一种高精度航拍图像目标检测算法研究与实现
2019-11-12刘洋
刘洋

[摘 要] 航拍图像目标形态受颜色变化、长宽比变化以及复杂背景的影响大,待检测的目标相对于图片背景来说属于相对的小目标,特征提取不易。传统的图像处理方法检测效果差,通过采用深度学习的方法可以实现对航拍图像的准确检测。文章采用RetinaNet (Resnet + FPN + FCN)的方法成功解决这一难题题,实现了对于航拍图片的精准识别。RetinaNet中采用Focal loss损失函数,通过在原有的CE loss上乘以使易检测目标对模型训练贡献削弱的指数式,从而成功地解决了在目标检测时正负样本区域极不平衡而目标检测loss易被大批量负样本所左右的问题。
[关键词] 航拍图像;目标检测;深度学习;特征提取;损失函数
doi : 10 . 3969 / j . issn . 1673 - 0194 . 2019. 19. 064
[中图分类号] TP311 [文献标识码] A [文章编号] 1673 - 0194(2019)19- 0149- 03
1 国内外航拍目标检测现状
目前,航拍目标检测所采用的方法与技术多继承自经典目标检测算法,object detection的算法主要可以分为两大类:two-stage detector和one-stage detector。前者是指类似Faster RCNN、RFCN这样需要region proposal的检测算法,这类算法可以达到很高的准确率,但是速度较慢。虽然可以通过减少proposal的数量或降低输入图像的分辨率等方式达到提速,但是速度并没有质的提升。后者是指类似YOLO、SSD这样不需要region proposal,直接回归的检测算法,这类算法速度很快,但是它当前的检测准确度已经落后于两阶段检测器了。
對于two-stage的检测器而言,通常分为两个步骤,第一个步骤即产生合适的候选区域,而这些候选区域经过筛选,一般控制一个比例(比如正负样本1∶3),另外还通过hard negative mining(OHEM),控制难分样本占据的比例,以解决样本类别不均衡的问题。但是对于one-stage的检测器来说,尽管可以采用同样的策略(OHEM)控制正负样本,但是还是有缺陷。
2016年何恺明博士提出图像识别中的深度残差学习(Deep Residual Learning for Image Recognition),就是举世闻名的152层深度残差网络 ResNet-152。2017他又提出Focal Loss for Dense Object Detection,利用焦点损失提升物体检测效果,这使得one-stage 目标检测器,首次达到了更复杂的 two-stage 检测器所能实现的最高 COCO 平均精度。他们设计了一个one-stage目标检测器RetinaNet,在COCO test-dev 上取得了 39.1 AP 的成绩,超过目前公开的单一模型在 one-stage 和 two-stage 检测器上取得的最好成绩。
为解决two-stage detector检测算法精度高但是速度慢,one-stage detector检测速度高但是精度相对较差的问题,本文介绍使用改进的RetinaNet来实现快速精确的航拍目标检测。
2 RetinaNet与航拍图像检测
2.1 RetinaNet概述
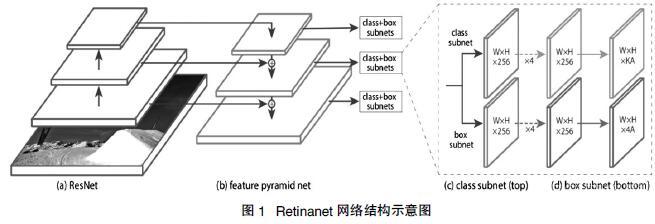
Retinanet的模型结构如图1所示。该模型采用Resnet50/Resnet101作为基础网络提取特征。之后用FPN(特征空间金字塔)进行多尺寸地预测。共输出三种尺寸的输出,每种输出为两路进行分类和box框的回归,输出时采用9个anchor(yolo v3 每个输出采用3个)。
首先多尺度上目标识别是计算机视觉领域的一个基本挑战,解决这一挑战的基本方法就是“基于图像金字塔的特征金字塔(简称为特征图像金字塔)”,这些金字塔具有尺度不变性,可以通过扫描位置和金字塔层来检测大范围上的尺度。将图像金字塔各层提取特征的主要好处就在于产生了一个多尺度特征表示,这个表示的所有层语义很强,包括高精度的层。尽管这样,然而对每层进行特征提取有很明显的限制,Inference time将急剧上升,在图像金字塔上进行end-to-end的训练内存上也不可行,最多只能在测试的时候将就用一下。Fast and Faster R-CNN也尽量避免采用这种方法。
Retinanet的主网络部分采用的是FPN结构,两个不同任务的子网络,一个是分类网络,一个是位置回归网络,如图1所示。
