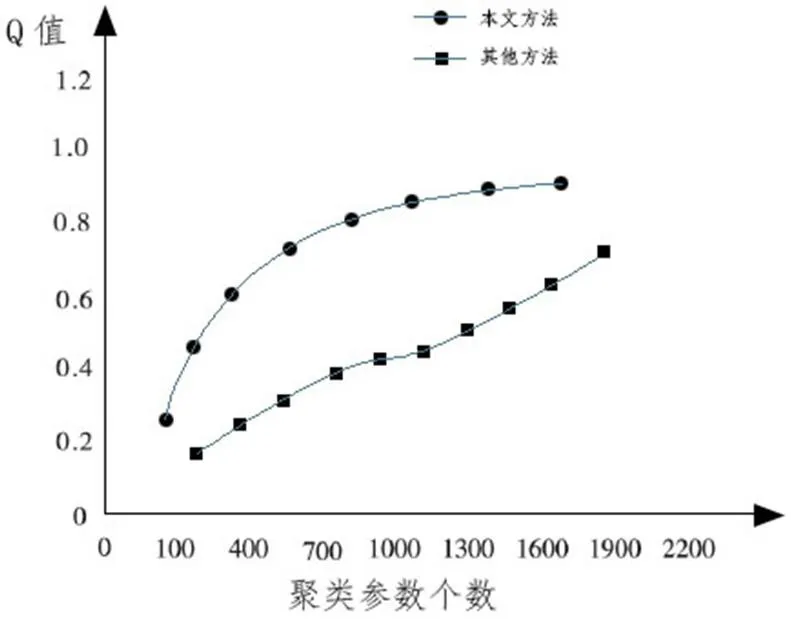
图1:不同聚类方法Q值对比
