基于Hadoop平台的岗位推荐系统设计
2019-11-12顾军林刘玮玮陈冠宇
顾军林 刘玮玮 陈冠宇
摘 要: 针对当前学生择业难而学校人才培养无法满足当前社会实际需求的问题,提出基于Hadoop平台的大数据就业岗位推荐系统。该系统利用爬虫技术爬取互联网招聘网站上的海量岗位信息,并对岗位信息进行整理、清洗、分析,HBase作为数据存储,将数据制作成图表,给用户直观体验;根据用户提供的用户技能为用户筛选出合适的岗位,实现岗位的精确推荐。
关键词: 岗位推荐; Hadoop平台; 爬虫技术; 信息处理; HBase; 功能实现
中图分类号: TN911?34; TP391.1 文献标识码: A 文章编号: 1004?373X(2019)20?0123?05
Design of post recommendation system based on Hadoop platform
GU Junlin, LIU Weiwei, CHEN Guanyu
(Engineering Technology Research and Developent Center of Electronic Products Equipment Manufacturing of Jiangsu Province, Huaian 223003, China)
Abstract: In allusion to the problems that it is difficult for students to choose jobs and the talent training in schools cannot meet the actual needs of the current society, a big data employment post recommendation system based on Hadoop platform is proposed. The crawler technology is used in this system to catch the massive post information in the Internet recruitment website, and then sort, clean and analyze it. The HBase is used as data storage to put the data into charts to give users an intuitive experience. The appropriate post is selected for the user according to the skills provided by him to achieve accurate job recommendation.
Keywords: post recommendation; Hadoop platform; crawler technology; information processing; HBase; function realization
0 引 言