Retinanet的主网络部分结构并不与FPN中提到的结构完全一致,Retinanet使用特征金字塔层P3,P4,P5,P6,P7,其中,P3,P4,P5与FPN中的产生方式一样,通过上采样和横向连接从C3,C4,C5中产生,P6是在C5的基础上通过3×3的卷积核,步长为2的卷积得到的,P7在P6的基础上加了个RELU再通过3×3的卷积核,步长为2的卷积得到的。在P3-P7层上选用的anchors拥有的像素区域大小从32×32到512×512,每层之间的长度是两倍的关系。每个金字塔层有三种长宽比例[1∶2 ,1∶1 ,2∶1],有三种尺寸大小[2^0,2^(1/3), 2^(2/3))。总共便是每层9个anchors。大小从32像素到813像素。其中32=(32x2^0)813=(512x2^(2/3))
分类子网络和回归子网络的参数是分开的,但结构却相似。都是用小型FCN网络,将金字塔层作为输入,接着连接4个3x3的卷积层,fliter为金字塔层的通道数(论文中是256),每个卷积层后都有RELU激活函数,这之后连接的是fliter为KA(K是目标种类数,A是每层的anchors数,论文中是9)的3×3的卷积层,激活函数是sigmoid。另外Retinanet的主要亮点是损失函数(loss = focal loss(分类) + smooth L1 loss),下面重点讲一下Focal Loss。
2.2 Focal Loss分析
直接应用Retinanet引出一个问题:在目标检测中,one stage效果较差于two stage的主要原因是one stage在训练时样本比例不均衡(比如yolo v3等,在训练时要生成3×13×13 + 3×26×26 + 3×52×52 = 10 647个box,但这些box中真正有物体的也就几个,其他都是背景,这样导致背景太多物体太少严重失衡;而two stage的faster-cnn通过RPN可以过滤掉大量的box,保留2 000个,虽然也不均衡,但相对于one stage好的多)。目前常见的解决方法是:在训练的时候用不同的采样频率;给予不同的权重。而提出的focal loss不需要这些步骤。
新的损失函数 Focal Loss主要思路是降低分类效果好(网络预测的置信度confidence高)的样本的loss值,让模型聚焦在难学习的样本中。这个损失函数在标准的交叉熵标准上添加了一个因子 (1- pt) γ 。设定 γ > 0 可以减小分类清晰的样本的相对损失(pt >.5),使模型更加集中于困难的错误分类的样本。
图2显示了交叉熵loss和focal loss的关系,横轴表示网络预测该类物体的置信度。当r=0时,cross entropy = focal loss,不同的r代表了不同的惩罚力度,作者使用r=2效果最好。在confidence高时,用cross entropy 时loss的值相对于focal loss大,如果使用cross entropy loss, 它使得模型倾向于这些样本的训练(由于预测的置信度已经很高了,无须再多关注这个样本),使用focal减小了这种倾向,使模型不过于关注效果好的样本。在confidenct很低时,很有可能预测错误,此时focal loss和交叉熵loss十分接近,二者但作用接近。
试验证明,在存在大量简单背景样本(background example)的情况下Focal Loss 函数可以训练出准确度很高的密集对象检测器。
2.3 残差神经网络ResNet
ResNet最初的灵感出自这个问题:在不断增加神经网络的深度时,会出现一个Degradation(退化)的问题,即准确率会先上升然后达到饱和,再持续增加深度则会导致准确率下降。这并不是过拟合的问题,因为不光在测试集上误差增大,训练集本身误差也会增大。
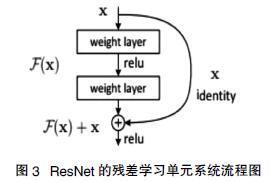
假设有一个比较浅的网络达到了饱和的准确率,那么后面再加上几个y=x的全等映射层,起码误差不会增加,即更深的网络不应该带来训练集上误差上升。而这里提到的使用全等映射直接将前一层输出传到后面的思想,就是ResNet的基础。假定某段神经网络的输入是x,期望输出是H(x),如果直接把输入x传到输出作为初始结果,那么此时需要学习的目标就是F(x)=H(x)-x。如图3所示,这就是一个ResNet的残差学习单元。
可以看到x是这一层残差块的输入,也称作F(x)为残差,x为输入值,F(X)是经过第一层线性变化并激活后的输出,该图表示在残差网络中,第二层进行线性变化之后激活之前,F(x)加入了这一层输入值x,然后再进行激活后输出。在第二层输出值激活前加入x,这条路径称作shortcut连接。
假设该层是冗余的,在引入ResNet之前,想让该层学习到的参数能够满足h(x)=x,即输入是x,经过该冗余层后,输出仍然为x。但是可以看见,要想学习h(x)=x恒等映射时的这层参数时比较困难的。ResNet想到避免去学习该层恒等映射的参数,使用了如上图的结构,让h(x)=F(x)+x;这里的F(x)称作残差项。要想让该冗余层能够恒等映射,只需要学习F(x)=0。学习F(x)=0比学习h(x)=x要简单,因为一般每层网络中的参数初始化偏向于0,这样在相比于更新该网络层的参数来学习h(x)=x,该冗余层学习F(x)=0的更新参数能够更快收敛。
普通直连的卷积神经网络和ResNet的最大区别在于,ResNet有很多旁路的支线将输入直接连到后面的层,使得后面的层直接学习残差,这种结构也被称为shortcut或skip connections。
传统的卷积层或全连接层在信息传递时,或多或少会存在信息丢失、损耗等问题。ResNet在某种程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络则只需要学习输入、输出差别的那一部分,简化学习目标和难度。
3 基于RetinaNet的航拍影像目标检测
处理好模型需要的数据集后,可以将数据集分为训练集和测试集,使用训练集去进行训练,测试集验证模型的错误率。
训练开始前需要设置模型训练参数,包括image-min-side,image-max-side模型图片的输入尺寸,batch-size每步训练使用图片数量,epochs训练总共进行轮次,steps每个epoch训练步数,设置完成后,可以开始进行训练,在训练完成后将得到多个模型权重文件。
通过前面的操作得到了相对来说较好的模型权重文件,但是这个模型文件是不能直接用于检测的,需要进行转化才可以使用。选取一个模型文件进行转化,得到推断预测模型,使用这个模型进行目标检测。
图4为实际使用推断模型对航拍图片进行目标检测的结果展示。
4 结 语
航拍目标检测作为目标检测的子方向,是计算机视觉领域的重要研究内容。航拍目标检测在军事目标智能识别,遥感影像解析以及民用航空等领域具备广阔的应用前景。但是,航拍图像中的目标受颜色,长宽比变化以及复杂背景以及旋转的影响很大。本文提出使用Resnet残差网络和损失函数Focal Loss来对航拍目标进行检测。在保证检测速度的前提下,提高了目标检测精度,目标检测准确度达到了90%以上。同时通过对数据集的增强处理,提高了模型预测的准确度。
在深度学习网络方面,本文只采用了101层Resnet和50层的Resnet残差网络进行了测试学习,没有进行更多种类的尝试。本文只对航拍中比较清晰的高分辨率图像进行了一定的尝试,而对低分辨率的图像有待验证。在数据增强中,后面会考虑使用条件型生成对抗网络,使用CycleGAN进行更多的数据增强扩张,这部分工作会继续进行下去。
主要参考文献
[1]Tsung-Yi Lin, Priya Goyal, Ross Girshick, et al.Focal Loss for Dense Object Detection[C]//IEEE Transactions on Pattern Analysis and Machine Intelligence,2017.
[2]Kaiming He,Xiangyu Zhang,Shaoqing Ren,et al.Deep Residual Learning for Image Recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition,2016.
[3]蔡强,刘亚东,曹建,等.图像目标类别检测综述[J] .计算机科学与探索,2015(3):257-265.
[4]G Montufar,R Pascanu,K Cho,et al. On the Number of Linear Regions of Deep Neural Networks[C]//Proceedings of the 27th International Conference on Neural Information Proceeding Sytems-2,2014.
[5]高常鑫.基于深度學习的高分辨率遥感影像目标检测[D] .武汉:华中科技大学,2014.
[6]丰晓霞.基于深度学习的图像识别算法研究[D] .太原:太原理工大学,2015:29-32.