时代迅速发展,人们已经步入大数据时代,大数据通过对海量数据的分析,从而得出一个数据走向,相比随机采样式数据分析,结果更可靠更有说服力[1]。如今,就业问题让许多人头疼,其中有几个原因[2?3]:一是中国人口数量庞大,岗位的状态接近饱和;二是许多就业者不能认识到当前的行业的状况,在学校中也缺少对行业、岗位状况的了解,再就是不能认识到自己,不知道自己的所学能胜任什么工作[4?6]。本文实现目标是构建一个基于Hadoop平台的大数据就业岗位推荐系统,利用爬虫[7]技术爬取互联网招聘网站上的海量岗位信息,并对岗位信息进行整理、清洗、分析、聚类、存储,数据制作成图表,给用户直观体验。根据用户提供的用户技能来为用户筛选出合适的岗位,应用大数据推荐算法实现岗位的精确推荐,以帮助用户从茫茫岗海中迅速找到合适的岗位,让择业目的性、准确性更加突出。
1 系统架构架构设计
根据系统需求设计系统的架构如图1所示。
项目采用前后台分离开发模式。后端主要专注于控制层(Restful API)、服务层、数据访问层;前端专注于前端控制层(Nodejs)、视图层、相互协作、高度配合。系统主要分为以下两个部分:
1.1 Xq?Server服务端设计
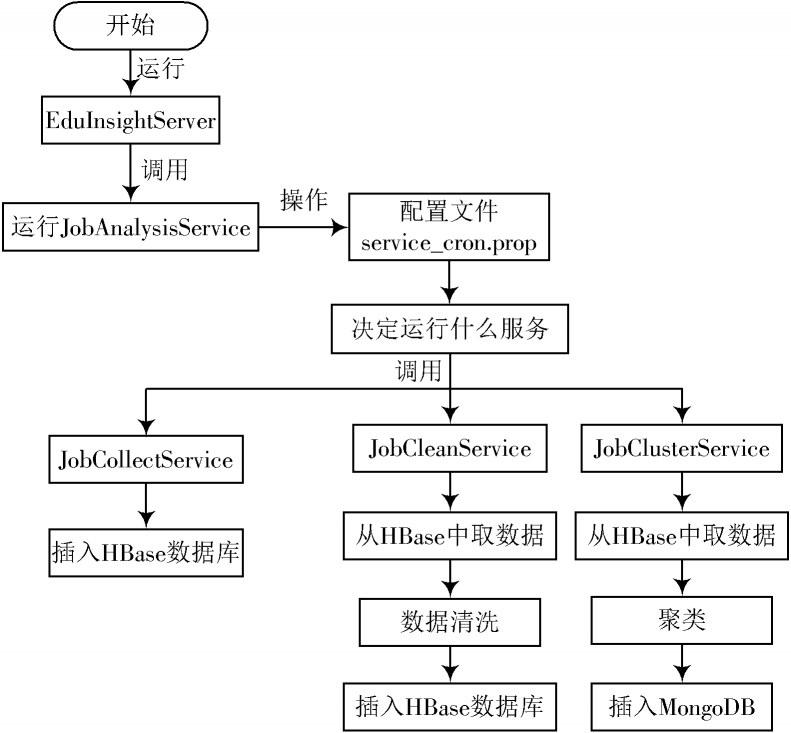
Xq?Server负责从招聘网站上的海量岗位中爬取有用的岗位数据进行整理、清洗、分析、聚类、存储,为前端调用提供数据支撑。Xq?Server详细运行流程如图2所示。
图1 系统架构图
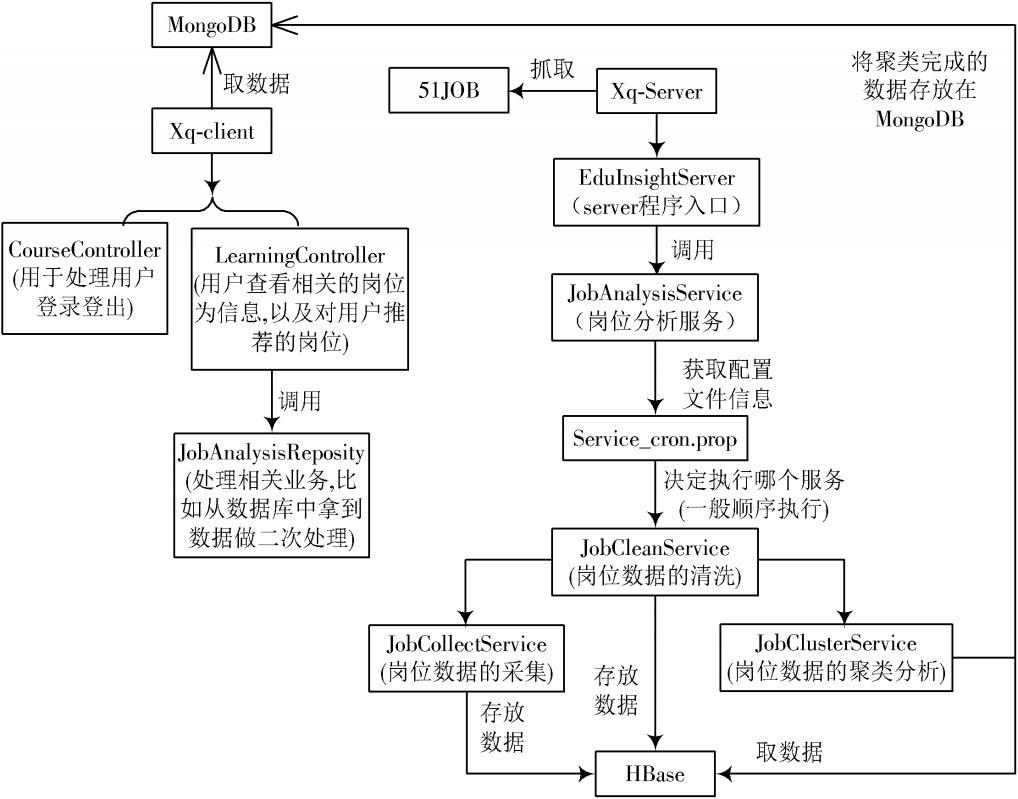
图2 Xq?Server运行流程图
Xq?Server部分中有两大重要接口:一个是Service接口;一个是Server接口。每个功能模块都有一个Service,各功能模块的Service都实现了Service的接口。系统中各Service类如图3所示。
1.2 Xq?Client客户端设计
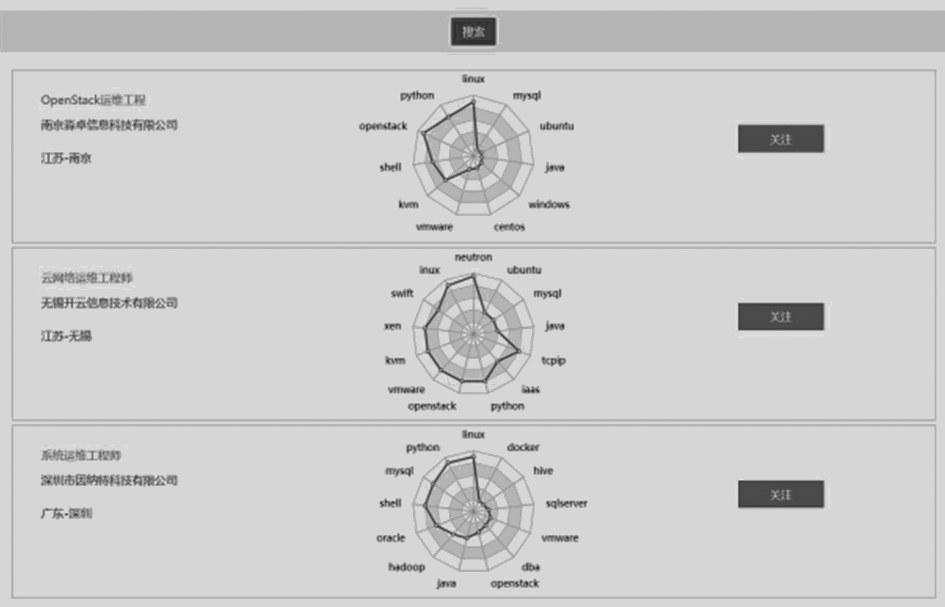
Xq?Client:负责岗位推荐、数据的显示,从MongoDB中读取数据绘制前端图表。Xq?Client部分有岗位推荐功能,推荐部分入口是LearningController的getJytj()方法,该方法接收用户传递过来的技能信息和技能积累时间,然后调用JobAnalysisReposity类中的getJytj()方法获得推荐数据返回给用户。
岗位推荐类结构如图4所示。
图3 各Service类结构
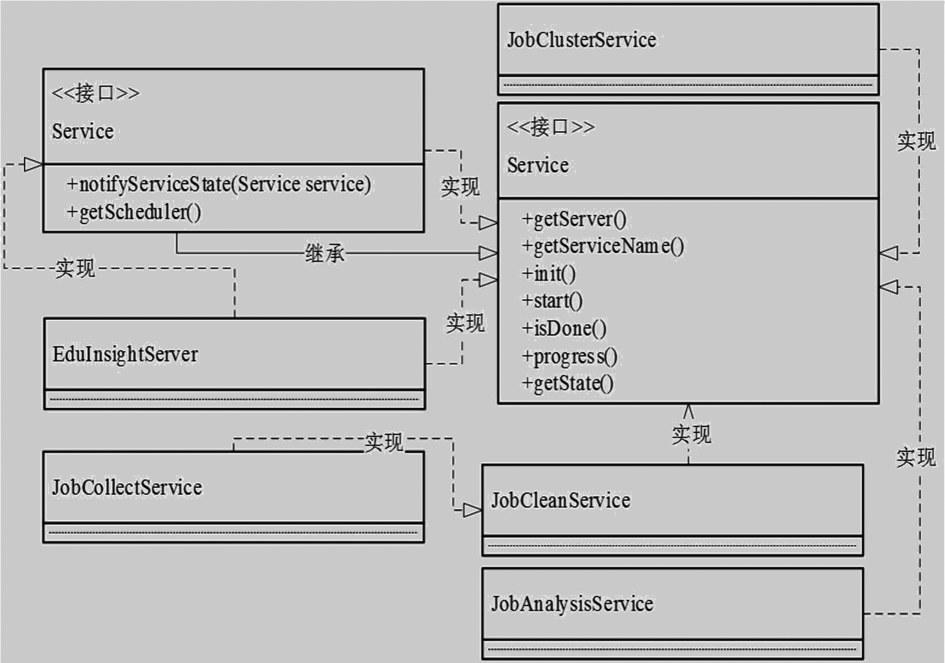
图4 岗位推荐类图结构
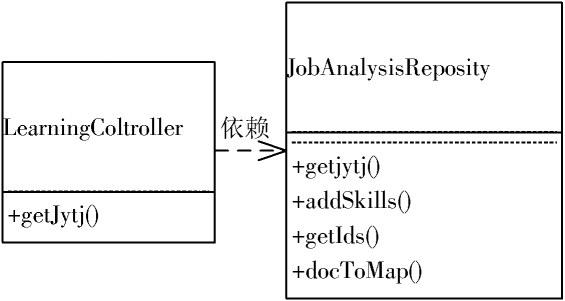
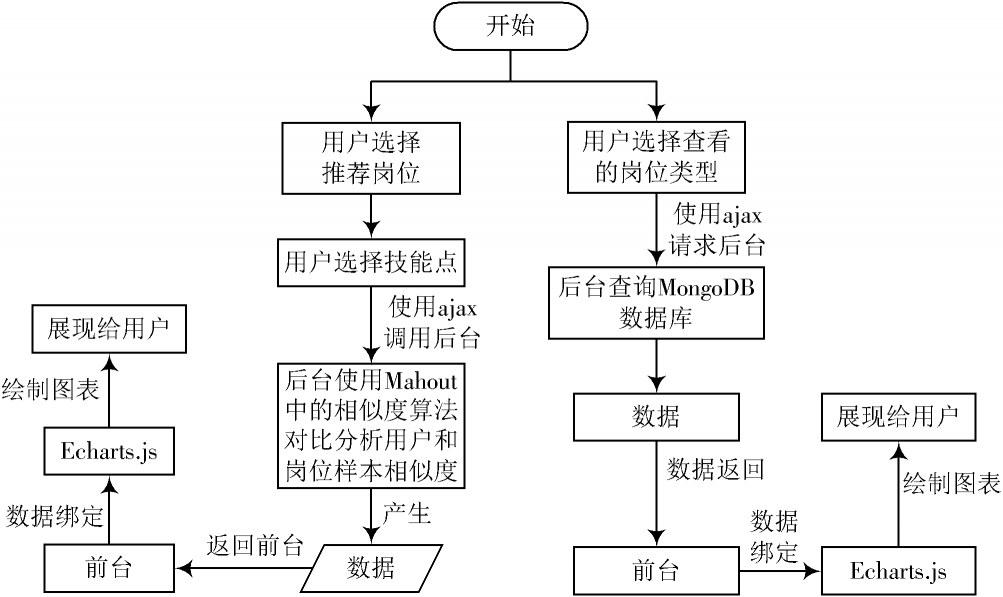
图5 Xq?Client运行流程图
1.3 HBase系统数据库设计
网络爬虫爬取的招聘岗位数据,存储表“job_internet”初始设计为2个列族:RAW_DATA和TAG_DATA,分别保存爬取的原始数据和标签获得原始数据,经过数据清洗之后,保存为列族PERCEPT_DATA,存放感知数据。job_internet结构如图6所示。
“job_internet”表中列族RAW_DATA,TAG_DATA,PERCEPT_DATA数据描述如下:
图6 job_Internet表列簇功能描述
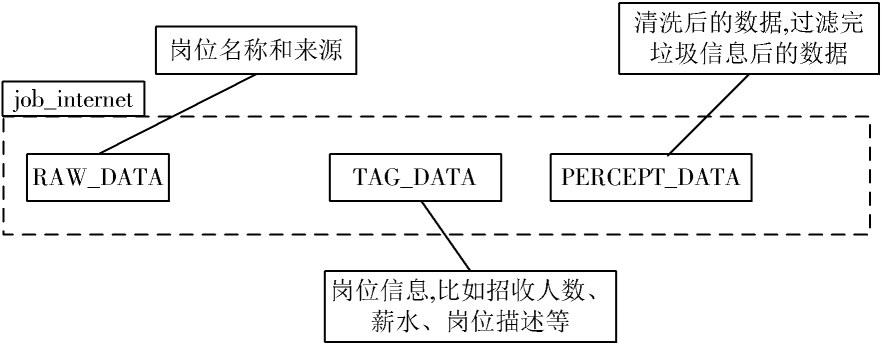
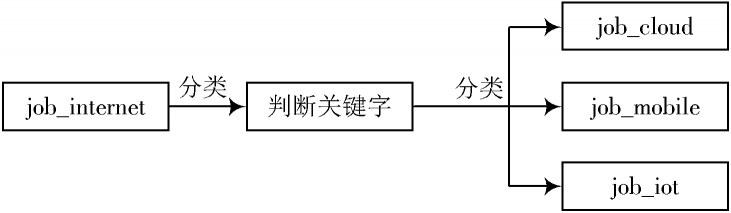
图7 从job_Internet中分出不同的类别,每个类别作为一张表
2 系统功能模块实现
2.1 岗位数据收集模块
岗位分布统计的实现步骤如下:
1) 爬取岗位信息;
2) 将原始数据存入HBase数据库;
3) 清洗崗位信息;
4) 清洗后数据存入HBase数据库;
5) 统计岗位分布结果。
数据收集中间结果:
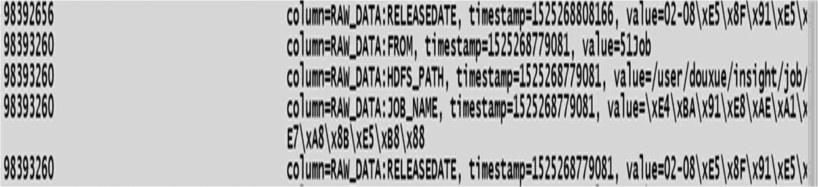
1) job_internet表RAW_DATA列簇(一条)如图8所示。
图8 RAW_DATA中一条数据

2) job_internet表TAG_DATA列簇(一条)如图9所示。
2.2 岗位数据清洗模块
清洗岗位信息,规范化原始数据,并根据岗位名分成多张HBase表,数据清洗中间结果效果图如图10所示。
2.3 岗位统计模块
统计岗位分布结果,根据HBase中清洗后的数据,将所有的岗位按照不同方式统计,包括:岗位地区分布、岗位薪资分布、岗位学历分布、岗位经验分布、公司的性质分布、公司的规模分布等,将统计的数据存入MongoDB,岗位薪资分布图如图11所示。
2.4 岗位聚类模块
岗位聚类模块将所有的岗位先分大类,如:开发、运维、架构等,在大类下,将相似度高的岗位聚合,产生有高代表性的可指定个数的岗位。
1) 岗位聚类模块效果图如图12所示。
2) 岗位聚类模块核心代码如下:
图12 岗位聚类模块效果图

2.5 岗位推荐模块
1) 岗位推荐效果图如图13、图14所示。